旋转框常用于检测带有角度信息的矩形框,即矩形框的宽和高不再与图像坐标轴平行。相较于水平矩形框,旋转矩形框一般包括更少的背景信息。旋转框检测常用于遥感等场景中,本博文简单的介绍了可应用于旋转框数据训练的开源库,数据结构、OBB关键知识(如何实现角度预测、标签预测),最后分享了两个基于mmrotate自定义的旋转框模型(yolox_obb)。
1、相关开源库
目前的旋转框开源库有yolo_obb(yolov5_obb、yolov7_obb、yolov7_obb等)、paddledetection(ppyoloe_r模型等)、mmrotate库(各类obb模型库)
1.1 mmrotate库
MMRotate 是一款基于 PyTorch 的旋转框检测的开源工具箱,是 OpenMMLab 项目的成员之一。主分支代码目前支持 PyTorch 1.6 以上的版本。
MMRotate 提供了三种主流的角度表示法以满足不同论文的配置,并将旋转框检测任务解耦成不同的模块组件,通过组合不同的模块组件,用户可以便捷地构建自定义的旋转框检测算法模型。
mmrotate库下各种模型检测精度如下所。mmrotate库提到其最强模型达到了 78.9(single-scale)/81.3(multi–scale)map50,但在其模型库和config目录下并未找到。

mmrotate库中大部分模型都是基于faster–rcnn所实现,很难脱离mmdeploy进行部署(主要是rotate roi网络所导致的)。基于其灵活的配置文件,我们可以将其与mmdetection、mmyolo结合起构建基于yolo系列的各种一阶段检测器。博主曾基于mmyolo与mmrotate实现了yolox_obb的训练与测试,但精度总差于yolov5_obb项目
1.2 paddledetection库
paddledetection库是百度公司基于paddle框架推出的目标检测库,其中包含了rotate分支可用于旋转框目标检测。paddledetection将其中的明星模型ppyoloe发表了多个领域的模型,并基于ppyoloe实现了ppyoloe_r模型专用于旋转框目标检测。

paddledetection中ppyoloe_r等模型精度。模型库中的模型默认使用单尺度训练单尺度测试。如果数据增广一栏标明MS,意味着使用多尺度训练和多尺度测试。如果数据增广一栏标明RR,意味着使用RandomRotate数据增广进行训练。
使用ppyoloe_r训练可以参考 https://hpg123.blog.csdn.net/article/details/128137127 , c++部署可以参考 https://blog.csdn.net/a486259/article/details/128151738
1.3 yolo_obb系列库
yolo_obb是指基于yolo系列改造的obb模型,具体有yolov5-v8, 4个版本的obb模型。目前广泛使用的是yolov5_obb项目(yolov7_obb项目未公布在dota数据集上的精度,开源的yolov8obb项目还在开源中,博主自行实现的yolov8_obb在map50上与yolov5_obb处于同一精度水平,而map5095则要高3-5个百分点)
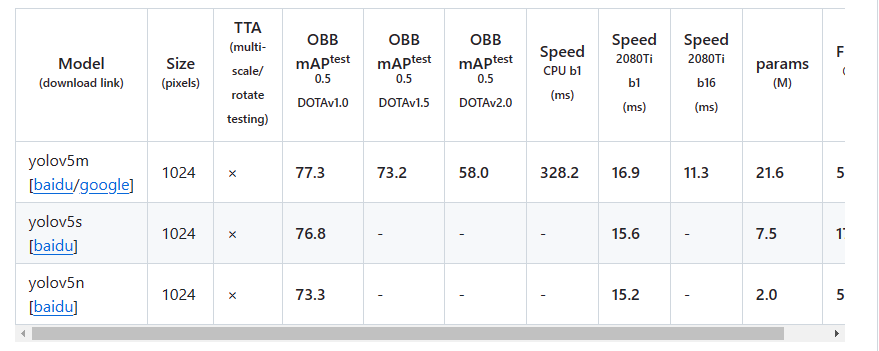
yolov5_obb项目的使用可以参考 https://blog.csdn.net/a486259/article/details/129366477 , c++部署可以参考 https://blog.csdn.net/a486259/article/details/130238663
2、 相关数据集
2.1 数据集标注格式
在数据集中,每个对象都由一个定向边界框 (OBB) 进行注释,该边界框可以表示为 (x1, y1, x2, y2, x3, y3, x4, y4) 。(xi,yi)表示 OBB 的第 i 个顶点。除了 OBB 之外,每个实例还标有类别和难度,表示该实例是否难以被检测到 (1 困难,0 表示不困难)。图像的注释保存在具有相同文件名的文本文件中。 每行代表一个实例。以下是图像的注释示例:
x1, y1, x2, y2, x3, y3, x4, y4, category, difficult
x1, y1, x2, y2, x3, y3, x4, y4, category, difficult
...
更多信息参考:https://captain-whu.github.io/DOTA/dataset.html
paddledetection基于coco格式的数据进行训练,其提供了工具支持将dota格式的数据转换为coco格式,具体如下所示。
python configs/rotate/tools/prepare_data.py --input_dirs ${train_dir} --only_change_format --coco_json_file DOTA_train.json
'annotations': [
{
'id': 2083, 'category_id': 9, 'image_id': 9008,
'bbox': [x, y, w, h], # 水平框标注
'segmentation': [[x1, y1, x2, y2, x3, y3, x4, y4]], # 旋转框标注
...
}
...
]
2.2 dota数据集介绍
DOTA是一个用于航空图像中目标检测的大规模数据集。它可用于开发和评估目标探测器 在航拍图像中。图像是从不同的传感器和平台收集的。每个图像的大小都在该范围内 从 800 × 800 到 20,000 × 20,000 像素,包含表现出各种比例、方向和形状的对象。 DOTA图像中的实例由航空图像解释专家通过任意(8 d.o.f.)四边形进行注释。 我们将继续更新 DOTA,以扩大规模和范围,以反映不断变化的现实世界条件。现在它有三个 版本:
-
DOTA-v1.0 包含 15 个常见类别、2,806 张图片和 188, 282 个实例。培训比例 DOTA-v1.0 中的 set、validation set 和 testing set 分别为 1/2、1/6 和 1/3。具体类别:
飞机、轮船、储罐、棒球钻石、网球场、篮球场、 地面田径场、港口、桥梁、大型车辆、小型车辆、直升机、环形交叉路口、足球场和游泳池,英文类别:plane, ship, storage tank, baseball diamond, tennis court, basketball court, ground track field, harbor, bridge, large vehicle, small vehicle, helicopter, roundabout, soccer ball field and swimming pool -
DOTA-v1.5 使用与 DOTA-v1.0 相同的图像,但实例非常小(小于 10 像素) 也被注释。此外,还增加了一个新类别,“container crane”。它总共包含 403,318 个实例。 图像数量和数据集拆分数量与 DOTA-v1.0 相同。此版本是为 DOAI 挑战赛发布的 2019年与IEEE CVPR 2019一起在航空图像中进行目标检测。具体类别:
飞机、轮船、储罐、棒球钻石、网球场、篮球场、 地面田径场, 港口, 桥梁, 大型车辆, 小型车辆, 直升机, 环形交叉路口, 足球场, 游泳 泳池和集装箱起重机,英文类别:plane, ship, storage tank, baseball diamond, tennis court, basketball court, ground track field, harbor, bridge, large vehicle, small vehicle, helicopter, roundabout, soccer ball field, swimming pool and container crane -
DOTA-v2.0 收集了更多谷歌地球、GF-2卫星和航空图像。DOTAv2.0中有18个常见类别、11268个图像和1793658个实例。与DOTA-V.5相比,它进一步增加了“机场”和“直升机停机坪”的新类别。DOTA的11268个图像分为训练、验证、测试开发和测试挑战集。为了避免过拟合的问题,训练和验证集的比例小于测试集。此外,我们有两个测试集,即测试开发和测试挑战。训练包含1830个图像和268627个实例。验证包含593个图像和81048个实例。我们发布了训练和验证集的图像和基本事实。测试开发包含2792个映像和353346个实例。我们公布了图像,但没有公布基本真相。测试挑战包含6053个图像和1090637个实例。。具体类别:
飞机、轮船、储罐、棒球钻石、网球场、篮球场、 地面田径场, 港口, 桥梁, 大型车辆, 小型车辆, 直升机, 环形交叉路口, 足球场, 游泳 游泳池、集装箱起重机、机场和直升机停机坪,英文类别:plane, ship, storage tank, baseball diamond, tennis court, basketball court, ground track field, harbor, bridge, large vehicle, small vehicle, helicopter, roundabout, soccer ball field, swimming pool, container crane, airport and helipad.
官网地址:https://captain-whu.github.io/DOTA/index.html

原始的dota数据集都是高清大图,基于paddledetection提供的工具可以进行切图操作。具体可参考:https://gitee.com/paddlepaddle/PaddleDetection/tree/develop/configs/rotate ,其支持对有标注和无标注的数据进行多尺度切图
3、OBB的关键知识
3.1 基本概念
OBB是指旋转框目标,HBB是指水平框目标(也就是常规的预测方法)。同架构的OBB模型与HBB相比,OBB多了一个角度输出(通常采用分类方法)。在进行锚框分配时,OBB与HBB并无差别,不将角度考虑到空间维度,仅将其作为附加信息进行预测。而在设计loss时,则需要考虑角度的周期性和对wh空间的影响。 同时,在训练时obb回归的是旋转框的宽和高,hbb回归的是正框的宽高,而正框的宽高扩散更符合卷积模型的感受野扩散过程,故此同模型同数据集下,hbb通常比obb在map50上高1%左右。
在评价指标上有map_obb与map_hbb,map_hbb是原始的map,map_obb是指在计算iou时将使用旋转矩形(基于2个多边形的8个坐标点计算与正框的iou有差异,故计算obb通常需要使用自行编码c++,编译成python的obb插件)
3.2 角度的表示
根据角度范围不同可以划分为不同的表示方法。目前常用的有三种:oc、le90、le135。oc是指opencv表示法,计算矩形与x轴正方向的夹角,角度范围为0~90;le是指长边表示法,计算矩形长边与x轴正方向的夹角。在le90中角度范围为-90到90,在le135中为-45到135。更多细节可以参考:https://zhuanlan.zhihu.com/p/642532202

通常各模型在给出map精度时也会指出其是使用何种角度表示方法,如ppyoloe_r使用oc表示法。
3.3 角度的预测
通常来说在目标检测网络输出分支中加上角度分支即可实现将正框检测模型修改为旋转框模型。关于预测角度则需要确定预测的形式(分类或回归,ppyoloe_r使用分类的方法预测角度,角度值采用弧度制表示,范围为[0,1]。角度回归loss用的是df_loss.转换为角度方法为:angle * 180 / 3.141592653),通常是以分类的进行进行预测(将连续的角度离散为360或180个类别[差1~2度,肉眼基本上不会发现,同时对于iou计算影响很小])
CSL(Circular Smooth Label,ECCV2020) 与KLD(Kullback-Leibler Divergence,NeurIPS2021) 都为大佬yangxue所提出。
Circular Smooth Label
CSL以环形标签表示方法对角度进行编码(使用独热码训练难以收敛,故对标签进行平滑操作),具体下图b所示。

CSL与原始的标签平滑操作(label和为1)是不太一样的,CLS设计了4种窗口函数来进行标签平滑(分别是脉冲函数、矩形函数、三角函数、高斯函数),具体如下图所示。窗口函数还有个参数为窗口半径,窗口半径过小则会变成One-hot label形式,无法学到角度信息,过大则角度预测偏差会加大,论文中的最佳半径为6。

基于高斯窗口函数的方法效果最好,而基于脉冲窗口函数(One-hot label)的效果最差,几乎预测不出角度值。那些角度信息明显的类别(具有一定长宽比),角度分类应该是比较容易,相反则不太容易,比如遥感场景中的油桶。由于边的交换性问题的存在, 90-CSL-baesd方法总体不如180-CSL-baesd方法

更多知识可以参考:https://zhuanlan.zhihu.com/p/111493759
特别注意的是,csl的作者指出边的交换性(exchangeability of edges,EoE)问题,即预测的角度差90度时,模型预测的宽高与真实的宽高在矫正后是相反的,然而在训练是loss却是很小的。针对于EOE问题,我们可以进行2次训练,第一次使角度的loss权重较大,第二次再正常设置loss
yolo_obb系列默认都是使用csl的方法预测角度,mmrotate则可以指定角度预测方法
Kullback-Leibler Divergence
KLD参考GWD先将旋转矩形(x,y,w,h,theat)转换成一个二维的高速分布,具体如下图所示:

其同时对x,y,w,h,theat进行回归,避免了EOE问题。KLD loss中角度loss部分考虑了长宽比,当h/w变大时,角度loss权重系数变的更大,表明了对长方形物体loss的加强。
通过以下可以看出KLD方法基本上要比CSL方法在map50高4个百分点,在map上则要高7个百分点,可见KLD方法所预测出的框更加精准。
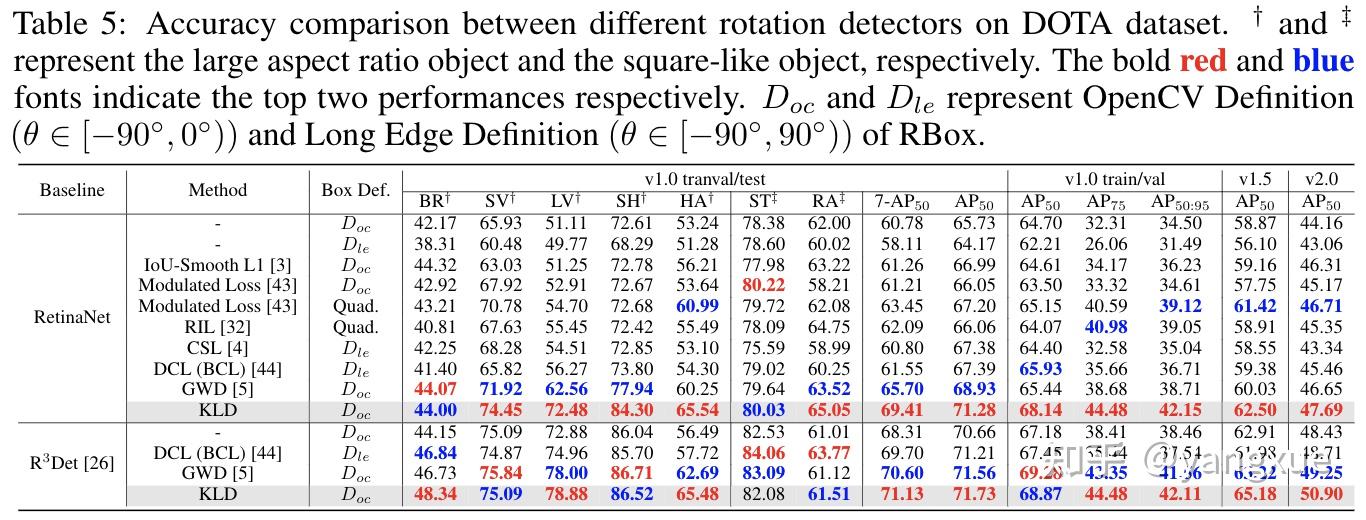
更多细节请参考:https://zhuanlan.zhihu.com/p/642532202
4、基于mmrotate自定义模型
基于mmyolo、mmdetection、mmrotate这三个库的组合,我们可以自定义各种旋转框模型。只需要rotate_head与backbone的输出相符合即可,此外我们也可以自定义rotate_head。
4.1 rotated_yolox.py
在modelsdetectors目录下创建rotated_yolox.py文件,文件内容如下
# Copyright (c) OpenMMLab. All rights reserved.
from ..builder import ROTATED_DETECTORS
from .single_stage import RotatedSingleStageDetector
@ROTATED_DETECTORS.register_module()
class RotatedYolox(RotatedSingleStageDetector):
"""Implementation of Rotated `RetinaNet.`__
__ https://arxiv.org/abs/1708.02002
"""
def __init__(self,
backbone,
neck,
bbox_head,
train_cfg=None,
test_cfg=None,
pretrained=None,
init_cfg=None):
super(RotatedYolox,
self).__init__(backbone, neck, bbox_head, train_cfg, test_cfg,
pretrained, init_cfg)
并在modelsdetectors目录下修改__init__.py文件,新增from .rotated_yolox import RotatedYolox,并在__all__数组内新增,'RotatedYolox'
from .base import RotatedBaseDetector
from .gliding_vertex import GlidingVertex
from .oriented_rcnn import OrientedRCNN
from .r3det import R3Det
from .redet import ReDet
from .roi_transformer import RoITransformer
from .rotate_faster_rcnn import RotatedFasterRCNN
from .rotated_fcos import RotatedFCOS
from .rotated_reppoints import RotatedRepPoints
from .rotated_retinanet import RotatedRetinaNet
from .s2anet import S2ANet
from .single_stage import RotatedSingleStageDetector
from .two_stage import RotatedTwoStageDetector
from .rotated_yolox import RotatedYolox
__all__ = [
'RotatedRetinaNet', 'RotatedFasterRCNN', 'OrientedRCNN', 'RoITransformer',
'GlidingVertex', 'ReDet', 'R3Det', 'S2ANet', 'RotatedRepPoints',
'RotatedBaseDetector', 'RotatedTwoStageDetector',
'RotatedSingleStageDetector', 'RotatedFCOS','RotatedYolox'
]
4.2 yolox_retina_head.py
_base_ = [
'./_base_/datasets/hrsid.py',
'./_base_/default_runtime.py'
]
evaluation = dict(interval=1, metric='mAP')
# optimizer
optimizer = dict(type='SGD', lr=0.001, momentum=0.9, weight_decay=0.0001)
#optimizer = dict(type='Adam', lr=0.0000)
optimizer_config = dict(grad_clip=dict(max_norm=2, norm_type=1))#,error_if_nonfinite=True
# learning policy
#https://github.com/open-mmlab/mmcv/blob/e417035f5d473b9f85d15ba01267d48d7f30e71e/mmcv/runner/hooks/lr_updater.py#L407
lr_config = dict(
policy='CosineRestart',
periods=[20,40,60],
restart_weights=[0.8,0.5,0.2],
min_lr=0.0001)
runner = dict(type='EpochBasedRunner', max_epochs=60)
checkpoint_config = dict(interval=1)
fp16 = dict(loss_scale='dynamic')
data_root = 'datadata//'
classes = ('cls1', 'cls2')
#load_from="./checkpoints/rotated_retinanet_obb_r50_fpn_1x_dota_le135-e4131166.pth"
angle_version = 'le90'
# model settings
model = dict(
type='RotatedYolox',
backbone=dict(type='CSPDarknet', deepen_factor=1, widen_factor=1),
neck=dict(
type='YOLOXPAFPN',
in_channels=[ 256, 512, 1024],
out_channels=256,
num_csp_blocks=1),
bbox_head=dict(
type='RotatedRetinaHead',
num_classes=len(classes),
in_channels=256,
stacked_convs=4,
feat_channels=256,
assign_by_circumhbbox=None,
anchor_generator=dict(
type='RotatedAnchorGenerator',
octave_base_scale=4,
scales_per_octave=3,
ratios=[1.0, 0.5, 2.0],
strides=[8, 16, 32]),
bbox_coder=dict(
type='DeltaXYWHAOBBoxCoder',
angle_range=angle_version,
norm_factor=None,
edge_swap=True,
proj_xy=True,
target_means=(.0, .0, .0, .0, .0),
target_stds=(1.0, 1.0, 1.0, 1.0, 1.0)),
loss_cls=dict(
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
train_cfg=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.4,
min_pos_iou=0,
ignore_iof_thr=-1,
iou_calculator=dict(type='RBboxOverlaps2D')),
allowed_border=-1,
pos_weight=-1,
debug=False),
test_cfg=dict(
nms_pre=2000,
min_bbox_size=0,
score_thr=0.05,
nms=dict(iou_thr=0.1),
max_per_img=2000))
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
img_scale=(800, 800)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='YOLOXHSVRandomAug'),
dict(
type='PolyRandomRotate',
rotate_ratio=0.5,
angles_range=180,
auto_bound=False,
#rect_classes=[9, 11],
version=angle_version),
dict(type='RResize', img_scale=(800, 800)),
dict(
type='RRandomFlip',
flip_ratio=[0.25, 0.25, 0.25],
direction=['horizontal', 'vertical', 'diagonal'],
version=angle_version),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels'])
]
data = dict(
samples_per_gpu=8,
workers_per_gpu=4,
train=dict(pipeline=train_pipeline, version=angle_version),
val=dict(version=angle_version),
test=dict(version=angle_version))
4.3 yolox_fcos_head.py
_base_ = [
'./_base_/datasets/dotav2.py',
'./_base_/default_runtime.py'
]
classes = ('plane', 'ship', 'storage-tank', 'baseball-diamond', 'tennis-court', 'basketball-court', 'ground-track-field', 'harbor', 'bridge', 'large-vehicle', 'small-vehicle', 'helicopter', 'roundabout', 'soccer-ball-field', 'swimming-pool', 'container-crane', 'airport', 'helipad')
evaluation = dict(interval=1, metric='mAP')
# optimizer
#optimizer = dict(type='SGD', lr=0.005, momentum=0.9, weight_decay=0.0001)
optimizer = dict(type='Adam', lr=0.0005)
optimizer_config = dict(grad_clip=dict(max_norm=35, norm_type=2))
# learning policy
#https://github.com/open-mmlab/mmcv/blob/e417035f5d473b9f85d15ba01267d48d7f30e71e/mmcv/runner/hooks/lr_updater.py#L407
lr_config = dict(
policy='CosineRestart',
periods=[20,40,60],
restart_weights=[0.8,0.5,0.2],
min_lr=0.0001)
runner = dict(type='EpochBasedRunner', max_epochs=60)
checkpoint_config = dict(interval=1)
data_root = 'datadata//'
classes = ('cls1', 'cls2')
#load_from="./checkpoints/rotated_fcos_kld_r50_fpn_1x_dota_le90-ecafdb2b.pth"
angle_version = 'le90'
# model settings
model = dict(
type='RotatedYolox',
backbone=dict(type='CSPDarknet', deepen_factor=0.33, widen_factor=0.5),
neck=dict(
type='YOLOXPAFPN',
in_channels=[128, 256, 512],
out_channels=128,
num_csp_blocks=1),
bbox_head=dict(
type='RotatedFCOSHead',
num_classes=len(classes),
in_channels=128,
stacked_convs=4,
feat_channels=256,
regress_ranges=((-1, 64), (64, 128), (128, 256)),
strides=[8, 16, 32],
center_sampling=True,
center_sample_radius=1.5,
norm_on_bbox=True,
centerness_on_reg=True,
separate_angle=False,
scale_angle=True,
bbox_coder=dict(
type='DistanceAnglePointCoder', angle_version=angle_version),
loss_cls=dict(
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=1.0),
# loss_bbox=dict(
# type='GDLoss_v1',
# loss_type='kld',
# fun='log1p',
# tau=1,
# loss_weight=1.0),
loss_bbox=dict(type='SmoothL1Loss', beta=0.11, loss_weight=1.0),
loss_centerness=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0)),
# training and testing settings
train_cfg=None,
test_cfg=dict(
nms_pre=2000,
min_bbox_size=0,
score_thr=0.05,
nms=dict(iou_thr=0.1),
max_per_img=2000))
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
img_scale=(800, 800)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(
type='Mosaic',
img_scale=img_scale,
use_cached=True,
max_cached_images=40,
pad_val=114.0),
dict(type='YOLOXHSVRandomAug'),
dict(
type='YOLOXMixUp',
img_scale=img_scale,
use_cached=True,
ratio_range=(1.0, 1.0),
max_cached_images=20,
pad_val=(114, 114, 114)),
dict(
type='PolyRandomRotate',
rotate_ratio=0.5,
angles_range=180,
auto_bound=False,
rect_classes=[9, 11],
version=angle_version),
dict(type='RResize', img_scale=(800, 800)),
dict(
type='RRandomFlip',
flip_ratio=[0.25, 0.25, 0.25],
direction=['horizontal', 'vertical', 'diagonal'],
version=angle_version),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels'])
]
train_pipeline = [
dict(type='Mosaic', img_scale=img_scale, pad_val=114.0),
dict(
type='RandomAffine',
scaling_ratio_range=(0.1, 2),
border=(-img_scale[0] // 2, -img_scale[1] // 2)),
dict(
type='MixUp',
img_scale=img_scale,
ratio_range=(0.8, 1.6),
pad_val=114.0),
dict(type='YOLOXHSVRandomAug'),
dict(type='RandomFlip', flip_ratio=0.5),
# According to the official implementation, multi-scale
# training is not considered here but in the
# 'mmdet/models/detectors/yolox.py'.
dict(type='Resize', img_scale=img_scale, keep_ratio=True),
dict(
type='Pad',
pad_to_square=True,
# If the image is three-channel, the pad value needs
# to be set separately for each channel.
pad_val=dict(img=(114.0, 114.0, 114.0))),
dict(type='FilterAnnotations', min_gt_bbox_wh=(1, 1), keep_empty=False),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels'])
]
train_dataset = dict(
type='MultiImageMixDataset',
dataset=dict(
type="SARDataset",
ann_file=data_root + 'annotations/instances_train2017.json',
img_prefix=data_root + 'train2017/',
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True)
],
filter_empty_gt=False,
),
pipeline=train_pipeline)
data = dict(
samples_per_gpu=32,
workers_per_gpu=4,
train=dict(pipeline=train_pipeline, version=angle_version),
val=dict(version=angle_version),
test=dict(version=angle_version))
原文地址:https://blog.csdn.net/a486259/article/details/134557389
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_16697.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!