本文介绍: 但是有限制: 16,000Hz的audio sample, 80 channels,25 millisseconds的窗口,移动距离为 10 milliseconds。它在decoding(decoding.py)阶段,只需要依靠 self.tokenizer.timestamp 里的数据来,只要知道一段语音的开始,就能反推结束,因为一段语音的分割结尾即是另一个语音的开始。mel 比 STFT更少的特征数量,也更接近人类感知,Mel 频谱通过在较低频率提供更多的分辨率,有助于减少背景噪音的影响。
使后感
因为运用里需要考虑到时效和准确性,类似于YOLO,只考虑 tiny, base,和small 的模型。准确率基本反应了模型的大小,即越大的模型有越高的准确率
Paper Review
个人觉得有趣的
Log Mel spectrogram & STFT
Training
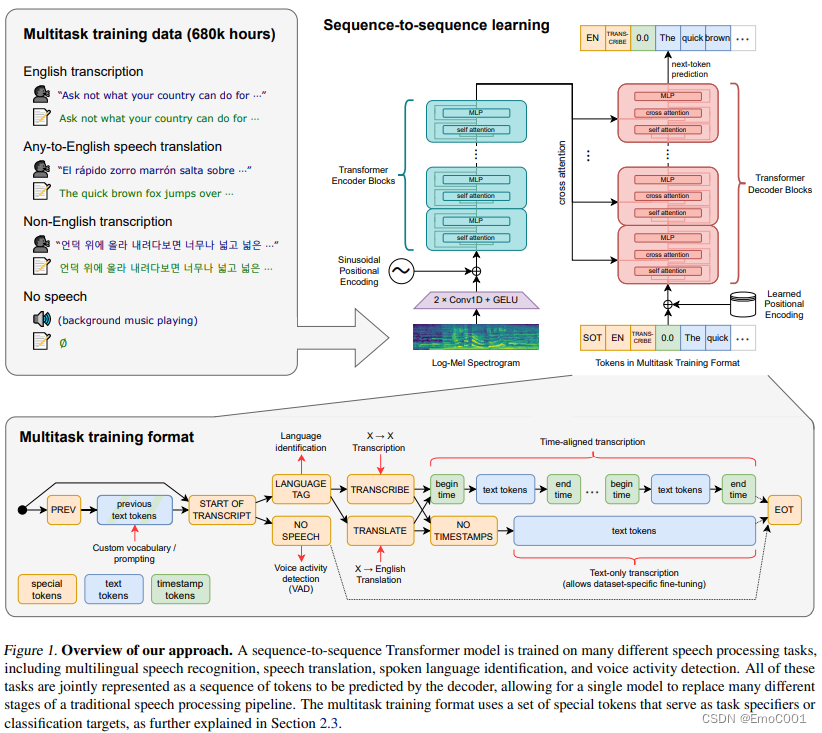
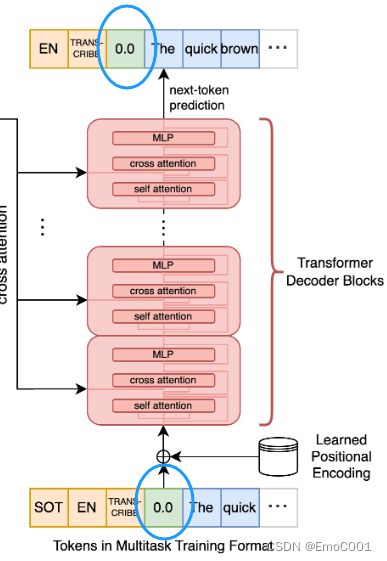
cross–attention输入
SOT: start of trascription token
EN: English token
TRANS-CRIBE: token
timestamp
balabalabala(真的语音转成的文字)
cross–attention输出
EN: English token
TRANS-CRIBE: token
timestamp
balabalabala(真的语音转成的文字)
positional encoding
在这里面用到了不同的positional encoding,只是不确定如果不一样会不会有什么影响。挖个坑先(后面把这里填了)
输入用的是Sinusoidal Positional Encoding
输出用的是 Learned Positional Encoding
数据
Decoding
为什么可以有时间戳的信息
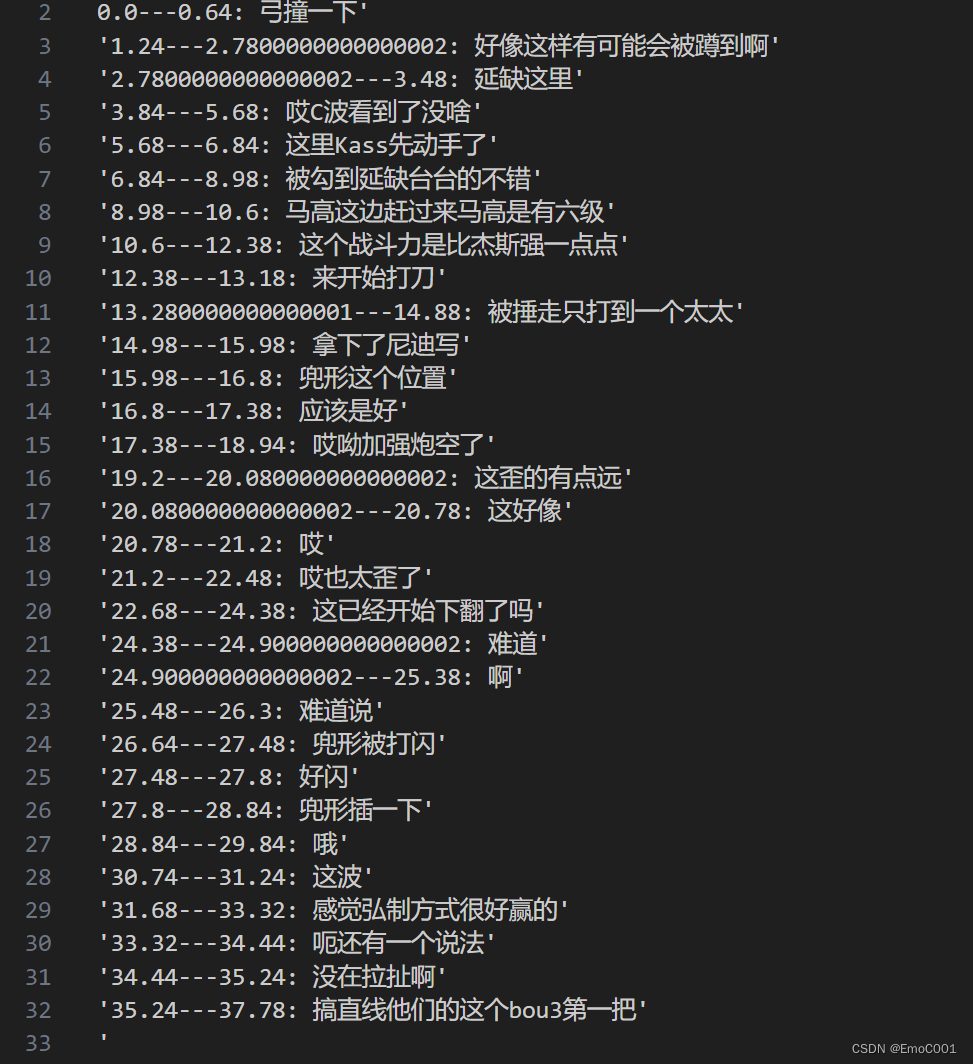
Test code
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。





