本文介绍: Prometheus 中的 Alerting(报警) 分为两部分1)Prometheus servers 中的 Alerting rules 将 alerts 发送给 Alertmanager2)之后,Alertmanager 管理这些 alertsalerts 包括:silencing, inhibition, aggregation以及通过 email, on–call notification systems(呼叫通知系统)和聊天平台等方式,发送通知。
名词解释
Promethus 是什么
专注于:
1)可靠的实时监控
2)收集时间序列数据
3)提供强大的查询语言(PromQL),用于分析这些数据
功能:
1)【监控】各种资源、服务和应用程序的性能指标
2)支持多维数据模型和灵活的查询语言,从而 -> 用户,可以轻松地获取他们关心的信息
Actuator 是什么
在Java生态系统中,Spring Boot 提供了 Actuator 模块,用于【监控和管理】应用程序
举例
1)监控应用程序健康状况:
Actuator 提供了 /actuator/health 端点,用于检查应用程序的健康状态。通过这个端点,你可以了解应用程序是否运行正常、数据库连接是否正常等。
Promethus 和 Actuator 的关系是什么?
AlertManager 是什么
Grafna是什么
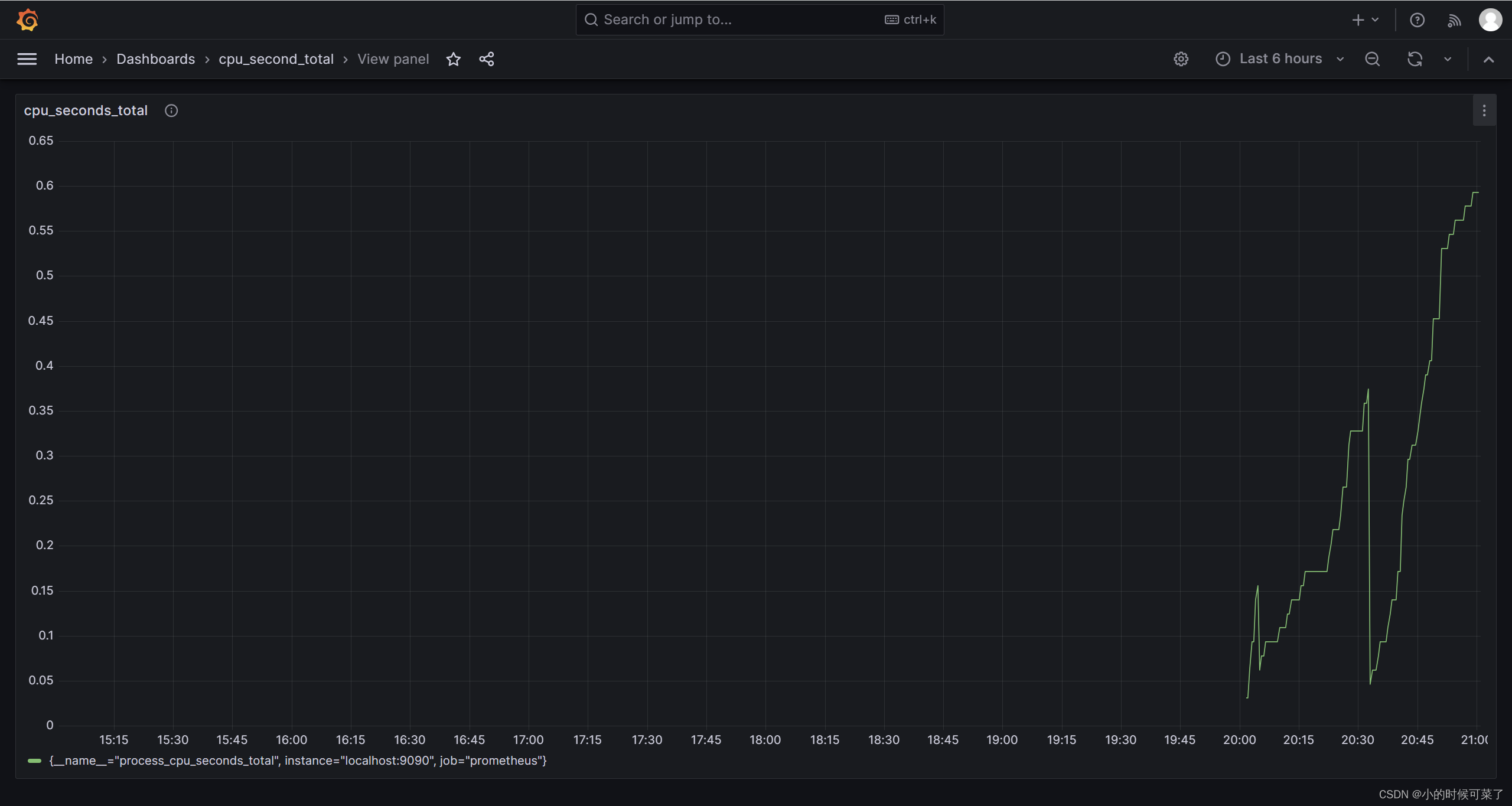
Promethus 基本概念
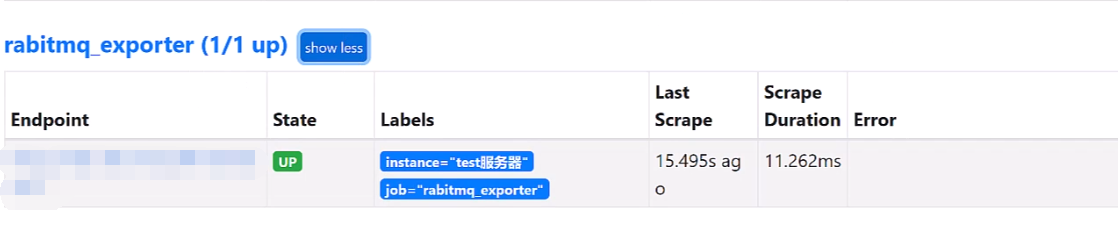
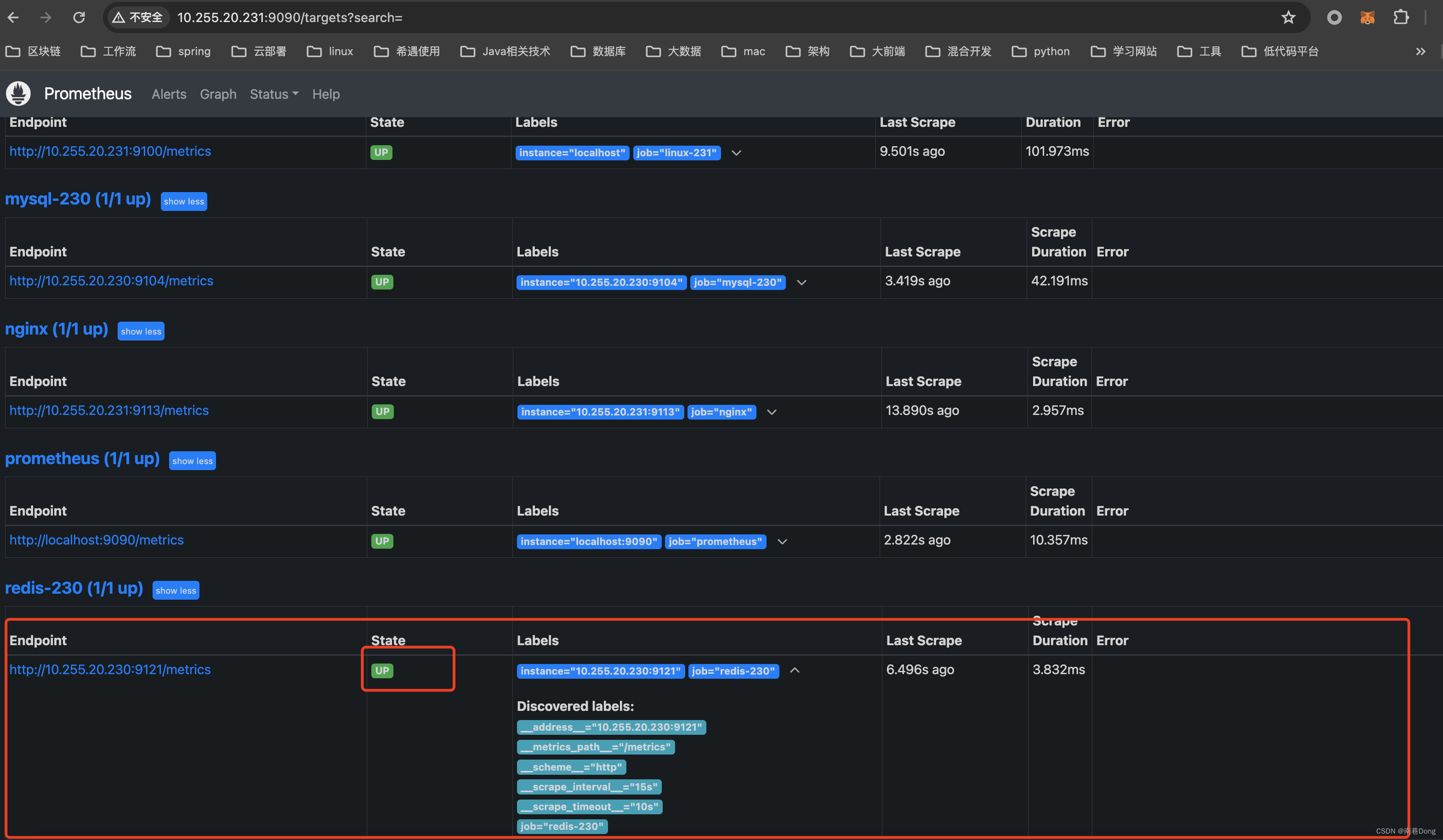
查看抓取的端点

Prometheus 自带浏览器

Expression browser

配置规则(将抓取的数据,聚合到新的时间序列中)


让 Grafana 支持 Prometheus




alerting 概述
ALERTMANAGER
Grouping
Inhibition
Silences
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。