本文介绍: 在教学模型中,运输层是自上而下的第二层,主要任务是为了相互通信的进程完成服务, 进程是计算机上运行的程序,在这一章节姑且可以这样理解(肯定是不贴切的,不过我相信学过操作系统的大家能理解我的意思, 对吧?在这一层中,真正通信的实体不是链接在网络上的计算机,而是计算机上的程序,如果看图可以发现大概是这样子的:从图上来看,确确实实是将计算机网络的作用范围又扩大了一层,虽然这一个扩大范围来物理意义上是没啥变化的, 但是在逻辑上确实解决了很多问题. 我们将这个服务范围范围称之为:”运输。
虽然我自己也不知道写在前面和前言有什么区别…..
这个系列其实是针对<深入浅出计算机网络>的简单总结,加入了一点个人的理解和浅薄见识,如果您有一些更好的意见和见解,欢迎随时协助我改正,感激不尽啦.
最近心态平和了不少, 和过去也完全做了个割舍吧,既然痛苦和压力的源头是曾经的爱和信任,那么就当这些从未出现过好了…
0.写在前面
在先前的时候,我们解释了网络层,数据链路层,物理层,其实这三个层理论上已经构建出了我们熟悉的计算机网络的体系结构了,我们知道计算机和计算机之间是如何实现链接,寻址,以及拓扑结构如何构建. 而接下来的两个层, 个人认为是更偏向于用户,或者是程序员的两层,我们需要具体确定用户使用了什么进程, 采取了什么服务,应该怎么样分配,基于完善的计算机网络结构真正意义上实现一些网络应用.
1.什么是运输层
1.1:运输层的任务
在教学模型中,运输层是自上而下的第二层,主要任务是为了相互通信的进程完成服务, 进程是计算机上运行的程序,在这一章节姑且可以这样理解(肯定是不贴切的,不过我相信学过操作系统的大家能理解我的意思, 对吧?)
在这一层中,真正通信的实体不是链接在网络上的计算机,而是计算机上的程序,如果看图可以发现大概是这样子的:

1.2.端口

1.3:提供的服务以及两种核心协议:
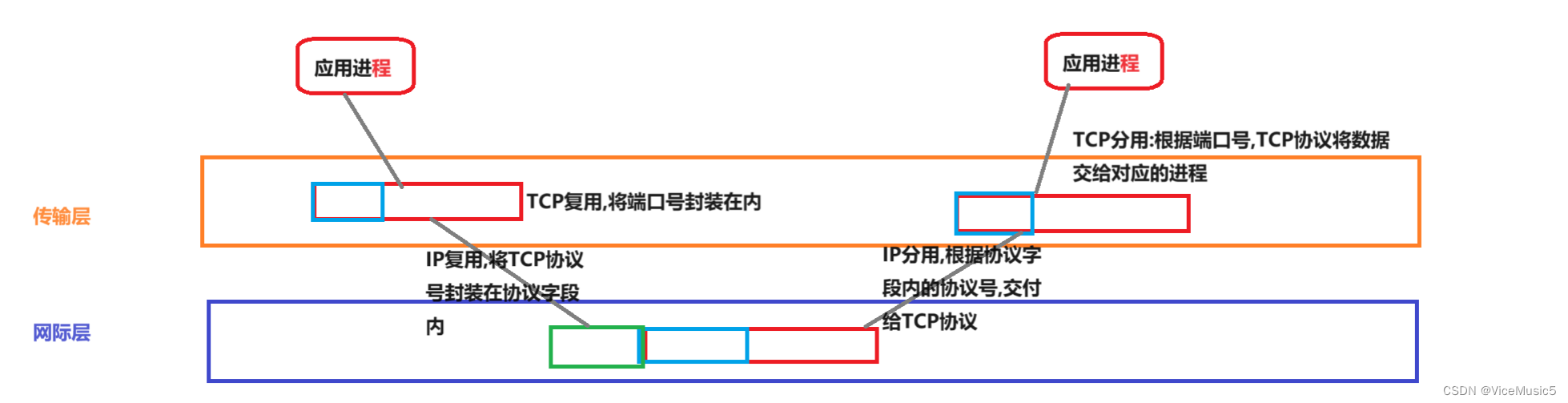
1.4:复用,分用

2.UDP和TCP,以及对比
2.1. 无连接的UDP:

2.2.1:UDP对于应用层报文的处理:

2.2.2:UDP对于数据可靠性的支持:
2.2.3:UDP的首部格式


2.2:面向链接的TCP
2.2.1:TCP对于报文的处理

2.2.2:TCP报文段的首部:

2.2.3:TCP对于数据可靠性的支持
2.2.3.1:TCP建立连接(三次握手)



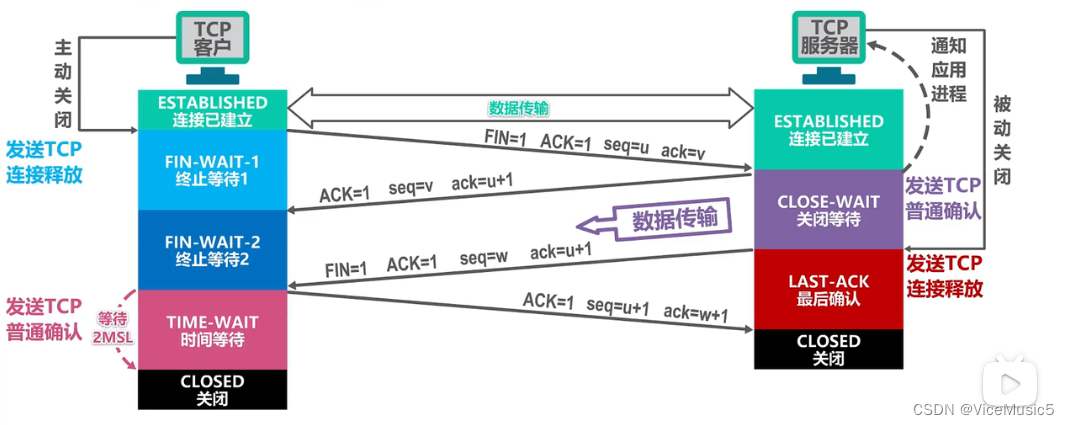
2.2.3.2:TCP释放链接(四次挥手)


2.2.3.3: TCP保活计时器


3.TCP实现的一些可靠传输的支持以及算法
3.1:流量控制







3.2: 拥塞控制


3.2.1:慢开始和拥塞避免
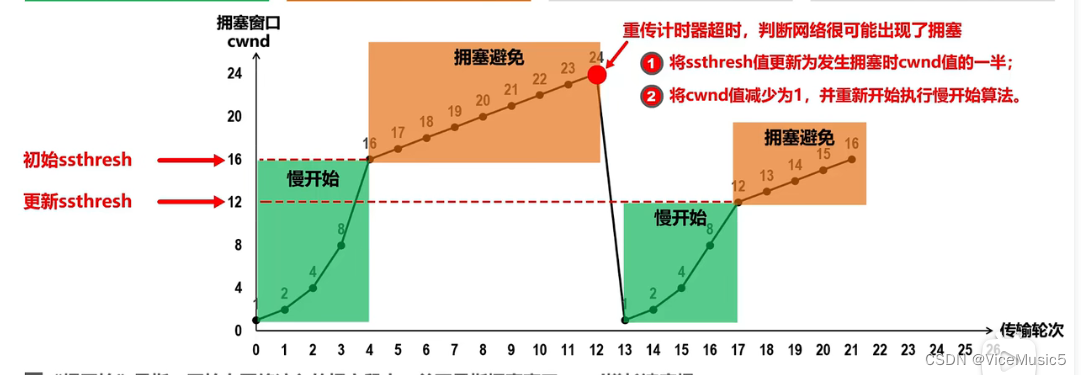
3.2.2:快重传和快恢复

3.2.3:拥塞是如何判断的
3.3: 可靠传输/滑动窗口
3.4:超时重传




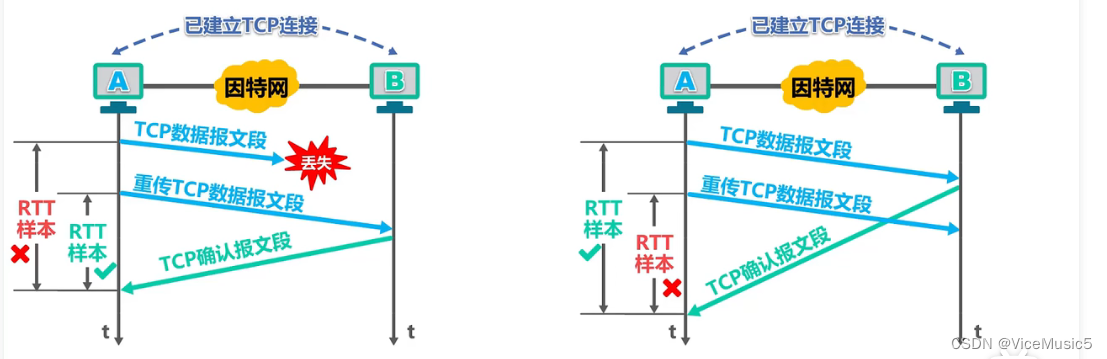
3.5:缓存和窗口的关系
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。