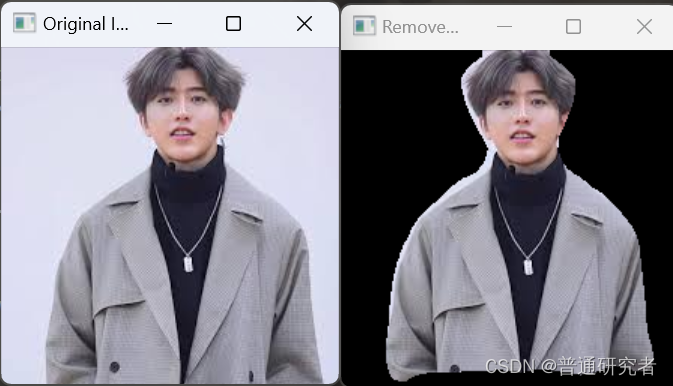
分离图像中的人物和背景通常需要一些先进的图像分割技术。GrabCut是一种常见的方法,但是对于更复杂的场景,可能需要使用深度学习模型。以下是使用深度学习模型(如人像分割模型)的示例代码:
#导入相关的库
import cv2
import numpy as np
import torch
import torchvision.transforms as T
from torchvision.models.segmentation import deeplabv3_resnet101
def remove_background_with_deep_learning(image_path):
# 读取图像
image = cv2.imread(image_path)
# 将图像转换为RGB格式
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) #将图像从BGR格式转换为RGB格式,因为深度学习模型通常使用RGB。
# 定义图像预处理和转换
transform = T.Compose([ #定义了图像的预处理和转换步骤,包括将图像转换为PyTorch张量和标准化。
T.ToTensor(), # 将图像转换为PyTorch张量
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), # 标准化图像
])
# 对图像进行预处理和转换
input_tensor = transform(image_rgb)
input_batch = input_tensor.unsqueeze(0) # 添加一个维度,使其成为批处理的一部分
# 加载预训练的DeepLabV3模型
model = deeplabv3_resnet101(pretrained=True)
model.eval() # 设置为评估模式,不进行梯度更新
# 运行模型并获取分割掩模
with torch.no_grad(): #上下文管理器,用于关闭梯度计算,以提高推断速度。
output = model(input_batch)['out'][0]#运行模型并获取输出。
output_predictions = output.argmax(0) # 获取模型输出中预测类别的索引
# 将分割结果转换为二进制掩模
mask = (output_predictions == 15).numpy() # 在DeepLabV3模型中,15是人物的标签
# 将原始图像与二进制掩模相乘,去除背景
result = image * mask[:, :, np.newaxis]
# 显示结果
cv2.imshow('Original Image', image)
cv2.imshow('Removed Background', result)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 使用示例
remove_background_with_deep_learning(r"C:UsersmzdDesktopopencvimages.jpg")
代码解释:
理解代码可能需要一些基本的编程和机器学习知识,以下是逐步解释代码的主要部分:
-
定义函数:
remove_background_with_deep_learning是一个用于去除图像背景的函数。它接受一个图像路径作为参数。 -
加载预训练模型: 使用
deeplabv3_resnet101模型,它是一个预训练的深度学习模型,专门用于图像分割任务。
在这个函数中,将原始图像与二进制掩模相乘的目的是将背景部分置零,从而实现去除背景的效果。这是基于掩模的思想,其中掩模是一个与原始图像大小相同的二维数组,其中元素的值为0或1,用于指示哪些像素应该保留(值为1)或去除(值为0)。
具体流程如下:
这是一种简单而有效的背景去除方法,尤其在利用深度学习模型进行图像分割的场景中得到了广泛应用。
原文地址:https://blog.csdn.net/weixin_42367888/article/details/134629011
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_16781.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。