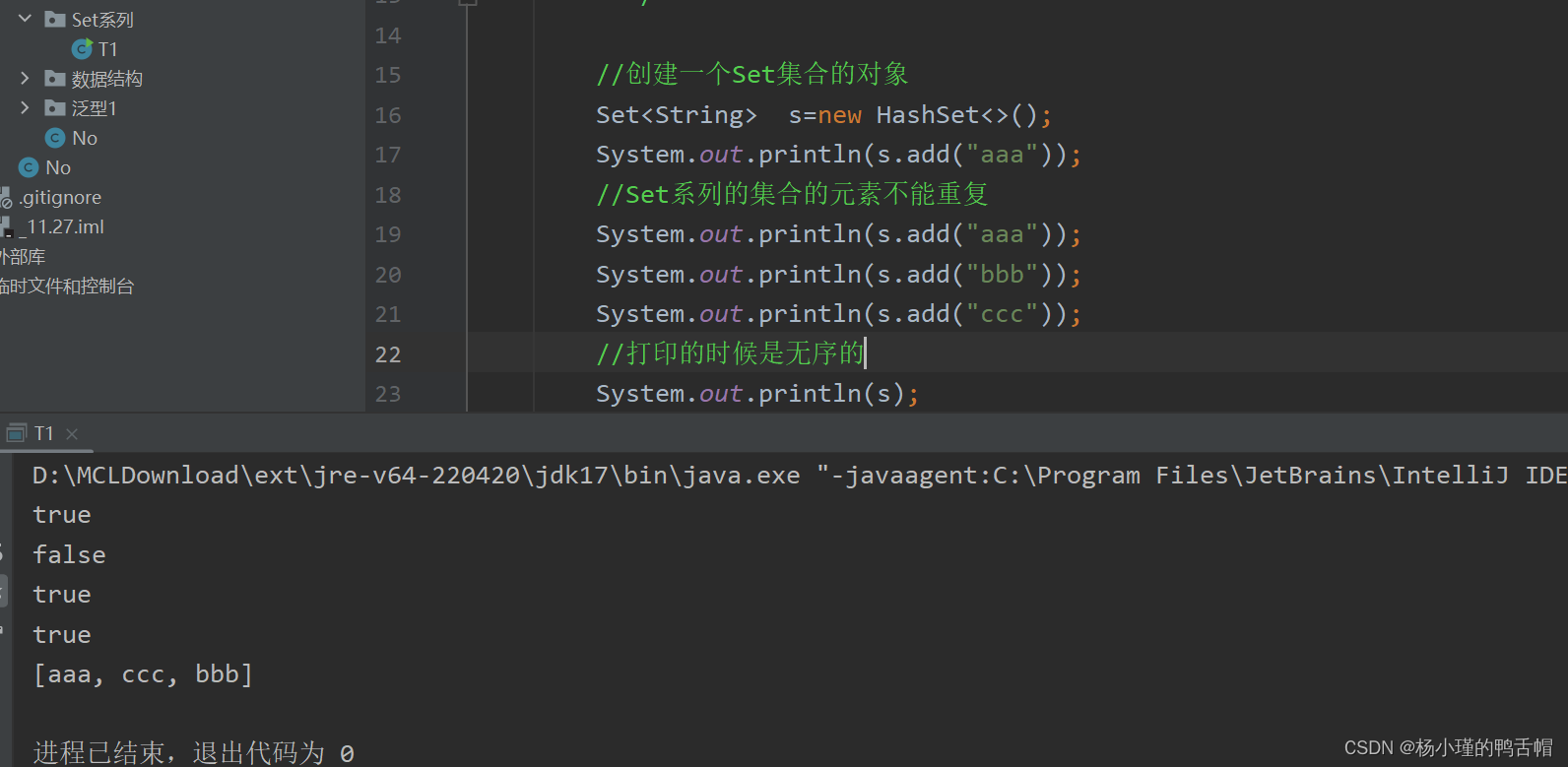
无序: 存取的顺序不一样
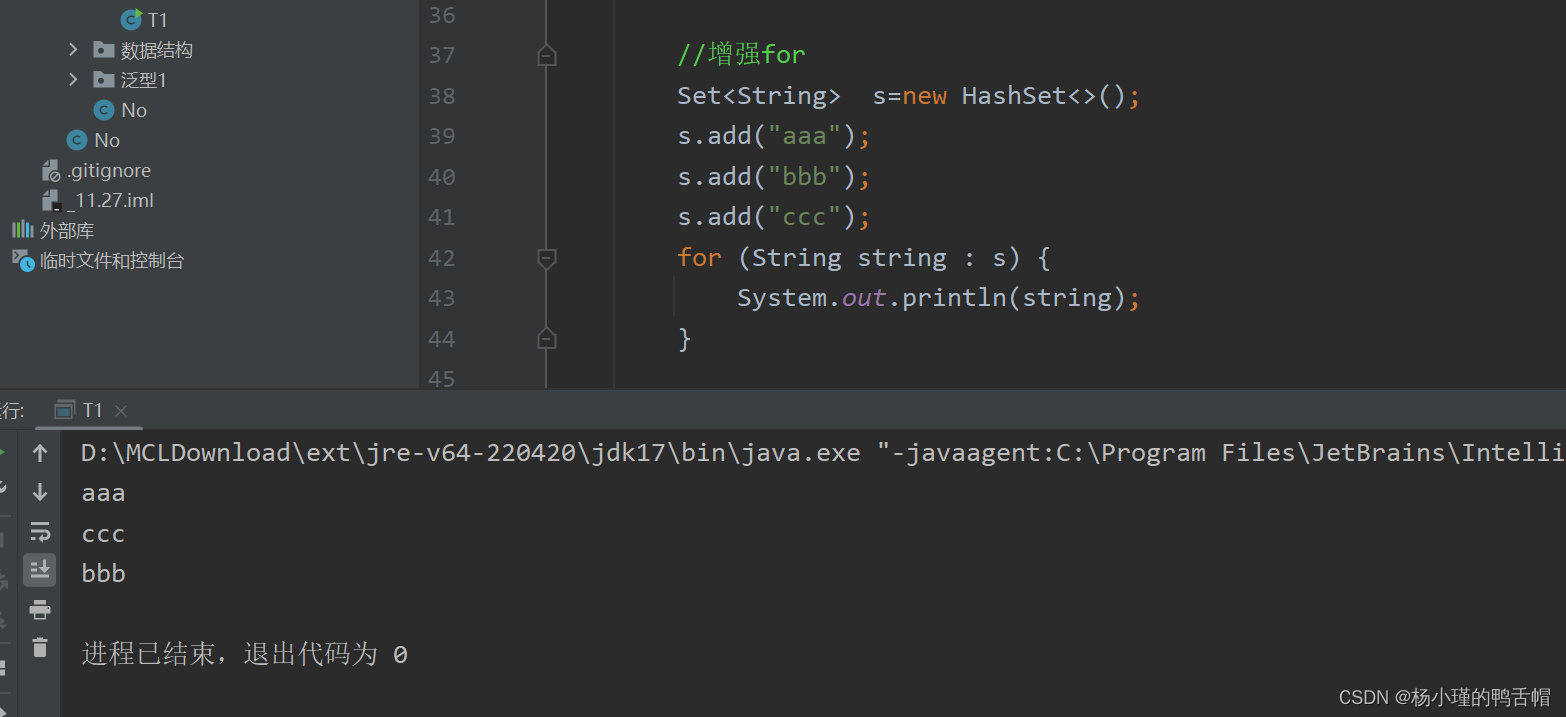
一.三种遍历
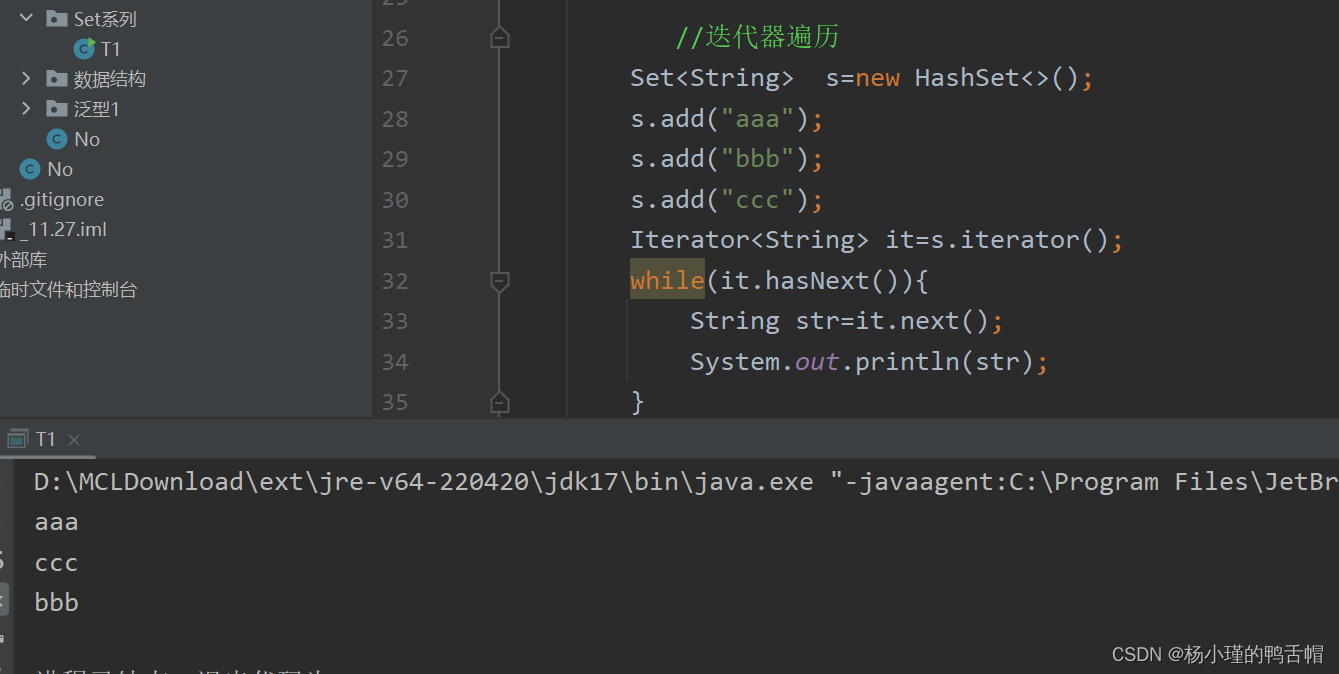
<2>增强for
<3>Lambda表达式

二.HashSet
哈希表的组成:
哈希值的特点
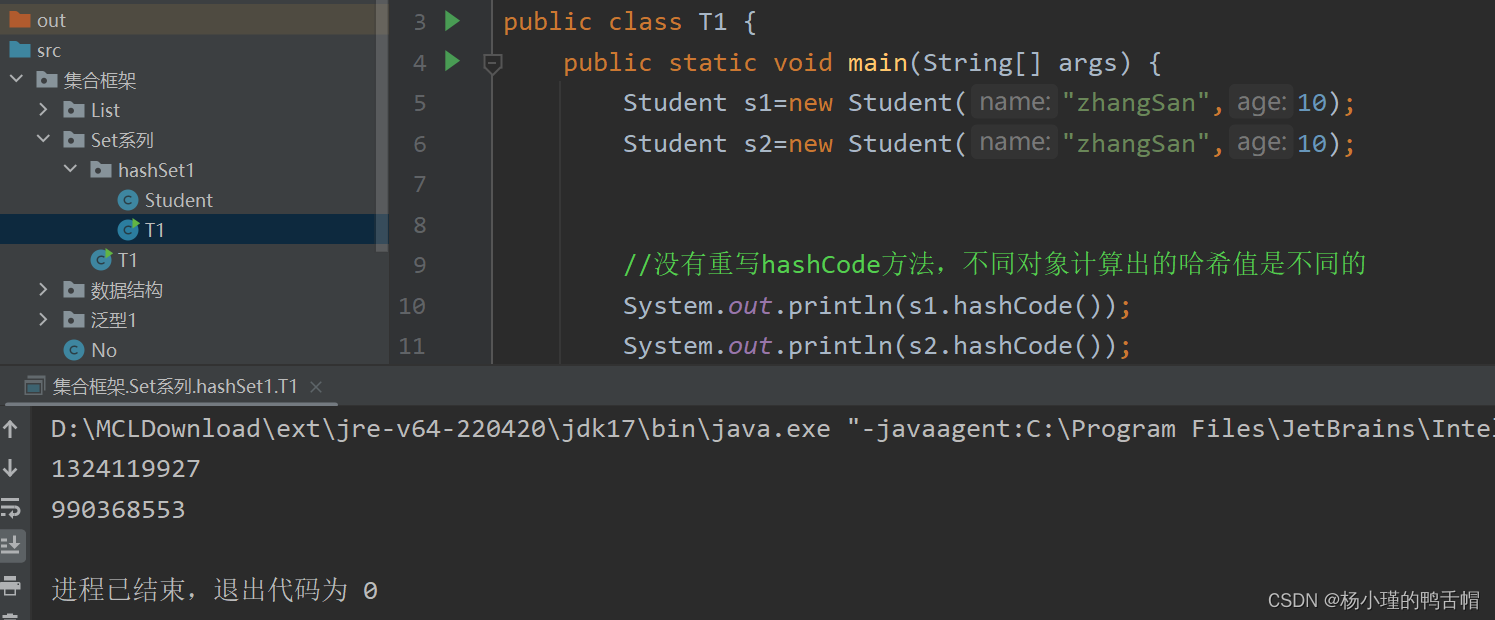
如果没用重写hashCode方法,不同对象计算出的哈希值是不同的
哈希碰撞
举一个极端例子:整形的范围是-21亿—+21亿加入有50亿个对象那么必然会有重复的
没重写
HashSet的底层原理

4.如果位置不为null,表示有元素,则调用equals方法比较属性值
5.如果一样就不存入,如果不一样就存入
存入的方式有两种
JDK8以后:新元素直接挂在老元素下面
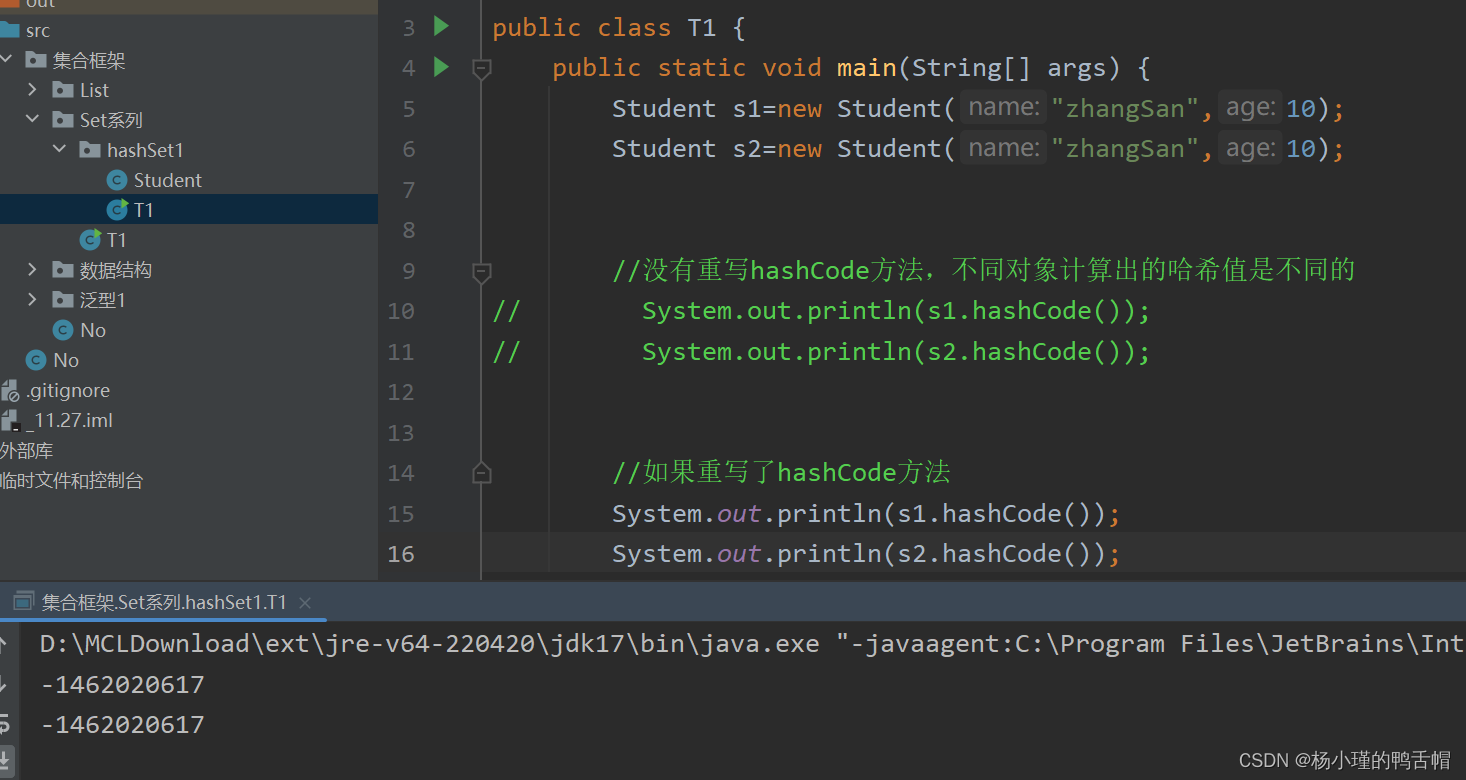
如果集合中存储的是自定义的对象,必须重写hashCode和equals方法否则就会使用地址值比较
三个问腿
A:因为遍历是在数组的0索引开始遍历,可能是null,可能是链表,可能是红黑树,索引小的数据不一定是先添加的
A:使用HashCode得到哈希值得到数据应存储的位置再使用equals比较属性值
三.LinkedHashSet
有序,无索引,不重复
原理:底层仍然是哈希表,只是每个元素又额外多了一个双链表的机制记录存储的数据
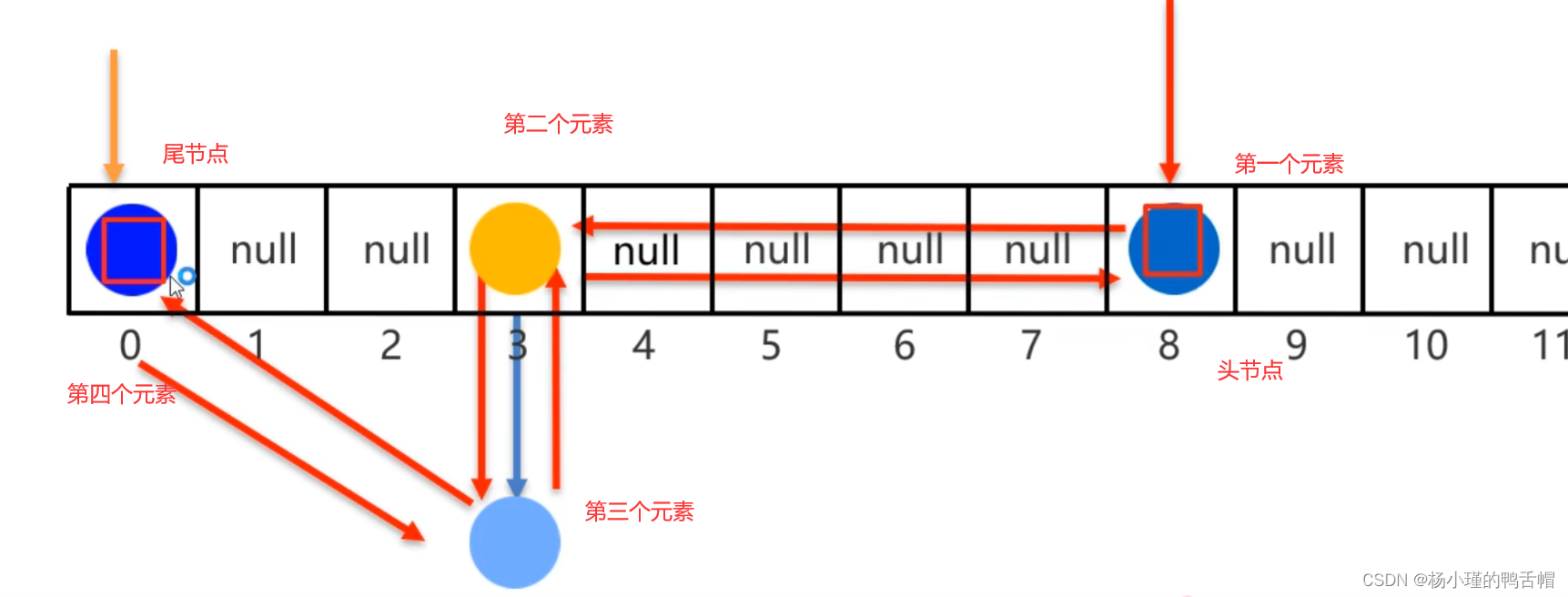
这样每两个相邻添加成功的数据,都会互相记录地址值,形成双向链表
LinkedHashSet遍历就是再双向链表的头节点开始遍历保证了数据存取一致
这个集合不为了效率,只保证顺序
四.TreeSet
不重复,无索引,可排序
底层是红黑树
原文地址:https://blog.csdn.net/Ineedmame/article/details/134698944
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_17725.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。