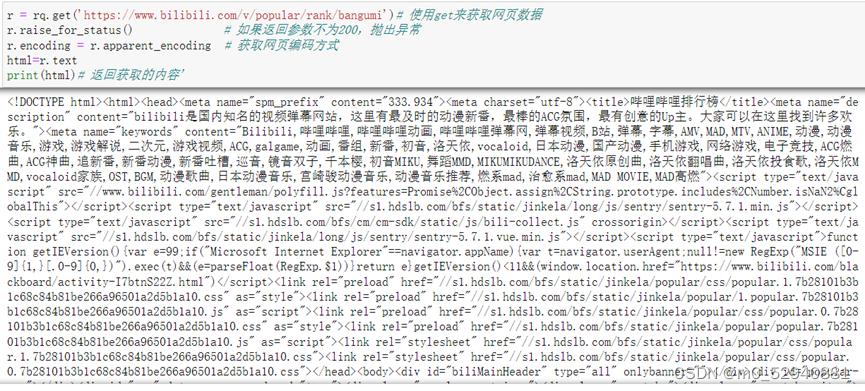
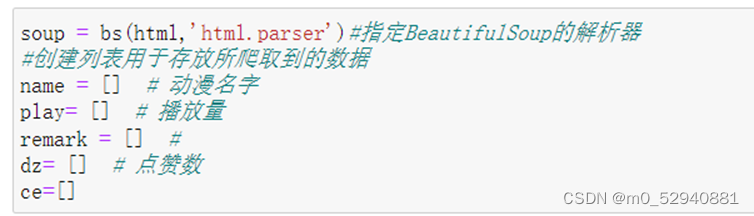
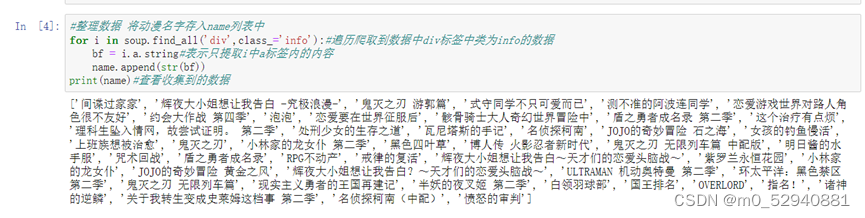
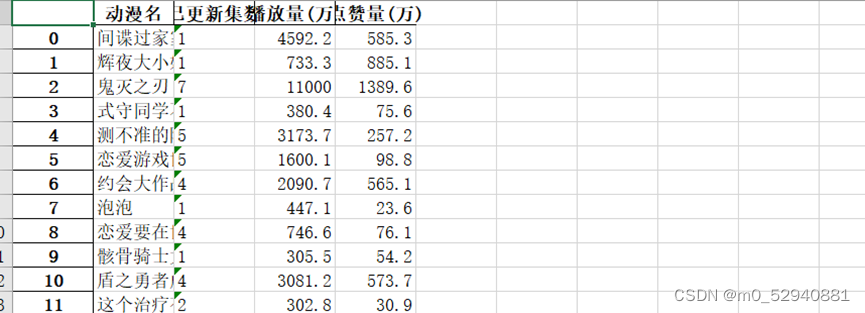
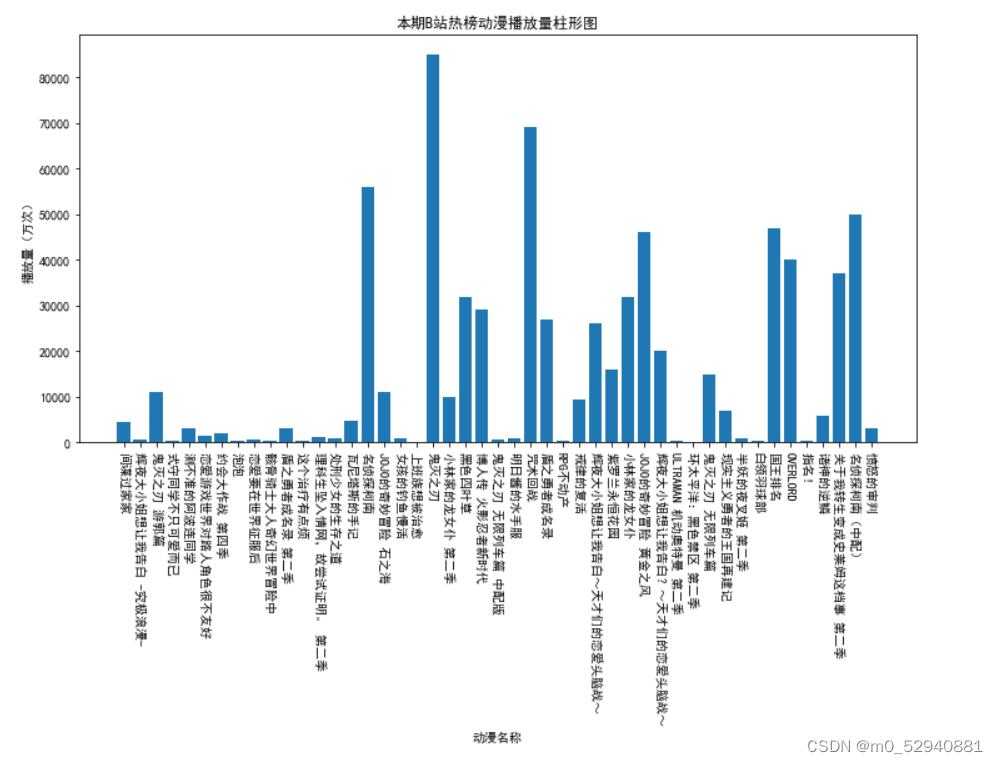
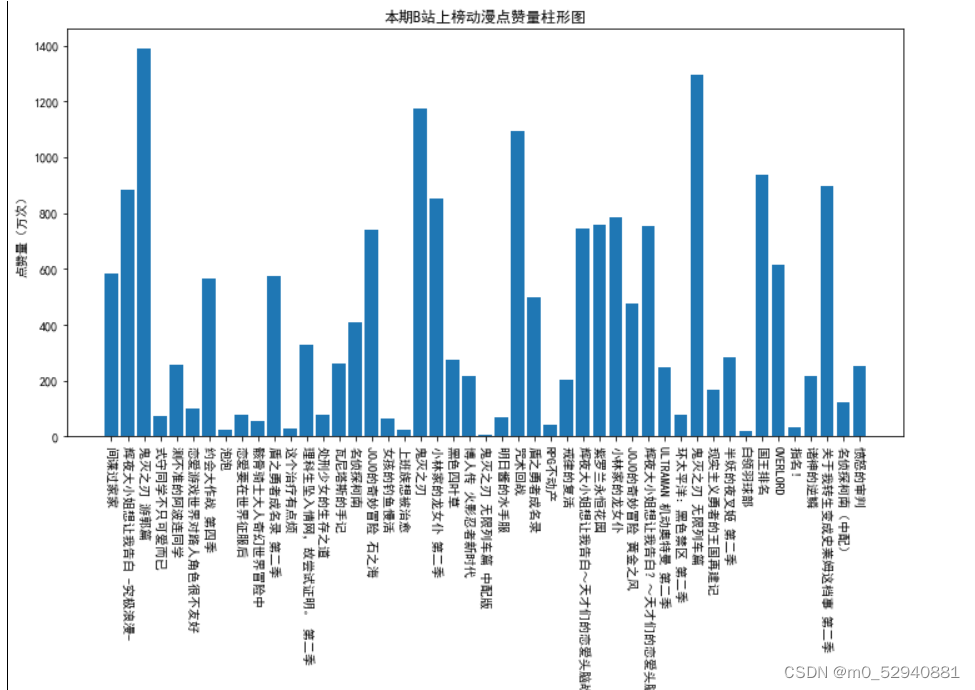
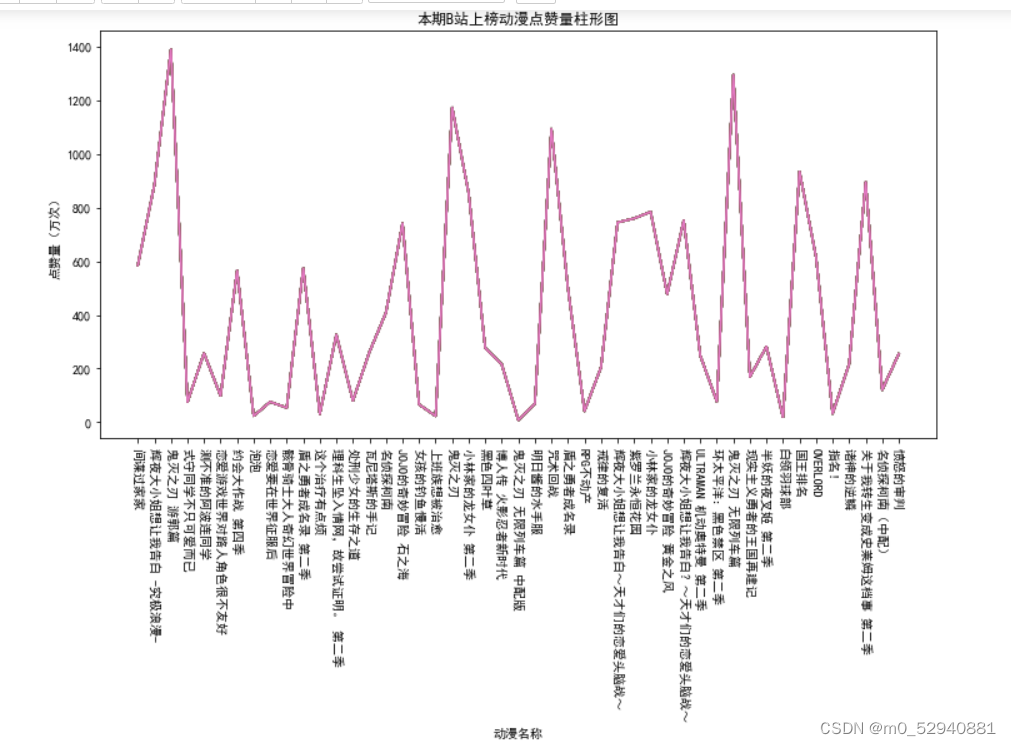
当前位置: 首页python正文 本文介绍: 对于哔哩哔哩动漫排行榜网页信息的爬取及处理(静态网页) 对于哔哩哔哩动漫排行榜网页信息的爬取及处理(静态网页) 1.数据来源: 哔哩哔哩排行榜 2.数据描述: 利用python的第三方库requests对网页进行爬取 利用re库提供的正则表达式对网页数据进行整理,提取 利用bs4库中的beautifulsoup 对整个网页内容进行解析,抓取 利用pandas库将数据整理成excel文件,以及读取csv文件 利用matplotlib库进行数据可视化展示 数据内容共包括:动漫名称,已更新集数,播放量,点赞量4部分 3.数据处理: 利用requests库中提供的get函数对网页源码内容进行获取 通过beautifulsoup的find_all()来进行解析。在这里,find_all()的第一个参数是标签名,第二个是标签中的class值(注意下划线(class_=‘info’))对标签中的数据进行提取 同理对于已更新集数,播放量,点赞量这三项数据也可以通过findall函数进行提取 已更新集数: 播放量: 点赞量: 处理完数据后保存为字典形式并通过pandas提供的DataFrame函数保存为excel文件 4.可视化过程: 通过matplotlib库进行可视化展示 附录(代码部分): #导入所需要的第三方库 from bs4 import BeautifulSoup as bs import requests as rq import pandas as pd import matplotlib.pyplot as plt import re r = rq.get('https://www.bilibili.com/v/popular/rank/bangumi')# 使用get来获取网页数据 r.raise_for_status() # 如果返回参数不为200,抛出异常 r.encoding = r.apparent_encoding # 获取网页编码方式 html=r.text print(html)# 返回获取的内容' soup = bs(html,'html.parser')#指定BeautifulSoup的解析器 #创建列表用于存放所爬取到的数据 name = [] # 动漫名字 play= [] # 播放量 remark = [] # dz= [] # 点赞数 #整理数据 将动漫名字存入name列表中 for i in soup.find_all('div',class_='info'):#遍历爬取到数据中div标签中类为info的数据 bf = i.a.string#表示只提取i中a标签内的内容 name.append(str(bf)) print(name)#查看收集到的数据 #已更新集数存储 for i in soup.find_all('div',class_='detail'): bf = i.find('span',class_='data-box').get_text()#查找i中标签为span且类为data—box中的数据 #r表示声明后面字符不是转义字符 bf =re.search(r'd*d', bf).group()#使用正则表达式匹配bf中的数字字符 play.append(int(bf))#必须统一形式否则后面可视化展示会导致y轴乱序 print(play) #对播放量进行存储 for i in soup.find_all('div', class_='detail'): bf = i.find('span', class_='data-box').next_sibling.next_sibling.get_text() # 统一单位 if '亿' in bf: num = float(re.search(r'd(.d)?', bf).group()) * 10000 #正则表达式提取bf中的数字,因为网页中过亿的数字最多两位 bf=num else: bf = re.search(r'd*(.)?d', bf).group() remark.append(float(bf)) print(remark) #对点赞量进行存储 for i in soup.find_all('div', class_='detail-state'): sc = i.find('span', class_='data-box').next_sibling.next_sibling.get_text() sc = re.search(r'd*(.)?d', sc).group() dz.append(float(sc)) print(dz) info={'动漫名':name,'已更新集数':play,'播放量(万)':remark,'点赞量(万)':dz}#将之前的列表数据储存为字典 并通过pandas导出 file=pd.DataFrame(info) #设置excel文件名称为bilibili 工作表名为动漫数据分析 储存在根目录下 file.to_excel('bilibili.xlsx',sheet_name="动漫数据分析") #对数据进行可视化展示 #为了坐标轴上能显示中文 plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False #创建列表用以储存所需展示的数据 mtname = info['动漫名'] # 动漫名 mtplay = info['已更新集数'] # 更新集数 mtremark = info['播放量(万)'] # 播放量 mtdz = info['点赞量(万)'] # 点赞量 #print(len(mtdz))查看数据有几条 #利用matplot进行绘制图形 #播放量柱形图 p1 = plt.figure(figsize=(12,6)) a1 = p1.add_subplot(1,1,1) plt.title('本期B站热榜动漫播放量柱形图') plt.xlabel('动漫名称') plt.ylabel('播放量(万次)') plt.xticks(rotation=270)#加入此行代码可以让x轴文字竖立 plt.bar(mtname,mtremark) plt.show() #点赞量柱形图 p2 = plt.figure(figsize=(12,6)) a2 = p2.add_subplot(1,1,1) plt.title('本期B站上榜动漫点赞量柱形图') plt.xlabel('动漫名称') plt.ylabel('点赞量(万次)') plt.xticks(rotation=270)#加入此行代码可以让x轴文字竖立 plt.bar(mtname,mtdz) plt.show() #播放量折线图 p3 = plt.figure(figsize=(12,6)) a3 = p3.add_subplot(1,1,1) plt.title('本期B站上榜动漫点赞量折线图') plt.xlabel('动漫名称') plt.ylabel('播放量(万次)') plt.xticks(rotation=270)#加入此行代码可以让x轴文字竖立 for i in range(47): plt.plot(mtname,mtremark) plt.show() #播放量折线图 p4 = plt.figure(figsize=(12,6)) a4 = p4.add_subplot(1,1,1) plt.title('本期B站上榜动漫点赞量折线图') plt.xlabel('动漫名称') plt.ylabel('点赞量(万次)') plt.xticks(rotation=270)#加入此行代码可以让x轴文字竖立 for i in range(47): plt.plot(mtname,mtdz) plt.show() p5 = plt.figure(figsize=(12,6)) ax1=p5.add_subplot(1,1,1) plt.bar(mtname, mtplay, color='cyan') plt.title('播放量和已更集数 数据分析') plt.xlabel('动漫名称') plt.ylabel('已更集数') plt.xticks(rotation=270) # *******评论数折线图 ax2 = ax1.twinx() # 组合图必须加这个 ax2.plot(mtremark, color='green') # 设置线粗细,节点样式 plt.ylabel('播放量(万)') plt.plot(1, label='播放量', linewidth=5.0 ,color='cyan') plt.plot(1, label='已更集数', linewidth=1.0,color='green') plt.legend() plt.show() #利用matplot进行绘制图形 #已更集数的柱形图 p6 = plt.figure(figsize=(12,6)) a6 = p6.add_subplot(1,1,1) plt.title('本期B站热榜动漫已更集数柱形图') plt.xlabel('动漫名称') plt.ylabel('已更集数') plt.xticks(rotation=270)#加入此行代码可以让x轴文字竖立 plt.bar(mtname,mtplay) plt.show() 原文地址:https://blog.csdn.net/m0_52940881/article/details/127046916 本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若转载,请注明出处:http://www.7code.cn/show_18349.html 如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除! 主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网显示所有内容声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。利用哔哩网页 代码007普通 打赏 收藏 海报 链接