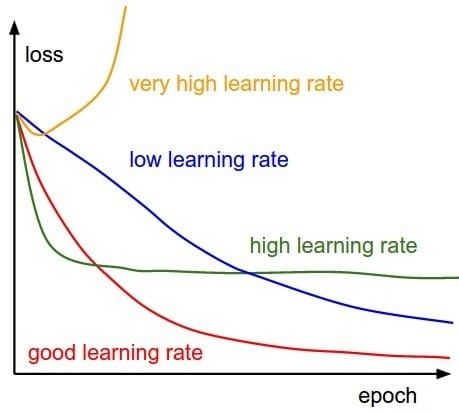
本文介绍: 之所以上面的方法可以work,因为小的学习率对参数更新的影响相对于大的学习率来讲是非常小的,比如第一次迭代的时候学习率是1e-5,参数进行了更新,然后进入第二次迭代,学习率变成了5e-5,参数又进行了更新,那么这一次参数的更新可以看作是在最原始的参数上进行的,而之后的学习率更大,参数的更新幅度相对于前面来讲会更大,所以都可以看作是在原始的参数上进行更新的。学习率的选择策略在网络的训练过程中是不断在变化的,在刚开始的时候,参数比较随机,所以我们应该选择相对较大的学习率,这样loss下降更快;
经过了大量炼丹的同学都知道,超参数是一个非常玄乎的东西,比如batch size,学习率等,这些东西的设定并没有什么规律和原因,论文中设定的超参数一般都是靠经验决定的。但是超参数往往又特别重要,比如学习率,如果设置了一个太大的学习率,那么loss就爆了,设置的学习率太小,需要等待的时间就特别长,那么我们是否有一个科学的办法来决定我们的初始学习率呢?
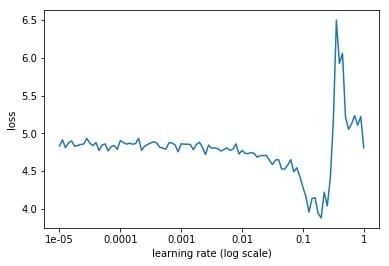
在这篇文章中,我会讲一种非常简单却有效的方法来确定合理的初始学习率。
学习率的重要性
目前深度学习使用的都是非常简单的一阶收敛算法,梯度下降法,不管有多少自适应的优化算法,本质上都是对梯度下降法的各种变形,所以初始学习率对深层网络的收敛起着决定性的作用,下面就是梯度下降法的公式
![]()

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。





