本文介绍: 本项目通过爬虫技术获取图片,利用OpenCV库对图像进行处理,识别并切割出人物脸部,形成了一个用于训练的数据集。通过ImageAI进行训练,最终实现了对动漫人物的识别模型。同时,本项目还开发了一个线上Web应用,使得用户可以方便地体验和使用该模型。

前言
本项目通过爬虫技术获取图片,利用OpenCV库对图像进行处理,识别并切割出人物脸部,形成了一个用于训练的数据集。通过ImageAI进行训练,最终实现了对动漫人物的识别模型。同时,本项目还开发了一个线上Web应用,使得用户可以方便地体验和使用该模型。
首先,项目使用爬虫技术从网络上获取图片。这些图片包含各种动漫人物,其中我们只对人物脸部进行训练,所以我们会对图像进行处理,并最终将这些图像将作为训练数据的来源。
其次,利用OpenCV库对这些图像进行处理,包括人脸检测、图像增强等步骤,以便准确识别并切割出人物脸部。这一步是为了构建一个清晰而准确的数据集,用于模型的训练。
接下来,通过ImageAI进行训练。ImageAI是一个简化图像识别任务的库,它可以方便地用于训练模型,这里用于训练动漫人物的识别模型。
总体设计
系统整体结构图
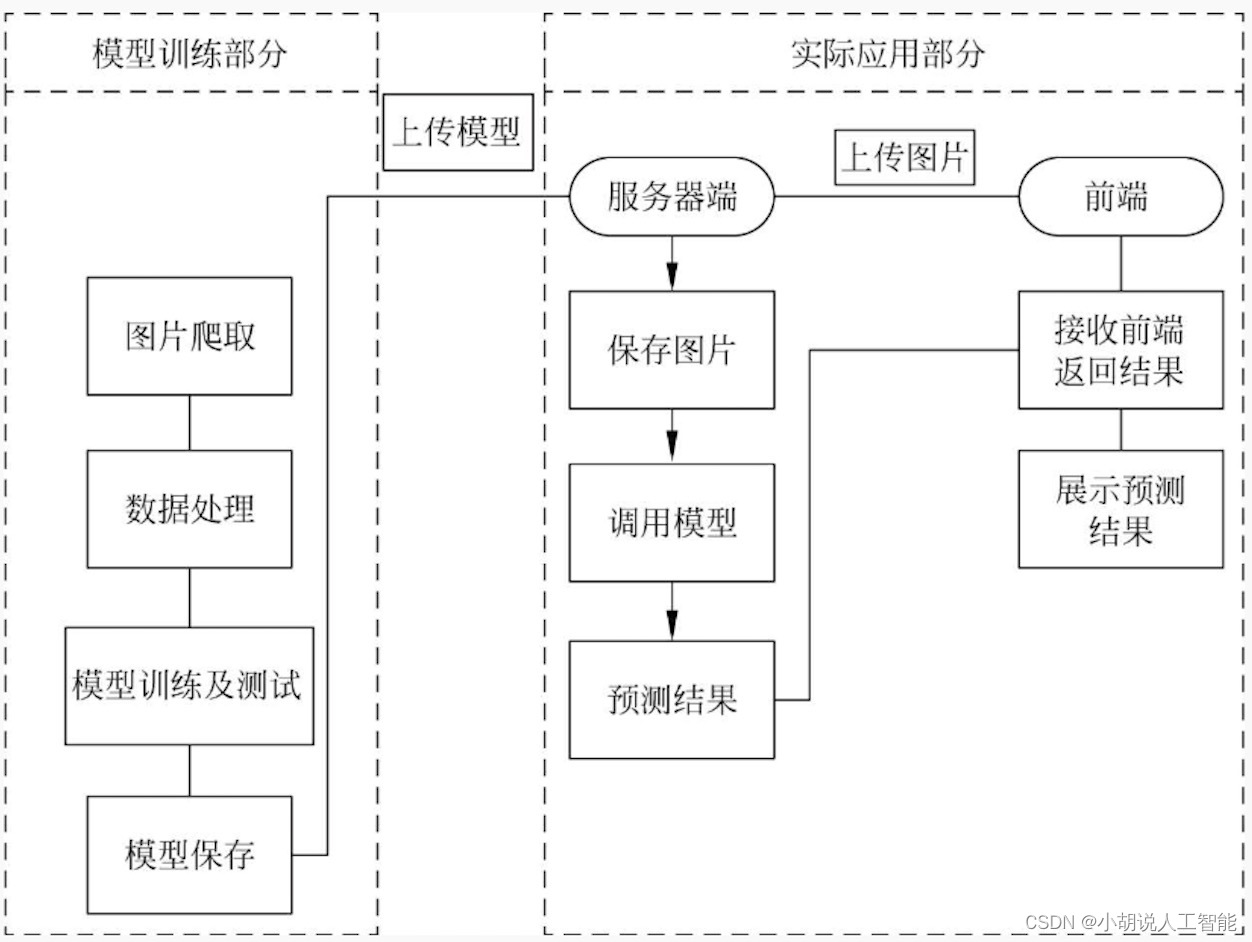
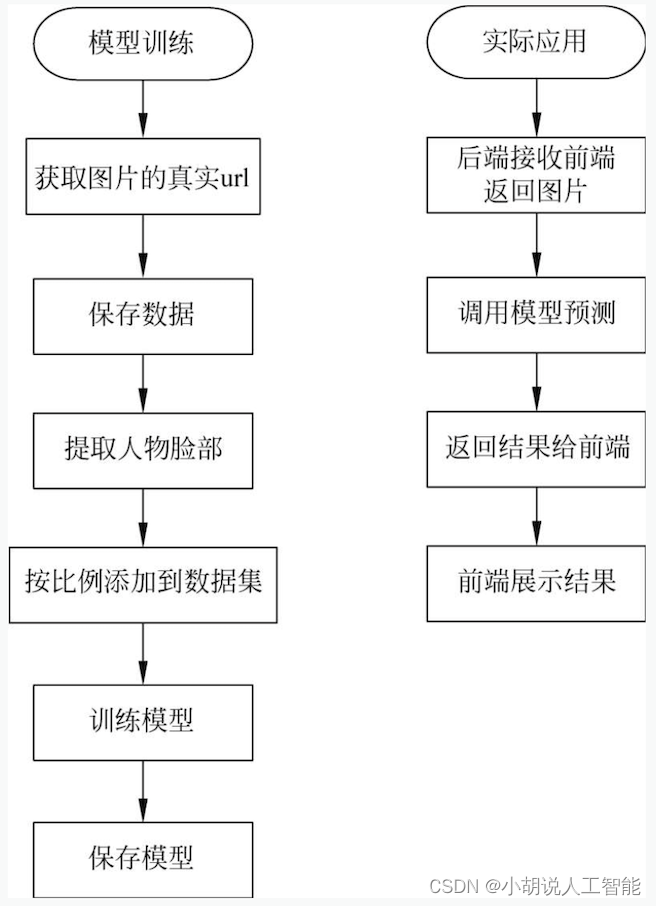
系统流程图
运行环境
爬虫
1.安装Anaconda
2.安装Python3.6
3.更换pip源
4.安装Python包
5.下载phantomjs
模型训练
1.安装依赖
2.安装lmageAl
实际应用
1.前端
2.安装Flask
3.安装Nginx
相关其它博客
工程源代码下载
其它资料下载
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。