解析器本质上是一个状态机。但我们也曾提到,正则表达式其实也是一个状态机。因此在编写 parser 的时候,利用正则表达式能够让我们少写不少代码。本章我们将更多地利用正则表达式来实现 HTML 解析器。另外,一个完善的 HTML 解析器远比想象的要复杂。我们知道,浏览器会对 HTML 文本进行解析,那么它是如何做的呢?其实关于 HTML 文本的解析,是有规范可循的,即 WHATWG 关于 HTML 的解析规范,其中定义了完整的错误处理和状态机的状态迁移流程,还提及了一些特殊的状态,例如 DATA、CDATA、RCDATA、RAWTEXT 等。那么,这些状态有什么含义呢?它们对解析器有哪些影响呢?什么是 HTML 实体,以及 Vue.js 模板解析器需要如何处理HTML 实体呢?
1、文本模式及其对解析器的影响
文本模式指的是解析器在工作时所进入的一些特殊状态,在不同的特殊状态下,解析器对文本的解析行为会有所不同。具体来说,当解析器遇到一些特殊标签时,会切换模式,从而影响其对文本的解析行为。这些特殊标签是:
<title>标签、<textarea>标签,当解析器遇到这两个标签时,会切换到 RCDATA 模式;<style>、<xmp>、<iframe>、<noembed>、<noframes>、<noscript>等标签,当解析器遇到这些标签时,会切换到 RAWTEXT 模式;- 当解析器遇到 <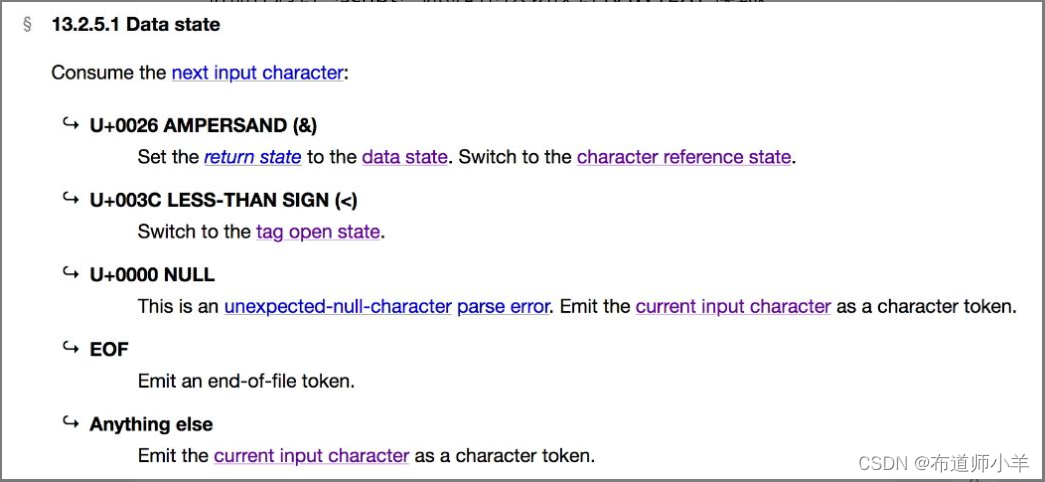
我们对上图做一些必要的解释。在默认的 DATA 模式下,解析器在遇到字符 < 时,会切换到标签开始状态(tag open state)。换句话说,在该模式下,解析器能够解析标签元素。当解析器遇到字符 & 时,会切换到字符引用状态(character reference state),也称 HTML 字符实体状态。也就是说,在DATA 模式下,解析器能够处理 HTML 字符实体。
我们再来看看当解析器处于 RCDATA 状态时,它的工作情况如何。下图给出了 WHATWG 规范第 13.2.5.2 节的内容:

由上图可知,当解析器遇到字符 < 时,不会再切换到标签开始状态,而会切换到 RCDATA less–than sign state 状态。下图给出了 RCDATA less–than sign state 状态下解析器的工作方式:

由下图可知,在 RCDATA less–than sign state 状态下,如果解析器遇到字符 /,则直接切换到 RCDATA 的结束标签状态,即 RCDATA end tag open state;否则会将当前字符 < 作为普通字符处理,然后继续处理后面的字符。由此可知,在RCDATA 状态下,解析器不能识别标签元素。这其实间接说明了在 <textarea> 内可以将字符 < 作为普通文本,解析器并不会认为字符 < 是标签开始的标志,如下面的代码所示:
01 <textarea>
02 <div>asdf</div>asdfasdf
03 </textarea>
在上面这段 HTML 代码中,<textarea> 标签内存在一个<div> 标签。但解析器并不会把 <div> 解析为标签元素,而是作为普通文本处理。但是,由上上图可知,在 RCDATA 模式下,解析器仍然支持 HTML 实体。因为当解析器遇到字符 &时,会切换到字符引用状态,如下面的代码所示:
01 <textarea>&copy;</textarea>
浏览器在渲染这段 HTML 代码时,会在文本框内展示字符 ©。
解析器在 RAWTEXT 模式下的工作方式与在 RCDATA 模式下类似。唯一不同的是,在 RAWTEXT 模式下,解析器将不再支持HTML 实体。下图给出了 WHATWG 规范第 13.2.5.3 节中所定义的 RAWTEXT 模式下状态机的工作方式:

RAWTEXT 模式的确不支持HTML 实体。在该模式下,解析器会将 HTML 实体字符作为普通字符处理。Vue.js 的单文件组件的解析器在遇到 <script> 标签时就会进入 RAWTEXT 模式,这时它会把 <script> 标签内的内容全部作为普通文本处理。
CDATA 模式在 RAWTEXT 模式的基础上更进一步。下图给出了 WHATWG 规范第 13.2.5.69 节中所定义的 CDATA 模式下状态机的工作方式:

在 CDATA 模式下,解析器将把任何字符都作为普通字符处理,直到遇到 CDATA 的结束标志为止。
实际上,在 WHATWG 规范中还定义了 PLAINTEXT 模式,该模式与 RAWTEXT 模式类似。不同的是,解析器一旦进入PLAINTEXT 模式,将不会再退出。另外,Vue.js 的模板 DSL 解析器是用不到 PLAINTEXT 模式的,因此我们不会过多介绍它。
下表汇总了不同的模式及各其特性:
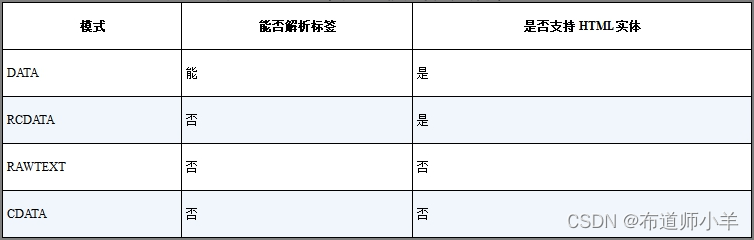
除了上表列出的特性之外,不同的模式还会影响解析器对于终止解析的判断,后文会具体讨论。另外,后续编写解析器代码时,我们会将上述模式定义为状态表,如下面的代码所示:
01 const TextModes = {
02 DATA: 'DATA',
03 RCDATA: 'RCDATA',
04 RAWTEXT: 'RAWTEXT',
05 CDATA: 'CDATA'
06 }
2、递归下降算法构造模板 AST
从本节开始,我们将着手实现一个更加完善的模板解析器。解析器的基本架构模型如下:
01 // 定义文本模式,作为一个状态表
02 const TextModes = {
03 DATA: 'DATA',
04 RCDATA: 'RCDATA',
05 RAWTEXT: 'RAWTEXT',
06 CDATA: 'CDATA'
07 }
08
09 // 解析器函数,接收模板作为参数
10 function parse(str) {
11 // 定义上下文对象
12 const context = {
13 // source 是模板内容,用于在解析过程中进行消费
14 source: str,
15 // 解析器当前处于文本模式,初始模式为 DATA
16 mode: TextModes.DATA
17 }
18 // 调用 parseChildren 函数开始进行解析,它返回解析后得到的子节点
19 // parseChildren 函数接收两个参数:
20 // 第一个参数是上下文对象 context
21 // 第二个参数是由父代节点构成的节点栈,初始时栈为空
22 const nodes = parseChildren(context, [])
23
24 // 解析器返回 Root 根节点
25 return {
26 type: 'Root',
27 // 使用 nodes 作为根节点的 children
28 children: nodes
29 }
30 }
在上面这段代码中,我们首先定义了一个状态表 TextModes,它用来描述预定义的文本模式。然后,我们定义了 parse 函数,即解析器函数,在其中定义了上下文对象 context,用来维护解析程序执行过程中程序的各种状态。接着,调用parseChildren 函数进行解析,该函数会返回解析后得到的子节点,并使用这些子节点作为 children 来创建 Root 根节点。最后,parse 函数返回根节点,完成模板 AST 的构建。
在上面这段代码中,parseChildren 函数是整个解析器的核心。后续我们会递归地调用它来不断地消费模板内容。parseChildren 函数会返回解析后得到的子节点。举个例子,假设有如下模板:
01 <p>1</p>
02 <p>2</p>
上面这段模板有两个根节点,即两个 <p> 标签。parseChildren 函数在解析这段模板后,会得到由这两个 <p>节点组成的数组:
01 [
02 { type: 'Element', tag: 'p', children: [/*...*/] },
03 { type: 'Element', tag: 'p', children: [/*...*/] },
04 ]
之后,这个数组将作为 Root 根节点的 children。
parseChildren 函数本质上也是一个状态机,该状态机有多少种状态取决于子节点的类型数量。在模板中,元素的子节点可以是以下几种:
在标准的 HTML 中,节点的类型将会更多,例如 DOCTYPE 节点等。为了降低复杂度,我们仅考虑上述类型的节点。
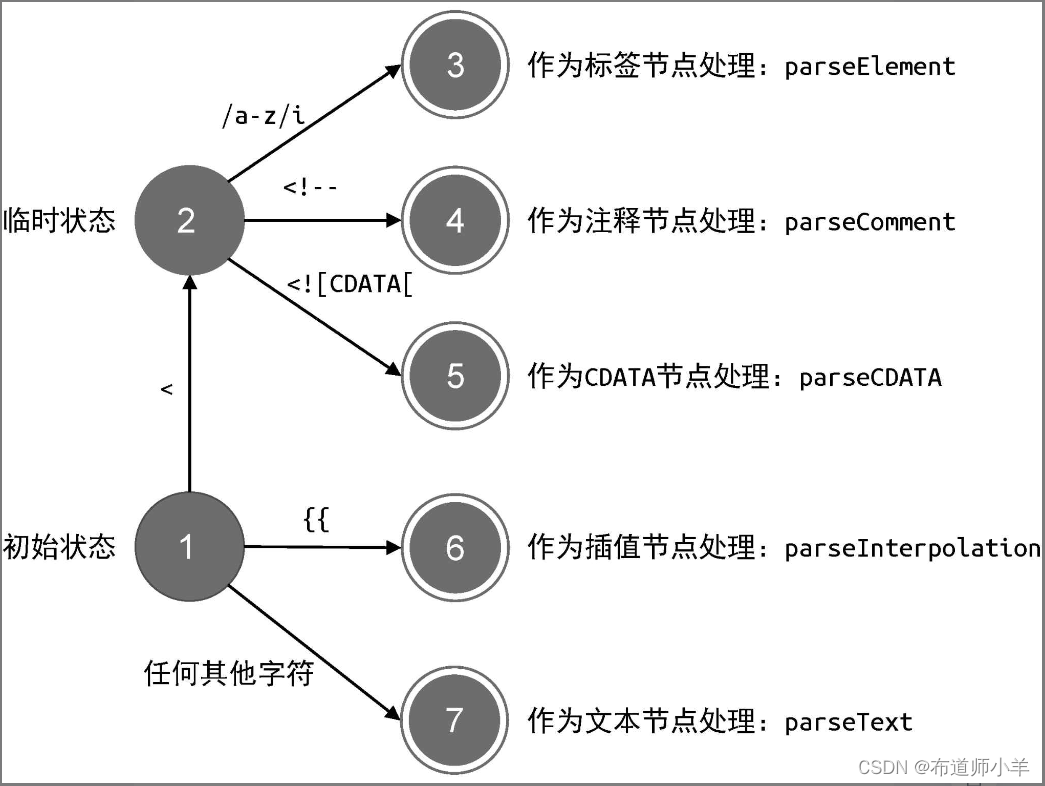
上图给出了 parseChildren 函数在解析模板过程中的状态迁移过程:
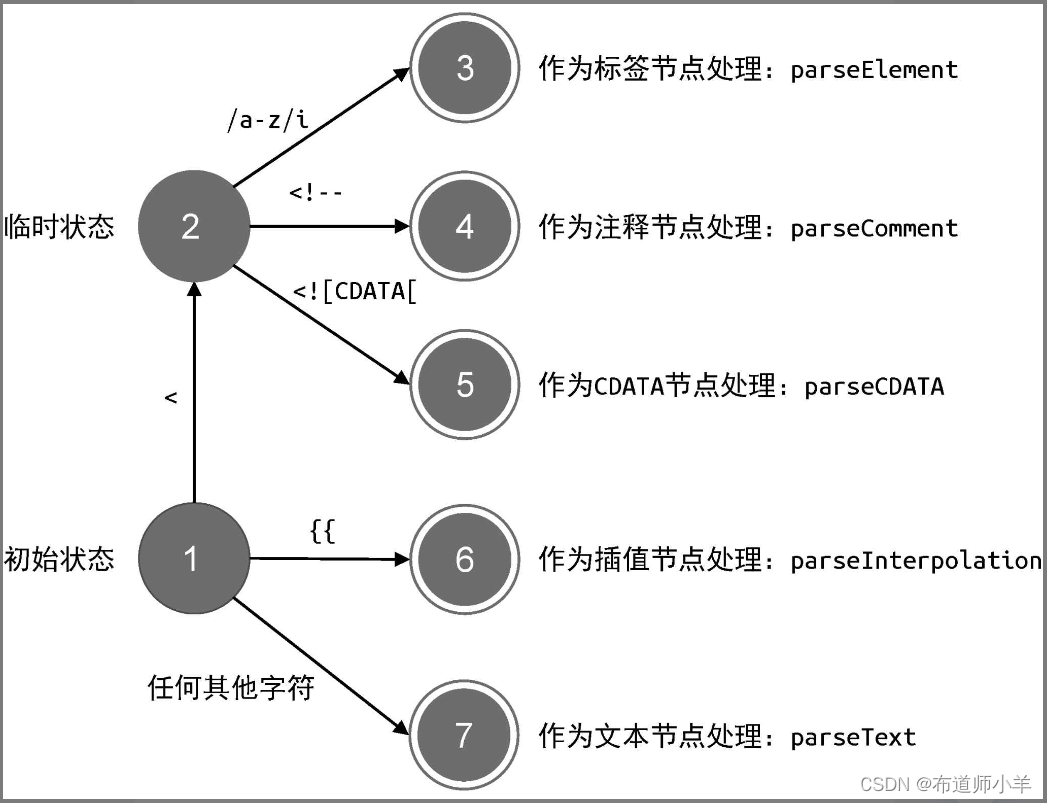
我们可以把上图所展示的状态迁移过程总结如下:
- 当遇到字符 < 时,进入临时状态。
- 如果下一个字符匹配正则 /a-z/i,则认为这是一个标签节点,于是调用 parseElement 函数完成标签的解析。注意正则表达式 /a-z/i 中的 i,意思是忽略大小写(case–insensitive)。
- 如果字符串以 <!– 开头,则认为这是一个注释节点,于是调用 parseComment 函数完成注释节点的解析。
- 如果字符串以 <![CDATA[ 开头,则认为这是一个 CDATA 节点,于是调用 parseCDATA 函数完成 CDATA 节点的解析。
- 如果字符串以 {{ 开头,则认为这是一个插值节点,于是调用parseInterpolation 函数完成插值节点的解析。
- 其他情况,都作为普通文本,调用 parseText 函数完成文本节点的解析。
01 function parseChildren(context, ancestors) {
02 // 定义 nodes 数组存储子节点,它将作为最终的返回值
03 let nodes = []
04 // 从上下文对象中取得当前状态,包括模式 mode 和模板内容 source
05 const { mode, source } = context
06
07 // 开启 while 循环,只要满足条件就会一直对字符串进行解析
08 // 关于 isEnd() 后文会详细讲解
09 while(!isEnd(context, ancestors)) {
10 let node
11 // 只有 DATA 模式和 RCDATA 模式才支持插值节点的解析
12 if (mode === TextModes.DATA || mode === TextModes.RCDATA) {
13 // 只有 DATA 模式才支持标签节点的解析
14 if (mode === TextModes.DATA && source[0] === '<') {
15 if (source[1] === '!') {
16 if (source.startsWith('<!--')) {
17 // 注释
18 node = parseComment(context)
19 } else if (source.startsWith('<![CDATA[')) {
20 // CDATA
21 node = parseCDATA(context, ancestors)
22 }
23 } else if (source[1] === '/') {
24 // 结束标签,这里需要抛出错误,后文会详细解释原因
25 } else if (/[a-z]/i.test(source[1])) {
26 // 标签
27 node = parseElement(context, ancestors)
28 }
29 } else if (source.startsWith('{{')) {
30 // 解析插值
31 node = parseInterpolation(context)
32 }
33 }
34
35 // node 不存在,说明处于其他模式,即非 DATA 模式且非 RCDATA 模式
36 // 这时一切内容都作为文本处理
37 if (!node) {
38 // 解析文本节点
39 node = parseText(context)
40 }
41
42 // 将节点添加到 nodes 数组中
43 nodes.push(node)
44 }
45
46 // 当 while 循环停止后,说明子节点解析完毕,返回子节点
47 return nodes
48 }
上面这段代码完整地描述了上图所示的状态迁移过程,这里有几点需要注意:
- parseChildren 函数的返回值是由子节点组成的数组,每次while 循环都会解析一个或多个节点,这些节点会被添加到nodes 数组中,并作为 parseChildren 函数的返回值返回。
- 解析过程中需要判断当前的文本模式。根据上表可知,只有处于 DATA 模式或 RCDATA 模式时,解析器才支持插值节点的解析。并且,只有处于 DATA 模式时,解析器才支持标签节点、注释节点和 CDATA 节点的解析。
- 当遇到特定标签时,解析器会切换模式。一旦解析器切换到 DATA 模式和 RCDATA 模式之外的模式时,一切字符都将作为文本节点被解析。当然,即使在 DATA 模式或 RCDATA 模式下,如果无法匹配标签节点、注释节点、CDATA 节点、插值节点,那么也会作为文本节点解析。
除了上述三点内容外,你可能对这段代码仍然有疑问,其中之一是 while 循环何时停止?以及 isEnd() 函数的用途是什么?这里我们给出简单的解释,parseChildren 函数是用来解析子节点的,因此 while 循环一定要遇到父级节点的结束标签才会停止,这是正常的思路。但这个思路存在一些问题,不过我们这里暂时将其忽略,后文会详细讨论。
我们可以通过一个例子来更加直观地了解 parseChildren 函数,以及其他解析函数在解析模板时的工作职责和工作流程。以下面的模板为例:
01 const template = `<div>
02 <p>Text1</p>
03 <p>Text2</p>
04 </div>`
这里需要强调的是,在解析模板时,我们不能忽略空白字符。这些空白字符包括:换行符(n)、回车符(r)、空格('')、制表符(t)以及换页符(f)。如果我们用加号(+)代表换行符,用减号(-)代表空格字符。那么上面的模板可以表示为:
01 const template = `<div>+--<p>Text1</p>+--<p>Text2</p>+</div>`
解析器一开始处于 DATA 模式。开始执行解析后,解析器遇到的第一个字符为 <,并且第二个字符能够匹配正则表达式 /a-z/i,所以解析器会进入标签节点状态,并调用 parseElement 函数进行解析。
parseElement 函数会做三件事:解析开始标签,解析子节点,解析结束标签。可以用下面的伪代码来表达 parseElement 函数所做的事情:
01 function parseElement() {
02 // 解析开始标签
03 const element = parseTag()
04 // 这里递归地调用 parseChildren 函数进行 <div> 标签子节点的解析
05 element.children = parseChildren()
06 // 解析结束标签
07 parseEndTag()
08
09 return element
10 }
如果一个标签不是自闭合标签,则可以认为,一个完整的标签元素是由开始标签、子节点和结束标签这三部分构成的。因此,在 parseElement 函数内,我们分别调用三个解析函数来处理这三部分内容。以上述模板为例。
parseTag 解析开始标签。parseTag 函数用于解析开始标签,包括开始标签上的属性和指令。因此,在 parseTag 解析函数执行完毕后,会消费字符串中的内容 <div>,处理后的模板内容将变为:
01 const template = `+--<p>Text1</p>+--<p>Text2</p>+</div>`
递归地调用 parseChildren 函数解析子节点。parseElement 函数在解析开始标签时,会产生一个标签节点 element。在parseElement 函数执行完毕后,剩下的模板内容应该作为element 的子节点被解析,即 element.children。因此,我们要递归地调用 parseChildren 函数。在这个过程中,parseChildren 函数会消费字符串的内容:+--<p>Text1</p>+--<p>Text2</p>+。处理后的模板内容将变为:
01 const template = `</div>`
parseEndTag 处理结束标签。可以看到,在经过parseChildren 函数处理后,模板内容只剩下一个结束标签了。因此,只需要调用 parseEndTag 解析函数来消费它即可。
经过上述三个步骤的处理后,这段模板就被解析完毕了,最终得到了模板 AST。但这里值得注意的是,为了解析标签的子节点,我们递归地调用了 parseChildren 函数。这意味着,一个新的状态机开始运行了,我们称其为“状态机 2”。“状态机2”所处理的模板内容为:
01 const template = `+--<p>Text1</p>+--<p>Text2</p>+`
接下来,我们继续分析“状态机 2”的状态迁移流程。在“状态机 2”开始运行时,模板的第一个字符是换行符(字符 + 代表换行符)。因此,解析器会进入文本节点状态,并调用parseText 函数完成文本节点的解析。parseText 函数会将下一个 < 字符之前的所有字符都视作文本节点的内容。换句话说,parseText 函数会消费模板内容 ±-,并产生一个文本节点。在parseText 解析函数执行完毕后,剩下的模板内容为:
01 const template = `<p>Text1</p>+--<p>Text2</p>+`
接着,parseChildren 函数继续执行。此时模板的第一个字符为<,并且下一个字符能够匹配正则 /a-z/i。于是解析器再次进入parseElement 解析函数的执行阶段,这会消费模板内容<p>Text1</p>。在这一步过后,剩下的模板内容为:
01 const template = `+--<p>Text2</p>+`
可以看到,此时模板的第一个字符是换行符,于是调用parseText 函数消费模板内容 ±-。现在,模板中剩下的内容是:
01 const template = `<p>Text2</p>+`
解析器会再次调用 parseElement 函数处理标签节点。在这之后,剩下的模板内容为:
01 const template = `+`
可以看到,现在模板内容只剩下一个换行符了。parseChildren 函数会继续执行并调用 parseText 函数消费剩下的内容,并产生一个文本节点。最终,模板被解析完毕,“状态机 2”停止运行。
在“状态机 2”运行期间,为了处理标签节点,我们又调用了两次 parseElement 函数。第一次调用用于处理内容<p>Text1</p>,第二次调用用于处理内容 <p>Text2</p>。我们知道,parseElement 函数会递归地调用 parseChildren 函数完成子节点的解析,这就意味着解析器会再开启了两个新的状态机。
通过上述例子我们能够认识到,parseChildren 解析函数是整个状态机的核心,状态迁移操作都在该函数内完成。在parseChildren 函数运行过程中,为了处理标签节点,会调用parseElement 解析函数,这会间接地调用 parseChildren 函数,并产生一个新的状态机。随着标签嵌套层次的增加,新的状态机会随着 parseChildren 函数被递归地调用而不断创建,这就是“递归下降”中“递归”二字的含义。而上级parseChildren 函数的调用用于构造上级模板 AST 节点,被递归调用的下级 parseChildren 函数则用于构造下级模板 AST 节点。最终,会构造出一棵树型结构的模板 AST,这就是“递归下降”中“下降”二字的含义。
3、状态机的开启与停止
在上一节中,我们讨论了递归下降算法的含义。我们知道,parseChildren 函数本质上是一个状态机,它会开启一个 while 循环使得状态机自动运行,如下面的代码所示:
01 function parseChildren(context, ancestors) {
02 let nodes = []
03
04 const { mode } = context
05 // 运行状态机
06 while(!isEnd(context, ancestors)) {
07 // 省略部分代码
08 }
09
10 return nodes
11 }
这里的问题在于,状态机何时停止呢?换句话说,while 循环应该何时停止运行呢?这涉及 isEnd() 函数的判断逻辑。为了搞清楚这个问题,我们需要模拟状态机的运行过程。
我们知道,在调用 parseElement 函数解析标签节点时,会递归地调用 parseChildren 函数,从而开启新的状态机,如下图所示:

为了便于描述,我们可以把上图中所示的新的状态机称为“状态机 1”。“状态机 1”开始运行,继续解析模板,直到遇到下一个 <p> 标签,如下图所示:
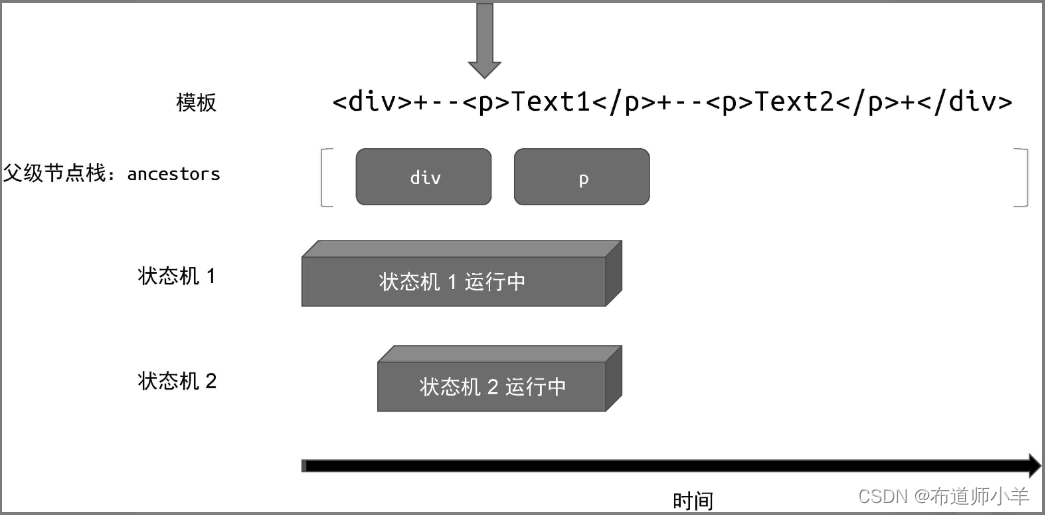
因为遇到了 <p> 标签,所以“状态机 1”也会调用parseElement 函数进行解析。于是又重复了上述过程,即把当前解析的标签节点压入父级节点栈,然后递归地调用parseChildren 函数开启新的状态机,即“状态机 2”。可以看到,此时有两个状态机在同时运行。
此时“状态机 2”拥有程序的执行权,它持续解析模板直到遇到结束标签 </p>。因为这是一个结束标签,并且在父级节点栈中存在与该结束标签同名的标签节点,所以“状态机 2”会停止运行,并弹出父级节点栈中处于栈顶的节点,如下图所示:
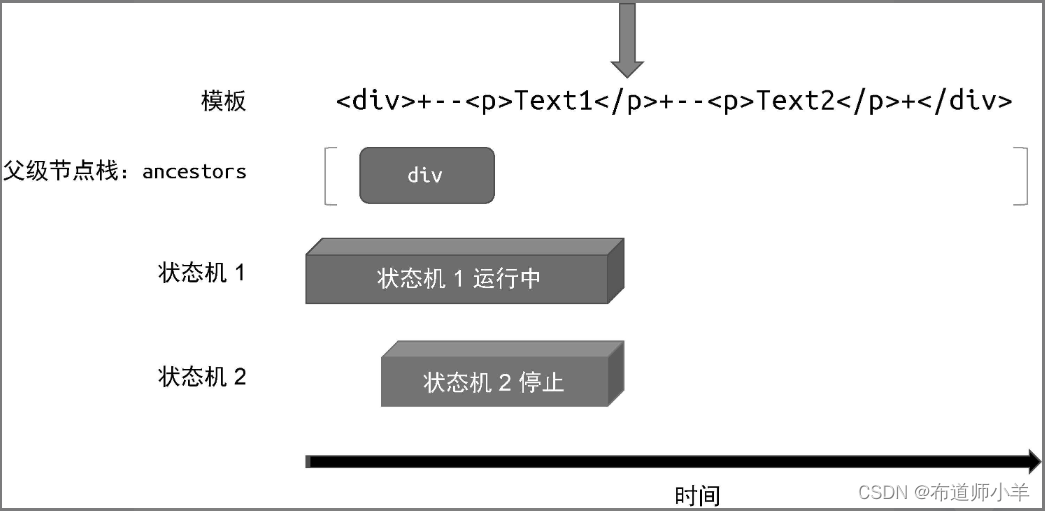
此时“状态机 2”已经停止运行了,但“状态机 1”仍在运行中,于是会继续解析模板,直到遇到下一个 <p> 标签。这时“状态机 1”会再次调用 parseElement 函数解析标签节点,因此又会执行压栈并开启新的“状态机 3”,如下图 所示:
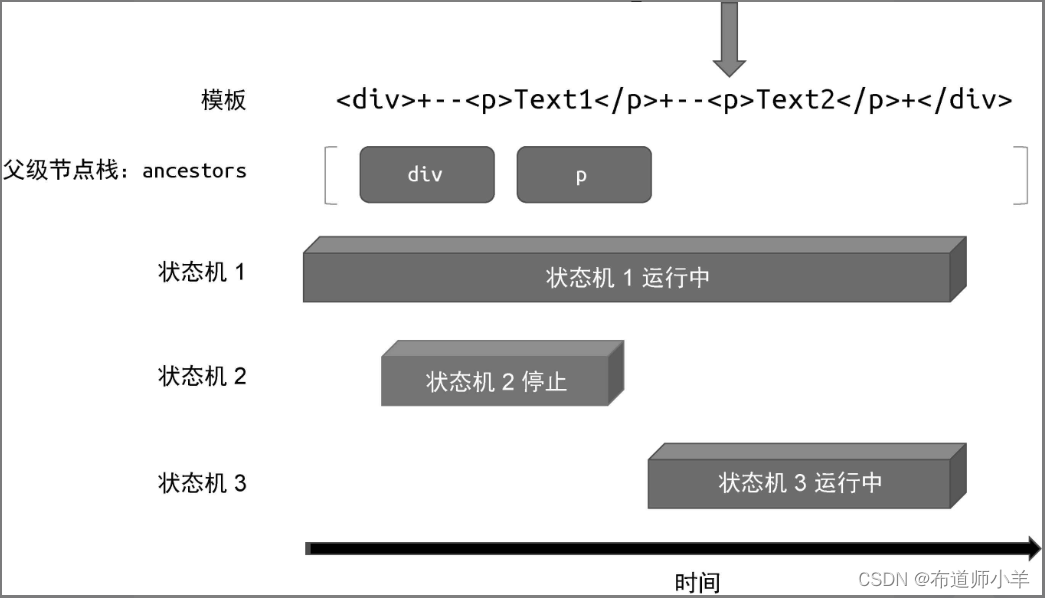
此时“状态机 3”拥有程序的执行权,它会继续解析模板,直到遇到结束标签 </p>。因为这是一个结束标签,并且在父级节点栈中存在与该结束标签同名的标签节点,所以“状态机 3”会停止运行,并弹出父级节点栈中处于栈顶的节点,如下图所示:
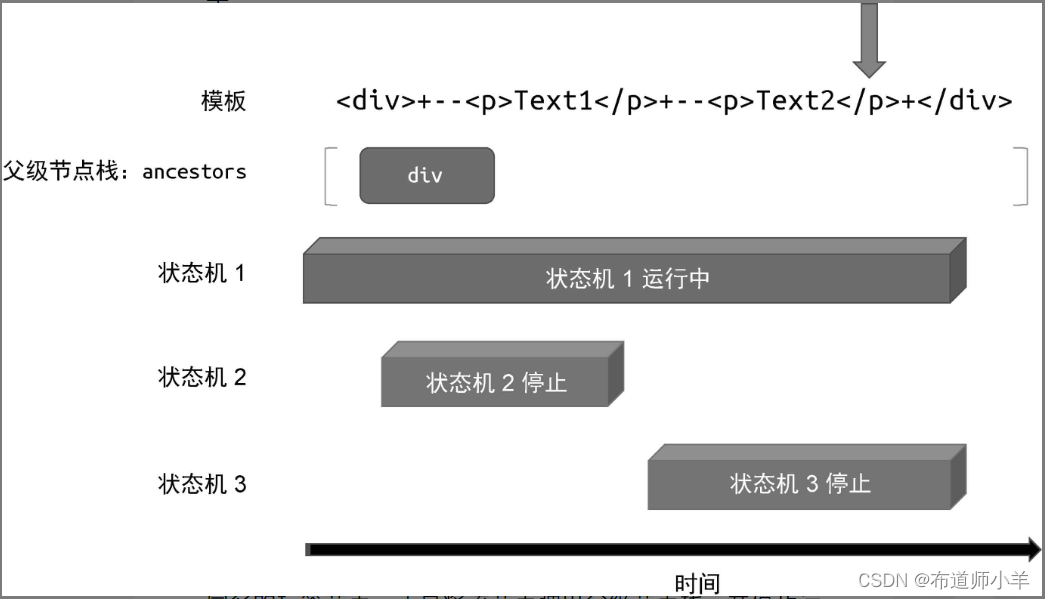
当“状态机 3”停止运行后,程序的执行权交还给“状态机1”。“状态机 1”会继续解析模板,直到遇到最后的 </div>结束标签。这时“状态机 1”发现父级节点栈中存在与结束标签同名的标签节点,于是将该节点弹出父级节点栈,并停止运行,如下图所示:
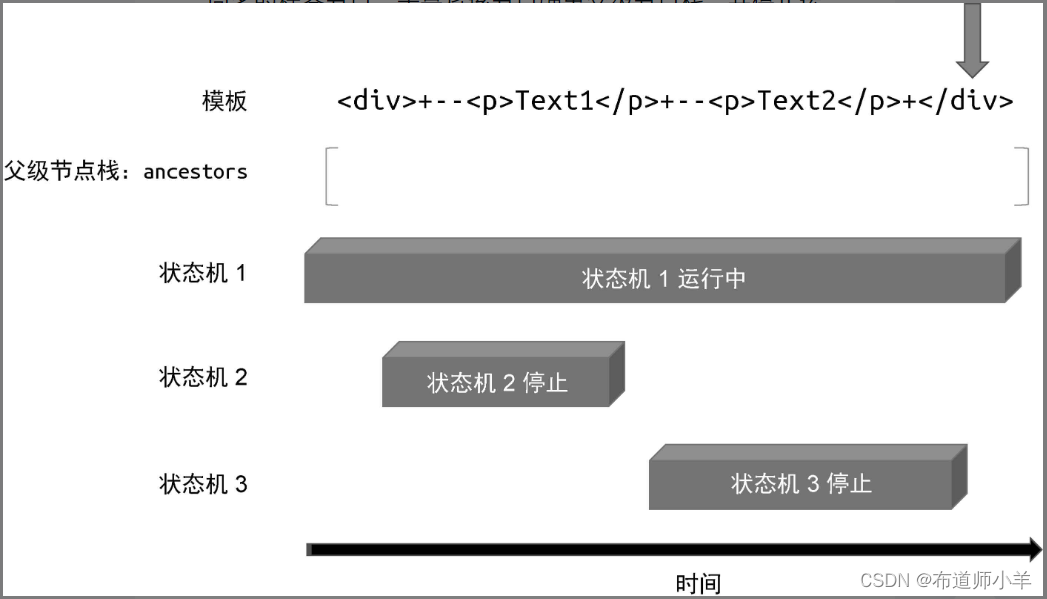
这时父级节点栈为空,状态机全部停止运行,模板解析完毕。
通过上面的描述,我们能够清晰地认识到,解析器会在何时开启新的状态机,以及状态机会在何时停止。结论是:**当解析器遇到开始标签时,会将该标签压入父级节点栈,同时开启新的状态机。当解析器遇到结束标签,并且父级节点栈中存在与该标签同名的开始标签节点时,会停止当前正在运行的状态机。**根据上述规则,我们可以给出 isEnd 函数的逻辑,如下面的代码所示:
01 function isEnd(context, ancestors) {
02 // 当模板内容解析完毕后,停止
03 if (!context.source) return true
04 // 获取父级标签节点
05 const parent = ancestors[ancestors.length - 1]
06 // 如果遇到结束标签,并且该标签与父级标签节点同名,则停止
07 if (parent && context.source.startsWith(`</${parent.tag}`)) {
08 return true
09 }
10 }
上面这段代码展示了状态机的停止时机,具体如下:
这里需要注意的是,在第二个停止时机中,我们直接比较结束标签的名称与栈顶节点的标签名称。这么做的确可行,但严格来讲是有瑕疵的。例如下面的模板所示:
01 <div><span></div></span>
观察上述模板,它存在一个明显的问题,你能发现吗?实际上,这段模板有两种解释方式,下图给出了第一种:
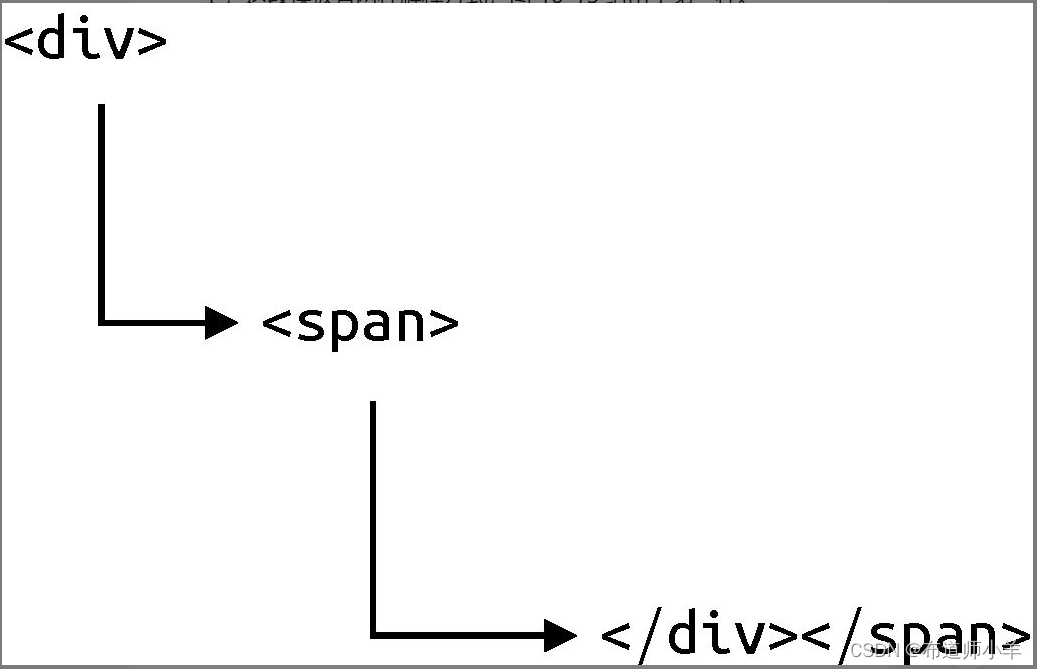
如上图所示,这种解释方式的流程如下:
- 状态机 1”遇到
<div>开始标签,调用 parseElement 解析函数,这会开启“状态机 2”来完成子节点的解析。 - “状态机 2”遇到
<span>开始标签,调用 parseElement 解析函数,这会开启“状态机 3”来完成子节点的解析。 - “状态机 3”遇到
</div>结束标签。由于此时父级节点栈栈顶的节点名称是 span,并不是 div,所以“状态机 3”不会停止运行。这时,“状态机 3”遭遇了不符合预期的状态,因为结束标签</div>缺少与之对应的开始标签,所以这时“状态机3”会抛出错误:“无效的结束标签”。
上述流程的思路与我们当前的实现相符,状态机会遭遇不符合预期的状态。下面 parseChildren 函数的代码能够体现这一点:
01 function parseChildren(context, ancestors) {
02 let nodes = []
03
04 const { mode } = context
05
06 while(!isEnd(context, ancestors)) {
07 let node
08
09 if (mode === TextModes.DATA || mode === TextModes.RCDATA) {
10 if (mode === TextModes.DATA && context.source[0] === '<') {
11 if (context.source[1] === '!') {
12 // 省略部分代码
13 } else if (context.source[1] === '/') {
14 // 状态机遭遇了闭合标签,此时应该抛出错误,因为它缺少与之对应的开始标签
15 console.error('无效的结束标签')
16 continue
17 } else if (/[a-z]/i.test(context.source[1])) {
18 // 省略部分代码
19 }
20 } else if (context.source.startsWith('{{')) {
21 // 省略部分代码
22 }
23 }
24 // 省略部分代码
25 }
26
27 return nodes
28 }
换句话说,按照我们当前的实现思路来解析上述例子中的模板,最终得到的错误信息是:“无效的结束标签”。但其实还有另外一种更好的解析方式。观察上例中给出的模板,其中存在一段完整的内容,如下图所示:
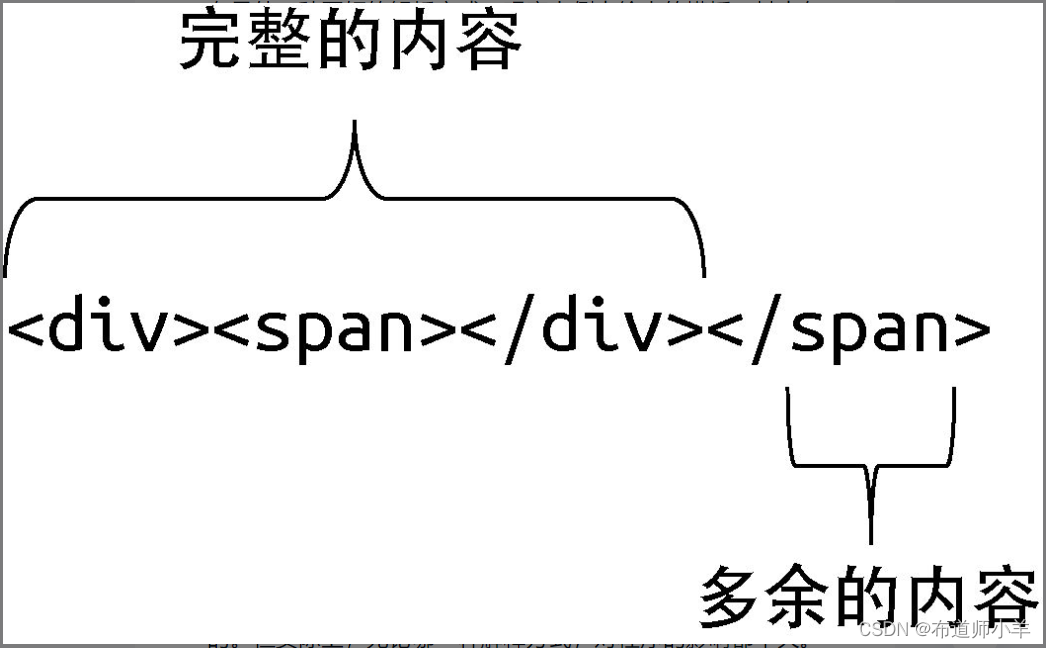
从上图中可以看到,模板中存在一段完整的内容,我们希望解析器可以正常对其进行解析,这很可能也是符合用户意图的。但实际上,无论哪一种解释方式,对程序的影响都不大。两者的区别体现在错误处理上。对于第一种解释方式,我们得到的错误信息是:“无效的结束标签”。而对于第二种解释方式,在“完整的内容”部分被解析完毕后,解析器就会打印错误信息:“<span> 标签缺少闭合标签”。很显然,第二种解释方式更加合理。
为了实现第二种解释方式,我们需要调整 isEnd 函数的逻辑。当判断状态机是否应该停止时,我们不应该总是与栈顶的父级节点做比较,而是应该与整个父级节点栈中的所有节点做比较。只要父级节点栈中存在与当前遇到的结束标签同名的节点,就停止状态机,如下面的代码所示:
01 function isEnd(context, ancestors) {
02 if (!context.source) return true
03
04 // 与父级节点栈内所有节点做比较
05 for (let i = ancestors.length - 1; i >= 0; --i) {
06 // 只要栈中存在与当前结束标签同名的节点,就停止状态机
07 if (context.source.startsWith(`</${ancestors[i].tag}`)) {
08 return true
09 }
10 }
11 }
按照新的思路再次对如下模板执行解析:
01 <div><span></div></span>
其流程如下:
- “状态机 1”遇到
<div>开始标签,调用 parseElement 解析函数,并开启“状态机 2”解析子节点。 - “状态机 2”遇到
<span>开始标签,调用 parseElement 解析函数,并开启“状态机 3”解析子节点。 - “状态机 3”遇到
</div>结束标签,由于节点栈中存在名为div 的标签节点,于是“状态机 3”停止了。
在这个过程中,“状态机 2”在调用 parseElement 解析函数时,parseElement 函数能够发现 <span> 缺少闭合标签,于是会打印错误信息“<span> 标签缺少闭合标签”,如下面的代码所示:
01 function parseElement(context, ancestors) {
02 const element = parseTag(context)
03 if (element.isSelfClosing) return element
04
05 ancestors.push(element)
06 element.children = parseChildren(context, ancestors)
07 ancestors.pop()
08
09 if (context.source.startsWith(`</${element.tag}`)) {
10 parseTag(context, 'end')
11 } else {
12 // 缺少闭合标签
13 console.error(`${element.tag} 标签缺少闭合标签`)
14 }
15
16 return element
17 }
4、解析标签节点
在上一节给出的 parseElement 函数的实现中,无论是解析开始标签还是闭合标签,我们都调用了 parseTag 函数。同时,我们使用 parseChildren 函数来解析开始标签与闭合标签中间的部分,如下面的代码及注释所示:
01 function parseElement(context, ancestors) {
02 // 调用 parseTag 函数解析开始标签
03 const element = parseTag(context)
04 if (element.isSelfClosing) return element
05
06 ancestors.push(element)
07 element.children = parseChildren(context, ancestors)
08 ancestors.pop()
09
10 if (context.source.startsWith(`</${element.tag}`)) {
11 // 再次调用 parseTag 函数解析结束标签,传递了第二个参数:'end'
12 parseTag(context, 'end')
13 } else {
14 console.error(`${element.tag} 标签缺少闭合标签`)
15 }
16
17 return element
18 }
标签节点的整个解析过程如下图所示:

这里需要注意的是,由于开始标签与结束标签的格式非常类似,所以我们统一使用 parseTag 函数处理,并通过该函数的第二个参数来指定具体的处理类型。当第二个参数值为字符串’end’ 时,意味着解析的是结束标签。另外,无论处理的是开始标签还是结束标签,parseTag 函数都会消费对应的内容。为了实现对模板内容的消费,我们需要在上下文对象中新增两个工具函数,如下面的代码所示:
01 function parse(str) {
02 // 上下文对象
03 const context = {
04 // 模板内容
05 source: str,
06 mode: TextModes.DATA,
07 // advanceBy 函数用来消费指定数量的字符,它接收一个数字作为参数
08 advanceBy(num) {
09 // 根据给定字符数 num,截取位置 num 后的模板内容,并替换当前模板内容
10 context.source = context.source.slice(num)
11 },
12 // 无论是开始标签还是结束标签,都可能存在无用的空白字符,例如 <div >
13 advanceSpaces() {
14 // 匹配空白字符
15 const match = /^[trnf ]+/.exec(context.source)
16 if (match) {
17 // 调用 advanceBy 函数消费空白字符
18 context.advanceBy(match[0].length)
19 }
20 }
21 }
22
23 const nodes = parseChildren(context, [])
24
25 return {
26 type: 'Root',
27 children: nodes
28 }
29 }
在上面这段代码中,我们为上下文对象增加了 advanceBy 函数和 advanceSpaces 函数。其中 advanceBy 函数用来消费指定数量的字符。其实现原理很简单,即调用字符串的 slice 函数,根据指定位置截取剩余字符串,并使用截取后的结果作为新的模板内容。advanceSpaces 函数则用来消费无用的空白字符,因为标签中可能存在空白字符,例如在模板 <div----> 中减号(-)代表空白字符。
有了 advanceBy 和 advanceSpaces 函数后,我们就可以给出parseTag 函数的实现了,如下面的代码所示:
01 // 由于 parseTag 既用来处理开始标签,也用来处理结束标签,因此我们设计第二个参数 type,
02 // 用来代表当前处理的是开始标签还是结束标签,type 的默认值为 'start',即默认作为开始标签处理
03 function parseTag(context, type = 'start') {
04 // 从上下文对象中拿到 advanceBy 函数
05 const { advanceBy, advanceSpaces } = context
06
07 // 处理开始标签和结束标签的正则表达式不同
08 const match = type === 'start'
09 // 匹配开始标签
10 ? /^<([a-z][^trnf />]*)/i.exec(context.source)
11 // 匹配结束标签
12 : /^</([a-z][^trnf />]*)/i.exec(context.source)
13 // 匹配成功后,正则表达式的第一个捕获组的值就是标签名称
14 const tag = match[1]
15 // 消费正则表达式匹配的全部内容,例如 '<div' 这段内容
16 advanceBy(match[0].length)
17 // 消费标签中无用的空白字符
18 advanceSpaces()
19
20 // 在消费匹配的内容后,如果字符串以 '/>' 开头,则说明这是一个自闭合标签
21 const isSelfClosing = context.source.startsWith('/>')
22 // 如果是自闭合标签,则消费 '/>', 否则消费 '>'
23 advanceBy(isSelfClosing ? 2 : 1)
24
25 // 返回标签节点
26 return {
27 type: 'Element',
28 // 标签名称
29 tag,
30 // 标签的属性暂时留空
31 props: [],
32 // 子节点留空
33 children: [],
34 // 是否自闭合
35 isSelfClosing
36 }
37 }
上面这段代码有两个关键点:
- 由于 parseTag 函数既用于解析开始标签,又用于解析结束标签,因此需要用一个参数来标识当前处理的标签类型,即type。
- 对于开始标签和结束标签,用于匹配它们的正则表达式只有一点不同:结束标签是以字符串 </ 开头的。下图给出了用于匹配开始标签的正则表达式的含义。
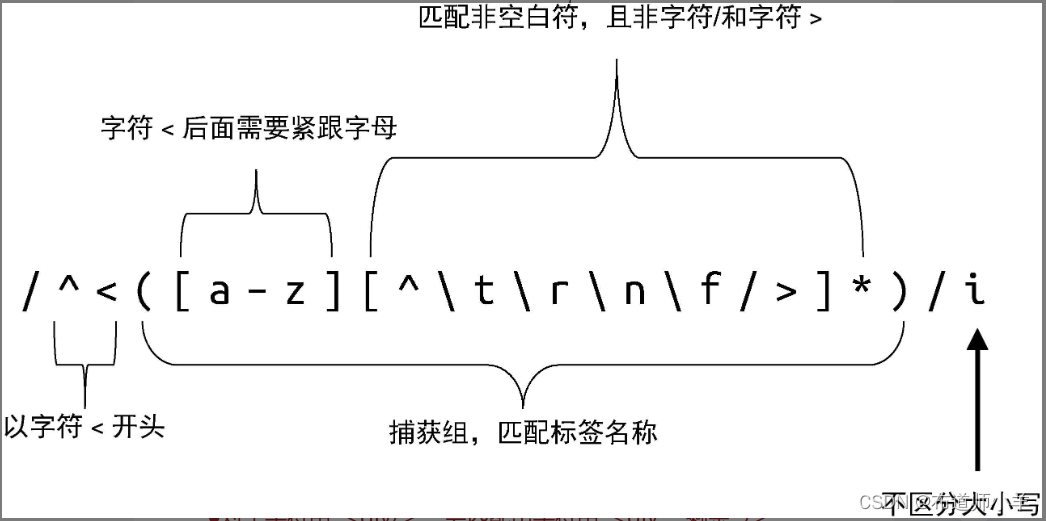
- 对于字符串
'<div>‘,会匹配出字符串 ‘<div',剩余 '>’。 - 对于字符串
'<div/>',会匹配出字符串'<div',剩余 '/>'。 - 对于字符串
'<div---->',其中减号(-)代表空白符,会匹配出字符串'<div',剩余 '---->'。
另外,上图中所示的正则拥有一个捕获组,它用来捕获标签名称。
除了正则表达式外,parseTag 函数的另外几个关键点如下:
- 在完成正则匹配后,需要调用 advanceBy 函数消费由正则匹配的全部内容。
- 根据上面给出的第三个正则匹配例子可知,由于标签中可能存在无用的空白字符,例如
<div---->,因此我们需要调用advanceSpaces 函数消费空白字符。 - 在消费由正则匹配的内容后,需要检查剩余模板内容是否以字符串
/>开头。如果是,则说明当前解析的是一个自闭合标签,这时需要将标签节点的 isSelfClosing 属性设置为 true。 - 最后,判断标签是否自闭合。如果是,则调用 advnaceBy 函数消费内容
/>,否则只需要消费内容 > 即可。
在经过上述处理后,parseTag 函数会返回一个标签节点。parseElement 函数在得到由 parseTag 函数产生的标签节点后,需要根据节点的类型完成文本模式的切换,如下面的代码所示:
01 function parseElement(context, ancestors) {
02 const element = parseTag(context)
03 if (element.isSelfClosing) return element
04
05 // 切换到正确的文本模式
06 if (element.tag === 'textarea' || element.tag === 'title') {
07 // 如果由 parseTag 解析得到的标签是 <textarea> 或 <title>,则切换到 RCDATA 模式
08 context.mode = TextModes.RCDATA
09 } else if (/style|xmp|iframe|noembed|noframes|noscript/.test(element.tag)) {
10 // 如果由 parseTag 解析得到的标签是:
11 // <style>、<xmp>、<iframe>、<noembed>、<noframes>、<noscript>
12 // 则切换到 RAWTEXT 模式
13 context.mode = TextModes.RAWTEXT
14 } else {
15 // 否则切换到 DATA 模式
16 context.mode = TextModes.DATA
17 }
18
19 ancestors.push(element)
20 element.children = parseChildren(context, ancestors)
21 ancestors.pop()
22
23 if (context.source.startsWith(`</${element.tag}`)) {
24 parseTag(context, 'end')
25 } else {
26 console.error(`${element.tag} 标签缺少闭合标签`)
27 }
28
29 return element
30 }
至此,我们就实现了对标签节点的解析。但是目前的实现忽略了节点中的属性和指令,下一节将会讲解。
5、解析属性
上一节中介绍的 parseTag 解析函数会消费整个开始标签,这意味着该函数需要有能力处理开始标签中存在的属性与指令,例如:
01 <div id="foo" v-show="display"/>
上面这段模板中的 div 标签存在一个 id 属性和一个 v-show 指令。为了处理属性和指令,我们需要在 parseTag 函数中增加parseAttributes 解析函数,如下面的代码所示:
01 function parseTag(context, type = 'start') {
02 const { advanceBy, advanceSpaces } = context
03
04 const match = type === 'start'
05 ? /^<([a-z][^trnf />]*)/i.exec(context.source)
06 : /^</([a-z][^trnf />]*)/i.exec(context.source)
07 const tag = match[1]
08
09 advanceBy(match[0].length)
10 advanceSpaces()
11 // 调用 parseAttributes 函数完成属性与指令的解析,并得到 props 数组,
12 // props 数组是由指令节点与属性节点共同组成的数组
13 const props = parseAttributes(context)
14
15 const isSelfClosing = context.source.startsWith('/>')
16 advanceBy(isSelfClosing ? 2 : 1)
17
18 return {
19 type: 'Element',
20 tag,
21 props, // 将 props 数组添加到标签节点上
22 children: [],
23 isSelfClosing
24 }
25 }
上面这段代码的关键点之一是,我们需要在消费标签的“开始部分”和无用的空白字符之后,再调用 parseAttribute 函数。举个例子,假设标签的内容如下:
01 <div id="foo" v-show="display" >
标签的“开始部分”指的是字符串 <div,所以当消耗标签的“开始部分”以及无用空白字符后,剩下的内容为:
01 id="foo" v-show="display" >
上面这段内容才是 parseAttributes 函数要处理的内容。由于该函数只用来解析属性和指令,因此它会不断地消费上面这段模板内容,直到遇到标签的“结束部分”为止。其中,结束部分指的是字符 > 或者字符串 />。据此我们可以给出parseAttributes 函数的整体框架,如下面的代码所示:
01 function parseAttributes(context) {
02 // 用来存储解析过程中产生的属性节点和指令节点
03 const props = []
04
05 // 开启 while 循环,不断地消费模板内容,直至遇到标签的“结束部分”为止
06 while (
07 !context.source.startsWith('>') &&
08 !context.source.startsWith('/>')
09 ) {
10 // 解析属性或指令
11 }
12 // 将解析结果返回
13 return props
14 }
实际上,parseAttributes 函数消费模板内容的过程,就是不断地解析属性名称、等于号、属性值的过程,如下图所示:
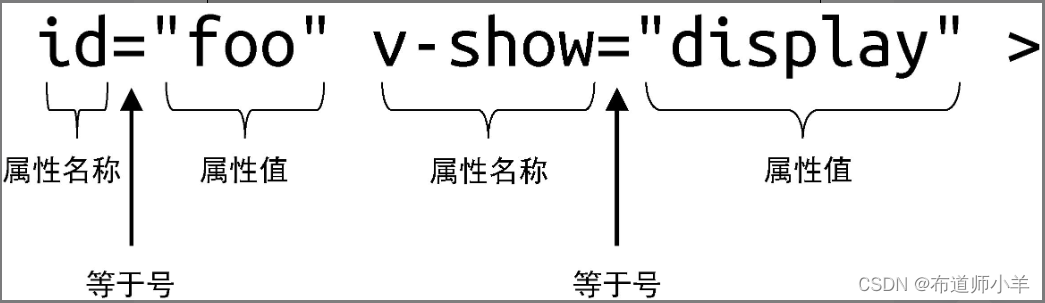
parseAttributes 函数会按照从左到右的顺序不断地消费字符串。以上图为例,该函数的解析过程如下:
首先,解析出第一个属性的名称 id,并消费字符串 ‘id’。此时剩余模板内容为:
01 ="foo" v-show="display" >
在解析属性名称时,除了要消费属性名称之外,还要消费属性名称后面可能存在的空白字符。如下面这段模板中,属性名称和等于号之间存在空白字符:
01 id = "foo" v-show="display" >
但无论如何,在属性名称解析完毕之后,模板剩余内容一定是以等于号开头的,即:
01 = "foo" v-show="display" >
如果消费属性名称之后,模板内容不以等于号开头,则说明模板内容不合法,我们可以选择性地抛出错误。
接着,我们需要消费等于号字符。由于等于号和属性值之间也可能存在空白字符,所以我们也需要消费对应的空白字符。在这一步操作过后,模板的剩余内容如下:
01 "foo" v-show="display" >
按照上述例子,此时模板的内容一定以双引号(”)开头。因此我们可以通过检查当前模板内容是否以引号开头来确定属性值是否被引用。如果属性值被引号引用,则消费引号。此时模板的剩余内容为:
01 foo" v-show="display" >
既然属性值被引号引用了,就意味着在剩余模板内容中,下一个引号之前的内容都应该被解析为属性值。在这个例子中,属性值的内容是字符串 foo。于是,我们消费属性值及其后面的引号。当然,如果属性值没有被引号引用,那么在剩余模板内容中,下一个空白字符之前的所有字符都应该作为属性值。
当属性值和引号被消费之后,由于属性值与下一个属性名称之间可能存在空白字符,所以我们还要消费对应的空白字符。在这一步处理过后,剩余模板内容为:
01 v-show="display" >
可以看到,经过上述操作之后,第一个属性就处理完毕了。
此时模板中还剩下一个指令,我们只需重新执行上述步骤,即可完成 v-show 指令的解析。当 v-show 指令解析完毕后,将会遇到标签的“结束部分”,即字符 >。这时,parseAttributes 函数中的 while 循环将会停止,完成属性和指令的解析。
下面的 parseAttributes 函数给出了上述逻辑的具体实现:
01 function parseAttributes(context) {
02 const { advanceBy, advanceSpaces } = context
03 const props = []
04
05 while (
06 !context.source.startsWith('>') &&
07 !context.source.startsWith('/>')
08 ) {
09 // 该正则用于匹配属性名称
10 const match = /^[^trnf />][^trnf />=]*/.exec(context.source)
11 // 得到属性名称
12 const name = match[0]
13
14 // 消费属性名称
15 advanceBy(name.length)
16 // 消费属性名称与等于号之间的空白字符
17 advanceSpaces()
18 // 消费等于号
19 advanceBy(1)
20 // 消费等于号与属性值之间的空白字符
21 advanceSpaces()
22
23 // 属性值
24 let value = ''
25
26 // 获取当前模板内容的第一个字符
27 const quote = context.source[0]
28 // 判断属性值是否被引号引用
29 const isQuoted = quote === '"' || quote === "'"
30
31 if (isQuoted) {
32 // 属性值被引号引用,消费引号
33 advanceBy(1)
34 // 获取下一个引号的索引
35 const endQuoteIndex = context.source.indexOf(quote)
36 if (endQuoteIndex > -1) {
37 // 获取下一个引号之前的内容作为属性值
38 value = context.source.slice(0, endQuoteIndex)
39 // 消费属性值
40 advanceBy(value.length)
41 // 消费引号
42 advanceBy(1)
43 } else {
44 // 缺少引号错误
45 console.error('缺少引号')
46 }
47 } else {
48 // 代码运行到这里,说明属性值没有被引号引用
49 // 下一个空白字符之前的内容全部作为属性值
50 const match = /^[^trnf >]+/.exec(context.source)
51 // 获取属性值
52 value = match[0]
53 // 消费属性值
54 advanceBy(value.length)
55 }
56 // 消费属性值后面的空白字符
57 advanceSpaces()
58
59 // 使用属性名称 + 属性值创建一个属性节点,添加到 props 数组中
60 props.push({
61 type: 'Attribute',
62 name,
63 value
64 })
65
66 }
67 // 返回
68 return props
69 }
在上面这段代码中,有两个重要的正则表达式:
我们分别来看看这两个正则表达式是如何工作的。下图给出了用于匹配属性名称的正则表达式的匹配原理:

如上图所示,我们可以将这个正则表达式分为 A、B 两个部分来看:
- 部分 A 用于匹配一个位置,这个位置不能是空白字符,也不能是字符 / 或字符 >,并且字符串要以该位置开头。
- 部分 B 则用于匹配 0 个或多个位置,这些位置不能是空白字符,也不能是字符 /、>、=。注意,这些位置不允许出现等于号(=)字符,这就实现了只匹配等于号之前的内容,即属性名称。
下图给出了第二个正则表达式的匹配原理:
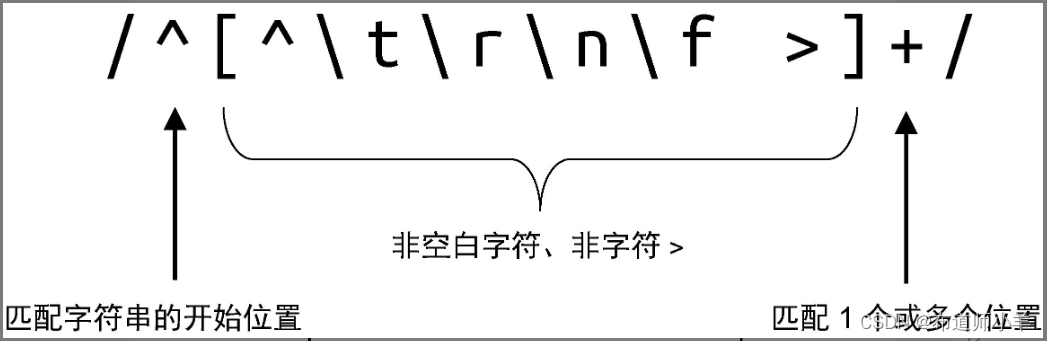
该正则表达式从字符串的开始位置进行匹配,并且会匹配一个或多个非空白字符、非字符 >。换句话说,该正则表达式会一直对字符串进行匹配,直到遇到空白字符或字符 > 为止,这就实现了属性值的提取。
配合 parseAttributes 函数,假设给出如下模板:
01 <div id="foo" v-show="display"></div>
解析上面这段模板,将会得到如下 AST:
01 const ast = {
02 type: 'Root',
03 children: [
04 {
05 type: 'Element'
06 tag: 'div',
07 props: [
08 // 属性
09 { type: 'Attribute', name: 'id', value: 'foo' },
10 { type: 'Attribute', name: 'v-show', value: 'display' }
11 ]
12 }
13 ]
14 }
可以看到,在 div 标签节点的 props 属性中,包含两个类型为Attribute 的节点,这两个节点就是 parseAttributes 函数的解析结果。
我们可以增加更多在 Vue.js 中常见的属性和指令进行测试,如以下模板所示:
01 <div :id="dynamicId" @click="handler" v-on:mousedown="onMouseDown" ></div>
上面这段模板经过解析后,得到如下 AST:
01 const ast = {
02 type: 'Root',
03 children: [
04 {
05 type: 'Element'
06 tag: 'div',
07 props: [
08 // 属性
09 { type: 'Attribute', name: ':id', value: 'dynamicId' },
10 { type: 'Attribute', name: '@click', value: 'handler' },
11 { type: 'Attribute', name: 'v-on:mousedown', value: 'onMouseDown' }
12 ]
13 }
14 ]
15 }
可以看到,在类型为 Attribute 的属性节点中,其 name 字段完整地保留着模板中编写的属性名称。我们可以对属性名称做进一步的分析,从而得到更具体的信息。例如,属性名称以字符 @ 开头,则认为它是一个 v-on 指令绑定。我们甚至可以把以 v- 开头的属性看作指令绑定,从而为它赋予不同的节点类型,例如:
01 // 指令,类型为 Directive
02 { type: 'Directive', name: 'v-on:mousedown', value: 'onMouseDown' }
03 { type: 'Directive', name: '@click', value: 'handler' }
04 // 普通属性
05 { type: 'Attribute', name: 'id', value: 'foo' }
不仅如此,为了得到更加具体的信息,我们甚至可以进一步分析指令节点的数据,也可以设计更多语法规则,这完全取决于框架设计者在语法层面的设计,以及为框架赋予的能力。
6、解析文本与解码 HTML 实体
6.1、解析文本
本节我们将讨论文本节点的解析。给出如下模板:
01 const template = '<div>Text</div>'
解析器在解析上面这段模板时,会先经过 parseTag 函数的处理,这会消费标签的开始部分 ‘
01 const template = 'Text</div>'
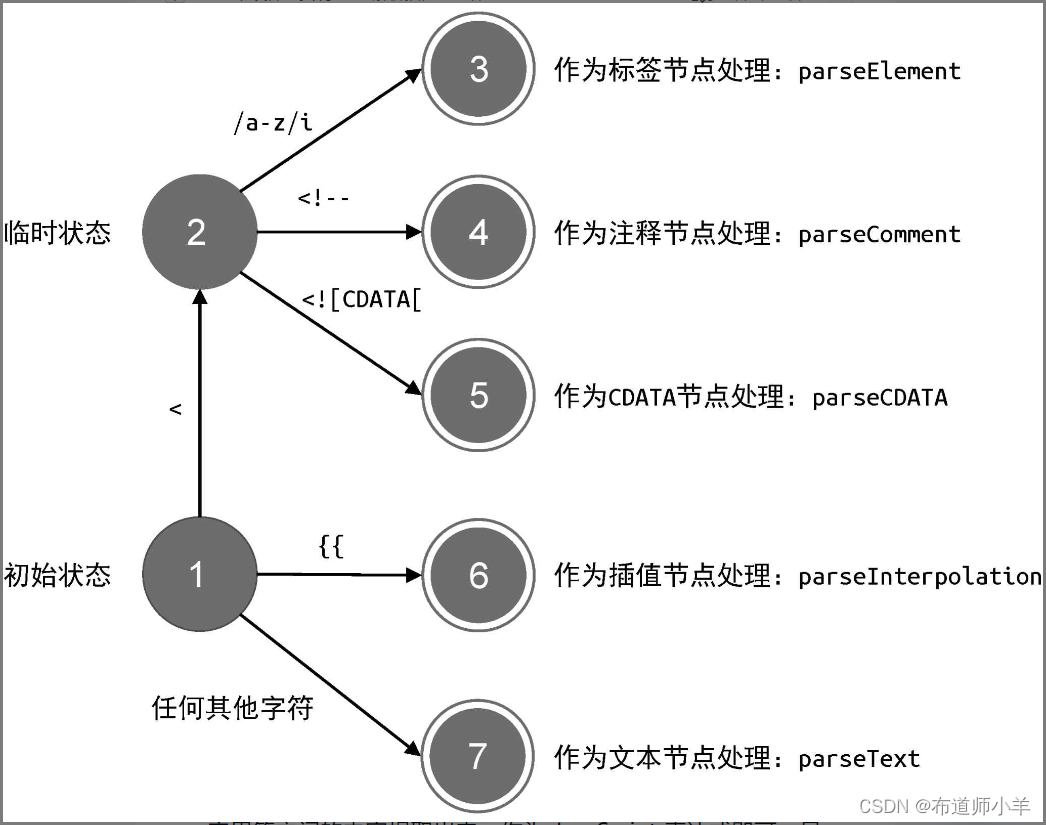
紧接着,解析器会调用 parseChildren 函数,开启一个新的状态机来处理这段模板。我们来回顾一下状态机的状态迁移过程,如下图所示:
状态机始于“状态 1”。在“状态 1”下,读取模板的第一个字符 T,由于该字符既不是字符 <,也不是插值定界符 {{,因此状态机会进入“状态 7”,即调用 parseText 函数处理文本内容。此时解析器会在模板中寻找下一个 < 字符或插值定界符 {{的位置索引,记为索引 I。然后,解析器会从模板的头部到索引I 的位置截取内容,这段截取出来的字符串将作为文本节点的内容。以下面的模板内容为例:
01 const template = 'Text</div>'
parseText 函数会尝试在这段模板内容中找到第一个出现的字符< 的位置索引。在这个例子中,字符 < 的索引值为 4。然后,parseText 函数会截取介于索引 [0, 4) 的内容作为文本内容。在这个例子中,文本内容就是字符串 ‘Text’。
假设模板中存在插值,如下面的模板所示:
01 const template = 'Text-{{ val }}</div>'
在处理这段模板时,parseText 函数会找到第一个插值定界符 {{出现的位置索引。在这个例子中,定界符的索引为 5。于是,parseText 函数会截取介于索引 [0, 5) 的内容作为文本内容。在这个例子中,文本内容就是字符串 ‘Text-’。
下面的 parseText 函数给出了具体实现:
01 function parseText(context) {
02 // endIndex 为文本内容的结尾索引,默认将整个模板剩余内容都作为文本内容
03 let endIndex = context.source.length
04 // 寻找字符 < 的位置索引
05 const ltIndex = context.source.indexOf('<')
06 // 寻找定界符 {{ 的位置索引
07 const delimiterIndex = context.source.indexOf('{{')
08
09 // 取 ltIndex 和当前 endIndex 中较小的一个作为新的结尾索引
10 if (ltIndex > -1 && ltIndex < endIndex) {
11 endIndex = ltIndex
12 }
13 // 取 delimiterIndex 和当前 endIndex 中较小的一个作为新的结尾索引
14 if (delimiterIndex > -1 && delimiterIndex < endIndex) {
15 endIndex = delimiterIndex
16 }
17
18 // 此时 endIndex 是最终的文本内容的结尾索引,调用 slice 函数截取文本内容
19 const content = context.source.slice(0, endIndex)
20 // 消耗文本内容
21 context.advanceBy(content.length)
22
23 // 返回文本节点
24 return {
25 // 节点类型
26 type: 'Text',
27 // 文本内容
28 content
29 }
30 }
如上面的代码所示,由于字符 < 与定界符 {{ 的出现顺序是未知的,所以我们需要取两者中较小的一个作为文本截取的终点。有了截取终点后,只需要调用字符串的 slice 函数对字符串进行截取即可,截取出来的内容就是文本节点的文本内容。最后,我们创建一个类型为 Text 的文本节点,将其作为 parseText 函数的返回值。
配合上述 parseText 函数解析如下模板:
01 const ast = parse(`<div>Text</div>`)
得到如下 AST:
01 const ast = {
02 type: 'Root',
03 children: [
04 {
05 type: 'Element',
06 tag: 'div',
07 props: [],
08 isSelfClosing: false,
09 children: [
10 // 文本节点
11 { type: 'Text', content: 'Text' }
12 ]
13 }
14 ]
15 }
这样,我们就实现了对文本节点的解析。解析文本节点本身并不复杂,复杂点在于,我们需要对解析后的文本内容进行HTML 实体的解码工作。为此,我们有必要先了解什么是HTML 实体。
6.2、解码命名字符引用
HTML 实体是一段以字符 & 开始的文本内容。实体用来描述HTML 中的保留字符和一些难以通过普通键盘输入的字符,以及一些不可见的字符。例如,在 HTML 中,字符 < 具有特殊含义,如果希望以普通文本的方式来显示字符 <,需要通过实体来表达:
01 <div>A<B</div>
其中字符串 < 就是一个 HTML 实体,用来表示字符 <。如果我们不用 HTML 实体,而是直接使用字符 <,那么将会产生非法的 HTML 内容:
01 <div>A<B</div>
这会导致浏览器的解析结果不符合预期。
HTML 实体总是以字符 & 开头,以字符 ; 结尾。在 Web 诞生的初期,HTML 实体的数量较少,因此允许省略其中的尾分号。但随着 HTML 字符集越来越大,HTML 实体出现了包含的情况,例如 < 和 <cc 都是合法的实体,如果不加分号,浏览器将无法区分它们。因此,WHATWG 规范中明确规定,如果不为实体加分号,将会产生解析错误。但考虑到历史原因(互联网上存在大量省略分号的情况),现代浏览器都能够解析早期规范中定义的那些可以省略分号的 HTML 实体。
HTML 实体有两类,一类叫作命名字符引用(named character reference),也叫命名实体(named entity),顾名思义,这类实体具有特定的名称,例如上文中的 <。WHATWG 规范中给出了全部的命名字符引用,有 2000 多个,可以通过命名字符引用表查询。下面列出了部分内容:
01 // 共 2000+
02 {
03 "GT": ">",
04 "gt": ">",
05 "LT": "<",
06 "lt": "<",
07 // 省略部分代码
08 "awint;": "⨑",
09 "bcong;": "≌",
10 "bdquo;": "„",
11 "bepsi;": "϶",
12 "blank;": "␣",
13 "blk12;": "▒",
14 "blk14;": "░",
15 "blk34;": "▓",
16 "block;": "█",
17 "boxDL;": "╗",
18 "boxDl;": "╖",
19 "boxdL;": "╕",
20 // 省略部分代码
21 }
除了命名字符引用之外,还有一类字符引用没有特定的名称,只能用数字表示,这类实体叫作数字字符引用(numeric character reference)。与命名字符引用不同,数字字符引用以字符串 &# 开头,比命名字符引用的开头部分多出了字符#,例如 <。实际上,< 对应的字符也是 <,换句话说,< 与 < 是等价的。数字字符引用既可以用十进制来表示,也可以使用十六进制来表示。例如,十进制数字 60 对应的十六进制值为 3c,因此实体 < 也可以表示为 <。可以看到,当使用十六进制数表示实体时,需要以字符串 &#x 开头。
理解了 HTML 实体后,我们再来讨论为什么 Vue.js 模板的解析器要对文本节点中的 HTML 实体进行解码。为了理解这个问题,我们需要先明白一个大前提:在 Vue.js 模板中,文本节点所包含的 HTML 实体不会被浏览器解析。这是因为模板中的文本节点最终将通过如 el.textContent 等文本操作方法设置到页面,而通过 el.textContent 设置的文本内容是不会经过 HTML 实体解码的,例如:
01 el.textContent = '<'
最终 el 的文本内容将会原封不动地呈现为字符串 ‘<',而不会呈现字符 <。这就意味着,如果用户在 Vue.js 模板中编写了HTML 实体,而模板解析器不对其进行解码,那么最终渲染到页面的内容将不符合用户的预期。因此,我们应该在解析阶段对文本节点中存在的 HTML 实体进行解码。
模板解析器的解码行为应该与浏览器的行为一致。因此,我们应该按照 WHATWG 规范实现解码逻辑。规范中明确定义了解码 HTML 实体时状态机的状态迁移流程。下图给出了简化版的状态迁移流程,我们会在后文中对其进行补充:
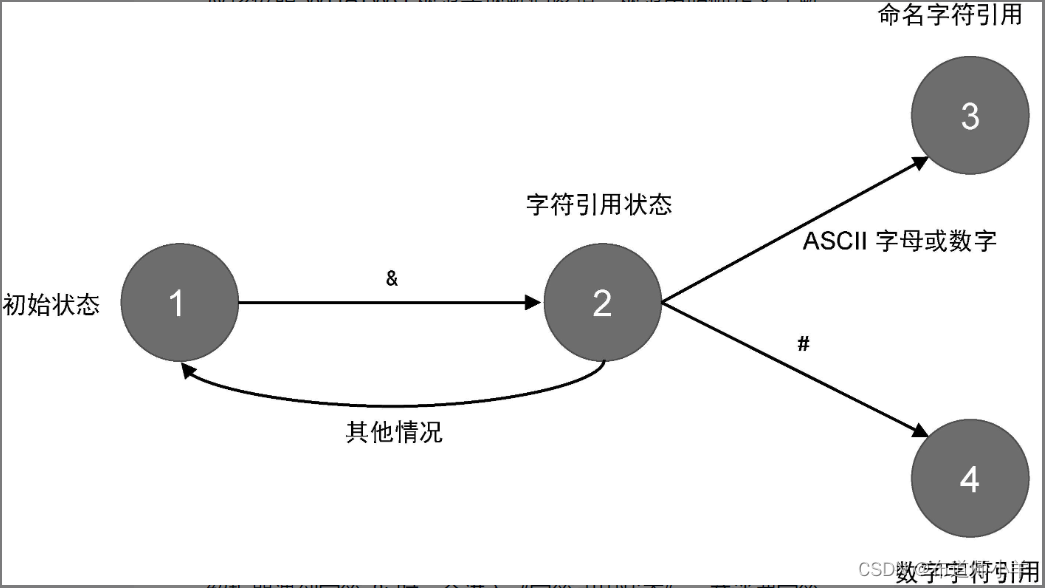
假定状态机当前处于初始的 DATA 模式。由上图可知,当解析器遇到字符 & 时,会进入“字符引用状态”,并消费字符&,接着解析下一个字符。如果下一个字符是 ASCII 字母或数字(ASCII alphanumeric),则进入“命名字符引用状态”,其中 ASCII 字母或数字指的是 0~9 这十个数字以及字符集合a~z 再加上字符集合 A~Z。当然,如果下一个字符是 #,则进入“数字字符引用状态”。
一旦状态机进入命名字符引用状态,解析器将会执行比较复杂的匹配流程。我们通过几个例子来直观地感受一下这个过程。假设文本内容为:
01 a<b
上面这段文本会被解析为:
01 a<b
为什么会得到这样的解析结果呢?接下来,我们分析整个解析过程:
- 首先,当解析器遇到字符 & 时,会进入字符引用状态。接着,解析下一个字符 l,这会使得解析器进入命名字符引用状态,并在命名字符引用表(后文简称“引用表”)中查找以字符 l 开头的项。由于引用表中存在诸多以字符 l 开头的项,例如lt、lg、le 等,因此解析器认为此时是“匹配”的。
- 于是开始解析下一个字符 t,并尝试去引用表中查找以 lt 开头的项。由于引用表中也存在多个以 lt 开头的项,例如 lt、ltcc;、ltri; 等,因此解析器认为此时也是“匹配”的。
- 于是又开始解析下一个字符 b,并尝试去引用表中查找以 ltb 开头的项,结果发现引用表中不存在符合条件的项,至此匹配结束。
当匹配结束时,解析器会检查最后一个匹配的字符。如果该字符是分号(;),则会产生一个合法的匹配,并渲染对应字符。但在上例中,最后一个匹配的字符是字符 t,并不是分号(;),因此会产生一个解析错误,但由于历史原因,浏览器仍然能够解析它。在这种情况下,浏览器的解析规则是:最短原则。其中“最短”指的是命名字符引用的名称最短。举个例子,假设文本内容为:
01 a⪦
我们知道 ⪦ 是一个合法的命名字符引用,因此上述文本会被渲染为:a⪦。但如果去掉上述文本中的分号,即:
01 a<cc
解析器在处理这段文本中的实体时,最后匹配的字符将不再是分号,而是字符 c。按照“最短原则”,解析器只会渲染名称更短的字符引用。在字符串 <cc 中,< 的名称要短于 <cc,因此最终会将 < 作为合法的字符引用来渲染,而字符串 cc 将作为普通字符来渲染。所以上面的文本最终会被渲染为:a<cc。
需要说明的是,上述解析过程仅限于不用作属性值的普通文本。换句话说,用作属性值的文本会有不同的解析规则。举例来说,给出如下 HTML 文本:
01 <a href="foo.com?a=1<=2">foo.com?a=1<=2</a>
可以看到,a 标签的 href 属性值与它的文本子节点具有同样的内容,但它们被解析之后的结果不同。其中属性值中出现的 < 将原封不动地展示,而文本子节点中出现的 < 将会被解析为字符 <。这也是符合期望的,很明显,<=2 将构成链接中的查询参数,如果将其中的 < 解码为字符 <,将会破坏用户的URL。实际上,WHATWG 规范中对此也有完整的定义,出于历史原因的考虑,对于属性值中的字符引用,如果最后一个匹配的字符不是分号,并且该匹配的字符的下一个字符是等于号、ASCII 字母或数字,那么该匹配项将作为普通文本被解析。
明白了原理,我们就着手实现。我们面临的第一个问题是,如何处理省略分号的情况?关于字符引用中的分号,我们可以总结如下:
- 当存在分号时:执行完整匹配。
- 当省略分号时:执行最短匹配。
为此,我们需要精心设计命名字符引用表。由于命名字符引用的数量非常多,因此这里我们只取其中一部分作为命名字符引用表的内容,如下面的代码所示:
01 const namedCharacterReferences = {
02 "gt": ">",
03 "gt;": ">",
04 "lt": "<",
05 "lt;": "<",
06 "ltcc;": "⪦"
07 }
上面这张表是经过精心设计的。观察namedCharacterReferences 对象可以发现,相同的字符对应的实体会有多个,即带分号的版本和不带分号的版本,例如”gt” 和 “gt;”。另外一些实体则只有带分号的版本,因为这些实体不允许省略分号,例如 “ltcc;”。我们可以根据这张表来实现实体的解码逻辑。假设我们有如下文本内容:
01 a<ccbbb
在解码这段文本时,我们首先根据字符 & 将文本分为两部分:
- 一部分是普通文本:a。
- 另一部分则是:<ccbbb。
对于普通文本部分,由于它不需要被解码,因此索引原封不动地保留。而对于可能是字符引用的部分,执行解码工作:
- 第一步:计算出命名字符引用表中实体名称的最大长度。由于在 namedCharacterReferences 对象中,名称最长的实体是ltcc;,它具有 5 个字符,因此最大长度是 5。
- 第二步:根据最大长度截取字符串 ltccbbb,即’ltccbbb’.slice(0, 5),最终结果是:‘ltccb’
- 第三步:用截取后的字符串 ‘ltccb’ 作为键去命名字符引用表中查询对应的值,即解码。由于引用表namedCharacterReferences 中不存在键值为 ‘ltccb’ 的项,因此不匹配。
- 第四步:当发现不匹配时,我们将最大长度减 1,并重新执行第二步,直到找到匹配项为止。在上面这个例子中,最终的匹配项将会是 ‘lt’。因此,上述文本最终会被解码为:
01 a<ccbbb
这样,我们就实现了当字符引用省略分号时按照“最短原则”进行解码。
01 // 第一个参数为要被解码的文本内容
02 // 第二个参数是一个布尔值,代表文本内容是否作为属性值
03 function decodeHtml(rawText, asAttr = false) {
04 let offset = 0
05 const end = rawText.length
06 // 经过解码后的文本将作为返回值被返回
07 let decodedText = ''
08 // 引用表中实体名称的最大长度
09 let maxCRNameLength = 0
10
11 // advance 函数用于消费指定长度的文本
12 function advance(length) {
13 offset += length
14 rawText = rawText.slice(length)
15 }
16
17 // 消费字符串,直到处理完毕为止
18 while (offset < end) {
19 // 用于匹配字符引用的开始部分,如果匹配成功,那么 head[0] 的值将有三种可能:
20 // 1. head[0] === '&',这说明该字符引用是命名字符引用
21 // 2. head[0] === '&#',这说明该字符引用是用十进制表示的数字字符引用
22 // 3. head[0] === '&#x',这说明该字符引用是用十六进制表示的数字字符引用
23 const head = /&(?:#x?)?/i.exec(rawText)
24 // 如果没有匹配,说明已经没有需要解码的内容了
25 if (!head) {
26 // 计算剩余内容的长度
27 const remaining = end - offset
28 // 将剩余内容加到 decodedText 上
29 decodedText += rawText.slice(0, remaining)
30 // 消费剩余内容
31 advance(remaining)
32 break
33 }
34
35 // head.index 为匹配的字符 & 在 rawText 中的位置索引
36 // 截取字符 & 之前的内容加到 decodedText 上
37 decodedText += rawText.slice(0, head.index)
38 // 消费字符 & 之前的内容
39 advance(head.index)
40
41 // 如果满足条件,则说明是命名字符引用,否则为数字字符引用
42 if (head[0] === '&') {
43 let name = ''
44 let value
45 // 字符 & 的下一个字符必须是 ASCII 字母或数字,这样才是合法的命名字符引用
46 if (/[0-9a-z]/i.test(rawText[1])) {
47 // 根据引用表计算实体名称的最大长度,
48 if (!maxCRNameLength) {
49 maxCRNameLength = Object.keys(namedCharacterReferences).reduce(
50 (max, name) => Math.max(max, name.length),
51 0
52 )
53 }
54 // 从最大长度开始对文本进行截取,并试图去引用表中找到对应的项
55 for (let length = maxCRNameLength; !value && length > 0; --length) {
56 // 截取字符 & 到最大长度之间的字符作为实体名称
57 name = rawText.substr(1, length)
58 // 使用实体名称去索引表中查找对应项的值
59 value = (namedCharacterReferences)[name]
60 }
61 // 如果找到了对应项的值,说明解码成功
62 if (value) {
63 // 检查实体名称的最后一个匹配字符是否是分号
64 const semi = name.endsWith(';')
65 // 如果解码的文本作为属性值,最后一个匹配的字符不是分号,
66 // 并且最后一个匹配字符的下一个字符是等于号(=)、ASCII 字母或数字,
67 // 由于历史原因,将字符 & 和实体名称 name 作为普通文本
68 if (
69 asAttr &&
70 !semi &&
71 /[=a-z0-9]/i.test(rawText[name.length + 1] || '')
72 ) {
73 decodedText += '&' + name
74 advance(1 + name.length)
75 } else {
76 // 其他情况下,正常使用解码后的内容拼接到 decodedText 上
77 decodedText += value
78 advance(1 + name.length)
79 }
80 } else {
81 // 如果没有找到对应的值,说明解码失败
82 decodedText += '&' + name
83 advance(1 + name.length)
84 }
85 } else {
86 // 如果字符 & 的下一个字符不是 ASCII 字母或数字,则将字符 & 作为普通文本
87 decodedText += '&'
88 advance(1)
89 }
90 }
91 }
92 return decodedText
93 }
有了 decodeHtml 函数之后,我们就可以在解析文本节点时通过它对文本内容进行解码:
01 function parseText(context) {
02 // 省略部分代码
03
04 return {
05 type: 'Text',
06 content: decodeHtml(content) // 调用 decodeHtml 函数解码内容
07 }
08 }
6.3、解码数字字符引用
在上一节中,我们使用下面的正则表达式来匹配一个文本中字符引用的开始部分:
01 const head = /&(?:#x?)?/i.exec(rawText)
我们可以根据该正则的匹配结果,来判断字符引用的类型:
-如果 head[0] === '&',则说明匹配的是命名字符引用。●如果 head[0] === '&#',则说明匹配的是以十进制表示的数字字符引用。
-如果 head[0] === '&#x',则说明匹配的是以十六进制表示的数字字符引用。
- 如果
head[0] === '&#x’,则说明匹配的是以十六进制表示的数字字符引用。
数字字符引用的格式是:前缀 + Unicode 码点。解码数字字符引用的关键在于,如何提取字符引用中的 Unicode 码点。考虑到数字字符引用的前缀可以是以十进制表示(&#),也可以是以十六进制表示(&#x),所以我们使用下面的代码来完成码点的提取:
01 // 判断是以十进制表示还是以十六进制表示
02 const hex = head[0] === '&#x'
03 // 根据不同进制表示法,选用不同的正则
04 const pattern = hex ? /^&#x([0-9a-f]+);?/i : /^&#([0-9]+);?/
05 // 最终,body[1] 的值就是 Unicode 码点
06 const body = pattern.exec(rawText)
有了 Unicode 码点之后,只需要调用 String.fromCodePoint 函数即可将其解码为对应的字符:
01 if (body) {
02 // 根据对应的进制,将码点字符串转换为数字
03 const cp = parseInt(body[1], hex ? 16 : 10)
04 // 解码
05 const char = String.fromCodePoint(cp)
06 }
不过,在真正进行解码前,需要对码点的值进行合法性检查。WHATWG 规范中对此也有明确的定义:
- 如果码点值为 0x00,即十进制的数字 0,它在 Unicode 中代表空字符(NULL),这将是一个解析错误,解析器会将码点值替换为 0xFFFD。
- 如果码点值大于 0x10FFFF(0x10FFFF 为 Unicode 的最大值),这也是一个解析错误,解析器会将码点值替换为0xFFFD。
- 如果码点值处于代理对(surrogate pair)范围内,这也是一个解析错误,解析器会将码点值替换为 0xFFFD,其中surrogate pair 是预留给 UTF-16 的码位,其范围是:[0xD800, 0xDFFF]。
- 如果码点值是 noncharacter,这也是一个解析错误,但什么都不需要做。这里的 noncharacter 代表 Unicode 永久保留的码点,用于 Unicode 内部,它的取值范围是:[0xFDD0,0xFDEF],还包括:0xFFFE、0xFFFF、0x1FFFE、0x1FFFF、0x2FFFE、0x2FFFF、0x3FFFE、0x3FFFF、0x4FFFE、0x4FFFF、0x5FFFE、0x5FFFF、0x6FFFE、0x6FFFF、0x7FFFE、0x7FFFF、0x8FFFE、0x8FFFF、0x9FFFE、0x9FFFF、0xAFFFE、0xAFFFF、0xBFFFE、0xBFFFF、0xCFFFE、0xCFFFF、0xDFFFE、0xDFFFF、0xEFFFE、0xEFFFF、0xFFFFE、0xFFFFF、0x10FFFE、0x10FFFF。
如果码点值对应的字符是回车符(0x0D),或者码点值为控制字符集(control character)中的非 ASCII 空白符(ASCII whitespace),则是一个解析错误。这时需要将码点作为索引,在下表中查找对应的替换码点:
01 const CCR_REPLACEMENTS = {
02 0x80: 0x20ac,
03 0x82: 0x201a,
04 0x83: 0x0192,
05 0x84: 0x201e,
06 0x85: 0x2026,
07 0x86: 0x2020,
08 0x87: 0x2021,
09 0x88: 0x02c6,
10 0x89: 0x2030,
11 0x8a: 0x0160,
12 0x8b: 0x2039,
13 0x8c: 0x0152,
14 0x8e: 0x017d,
15 0x91: 0x2018,
16 0x92: 0x2019,
17 0x93: 0x201c,
18 0x94: 0x201d,
19 0x95: 0x2022,
20 0x96: 0x2013,
21 0x97: 0x2014,
22 0x98: 0x02dc,
23 0x99: 0x2122,
24 0x9a: 0x0161,
25 0x9b: 0x203a,
26 0x9c: 0x0153,
27 0x9e: 0x017e,
28 0x9f: 0x0178
29 }
如果存在对应的替换码点,则渲染该替换码点对应的字符,否则直接渲染原码点对应的字符。
上述关于码点合法性检查的具体实现如下:
01 if (body) {
02 // 根据对应的进制,将码点字符串转换为数字
03 const cp = parseInt(body[1], hex ? 16 : 10)
04 // 检查码点的合法性
05 if (cp === 0) {
06 // 如果码点值为 0x00,替换为 0xfffd
07 cp = 0xfffd
08 } else if (cp > 0x10ffff) {
09 // 如果码点值超过 Unicode 的最大值,替换为 0xfffd
10 cp = 0xfffd
11 } else if (cp >= 0xd800 && cp <= 0xdfff) {
12 // 如果码点值处于 surrogate pair 范围内,替换为 0xfffd
13 cp = 0xfffd
14 } else if ((cp >= 0xfdd0 && cp <= 0xfdef) || (cp & 0xfffe) === 0xfffe) {
15 // 如果码点值处于 noncharacter 范围内,则什么都不做,交给平台处理
16 // noop
17 } else if (
18 // 控制字符集的范围是:[0x01, 0x1f] 加上 [0x7f, 0x9f]
19 // 去掉 ASICC 空白符:0x09(TAB)、0x0A(LF)、0x0C(FF)
20 // 0x0D(CR) 虽然也是 ASICC 空白符,但需要包含
21 (cp >= 0x01 && cp <= 0x08) ||
22 cp === 0x0b ||
23 (cp >= 0x0d && cp <= 0x1f) ||
24 (cp >= 0x7f && cp <= 0x9f)
25 ) {
26 // 在 CCR_REPLACEMENTS 表中查找替换码点,如果找不到,则使用原码点
27 cp = CCR_REPLACEMENTS[cp] || cp
28 }
29 // 最后进行解码
30 const char = String.fromCodePoint(cp)
31 }
在上面这段代码中,我们完整地还原了码点合法性检查的逻辑,它有如下几个关键点:
- 其中控制字符集(control character)的码点范围是:[0x01,0x1f] 和 [0x7f, 0x9f]。这个码点范围包含了 ASCII 空白符:0x09(TAB)、0x0A(LF)、0x0C(FF) 和 0x0D(CR),但WHATWG 规范中要求包含 0x0D(CR)。
- 码点 0xfffd 对应的符号是 �。你一定在出现“乱码”的情况下见过这个字符,它是 Unicode 中的替换字符,通常表示在解码过程中出现“错误”,例如使用了错误的解码方式等。
最后,我们将上述代码整合到 decodeHtml 函数中,这样就实现一个完善的 HTML 文本解码函数:
01 function decodeHtml(rawText, asAttr = false) {
02 // 省略部分代码
03
04 // 消费字符串,直到处理完毕为止
05 while (offset < end) {
06 // 省略部分代码
07
08 // 如果满足条件,则说明是命名字符引用,否则为数字字符引用
09 if (head[0] === '&') {
10 // 省略部分代码
11 } else {
12 // 判断是十进制表示还是十六进制表示
13 const hex = head[0] === '&#x'
14 // 根据不同进制表示法,选用不同的正则
15 const pattern = hex ? /^&#x([0-9a-f]+);?/i : /^&#([0-9]+);?/
16 // 最终,body[1] 的值就是 Unicode 码点
17 const body = pattern.exec(rawText)
18
19 // 如果匹配成功,则调用 String.fromCodePoint 函数进行解码
20 if (body) {
21 // 根据对应的进制,将码点字符串转换为数字
22 const cp = Number.parseInt(body[1], hex ? 16 : 10)
23 // 码点的合法性检查
24 if (cp === 0) {
25 // 如果码点值为 0x00,替换为 0xfffd
26 cp = 0xfffd
27 } else if (cp > 0x10ffff) {
28 // 如果码点值超过 Unicode 的最大值,替换为 0xfffd
29 cp = 0xfffd
30 } else if (cp >= 0xd800 && cp <= 0xdfff) {
31 // 如果码点值处于 surrogate pair 范围内,替换为 0xfffd
32 cp = 0xfffd
33 } else if ((cp >= 0xfdd0 && cp <= 0xfdef) || (cp & 0xfffe) === 0xfffe) {
34 // 如果码点值处于 noncharacter 范围内,则什么都不做,交给平台处理
35 // noop
36 } else if (
37 // 控制字符集的范围是:[0x01, 0x1f] 加上 [0x7f, 0x9f]
38 // 去掉 ASICC 空白符:0x09(TAB)、0x0A(LF)、0x0C(FF)
39 // 0x0D(CR) 虽然也是 ASICC 空白符,但需要包含
40 (cp >= 0x01 && cp <= 0x08) ||
41 cp === 0x0b ||
42 (cp >= 0x0d && cp <= 0x1f) ||
43 (cp >= 0x7f && cp <= 0x9f)
44 ) {
45 // 在 CCR_REPLACEMENTS 表中查找替换码点,如果找不到,则使用原码点
46 cp = CCR_REPLACEMENTS[cp] || cp
47 }
48 // 解码后追加到 decodedText 上
49 decodedText += String.fromCodePoint(cp)
50 // 消费整个数字字符引用的内容
51 advance(body[0].length)
52 } else {
53 // 如果没有匹配,则不进行解码操作,只是把 head[0] 追加到 decodedText 上并消费
54 decodedText += head[0]
55 advance(head[0].length)
56 }
57 }
58 }
59 return decodedText
60 }
7、解析插值与注释
文本插值是 Vue.js 模板中用来渲染动态数据的常用方法:
01 {{ count }}
默认情况下,插值以字符串 {{ 开头,并以字符串 }} 结尾。我们通常将这两个特殊的字符串称为定界符。定界符中间的内容可以是任意合法的 JavaScript 表达式,例如:
01 {{ obj.foo }}
或
01 {{ obj.fn() }}
解析器在遇到文本插值的起始定界符({{)时,会进入文本“插值状态 6”,并调用 parseInterpolation 函数来解析插值内容,如下图所示:
解析器在解析插值时,只需要将文本插值的开始定界符与结束定界符之间的内容提取出来,作为 JavaScript 表达式即可,具体实现如下:
01 function parseInterpolation(context) {
02 // 消费开始定界符
03 context.advanceBy('{{'.length)
04 // 找到结束定界符的位置索引
05 closeIndex = context.source.indexOf('}}')
06 if (closeIndex < 0) {
07 console.error('插值缺少结束定界符')
08 }
09 // 截取开始定界符与结束定界符之间的内容作为插值表达式
10 const content = context.source.slice(0, closeIndex)
11 // 消费表达式的内容
12 context.advanceBy(content.length)
13 // 消费结束定界符
14 context.advanceBy('}}'.length)
15
16 // 返回类型为 Interpolation 的节点,代表插值节点
17 return {
18 type: 'Interpolation',
19 // 插值节点的 content 是一个类型为 Expression 的表达式节点
20 content: {
21 type: 'Expression',
22 // 表达式节点的内容则是经过 HTML 解码后的插值表达式
23 content: decodeHtml(content)
24 }
25 }
26 }
配合上面的 parseInterpolation 函数,解析如下模板内容:
01 const ast = parse(`<div>foo {{ bar }} baz</div>`)
最终将得到如下 AST:
01 const ast = {
02 type: 'Root',
03 children: [
04 {
05 type: 'Element',
06 tag: 'div',
07 isSelfClosing: false,
08 props: [],
09 children: [
10 { type: 'Text', content: 'foo ' },
11 // 插值节点
12 {
13 type: 'Interpolation',
14 content: [
15 type: 'Expression',
16 content: ' bar '
17 ]
18 },
19 { type: 'Text', content: ' baz' }
20 ]
21 }
22 ]
23 }
解析注释的思路与解析插值非常相似,如下面的parseComment 函数所示:
01 function parseComment(context) {
02 // 消费注释的开始部分
03 context.advanceBy('<!--'.length)
04 // 找到注释结束部分的位置索引
05 closeIndex = context.source.indexOf('-->')
06 // 截取注释节点的内容
07 const content = context.source.slice(0, closeIndex)
08 // 消费内容
09 context.advanceBy(content.length)
10 // 消费注释的结束部分
11 context.advanceBy('-->'.length)
12 // 返回类型为 Comment 的节点
13 return {
14 type: 'Comment',
15 content
16 }
17 }
配合 parseComment 函数,解析如下模板内容:
01 const ast = parse(`<div><!-- comments --></div>`)
最终得到如下 AST:
01 const ast = {
02 type: 'Root',
03 children: [
04 {
05 type: 'Element',
06 tag: 'div',
07 isSelfClosing: false,
08 props: [],
09 children: [
10 { type: 'Comment', content: ' comments ' }
11 ]
12 }
13 ]
14 }
原文地址:https://blog.csdn.net/YYBDESHIJIE/article/details/134600500
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_16609.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!