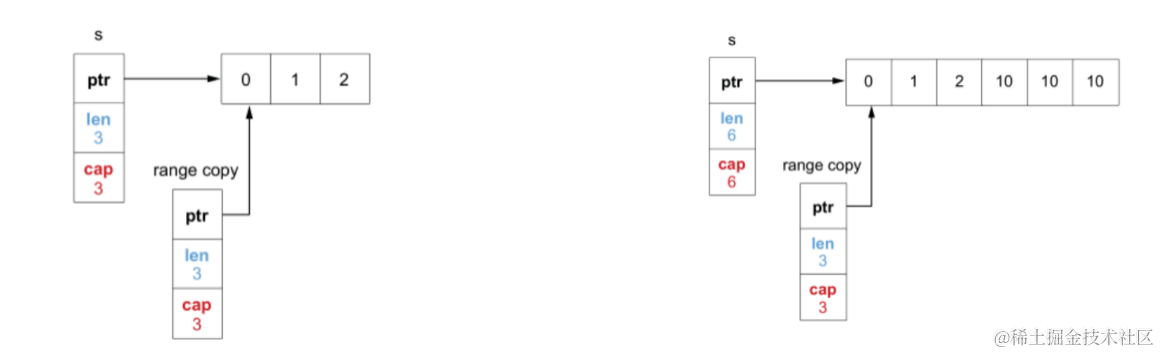
使用go语言用原生net/http写爬虫如何优雅的控制并发和请求速度
go程序的执行效率相对python要快的多,且占用的内存和cpu更少
本教程实现控制爬虫程序并发上限,同时控制程序对外请求上限。
控制并发
限流
并发和限流的区别
简单说明
可以将整个采集流程看成一段河流,将数据当作水。
并发就相当于河道的宽度,河道越宽单位时间内流过的水就越多。
而限流就相当于桥洞,河流要经过桥洞,桥洞的大小决定了瞬间有多少水流过河流
有了并发控制为什么还要限流
采集过程中需要使用代理,代理是有并发和带宽的上限的,代理的上限就是限流的大小,限流只控制爬虫调用代理的速度,踩着代理的上限跑爬虫
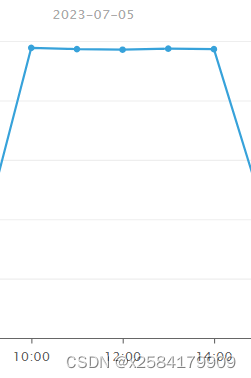
最总代码
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。