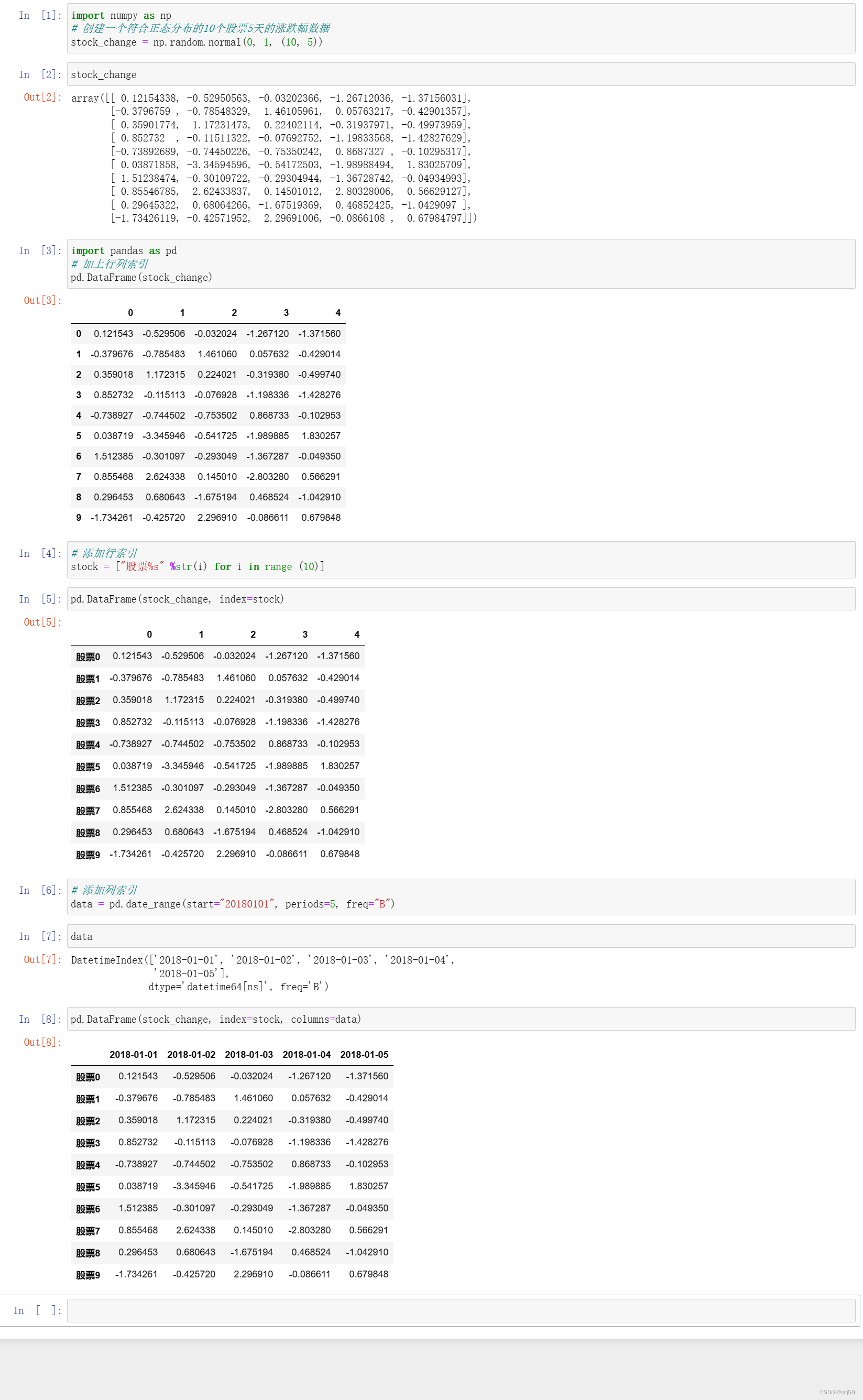
1、pandas中重复索引问题
df = df[~df.index.duplicated()]2、pandas删除重复数据行
# 首先导入常用的两个包
import pandas as pd
import numpy as np
# 1.删除完全重复的行
df.drop_duplicates()
2.按k列进行去重,对于重复项,保留第一次出现的值
df.drop_duplicates('k',keep='first')
3、k2和k1两列进行去重
df.drop_duplicates(['k2','k1'], keep='first')
"""
keep:{‘first’, ‘last’, False}, 默认值 ‘first’
first:保留第一次出现的重复行,删除后面的重复行。
last:删除前面的重复项,保留最后一次出现的重复行。
False:删除所有重复项
"""3、drop_duplicates()函数的语法
df.drop_duplicates(subset=['A','B','C'],keep='first',inplace=True)原文地址:https://blog.csdn.net/weixin_42322206/article/details/127673480
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_18347.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。