本章介绍python是数组库——numpy的使用。numpy数组对于表格的学习具有很重要的作用,特别是pandas,学好numpy,为pandas打好基础。
1. 创建数组
(1)np.array()


(2)np.arange()

2. 创建多维数组
(1)创建二维数组

(3)创建多维数组

3. 创建特殊数组
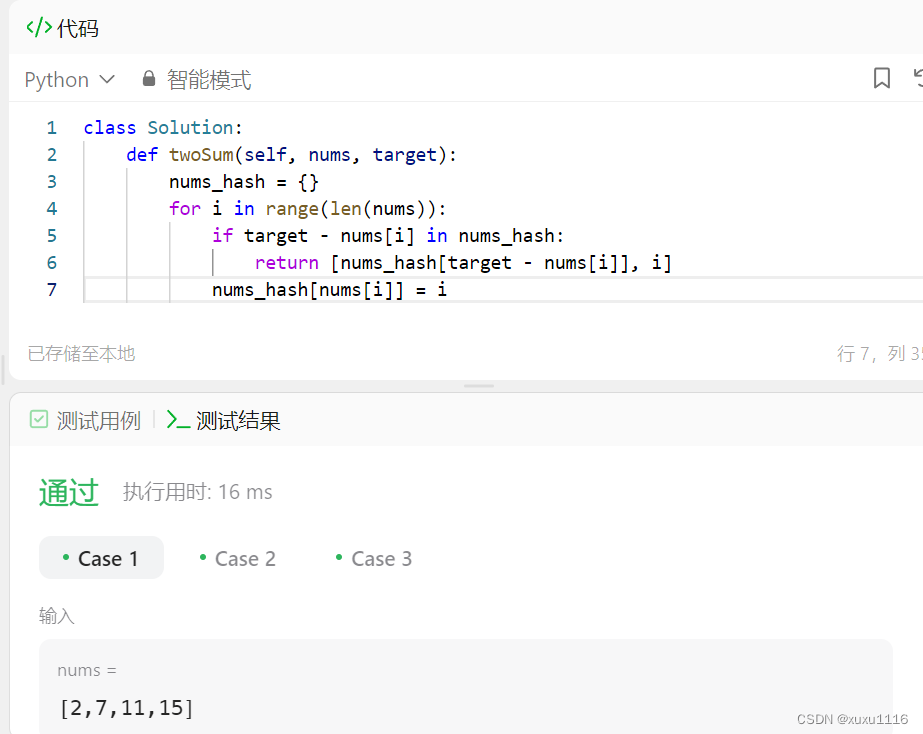
(1)np.ones()


(2)np.zeros()

(3)np.full()

(4)np.eye()

(5)np.diag()


4. 数组模板创建数组
(1)np.ones_like()
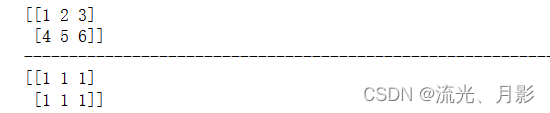
(2)np.zeros_like()

(3)np.full_like()

5. 数组的属性

6. numpy中的 random随机库
(1)随机数生成

(2)np.random.choice()

(3)np.random.shuffle()

(4)np.random.permutation()

7. 数组维度/形状的转换/转置
(1)arr.reshape()


(2)arr.flatten()

(3)arr.T 或 arr.transpose() 二维数组转置

8. 数组的运算
(1)数组和数字之间的加减乘除

(2)数组与数组之间的加减乘除(形状一样 个案对位)

(3)数组与数组之间的加减乘除(形状不一样 但行/列对位)

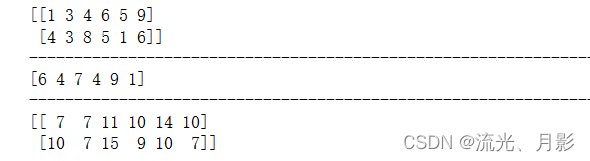
9. 数据选取/数据切片
(1)一维数组

(2)二维数组


10. 神奇索引
(1)一维

(2)二维
① 取行

② 取列

③ 对位取值


11. 数组元素的筛选/条件统计
(1)筛选出符合条件的值

(2)统计出符合条件的数的个数

(3)多条件筛选

12. 更改元素的值
(1)全局更改
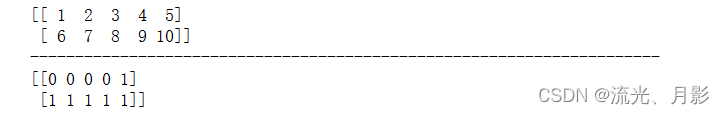
 这里也是,要
这里也是,要(2)局部更改(二次切片)

(3)np.where() 条件更改


13. 轴与数组元素的排序
(1)arr.sort(axis=1) 排序
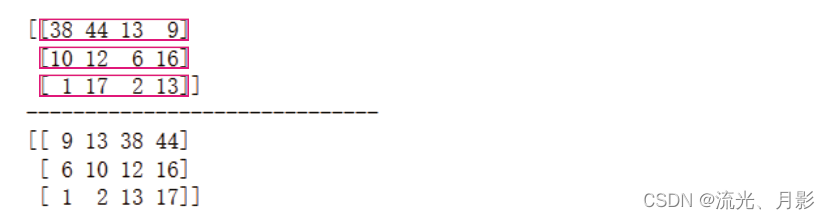

(2)arr.argsort() 排序对应的索引位置

(3)arr.argmax() 最大值所在的索引位置

(4)arr.argmin() 最小值所在的索引位置

(5)np.maximum()、np.minimum() 同位数比较取值

14. 轴与数组的加法/乘法
(1)一维

(2)二维

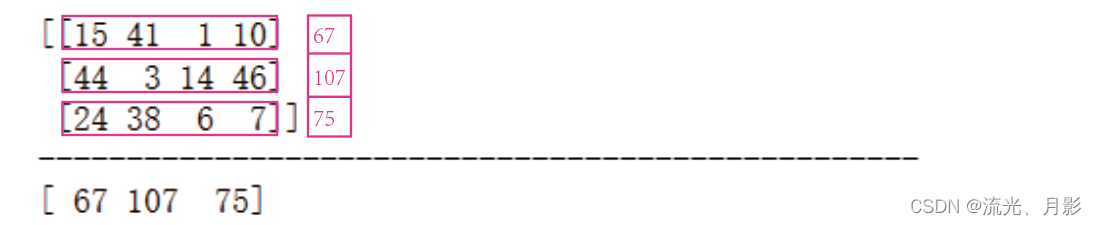
15. 轴与数组的累计加法/累计乘法
(1)一维


(2)二维
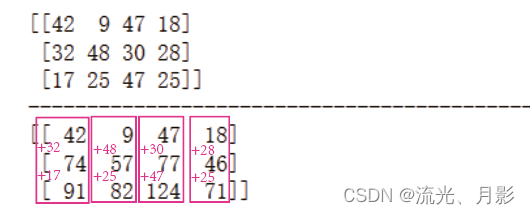

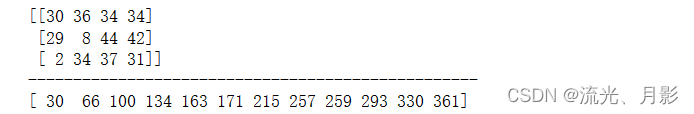
16. 索引量统计 np.bincount()

17. 数组合并
(1)np.vstack() 纵向合并

(2)np.hstack() 横向合并

(3)np.concatenate() 纵向/横向合并

18. 数组拆分
(1)np.hsplit()

(2)np.vsplit()

(3)np.split()
 同理,np.s
同理,np.s19.关于数学和统计的其他函数
20. any()和all()


21. np.unique() 去重
22. np.in1d() 共同元素判断
23. 浅拷贝与深拷贝
(1)浅拷贝

(2)深拷贝

(3)对比浅拷贝与深拷贝
结尾
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。