替换IP:PORT信息中的某一段信息,用于IP:端口信息的脱敏。
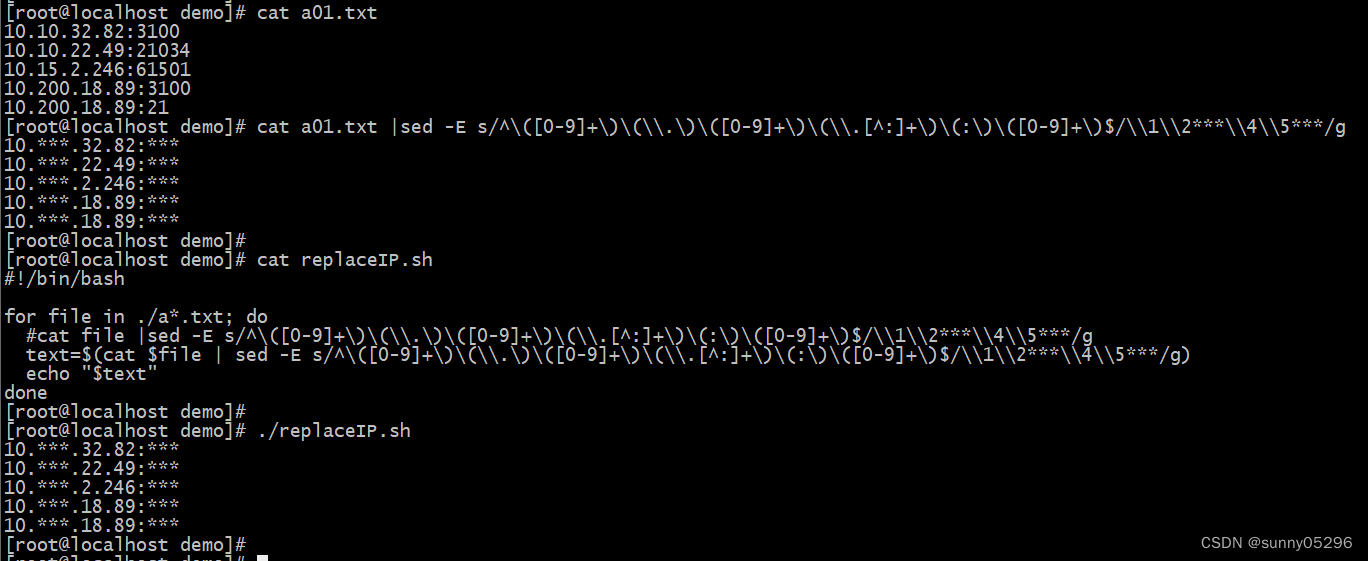
10.10.32.82:3100
10.10.22.49:21034
10.15.2.246:61501
10.200.18.89:3100
10.200.18.89:21
#!/bin/bash
for file in ./a*.txt; do
#cat file |sed -E s/^([0-9]+)(\.)([0-9]+)(\.[^:]+)(:)([0-9]+)$/\1\2***\4\5***/g
text=$(cat $file | sed -E s/^([0-9]+)(\.)([0-9]+)(\.[^:]+)(:)([0-9]+)$/\1\2***\4\5***/g)
echo "$text"
done10.***.32.82:***
10.***.22.49:***
10.***.2.246:***
10.***.18.89:***
10.***.18.89:***
说明:
1)sed不支持PCRE正则表达式,因此,d和w此处只是普通的无效构造。要匹配任何字母,可以使用[:alpha:] POSIX字符类,或者如果要匹配大写字母,请使用[:upper:]。
2)分组值引用方式:1 代表第一个分组值,2代表第二个分组值,示例中我只需要替换第三个分组和最后一个(第六个)分组,保留第一、第二、第四、第五分组,因此,替换后的表达式中不需要引用第三、第六个捕获组。
POSIX 正则表达式的 BRE / ERE 模式差异:
1)BRE,标准正则表达式,Basic Regular Expressions
2)ERE,扩展正则表达式,Extended Regular Expressions
Linux中,不同的程序支持的REGXP也不同:
sed 只支持BRE的大部分,sed 编辑器要尽可能快的处理数据流中的文本。但通过指定 –r 或 -E 参数也可以支持ERE。
grep 则可以支持ERE,不过要使用-E 选项。
gawk 使用BRE引擎。
BRE 定义的语法符号包括:
. – 匹配任意一个字符。
[] – 字符集匹配,匹配方括号中定义的字符集之一。
[^] – 字符集否定匹配,匹配没有在方括号中定义的字符。
^ – 匹配开始位置。
$ – 匹配结束位置。
() – 定义子表达式。
n – 子表达式向前引用,n 为 1-9 之间的数字。 由于此功能已超出正则语义,需
要在字符串中回溯,因此需要使用 NFA 算法进行匹配。
* – 任意次匹配(零次或多次匹配)。
{m,n} – 至少 m 次,至多 n 次匹配;{m} 表示 m 次精确匹配;{m,} 表示至少 m
次匹配。
ERE 修改了 BRE 中的部分语法,并增加了以下语法符号:
? – 最多一次匹配(零次或一次匹配)。
+ – 至少一次匹配(一次或更多次匹配)。
| – 或运算,其左右操作数均可以为一个子表达式。
同时,ERE 取消了子表达式 “()” 和 次数匹配 “{m,n}” 语法符号的转义符引用语法,在
使用这两种语法符号时,不在需要添加转义符。 与此同时, ERE 也取消了非正则语义的
子表达式向前引用能力。
BRE 和 ERE 共享同样的 POSIX 字符类定义。同时,它们还支持字符类比较操作 “[. .]”
和字符来等效体 “[= =]” 操作,但很少被使用。
f / fr / wfr / bwfr 等工具默认使用 ERE 模式,同时支持以下 perl 风格的字符类:
POSIX 类 perl类 描述
—————————————————————————-
[:alnum:] 字母和数字
[:alpha:] a 字母
[:lower:] l 小写字母
[:upper:] u 大写字母
[:blank:] 空白字符(空格和制表符)
[:space:] s 所有空格符(比[:blank:]包含的范围广)
[:cntrl:] 不可打印的控制字符(退格、删除、警铃…)
[:digit:] d 十进制数字
[:xdigit:] x 十六进制数字
[:graph:] 可打印的非空白字符
[:print:] p 可打印字符
[:punct:] 标点符号
原文地址:https://blog.csdn.net/sunny05296/article/details/134709163
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_18253.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!




