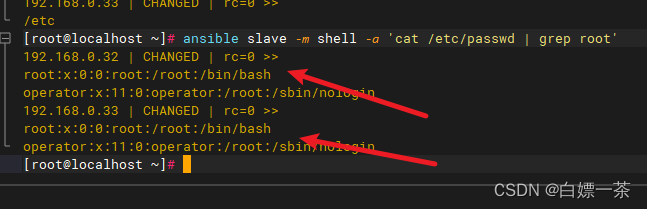
硬件、核心与 Shell
操作系统其实是一组软件,由于这组软件在控制整个硬件与管理系统的活动监测,如果这组软件能被用户随意的操作,若使用者应用不当,将会使得整个系统崩溃。因为操作系统管理的就是整个硬件功能。
应用程序在最外层,使得用户可以操作系统,称呼为 shell。只要能够操作应用程序的接口都能够称为 shell 程序。
shell 程序的功能只是提供用户操作系统的一个接口,因此这个shell程序需要可以呼叫其他软件才好。
Linux 的管理常常需要透过远程联机,而联机时文字接口的传输速度一定比较快,而且,较不容易出现断线或者是信息外流的问题。
Linux 使用的 shell 版本称为 Bourne Again SHell(简称 bash),是Bourne Shell(sh)的增强版本,也是基准于GNU的架构下发展出来的。
Bash shell 的功能
1.命令编修能力(history):
能记忆使用过的指令。
使用【上下键】就可以找到前后输入的一个指令。在很多 distribution 中,默认的指令记忆功能可达 1000 个。
记录在家目录内的 .bash_history。
~/.bash_history 记录的是前一次登入以前所执行过的指令,而至于这一次登入所执行的指令都被暂存在内存中,当你成功的注销系统后,该指令记忆才会记录到.bash_history当中。
2.命令与文件补全功能:([tab] 按键的好处)
[Tab]接在一串指令的第一个字的后面,则为【命令补全】;
[Tab]接在一串指令的第二个字以后时,则为【文件补齐】;
若安装 bash–completion 软件,则在某些指令后面使用 [tab] 按键时,可以进行【选项/参数的补齐】功能。
3.命令别名设定功能
可以在指令列输入alias 就可以知道目前的命令别名有哪些;
也可以直接下达命令来设定别名。
alias lm='ls -al'
4.工程控制、前景背景控制:(job control,foreground,background)
后面学。。。。
可以将平时管理系统常需要下达的连续指令写成一个文件,该文件并且可以透过对谈交互式的方式来进行主机的侦测工作。也可以由 shell 提供的环境变量及相关指令来进行设计。
6.通配符
除了完整的字符串之外, bash 还支持许多的通配符来帮助用户查询与指令下达。
举例来说,想要知道/usr/bin底下有多少以X为开头的文件;使用:ls -l/usr/bin/X*就能够知道。
查询指令是否为 Bash shell 的内建命令:type
查询指令是来自于外部指令(指的是其他非 bash所提供的指令)或是内建在 bash 当中。
type [-tpa] name


指令的下达与快速编辑按钮
【[Enter]】表示换行的功能, 让 [Enter] 不再具有开始执行的功能
| 组合键 | 说明 |
|---|---|
| [ctrl]+u/[ctrl]+k | 分别是从光标处向前删除指令串 ([ctrI]+u)及向后删除指令串 ([ctrl]+k)。 |
| [ctrl]+a/[ctrl]+e | 分别是让光标移动到整个指令串的最前面([ctrl]+a)或最后面([ctrl]+e)。 |
Shell 的变量功能
某些特定变量会影响到 bash 的环境。
在 Linux System下面,所有的线程都是需要一个执行码,真正以 shell 来跟 Linux 沟通,是在正确的登入Linux之后,这个时候就有一个 bash 的执行程序,也才可以真正的经由 bash 来跟系统沟通。而在进入 shell 之前,由于系统需要一些变量来提供他数据的存取(或者是一些环境的设定参数值),所以就有一些所谓的【环境变量】需要来读入系统中了。
这些【环境变量】例如 PATH、HOME、MAIL、SHELL等等,都是很重要的,为了区别与自定义变量的不同,环境变量通常以大写字符来表示。
变量就是以一组文字或符号等,来取代一些设定或者是一串保留的数据
变量的取用与设定: echo,变量设定规则, unset
变量的取用:echo ,在变量名称前面加上 $ 或以 ${变量} 的方式来取用。

修改:用等号 【=】来接与它的内容

在 bash 当中,当一个变量名称尚未被设定时,预设的内容是【空】的。
变量的设定规则
1.变量与变量内容以一个等号【=】来连结;
2.等号两边不能直接接空格符;
3.变量名称只能是英文字母与数字,但是开头字符不能是数字;
4.变量内容若有空格符可使用双引号【 " 】或单引号【'】将变量内容结合起来,但
双引号内的特殊字符如$等,可以保有原本的特性,如【var=" lang is $LANG"】则【echo $var】可得【lang is zh_TW.UTF-8】;
单引号内的特殊字符则仅为一般字符(纯文本),如【var='lang is $LANG'】则【echo $var】可得【lang is $LANG】;
5.可用跳脱字符【】将特殊符号(如[Enter],$,,空格符, '等)变成一般字符。
6.在一串指令的执行中,还需要由其他额外的指令所提供的信息时,可以使用反单引号【` 指令 `】或【$(指令)】。特别注意,那个 ` 是键盘上方的数字键 1 左边那个按键,而不是单引号。例如想要取得核心版本的设定:【version=$(uname -r)】再【echo $version】可得【3.10.0-229.e17.x86_64】
7.若该变量为扩增变量内容时,则可用”$变量名称”或${变量}累加内容,如:【PATH="$PATH":/home/bin】或【PATH=${PATH}:/home/bin】
8.若该变量需要在其他子程序执行,则需要以 export来使变量变成环境变量: 【export PATH】
9.通常大写字符为系统默认变量,自行设定变量可以使用小写字符,方便判断(纯粹依照使用者兴趣与嗜好);
10.取消变量的方法为使用unset : 【unset 变量名称】例如取消 myname 的设定: 【unset myname】
环境变量的功能
1.用 env 观察环境变量与常见环境变量说明
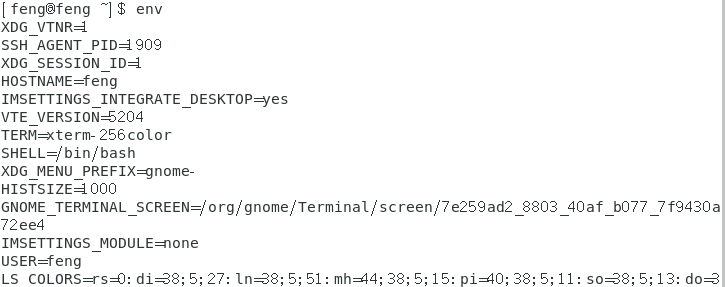
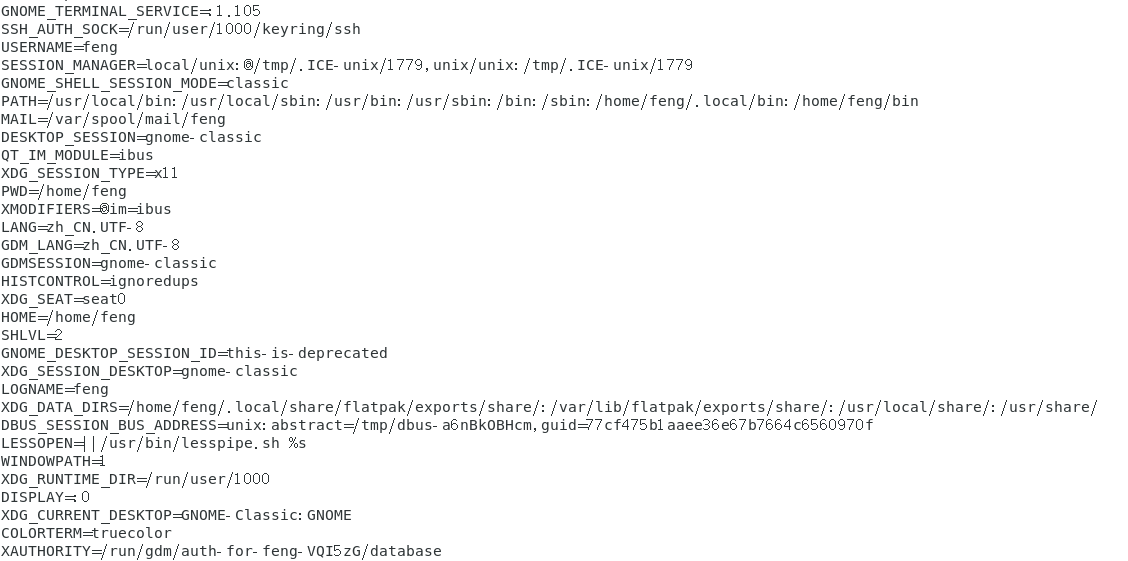
HOME
代表用户的家目录。可以使用cd~去到自己的家目录或者利用cd 就可以直接回到用户家目录了。那就是取用这个变量啦~有很多程序都可能会取用到这个变量的值。
SHELL
目前这个环境使用的SHELL是哪支程序。 Linux预设使用/bin/bash 。
HISTSIZE
这个与【历史命令】有关,亦即是,我们曾经下达过的指令可以被系统记录下来,而记录的【笔数】则是由这个值来设定的。
MAIL
使用 mail 这个指令在收信时,系统会去读取的邮件信箱文件(mailbox)。
PATH
就是执行文件搜寻的路径。目录与目录中间以冒号(:)分隔,由于文件的搜寻是依序由PATH 的变量内的目录来查询,所以,目录的顺序也是重要的。
LANG
这个是语系数据。一般来说,我们中文编码通常是 zh_TW.Big5或者是 zh_TW.UTF-8,这两个编码偏偏不容易被解译出来,所以,有的时候,可能需要修订一下语系数据。
RANDOM
【 随机随机数】的变量。目前大多数的 distributions 都会有随机数生成器,那就是 /dev/random 这个文件。我们可 以透过这个随机数文件相关的变量(SRANDOM)来随机取得随机数值。在 BASH 的环境下,这个 RANDOM 变量的内容,介于 0~32767 之间,所以,只要 echo $RANDOM 时,系统就会主动的随机取出一个介于 0~32767 的数值。
万一想要使用0~9 之间的数值:利用 declare 宣告数值类型:
declare -i number=$RANDOM*10/32768 ; echo $number
2.用 set 观察所有变量(含环境变量与自定义变量)
bash 不只有环境变量,还有一些与 bash 操作接口有关的变量,以及用户自己定义的变量存在的。


基本上,在 Linux预设的情况中,使用{大写的字母}来设定的变量一般为系统内定需要的变量。
比较重要的:
PS1:(提示字符的设定)
这是 PS1(数字的1不是英文字母),这个东西就是【命令提示字符】。
每次按下[Enter]按键去执行某个指令后,最后要再次出现提示字符时,就会主动去读取这个变数值了。
d:可显示出【星期 月 日】的日期格式,如:“Mon Feb 2”;
H:完整的主机名;
h:仅取主机名在第一个小数点之前的名字。
T:显示时间,为 12 小时格式的【HH:MM:SS】
A:显示时间,为 24 小时格式的【HH:MM】
@:显示时间,为 12 小时格式的【am/ pm】样式
u:目前使用者的账号名称,如【feng】
v:BASH 的版本信息
w:完整的工作目录名称,由根目录写起的目录名称。但家目录会以~取代;
W:利用 basename 函数取得工作目录名称,所以仅会列出最后一个目录名
#:下达的第几个指令。
$:提示字符,如果是 root 时,提示字符为 #,否则就是$
$: 关于本 shell 的 PID
$ 本身也是个变量,代表的是【目前这个Shell 的线程代号】,亦即是所谓的 PID(Process ID)。
想知道shell 的 PID,使用【echo $$】即可。

?:关于上个执行指令的回传值
问号也是一个特殊的变量:【上一个执行的指令所回传的值】,上面这句话的重点是【上一个指令】与【回传值】两个地方。当我们执行某些指令时,这些指令都会回传一个执行后的代码。
一般来说,如果成功的执行该指令,则会回传一个0值,如果执行过程发生错误,就会回传【错误代码】,一般就是以非为0的数值来取代。

? 只与上一个指令有关
3.export:自定义变量转换为环境变量
env 与 set 现在知道有所谓的环境变量与自定义变量:两者差异主要在于该变量是否被子程序所继续引用。
当登入Linux并取得一个 bash 之后,你 的 bash就是一个独立的程序,这个程序的识别使用的是一个称为程序标识符,被称为 PID 的就是。接下来你在这个 bash底 下所下达的任何指令都是由这个 bash 所衍生出来的,那些被下达的指令就被称为子程序了。
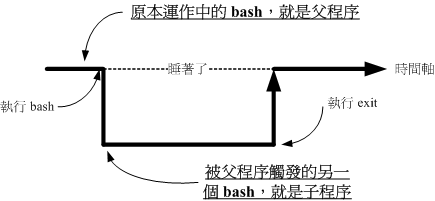
如上所示,在原本的 bash 底下执行另一个 bash ,结果操作的环境接口会跑到第二个bash 去(就是子程序),那原本的 bash 就会在暂停的情况(睡着了,就是 sleep)。整个指令运作的环境是实线的部分。若要回到原本的 bash 去,就只有将第二个 bash 结束掉(下达 exit 或 logout)才行。
因为子程序仅会继承父程序的环境变量,子程序不会继承父程序的自定义变量。
换个角度来想,如果能将自定义变量变成环境变量的话,就可以让该变量值继续存在于子程序了。
export 变量名称
影响显示结果的语系变量(locale)
locale -a

有设定 LANG 或者是 LC_ALL 时,则其他的语系变量就会被这两个变量所取代。
系统是列出目前 Linux 主机内保有的语系文件,这些语系文件都放置在: /usr/lib/locale/这个目录中。
变量的有效范围
变量也有使用的范围,如果在跑程序的时候,有父程序与子程序的不同程序关系时,则【变量】可否被引用与export 有关。因此,export 后的变量,也可以称他为【环境变量】。
环境变量可以被子程序所引用,但是其他的自定义变量内容不会存在于子程序中。
环境变量的数据可以被子程序所引用的原因:内存配置
当启动一个 shell,操作系统会分配一记忆区块给shell 使用,此内存内之变量可让子程序取用;
若在父程序利用 export 功能,可以让自定义变量的内容写到上述的记忆区块当中(环境变量);
当加载另一个 shell 时(亦即启动子程序,而离开原本的父程序了),子 shell 可以将父 shell 的环境变量所在的记忆区块导入自己的环境变量区块当中。
变量键盘读取、数组与宣告:read,array,declare
read [-pt] variable

read 之后不加任何参数,直接加上变量名称,那么底下就会主动出现一个空白行等待输入;
2.宣告变量的类型
宣告变量的类型:declare/typeset
declare [-aixr] variable

如果使用 declare 后面没有接任何参数,那么 bash 就会主动将所有的变量名称与内容显示出来,和 set 一样。
在默认的情况底下,bash 对于变量有几个基本的定义:
变量类型默认为【字符串】,所以若不指定变量类型,则 1+2 为一个【字符串】而不是【计算式】;
bash 环境中的数值运算,预设最多仅能到达整数形态,所以 1/3 结果是 0;
数组[array] 类型
在bash里,数组的设定方式是:var[index]=content
与文件系统及程序的限制关系:ulimit
bash 可以【限制用户的某些系统资源】,包括可以开启的文件数量,可以使用的CPU时间,可以使用的内存总量等等。
ulimit [-SHacdfltu] [配额]

想要复原 ulimit 的设定最简单的方法就是注销再登入,否则就是得要重新以 ulimit 设定才行。
要注意的是,一般身份使用者如果以 ulimit 设定了 -f 的文件大小,那么他【只能继续减小文件容量,不能增加文件容量】。
变量内容的删除、取代与替换
从左向右删除变量内容:#

在PATH这个变量的内容中,每个目录都是以冒号【:】隔开的,所以要从头删除掉目录就是介于斜线(/)到冒号(:)之间的数据,但是PATH中不止一个冒号(:)。
所以 # 与 ## 就分别代表:
#:符合取代文字的【最短的】那一个;·
##:符合取代文字的【最长的】那一个。

从后面向前删除变量内容:%
% 和 %% 与 # 与 ## 的用法类似

删除的数据最终一定是【bin】,即是【:*bin】那个 * 代表通配符。

变量的测试与内容替换
在某些时刻常常需要【判断】某个变量是否存在,若变量存在则使用既有的设定,若变量不存在则给予一个常用的设定。
new_var=${old_var-content}
# 新的变量,主要用来取代旧变量。新旧变量名称常常是一样的
# content 为 变量的内容
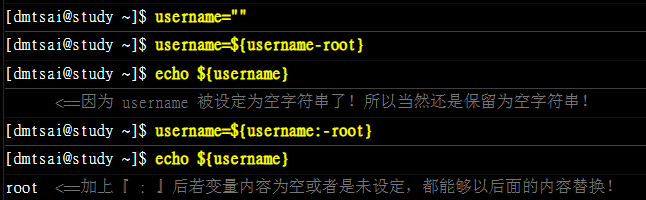
在大括号内有没有冒号【:】的差别是很大的,加上冒号后,被测试的变量未被设定或者是已被设定为空字符串时,都能够用后面的内容来替换与设定。
var 与 str 为变量,针对 str 是否有设定来决定 var
一般来说,str:代表【str没设定或为空的字符串时】, str 则仅为【没有该变数】。
 使用 – 不会影响到旧变量的内容,= 可以将旧变量内容一起替换掉。
使用 – 不会影响到旧变量的内容,= 可以将旧变量内容一起替换掉。
命令别名与历史命令
alias 别名='指令 选项...'
unalias 别名
命令别名与变量的不同:
命令别名是【新创一个新的指令,你可以直接下达该指令】的,至于变量则需要使用类似【echo 】指令才能够呼叫出变量的内容。相当于指针和引用的区别。。。。
历史命令
history [n]
history [-c]
history [-raw] histfiles

正常的情况下,历史命令的读取与记录是这样的:
当我们以 bash 登入 Linux 主机之后,系统会主动的由家目录的~./bash_history 读取以前曾经下过的指令;
假设这次登入主机后,共下达过 100 次指令,【等注销时,系统就会将101~1100 这总共1000 笔历史命令更新到~./bash_history当中】。也就是说,历史命令在注销时,会将最近的 HISTFILESIZE 笔记录到自己的纪录文件当中;
当然,也可以用 history -w 强制立刻写入的。
~./bash_history记录的笔数永远都是 HISTFILESIZE 那么多,旧的讯息会被主动的拿掉!仅保留最新的。
可以利用相关功能执行命令:
!number
!command
!!


Bash Shell 的操作环境
指令 ls 运作的顺序:
1.以相对/绝对路径执行指令,例如【/bin/ls】或【./ls】;
2. 由 alias 找到该指令来执行;
3.由 bash 内建的(builtin)指令来执行;
4.透过 $PATH 这个变量的顺序搜寻到的第一个指令来执行。
bash 的进站与欢迎信息:/etc/issue, etc/motd
cat /etc/issue
 至于如果想要让使用者登入后取得一些讯息,想要让大家都知道的讯息,那么可以将讯息加入/etc/motd 里面去。
至于如果想要让使用者登入后取得一些讯息,想要让大家都知道的讯息,那么可以将讯息加入/etc/motd 里面去。
使用者(包括所有的一般账号与root)登入主机后,就会将 /etc/motd 的讯息出来。
bash 的环境配置文件
login 与 non–login shell
login shell: 取得 bash 时需要完整的登入流程的,就称为 login shell。举例来说,要由tty1 ~ tty6登入,需要输入用户的账号与密码,此时取得的 bash 就称为【login shell】;
non–login shell: 取得 bash 接口的方法不需要重复登入的举动,举例来说,(1)以X window 登入 Linux 后,再以的图形化接口启动终端机,此时那个终端接口并没有需要再次的输入账号与密码,那个 bash 的环境就称为 non–login shell 了。(2)在原本的 bash环境下再次下达 bash 这个指令,同样的也没有输入账号密码,那第二个bash(子程序)也是 non–login shell 。
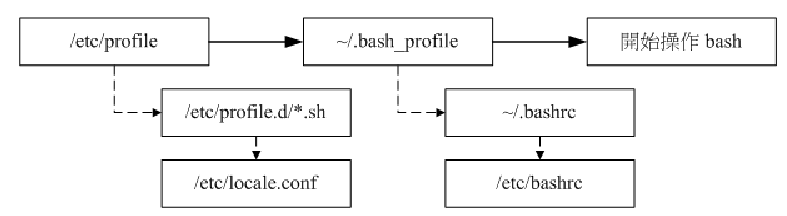
login,non–login shell 两个取得 bash 的情况中,读取的配置文件数据并不一样。
一般来说,login shell其实只会读取这两个配置文件:
1./etc/profile:这是系统整体的设定,最好不要修改这个文件;
2.~/.bash_profile 或 ~/.bash_login 或~/.profile:属于使用者个人设定,要改自己的数据,就写入这里。
/etc/profile 是每个使用者登入取得 bash 时一定会读取的配置文件
这个文件设定的变量主要有:
PATH:会依据 UID 决定 PATH 变量要不要含有 sbin 的系统指令目录;
MAIL:依据账号设定好使用者的 mailbox 到/var/spool/mail/账号名;
USER:根据用户的账号设定此一变量内容;
HOSTNAME:依据主机的hostname指令决定此一变量内容;
HISTSIZE:历史命令记录笔数。CentOS 7.x设定为1000;
umask:包括root默认为022,而一般用户为002等;
/etc/profile 还会去呼叫外部的设定数据,默认情况下,还会依次呼叫:/etc/profile.d/*.sh,/etc/locale.conf,/usr/share/bash-completion/completions/*…
/etc/profile.d/.sh:使用者能够具有 r 的权限,那么该文件就会被 /etc/profile 呼叫进来。在CentOS 7.x 中,这个目录底下的文件规范了bash操作接口的颜色、语系、ll与ls 指令的命令别名、vi的命令别名、which的命令别名等等。
/etc/locale.conf:决定 bash 预设使用何种语系
/usr/share/bash-completion/completions/:[tab],除了命令补齐、档名补齐之外,还可以进行指令的选项/参数补齐功能,就是从这个目录里面找到相对应的指令来处理的。其实这个目录底下的内容是由/etc/profile.d/bash_completion.sh这个文件载入的。
~/.bash_profile:使用者的个人配置文件
在 login shell 的 bash 环境中,所读取的个人偏好配置文件其实主要有三个,依序分别是:
1.~/.bash_ profile 2. ~/.bash_login 3. ~/.profile
其实 bash 的 login shell 设定只会读取上面三个文件的其中一个,而读取的顺序则是依照上面的顺序。也就是说,如果 ~/.bash _profile 存在,那么其他两个文件不论有无存在,都不会被读取。
整个 login shell 的读取流程:
source:读入环境配置文件的指令
由于 /etc/profile 与 ~/.bash_profile 都是在取得 login shell 的时候才会读取的配置文件,所以,如果将自己的偏好设定写入上述的文件后,通常都是得注销再登入后,该设定才会生效。
source 能直接读取配置文件而不注销登入。
source 配置文件档名
. 配置文件档名
利用 source 或小数点(.)都可以将配置文件的内容读进来目前的 shell 环境中。
~/.bashrc: non-login shell 才会读
/etc/bashrc 帮我们的 bash 定义出底下的数据:
依据不同的 UID 规范出 umask 的值;
依据不同的 UID 规范出提示字符(就是 PS1变量);
呼叫 /etc/profile.d/*.sh 的设定。
/etc/bashrc 是 CentOs 特有的
其他相关配置文件
/etc/man_db.conf
文件的内容【规范了使用 man 的时候,man page 的路径到哪里去寻找】
~/.bash_history
预设的情况下,历史命令记录在这里
~/.bash _logout
记录了【当我注销bash后,系统再帮我做完什么动作后才离开】
终端机的环境设定:stty, set
登入Linux时,可以在 tty1 ~ tty6 这六个文字接口的终端机(terminal)环境中登入,登入的时候可以取得一些字符设定的功能。
stty(setting tty):可以查询按键内容,也可以设定终端机的输入按键代表意义。
stty [-a]
# -a:将目前所有的 stty 参数列出来;

intr:送出一个 interrupt(中断)的讯号给目前正在 run的程序(就是终止啰! );
quit:送出一个 quit 的讯号给目前正在run的程序;
erase:向后删除字符;
kill:删除在目前指令列上的所有文字;
eof: End of file 的意思,代表【结束输入】;
start:在某个程序停止后,重新启动他的 output;
stop:停止目前屏幕的输出;
susp:送出一个 terminal stop 的讯号给正在 run 的程序;
可以利用set来设定自己的一些终端机设定值,也可以利用set 来显示,除此之外,其实 set还可以设定整个指令输出/输入的环境。例如记录历史命令、显示错误内容等等。
set [-uvCHhmBx]

bash 默认组合键汇总
| 组合键 | 执行结果 |
|---|---|
| Ctrl + C | 终止目前的命令 |
| Ctrl + D | 输入结束(EOF),例如邮件结束的时候; |
| Ctrl + M | 就是Enter |
| Ctrl + S | 暂停屏幕的输出 |
| Ctrl + Q | 恢复屏幕的输出 |
| Ctrl +U | 在提示字符下,将整列命令删除 |
| Ctrl+Z | 暂停目前的命令 |
通配符与特殊符号
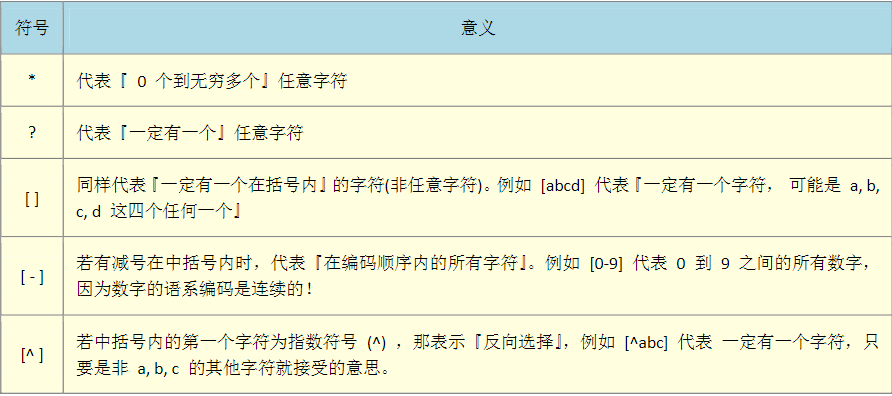
bash 环境中的特殊符号:
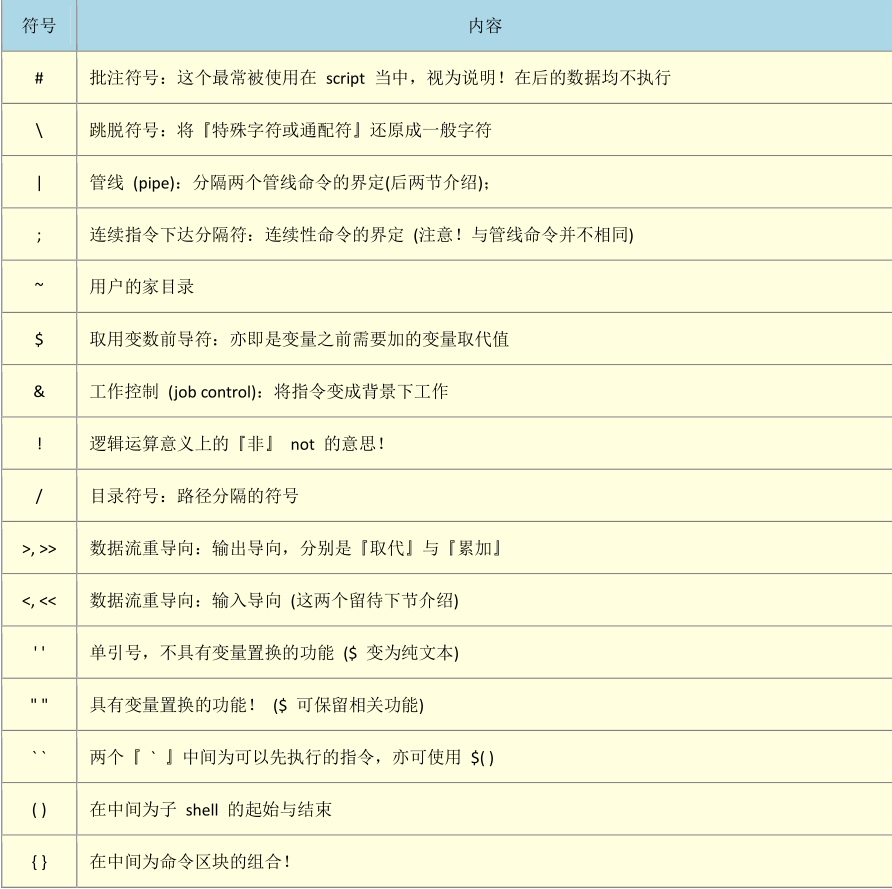
数据流重导向
数据流重导向就是将某个指令执行后应该要出现在屏幕上的数据,给它传输到其他地方。
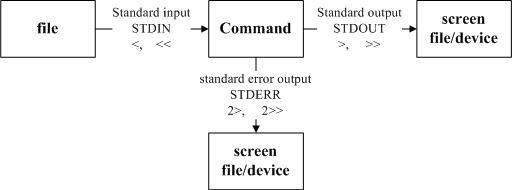
standard output 与 standard error output
标准输出指的是【指令执行所回传的正确的讯息】﹐
标准错误输出可理解为【指令执行失败后,所回传的错误讯息】。
不管正确或错误的数据都是默认输出到屏幕上,所以屏幕当然是乱乱的。
数据流重导向可以将 standard output(简称 stdout) 与 standard error output(简称 stderr) 分别传送到其他的文件或装置去,而分别传送所用的特殊字符如下所示:
1.标准输入(stdin):代码为 0,使用<或<<;
2.标准输出(stdout):代码为1,使用>或>>;
3.标准错误输出(stderr):代码为2,使用2>或2>> ;

1.该文件(本例中是~/rootfile)若不存在,系统会自动的将他建立起来,但是
2.当这个文件存在的时候,那么系统就会先将这个文件内容清空,然后再将数据写入。
3.也就是若以 > 输出到一个已存在的文件中,那个文件就会被覆盖掉。
要将数据累加而不想要将旧的数据删除,可以利用 >>,改为【ll />>~rootfile】,这样的话,若~/rootfile 不存在时,系统就会主动建立这个文件;若存在时,数据会在该文件的最下方累加进去。
1>:以覆盖的方法将『正确的数据』输出到指定的文件或装置上;
1>>:以累加的方法将『正确的数据』输出到指定的文件或装置上;
2>:以覆盖的方法将『错误的数据』输出到指定的文件或装置上;
2>>:以累加的方法将『错误的数据』输出到指定的文件或装置上;
/dev/null 垃圾桶黑洞装置与特殊写法

/dev/null 可以吃掉任何导向这个装置的信息。
如果要将正确讯息和错误讯息两股数据同时导入一个文件,需要特殊写法:
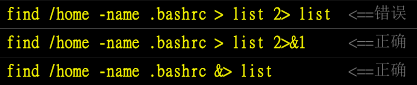
第一行错误的原因是,由于两股数据同时写入一个文件,又没有使用特殊的语法,此时两股数据可能会交叉写入该文件内,造成次序的错乱。所以虽然最终 list 文件还是会产生,但是里面的数据排列就会怪怪的,而不是原本屏幕上的输出排序。
写入同一个文件的特殊写法:可以用 2>&1,也可以用 &>
standard input:< 与 <<
<:【将原本需要由键盘输入的数据,改由文件内容来取代】
<<:【结束的输入字符】
使用命令输出重导向的原因:
屏幕输出的信息很重要,而且我们需要将他存下来的时候;
背景执行中的程序,不希望他干扰屏幕正常的输出结果时;
一些系统的例行命令(例如写在/etc/crontab 中的文件)的执行结果,希望他可以存下来时;
一些执行命令的可能已知错误讯息时,想以【2>/dev/null】将他丢掉时;
错误讯息与正确讯息需要分别输出时。
命令执行的判断依据:;,&&,||
cmd;cmd(不考虑指令相关性的连续指令下达)
在某些时候,我们希望可以一次执行多个指令
# 先执行两次 sync 同步化写入磁盘后才 shutdown 计算机
sync; sync; shutdown -h now
在指令与指令中间利用分号(;)来隔开,这样一来,分号前的指令执行完后就会立刻接着执行后面的指令了
若前一个指令执行的结果为正确,在 Linux底下会回传一个 $?=0 的值

Linux 底下的指令都是由左往右执行的
管线命令
管线命令使用的是【|】这个界定符号,另外,管线命令与【连续下达命令】是不一样的。
管线命令【|】仅能处理经由前面一个指令传来的正确信息,也就是 standard output 的信息,对于 stdandard error 并没有直接处理的能力。
那么整体的管线命令可以使用下图表示:
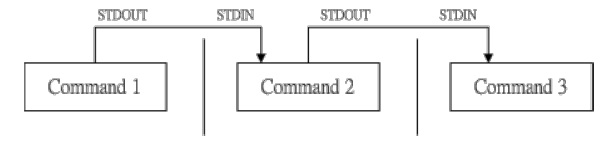
在每个管线后面接的第一个数据必定是【指令】,而且这个指令必须要能够接受 standard input 的数据才行,这样的指令才可以是为【管线命令】。
管线命令仅会处理 standard output,对于 standard error output 会予以忽略;
管线命令必须要能够接受来自前一个指令的数据成为 standard input 继续处理才行。
撷取命令:cut, grep
将一段数据经过分析后,取出我们所想要的,或者是经由分析关键词,取得我们所想要的那一行。
撷取信息通常同时针对一行一行来分析的。
cut
可以将一段讯息的某一段给他【切】出来
cut -d '分隔字符' -f fields
cut -c 字符区间


grep
grep 是分析一行讯息,若当中有我们所需要的信息,就将该行拿出来。
grep [-acinv] [--color=auto] '搜寻' filename

排序命令:sort, wc, uniq
sort [-fbMnrtuk] [file or stdin]


uniq [-ic]

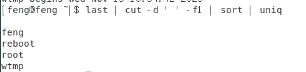
wc [-lwm]


上面分别代表:【行、字数、字符数】
双向重导向:tee
将数据流的处理过程中将某段讯息存下来
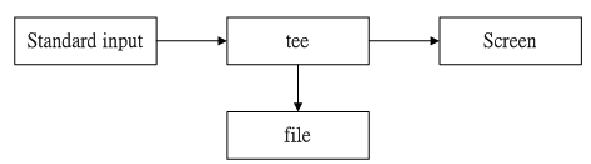 tee 会同时将数据流分送到文件去与屏幕(screen);而输出到屏幕的,其实就是 stdout ,那就可以让下个指令继续处理。
tee 会同时将数据流分送到文件去与屏幕(screen);而输出到屏幕的,其实就是 stdout ,那就可以让下个指令继续处理。
tee [-a] file
# -a:以累加(append)的方式,将数据加入到 file 中
tee 可以让 standard output 转存一份到文件内并将同样的数据继续送到屏幕去处理。
字符转换命令:tr, col, join, paste, expand
tr [-ds] SET1 ....
# -d:删除讯息当中的 SET1 这个字符串;
# -s:取代重复的字符
col [-xb]
# -x:将 tab 建转换为对等的空格键
join:处理两个文件之间的数据,两个文件中,有‘相同数据’的那一行,才将它加在一起
join [-ti12] file1 file2

需要特别注意的是,在使用 join 之前,所需要处理的文件应该要事先经过排序(sort)处理,否则有些比对的项目会被略过。
paste [-d] file1 file2

expand:将[tab]按键转成空格键
expand [-t] file
# -t:后面可以接数字,一般来说,一个tab 键可以用8哥空格取代,也可以自定义
分区命令:split
文件太大会导致一些携带式装置无法复制的问题,split 可以将一个大文件,依据文件大小或行数来分区,就可以将大文件分区成为小文件。
split [-bl] file PREFIX

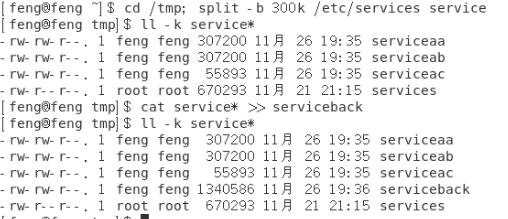
分成小文件后,可以使用数据流重导向合成大文件。
参数代换:xargs
xargs:以字面上的意义来看,x是加减乘除的乘号,args 则是arguments(参数),产生某个指令的参数。
xargs 可以读入 stdin 的数据,并且以空格符或断行字符作为分辨,将 stdin 的资料分隔成为 arguments 。因为是以空格符作为分隔,所以,如果有一些档名或者是其他意义的名词内含有空格符的候,xargs可能就会产生误判。
xargs [-Oepn] command

会使用xargs 的原因是,很多指令其实并不支持管线命令,因此我们可以透过 xargs 来提供该指令引用 standard input 之用。

减号 – 的用途
在管线命令中,常常会使用前一个指令的 stdout 作为这次的 stdin,某些指令需要用到文件名来进行处理,该 stdin 与 stdout 可以利用减号 – 来代替
mkdir /tmp/homeback
tar -cvf - /home | tar -xvf - -C /tmp/homeback
将 /home里面的文件给他打包,但打包的数据不是纪录到文件,而是传送到stdout;经过管线后,将tar–cvf – /home传送给后面的 tar -xvf- 。后面的这个 – 则是取用前一个指令的 stdout,因此,我们就不需要使用filename了。
原文地址:https://blog.csdn.net/FDS99999/article/details/134606255
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_16681.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!