≈0.709,这样就达到了将总面积缩放为原本的
1
2
frac{1}{2}
21的目的。
P-NET的模型是用单尺度(12*12)的图片训练出来的。推理的时候,缩小后的长宽最小不可以小于12。
对多个尺度的输入图像做训练,训练是非常耗时的。因此通常只在推理阶段使用图像金字塔,提高算法的精度。

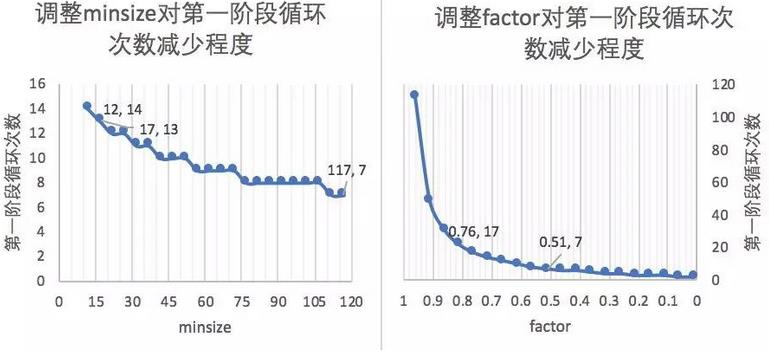
图像金字塔是有生成标准的,每次缩放的程度(factor)以及最小的兜底标准(minsize)都是需要合适的设置的,那么能够优化计算效率的合适的最小人脸尺寸(minsize)和缩放因子(factor)具有什么样的依据?
- 第一阶段会多次缩放原图得到图片金字塔,目的是为了让缩放后图片中的人脸与P-NET训练时候的图片尺度(
12
×
12
- 引申优化项:先把图像缩放到一定大小,再通过factor对这个大小进行缩放。可以减少计算量。
例:输入图片为
1200
×
1200
1200px×1200px,设置缩放后的尺寸接近训练图片的尺度(
12
x
×
12
x
12pxtimes 12px
12px×12px)
2.4 P-Net
网络的输入为预处理中得到的图像金字塔,P-Net中设计了一个全卷积网络(FCN)对输入的图像金字塔进行特征提取和边框回归。
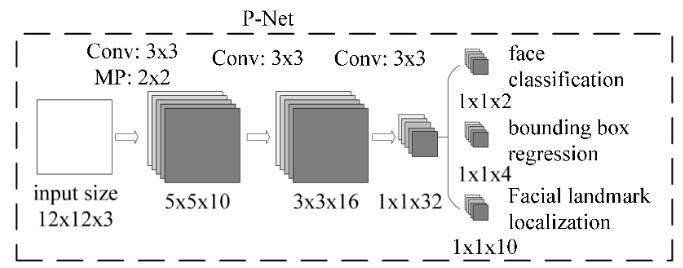
在P-Net中,经过了三次卷积和一次池化(MP:Max Pooling),输入
12
×
12
×
3
12×12×3的尺寸变为了
1
×
1
×
32
1×1×32,
1
×
1
×
32
1
×
1
×
2
12
×
12
12×12的区域都会判断一下是否存在人脸,通道数为2,即得到两个值;第二个部分得到(bounding box regrssion)边框回归的结果,因为
12
×
12
12×12的图像并不能保证,方形框能够完美的框住人脸,所以输出包含的信息都是误差信息,通道数为4,有4个方面的信息,边框左上角的横坐标的相对偏移信息、边框左上角纵坐标的相对偏移信息、标定框宽度的误差、标定框高度的误差;第三个部分给出了人脸的5个关键点的位置,分别是左眼位置、右眼位置、鼻子位置、嘴巴左位置、嘴巴右位置,每个关键位置使用两个维度表示,故而输出是
1
×
1
×
10
1×1×10。
70
×
70
70times 70
70
−
2
2
−
2
−
2
=
30
frac{70-2}{2} -2 -2 =30
270−2−2−2=30,即一个5通道的
30
×
30
30times 30
30×30的特征图。这就意味着该图经过p的一次滑窗操作,得到
30
×
30
=
900
30times 30=900
30×30=900个建议框,而每个建议框对应1个置信度与4个偏移量。再经nms把置信度分数大于设定的阈值0.6对应的建议框保留下来,将其对应的边框偏移量经边框回归操作,得到在原图中的坐标信息,即得到符合P-Net的这些建议框了。之后传给R-Net。
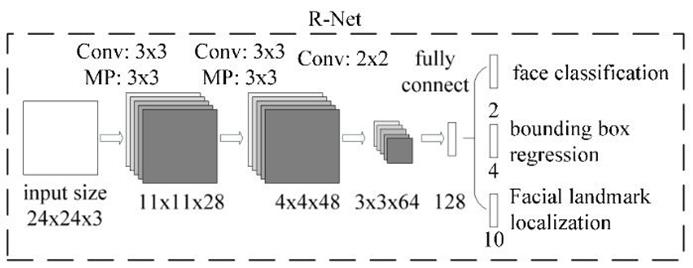
2.5 R-Net
R-Net(Refine Network),从网络图可以看到,该网络结构只是和P-Net网络结构多了一个全连接层。图片在输入R-Net之前,都需要缩放到24x24x3。网络的输出与P-Net是相同的,R-Net的目的是为了去除大量的非人脸框。
2.6 O-Net
O-Net(Output Network),该层比R-Net层又多了一层卷积层,所以处理的结果会更加精细。输入的图像大小48x48x3,输出包括N个边界框的坐标信息,score以及关键点位置。
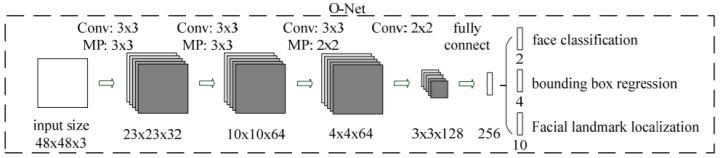
从P-Net到R-Net,再到最后的O-Net,网络输入的图像越来越大,卷积层的通道数越来越多,网络的深度(层数)也越来越深,因此识别人脸的准确率应该也是越来越高的。
3. 工程实践(基于Keras)
点击此处下载人脸数据集。该数据集有32,203张图片,共有93,703张脸被标记。

MTCNN网络定义,按照上述网络结构完成定义,代码按照P-Net、R-Net、O-Net进行模块化设计,在mtcnn的网络构建过程中将其整合。mtcnn.py代码如下:
from keras.layers import Conv2D, Input,MaxPool2D, Reshape,Activation,Flatten, Dense, Permute
from keras.layers.advanced_activations import PReLU
from keras.models import Model, Sequential
import tensorflow as tf
import numpy as np
import utils
import cv2
#-----------------------------#
# 粗略获取人脸框
# 输出bbox位置和是否有人脸
#-----------------------------#
def create_Pnet(weight_path):
input = Input(shape=[None, None, 3])
x = Conv2D(10, (3, 3), strides=1, padding='valid', name='conv1')(input)
x = PReLU(shared_axes=[1,2],name='PReLU1')(x)
x = MaxPool2D(pool_size=2)(x)
x = Conv2D(16, (3, 3), strides=1, padding='valid', name='conv2')(x)
x = PReLU(shared_axes=[1,2],name='PReLU2')(x)
x = Conv2D(32, (3, 3), strides=1, padding='valid', name='conv3')(x)
x = PReLU(shared_axes=[1,2],name='PReLU3')(x)
classifier = Conv2D(2, (1, 1), activation='softmax', name='conv4-1')(x)
# 无激活函数,线性。
bbox_regress = Conv2D(4, (1, 1), name='conv4-2')(x)
model = Model([input], [classifier, bbox_regress])
model.load_weights(weight_path, by_name=True)
return model
#-----------------------------#
# mtcnn的第二段
# 精修框
#-----------------------------#
def create_Rnet(weight_path):
input = Input(shape=[24, 24, 3])
# 24,24,3 -> 11,11,28
x = Conv2D(28, (3, 3), strides=1, padding='valid', name='conv1')(input)
x = PReLU(shared_axes=[1, 2], name='prelu1')(x)
x = MaxPool2D(pool_size=3,strides=2, padding='same')(x)
# 11,11,28 -> 4,4,48
x = Conv2D(48, (3, 3), strides=1, padding='valid', name='conv2')(x)
x = PReLU(shared_axes=[1, 2], name='prelu2')(x)
x = MaxPool2D(pool_size=3, strides=2)(x)
# 4,4,48 -> 3,3,64
x = Conv2D(64, (2, 2), strides=1, padding='valid', name='conv3')(x)
x = PReLU(shared_axes=[1, 2], name='prelu3')(x)
# 3,3,64 -> 64,3,3
x = Permute((3, 2, 1))(x)
x = Flatten()(x)
# 576 -> 128
x = Dense(128, name='conv4')(x)
x = PReLU( name='prelu4')(x)
# 128 -> 2 128 -> 4
classifier = Dense(2, activation='softmax', name='conv5-1')(x)
bbox_regress = Dense(4, name='conv5-2')(x)
model = Model([input], [classifier, bbox_regress])
model.load_weights(weight_path, by_name=True)
return model
#-----------------------------#
# mtcnn的第三段
# 精修框并获得五个点
#-----------------------------#
def create_Onet(weight_path):
input = Input(shape = [48,48,3])
# 48,48,3 -> 23,23,32
x = Conv2D(32, (3, 3), strides=1, padding='valid', name='conv1')(input)
x = PReLU(shared_axes=[1,2],name='prelu1')(x)
x = MaxPool2D(pool_size=3, strides=2, padding='same')(x)
# 23,23,32 -> 10,10,64
x = Conv2D(64, (3, 3), strides=1, padding='valid', name='conv2')(x)
x = PReLU(shared_axes=[1,2],name='prelu2')(x)
x = MaxPool2D(pool_size=3, strides=2)(x)
# 8,8,64 -> 4,4,64
x = Conv2D(64, (3, 3), strides=1, padding='valid', name='conv3')(x)
x = PReLU(shared_axes=[1,2],name='prelu3')(x)
x = MaxPool2D(pool_size=2)(x)
# 4,4,64 -> 3,3,128
x = Conv2D(128, (2, 2), strides=1, padding='valid', name='conv4')(x)
x = PReLU(shared_axes=[1,2],name='prelu4')(x)
# 3,3,128 -> 128,12,12
x = Permute((3,2,1))(x)
# 1152 -> 256
x = Flatten()(x)
x = Dense(256, name='conv5') (x)
x = PReLU(name='prelu5')(x)
# 鉴别
# 256 -> 2 256 -> 4 256 -> 10
classifier = Dense(2, activation='softmax',name='conv6-1')(x)
bbox_regress = Dense(4,name='conv6-2')(x)
landmark_regress = Dense(10,name='conv6-3')(x)
model = Model([input], [classifier, bbox_regress, landmark_regress])
model.load_weights(weight_path, by_name=True)
return model
class mtcnn():
def __init__(self):
self.Pnet = create_Pnet('model_data/pnet.h5')
self.Rnet = create_Rnet('model_data/rnet.h5')
self.Onet = create_Onet('model_data/onet.h5')
def detectFace(self, img, threshold):
#-----------------------------#
# 归一化,加快收敛速度
# 把[0,255]映射到(-1,1)
#-----------------------------#
copy_img = (img.copy() - 127.5) / 127.5
origin_h, origin_w, _ = copy_img.shape
#-----------------------------#
# 计算原始输入图像
# 每一次缩放的比例
#-----------------------------#
scales = utils.calculateScales(img)
out = []
#-----------------------------#
# 粗略计算人脸框
# pnet部分
#-----------------------------#
for scale in scales:
hs = int(origin_h * scale)
ws = int(origin_w * scale)
scale_img = cv2.resize(copy_img, (ws, hs))
inputs = scale_img.reshape(1, *scale_img.shape)
# 图像金字塔中的每张图片分别传入Pnet得到output
output = self.Pnet.predict(inputs)
# 将所有output加入out
out.append(output)
image_num = len(scales)
rectangles = []
for i in range(image_num):
# 有人脸的概率
cls_prob = out[i][0][0][:,:,1]
# 其对应的框的位置
roi = out[i][1][0]
# 取出每个缩放后图片的长宽
out_h, out_w = cls_prob.shape
out_side = max(out_h, out_w)
print(cls_prob.shape)
# 解码过程
rectangle = utils.detect_face_12net(cls_prob, roi, out_side, 1 / scales[i], origin_w, origin_h, threshold[0])
rectangles.extend(rectangle)
# 进行非极大抑制
rectangles = utils.NMS(rectangles, 0.7)
if len(rectangles) == 0:
return rectangles
#-----------------------------#
# 稍微精确计算人脸框
# Rnet部分
#-----------------------------#
predict_24_batch = []
for rectangle in rectangles:
crop_img = copy_img[int(rectangle[1]):int(rectangle[3]), int(rectangle[0]):int(rectangle[2])]
scale_img = cv2.resize(crop_img, (24, 24))
predict_24_batch.append(scale_img)
predict_24_batch = np.array(predict_24_batch)
out = self.Rnet.predict(predict_24_batch)
cls_prob = out[0]
cls_prob = np.array(cls_prob)
roi_prob = out[1]
roi_prob = np.array(roi_prob)
rectangles = utils.filter_face_24net(cls_prob, roi_prob, rectangles, origin_w, origin_h, threshold[1])
if len(rectangles) == 0:
return rectangles
#-----------------------------#
# 计算人脸框
# onet部分
#-----------------------------#
predict_batch = []
for rectangle in rectangles:
crop_img = copy_img[int(rectangle[1]):int(rectangle[3]), int(rectangle[0]):int(rectangle[2])]
scale_img = cv2.resize(crop_img, (48, 48))
predict_batch.append(scale_img)
predict_batch = np.array(predict_batch)
output = self.Onet.predict(predict_batch)
cls_prob = output[0]
roi_prob = output[1]
pts_prob = output[2]
rectangles = utils.filter_face_48net(cls_prob, roi_prob, pts_prob, rectangles, origin_w, origin_h, threshold[2])
return rectangles
当有了mtcnn定义之后,可以利用其作为自己的模块来进行调用,推理,detect.py代码如下:
import cv2
import numpy as np
from mtcnn import mtcnn
img = cv2.imread('img/test1.jpg')
model = mtcnn()
threshold = [0.5,0.6,0.7] # 三段网络的置信度阈值不同
rectangles = model.detectFace(img, threshold)
draw = img.copy()
for rectangle in rectangles:
if rectangle is not None:
W = -int(rectangle[0]) + int(rectangle[2])
H = -int(rectangle[1]) + int(rectangle[3])
paddingH = 0.01 * W
paddingW = 0.02 * H
crop_img = img[int(rectangle[1]+paddingH):int(rectangle[3]-paddingH), int(rectangle[0]-paddingW):int(rectangle[2]+paddingW)]
if crop_img is None:
continue
if crop_img.shape[0] < 0 or crop_img.shape[1] < 0:
continue
cv2.rectangle(draw, (int(rectangle[0]), int(rectangle[1])), (int(rectangle[2]), int(rectangle[3])), (255, 0, 0), 1)
for i in range(5, 15, 2):
cv2.circle(draw, (int(rectangle[i + 0]), int(rectangle[i + 1])), 2, (0, 255, 0))
cv2.imwrite("img/out.jpg",draw)
cv2.imshow("test", draw)
c = cv2.waitKey(0)
其中,用到的工具类助手如下,实现了非极大值抑制已经网络的后处理等过程逻辑。
import sys
from operator import itemgetter
import numpy as np
import cv2
import matplotlib.pyplot as plt
#-----------------------------#
# 计算原始输入图像
# 每一次缩放的比例
#-----------------------------#
def calculateScales(img):
copy_img = img.copy()
pr_scale = 1.0
h,w,_ = copy_img.shape
# 引申优化项 = resize(h*500/min(h,w), w*500/min(h,w))
if min(w,h)>500:
pr_scale = 500.0/min(h,w)
w = int(w*pr_scale)
h = int(h*pr_scale)
elif max(w,h)<500:
pr_scale = 500.0/max(h,w)
w = int(w*pr_scale)
h = int(h*pr_scale)
scales = []
factor = 0.709
factor_count = 0
minl = min(h,w)
while minl >= 12:
scales.append(pr_scale*pow(factor, factor_count))
minl *= factor
factor_count += 1
return scales
#-------------------------------------#
# 对pnet处理后的结果进行处理
#-------------------------------------#
def detect_face_12net(cls_prob,roi,out_side,scale,width,height,threshold):
cls_prob = np.swapaxes(cls_prob, 0, 1)
roi = np.swapaxes(roi, 0, 2)
stride = 0
# stride略等于2
if out_side != 1:
stride = float(2*out_side-1)/(out_side-1)
(x,y) = np.where(cls_prob>=threshold)
boundingbox = np.array([x,y]).T
# 找到对应原图的位置
bb1 = np.fix((stride * (boundingbox) + 0 ) * scale)
bb2 = np.fix((stride * (boundingbox) + 11) * scale)
# plt.scatter(bb1[:,0],bb1[:,1],linewidths=1)
# plt.scatter(bb2[:,0],bb2[:,1],linewidths=1,c='r')
# plt.show()
boundingbox = np.concatenate((bb1,bb2),axis = 1)
dx1 = roi[0][x,y]
dx2 = roi[1][x,y]
dx3 = roi[2][x,y]
dx4 = roi[3][x,y]
score = np.array([cls_prob[x,y]]).T
offset = np.array([dx1,dx2,dx3,dx4]).T
boundingbox = boundingbox + offset*12.0*scale
rectangles = np.concatenate((boundingbox,score),axis=1)
rectangles = rect2square(rectangles)
pick = []
for i in range(len(rectangles)):
x1 = int(max(0 ,rectangles[i][0]))
y1 = int(max(0 ,rectangles[i][1]))
x2 = int(min(width ,rectangles[i][2]))
y2 = int(min(height,rectangles[i][3]))
sc = rectangles[i][4]
if x2>x1 and y2>y1:
pick.append([x1,y1,x2,y2,sc])
return NMS(pick,0.3)
#-----------------------------#
# 将长方形调整为正方形
#-----------------------------#
def rect2square(rectangles):
w = rectangles[:,2] - rectangles[:,0]
h = rectangles[:,3] - rectangles[:,1]
l = np.maximum(w,h).T
rectangles[:,0] = rectangles[:,0] + w*0.5 - l*0.5
rectangles[:,1] = rectangles[:,1] + h*0.5 - l*0.5
rectangles[:,2:4] = rectangles[:,0:2] + np.repeat([l], 2, axis = 0).T
return rectangles
#-------------------------------------#
# 非极大抑制
#-------------------------------------#
def NMS(rectangles,threshold):
if len(rectangles)==0:
return rectangles
boxes = np.array(rectangles)
x1 = boxes[:,0]
y1 = boxes[:,1]
x2 = boxes[:,2]
y2 = boxes[:,3]
s = boxes[:,4]
area = np.multiply(x2-x1+1, y2-y1+1)
I = np.array(s.argsort())
pick = []
while len(I)>0:
xx1 = np.maximum(x1[I[-1]], x1[I[0:-1]]) #I[-1] have hightest prob score, I[0:-1]->others
yy1 = np.maximum(y1[I[-1]], y1[I[0:-1]])
xx2 = np.minimum(x2[I[-1]], x2[I[0:-1]])
yy2 = np.minimum(y2[I[-1]], y2[I[0:-1]])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
o = inter / (area[I[-1]] + area[I[0:-1]] - inter)
pick.append(I[-1])
I = I[np.where(o<=threshold)[0]]
result_rectangle = boxes[pick].tolist()
return result_rectangle
#-------------------------------------#
# 对Rnet处理后的结果进行处理
#-------------------------------------#
def filter_face_24net(cls_prob,roi,rectangles,width,height,threshold):
prob = cls_prob[:,1]
pick = np.where(prob>=threshold)
rectangles = np.array(rectangles)
x1 = rectangles[pick,0]
y1 = rectangles[pick,1]
x2 = rectangles[pick,2]
y2 = rectangles[pick,3]
sc = np.array([prob[pick]]).T
dx1 = roi[pick,0]
dx2 = roi[pick,1]
dx3 = roi[pick,2]
dx4 = roi[pick,3]
w = x2-x1
h = y2-y1
x1 = np.array([(x1+dx1*w)[0]]).T
y1 = np.array([(y1+dx2*h)[0]]).T
x2 = np.array([(x2+dx3*w)[0]]).T
y2 = np.array([(y2+dx4*h)[0]]).T
rectangles = np.concatenate((x1,y1,x2,y2,sc),axis=1)
rectangles = rect2square(rectangles)
pick = []
for i in range(len(rectangles)):
x1 = int(max(0 ,rectangles[i][0]))
y1 = int(max(0 ,rectangles[i][1]))
x2 = int(min(width ,rectangles[i][2]))
y2 = int(min(height,rectangles[i][3]))
sc = rectangles[i][4]
if x2>x1 and y2>y1:
pick.append([x1,y1,x2,y2,sc])
return NMS(pick,0.3)
#-------------------------------------#
# 对onet处理后的结果进行处理
#-------------------------------------#
def filter_face_48net(cls_prob,roi,pts,rectangles,width,height,threshold):
prob = cls_prob[:,1]
pick = np.where(prob>=threshold)
rectangles = np.array(rectangles)
x1 = rectangles[pick,0]
y1 = rectangles[pick,1]
x2 = rectangles[pick,2]
y2 = rectangles[pick,3]
sc = np.array([prob[pick]]).T
dx1 = roi[pick,0]
dx2 = roi[pick,1]
dx3 = roi[pick,2]
dx4 = roi[pick,3]
w = x2-x1
h = y2-y1
pts0= np.array([(w*pts[pick,0]+x1)[0]]).T
pts1= np.array([(h*pts[pick,5]+y1)[0]]).T
pts2= np.array([(w*pts[pick,1]+x1)[0]]).T
pts3= np.array([(h*pts[pick,6]+y1)[0]]).T
pts4= np.array([(w*pts[pick,2]+x1)[0]]).T
pts5= np.array([(h*pts[pick,7]+y1)[0]]).T
pts6= np.array([(w*pts[pick,3]+x1)[0]]).T
pts7= np.array([(h*pts[pick,8]+y1)[0]]).T
pts8= np.array([(w*pts[pick,4]+x1)[0]]).T
pts9= np.array([(h*pts[pick,9]+y1)[0]]).T
x1 = np.array([(x1+dx1*w)[0]]).T
y1 = np.array([(y1+dx2*h)[0]]).T
x2 = np.array([(x2+dx3*w)[0]]).T
y2 = np.array([(y2+dx4*h)[0]]).T
rectangles=np.concatenate((x1,y1,x2,y2,sc,pts0,pts1,pts2,pts3,pts4,pts5,pts6,pts7,pts8,pts9),axis=1)
pick = []
for i in range(len(rectangles)):
x1 = int(max(0 ,rectangles[i][0]))
y1 = int(max(0 ,rectangles[i][1]))
x2 = int(min(width ,rectangles[i][2]))
y2 = int(min(height,rectangles[i][3]))
if x2>x1 and y2>y1:
pick.append([x1,y1,x2,y2,rectangles[i][4],
rectangles[i][5],rectangles[i][6],rectangles[i][7],rectangles[i][8],rectangles[i][9],rectangles[i][10],rectangles[i][11],rectangles[i][12],rectangles[i][13],rectangles[i][14]])
return NMS(pick,0.3)


原文地址:https://blog.csdn.net/qq_38853759/article/details/129651261
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_17989.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!