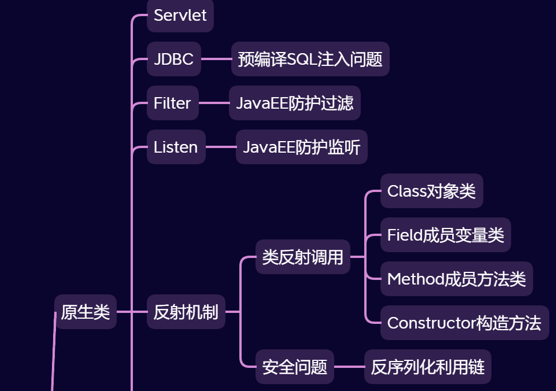
文章目录
前言
管他啥是啥,看就完了!如果觉得博主写的不错,可以点赞关注支持一下博主哦!有什么地方存在不足或者错误的,烦请各位大佬在评论区指正。万分感谢!!
本文结合了韩顺平零基础学java,黑马程序员零基础学 JavaWeb,等多个视频的相关知识内容整理而来。花费了很多很多的时间,大家有兴趣也可以结合视频一起xi
一. JDBC概述
在开发中我们使用的是 Java语言,那么势必要通过 Java语言操作数据库中的数据。这就是接下来要学习的 JDBC 技术。
1. JDBC 概念
JDBC 就是使用 Java语言操作关系型数据库的一套API。全称: Java DataBase Connectivity ,Java 数据库连接。
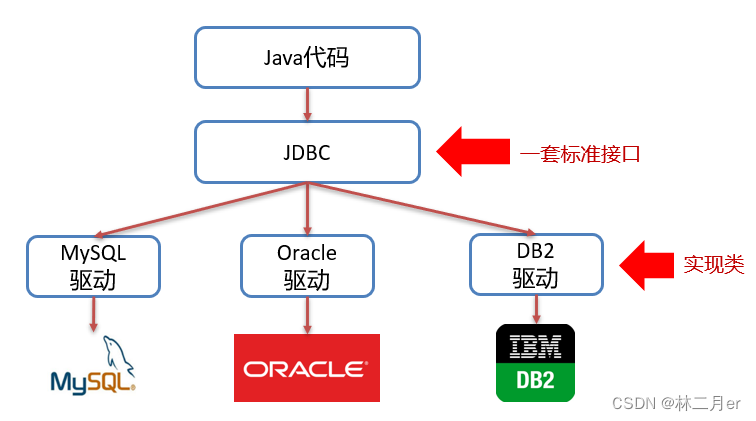
我们开发的同一套Java代码是无法操作不同的关系型数据库的,因为每一个关系型数据库的底层实现细节都不一样。如果这样,问题就很大了,在公司中可以在开发阶段使用的是MySQL数据库,而上线时公司最终选用 Oracle数据库,这就导致我们需要对代码进行大量修改,这显然并不是我们想看到的。
所以我们想要做到的就是,同一套Java代码可以操作不同的关系型数据库,而此时sun公司就制定了一套标准接口JDBC,JDBC 中定义了所有操作关系型数据库的规则。
众所周知,接口是无法直接使用的,因此就需要自定义类去实现接口,而这些自定义的实现类就由各个关系型数据库的厂商提供(我们也将这些实现类称为:驱动)。
2. JDBC 本质
JDBC 是官方(sun公司)定义的一套操作所有关系型数据库的规则,即接口。
各个数据库的厂商去实现这套接口,并给我们提供了数据库驱动(jar 包)。
于是我们便可以使用这套接口JDBC进行编程,而真正执行的代码是驱动(jar 包)中的实现类。
3. JDBC 的好处
-
以后我们编写操作数据库的代码时,只需要面向
JDBC(接口),需要操作哪个关系型数据库就导入该数据库的驱动(jar 包)即可。比如,我们想要操作 MySQL数据库,只需要在项目中导入MySQL数据库的驱动(jar 包)。如下图就是MySQL驱动包:

二. JDBC 快速入门
第二步:Java程序将要执行的SQL语句发送到 MySQL服务端。
1. 编写Java 程序步骤
第一步,创建一个 project,并导入MySQL 驱动 jar包。

Class.forName("com.mysql.cj.jdbc.Driver");
Java代码需要发送SQL语句给MySQL服务端,就需要先与服务端建立连接。
// 定义需要连接的数据库信息
String url = "jdbc:mysql://localhost:3306/hsp_db02?serverTimezone=UTC";
// 连接数据库的用户名和密码
String username = "root";
String password = "1234";
// 根据上面提供的数据库信息,获取对应数据库的一个连接对象
Connection conn = DriverManager.getConnection(url, username, password);
- (1)
jdbc:mysql:规定表示协议,通过 JDBC 的方式连接 MySQL数据库。 - (2)
localhost:表示主机,也可以是 ip地址 - (3)
3306:表示mysql 监听的端口 - (4)
hsp_db02:表示连接到 MySQL 中的的哪个数据库 - (5)
?:其后面是键值对,可以有多个键值对(用&连接),提供不同的功能。
补充:MySQL 的连接本质是 socket 连接。可以不用理会本句话。
第四步,定义SQL语句
String sql = "update …";
// 通过上面得到的数据库连接对象conn,创建一个 SQL执行对象 Statement
Statement stmt = conn.createStatement();
第六步,执行SQL语句。
// 调用Statement 对象的executeUpdate() 方法,执行SQL 语句
stmt.executeUpdate(sql);
执行SQL 语句后,会返回一个结果,我们可以获取该结果,并根据具体的业务需求对其进行各种操作。
第八步,释放数据库连接资源
// 释放数据库的Statement对象和Connection对象
stmt.close();
conn.close();
2. 在IDEA 中的操作流程
1. 创建一个新的 project

3. 对 project 进行设置,设置其 JDK版本、编译版本

4. 在project 中创建一个新模块module,并指定模块的名称及存储位置

5. 在 module 中导入MySQL 数据库的驱动(jar 包)
将MySQL 的驱动放在 module下的lib目录(随意命名,常用)下,并将该驱动添加为库文件

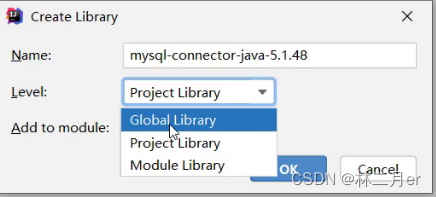

这样我们就在IDEA 开发工具中成功创建一个可以使用 JDBC 连接MySQL 数据库的项目了。
3. 正式编写 Java程序
1. 直接在程序中指定连接数据库的所有参数,代码如下:
/**
* JDBC快速入门
*/
public class JDBCDemo {
public static void main(String[] args) throws Exception {
// 1. 注册驱动
Class.forName("com.mysql.cj.jdbc.Driver");// 建议写上,不写也不会报错
// 2. 获取数据库连接
String url = "jdbc:mysql:///localhost:3306/db1";
String username = "root";
String password = "1234";
Connection conn = DriverManager.getConnection(url, username, password);
// 3. 定义sql
String sql = "update account set money = 2000 where id = 1";
// 4. 获取执行sql的对象 Statement
Statement stmt = conn.createStatement();
// 5. 执行sql,返回执行的结果,用 count变量接收
int count = stmt.executeUpdate(sql);// 方法返回表中受影响的行数
// 6. 处理结果
System.out.println(count);
// 7. 释放资源
stmt.close();
conn.close();
}
}
1.我们只需要将数据库信息另外保存在一个
properties配置文件中,然后在Java 程序代码中加载该配置文件即可连接数据库。
user=root
password=1234
url=jdbc:mysql://localhost:3306/db1?rewriteBatchedStatements=true
driver=com.mysql.cj.jdbc.Driver
- Java 程序如下:
@Test
public void JDBCDemo() throws IOException, ClassNotFoundException, SQLException {
// 1.通过Properties 对象获取配置文件的信息
Properties properties = new Properties();
properties.load(new FileInputStream("src\mysql.properties"));
// 2.获取连接数据库的相关参数信息
String user = properties.getProperty("user");
String password = properties.getProperty("password");
String driver = properties.getProperty("driver");
String url = properties.getProperty("url");
// 3.注册驱动
Class.forName(driver);// 建议写上
// 4.获取数据库连接
Connection connection = DriverManager.getConnection(url, user, password);
// 5.输出连接
System.out.println("通过配置文件方式连接" + connection);
}
三. JDBC API详解
1. DriverManager 类
DriverManager(驱动管理类)作用:
1. 注册驱动

static void registerDriver(Driver driver) // 使用DriverManager注册给定的驱动程序
Class.forName("com.mysql.cj.jdbc.Driver");

可以发现,在 Driver类中的静态代码块中已经执行 DriverManager 类中的 registerDriver() 方法进行驱动的注册了,那么我们只需要加载 Driver 类,DriverManager 类中的静态代码块就会执行。而语句Class.forName("com.mysql.cj.jdbc.Driver"); 就可以加载 Driver 类。
提示:
2. 获取数据库连接

static Connection getConnection(String url, String user, String password) // 尝试建立与给定数据库 url的连接
方法中的参数说明如下:
2. Connection 接口
Connection(数据库连接对象)接口作用:
2.1 获取执行SQL语句的对象
1. 第一种:普通执行 SQL 语句的对象 Statement
入门案例中就是通过下面方法获取的执行对象。
Statement stmt = connection.createStatement();
2. 第二种:可以预编译SQL语句并执行 SQL语句的对象 PreparedStatement,还可以防止SQL注入漏洞
通过下面方式获取的SQL语句执行对象 PreparedStatement 是我们下面会重点进行讲解的,它可以预编译SQL语句,还可以预防SQL注入漏洞。方法如下(这里先有个印象):
String sql = "...";
PreparedStatement pstmt = connecttion.prepareStatement(sql);
通过下面方式获取的 CallableStatement 执行对象是用来执行存储过程的,而存储过程在MySQL中不常用,所以这个我们将不进行讲解。
String sql = "...";
CallableStatement cstmp = connection.prepareCall(sql);
3 .ResultSet 类
3.1 概述
ResultSet(结果集对象)类作用:封装了 DQL 查询语句查询返回的结果。
我们执行了 DQL 语句后就会返回该对象,对应执行 DQL 语句的方法如下:
public ResultSet executeQuery(String sql) //执行DQL 语句,返回 ResultSet 对象
我们需要从 ResultSet 对象中获取我们想要的数据,而ResultSet 对象也给我们提供了操作查询结果数据的方法,如下:
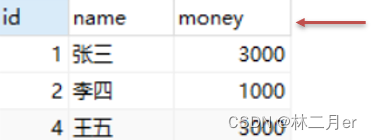
一开始光标指定于第一行前,如图所示红色箭头指向于表头行。当我们调用了 next() 方法后,光标就下移指向第一行记录,方法返回结果为 true,此时就可以通过 getInt("id") 获取当前行 id 字段的值,也可以通过 getString("id") 获取id字段的值。如果想获取下一行记录中的数据,则继续调用 next() 方法即可,以此类推。
3.2 代码实现使用ResultSet 对象
/**
* 执行 DQL语句
*/
@Test
public void testResultSet() throws Exception {
// 1. 注册驱动
Class.forName("com.mysql.cj.jdbc.Driver");
// 2. 获取连接:如果连接的是本机mysql并且端口是默认的 3306 可以简化书写
String url = "jdbc:mysql:///db1?useSSL=false";
String username = "root";
String password = "1234";
Connection conn = DriverManager.getConnection(url, username, password);
// 3. 定义sql
String sql = "select * from account";
// 4. 获取statement对象
Statement stmt = conn.createStatement();
// 5. 执行sql,获取到ResultSet 结果集对象
ResultSet rs = stmt.executeQuery(sql);
// 6. 处理结果集, 使用 while 遍历 rs中的所有记录
/* 获取字段的值有两种方式,第一种是通过传入字段的序号,如下:*/
// 6.1 光标向下移动一行,并且判断当前行是否有数据
while (rs.next()){
// 6.2 根据字段序号获取数据 getXxx()
int id = rs.getInt(1);
String name = rs.getString(2);
double money = rs.getDouble(3);
System.out.println(id);
System.out.println(name);
System.out.println(money);
System.out.println("--------------");
}
/*第二种获取字段的值的方法是通过传入字段名,如下:*/
// 6.1 光标向下移动一行,并且判断当前行是否有数据
while (rs.next()){
// 6.2 根据字段名获取数据 getXxx()
int id = rs.getInt("id");
String name = rs.getString("name");
double money = rs.getDouble("money");
System.out.println(id);
System.out.println(name);
System.out.println(money);
System.out.println("--------------");
}
// 7. 释放资源
rs.close();
stmt.close();
conn.close();
}
4. Statement 接口
4.1 概述
Statement 对象的作用就是用来执行 SQL语句。而针对不同类型的 SQL语句使用的方法也不一样。
1. 执行DDL、DML语句
int executeUpdate(String sql) // 执行给定的sql语句,这可能是 INSERT, UPDATE, 或DELETE 语句,或者不返回任何内容,如 DDL语句。
2. 执行DQL语句(查询语句)

ReseltSet execueteQuery(String sql) // 执行给定的 sql语句,该语句返回单个 ResultSet 对象。
4.2 代码实现
1. Statement 对象执行DML语句:
/**
* 执行DML语句
*/
@Test
public void testDML() throws Exception {
// 1. 注册驱动
Class.forName("com.mysql.cj.jdbc.Driver");
// 2. 获取连接:如果连接的是本机mysql并且端口是默认的 3306 可以简化书写
String url = "jdbc:mysql:///db1?useSSL=false";
String username = "root";
String password = "1234";
Connection conn = DriverManager.getConnection(url, username, password);
// 3. 定义sql
String sql = "update account set money = 3000 where id = 1";
// 4. 获取执行sql的对象 Statement
Statement stmt = conn.createStatement();
// 5. 执行sql
int count = stmt.executeUpdate(sql);// 执行完DML语句,返回受影响的行数
// 6. 处理结果
if(count > 0){
System.out.println("修改成功~");
}else{
System.out.println("修改失败~");
}
// 7. 释放资源
stmt.close();
conn.close();
}
2. Statement 对象执行DDL语句:
/**
* 执行DDL语句
*/
@Test
public void testDDL() throws Exception {
// 1. 注册驱动
Class.forName("com.mysql.cj.jdbc.Driver");
// 2. 获取连接:如果连接的是本机mysql并且端口是默认的 3306 可以简化书写
String url = "jdbc:mysql:///db1?useSSL=false";
String username = "root";
String password = "1234";
Connection conn = DriverManager.getConnection(url, username, password);
// 3. 定义sql
String sql = "drop database db2";
// 4. 获取执行sql的对象 Statement
Statement stmt = conn.createStatement();
// 5. 执行sql
int count = stmt.executeUpdate(sql);// 执行完DDL语句,可能是 0
// 6. 处理结果
System.out.println(count);
// 7. 释放资源
stmt.close();
conn.close();
}
注意:以后开发很少使用 Java代码操作DDL语句
4.3 Statement 对象应用案例
需求:查询 account账户表数据,封装为 Account对象,并且存储到ArrayList集合中

代码实现
/**
* 查询account 账户表数据,封装为Account对象,并且存储到ArrayList集合中
* 1. 定义实体类 Account。简单的定义三个字段id、name、money,此处未提供定义代码
* 2. 查询数据,封装到 Account对象中
* 3. 将Account对象存入ArrayList集合中
*/
@Test
public void testResultSet2() throws Exception {
//1. 注册驱动
Class.forName("com.mysql.cj.jdbc.Driver");
//2. 获取连接:如果连接的是本机mysql并且端口是默认的 3306 可以简化书写
String url = "jdbc:mysql:///db1?useSSL=false";
String username = "root";
String password = "1234";
Connection conn = DriverManager.getConnection(url, username, password);
//3. 定义sql
String sql = "select * from account";
//4. 获取statement对象
Statement stmt = conn.createStatement();
//5. 执行sql,返回查询结果集
ResultSet rs = stmt.executeQuery(sql);
// 创建集合
List<Account> list = new ArrayList<>();
// 6. 将结果集中的数据存入集合中
// 6.1 光标向下移动一行,并且判断当前行是否有数据
while (rs.next()){
Account account = new Account();
//6.2 获取数据 getXxx()
int id = rs.getInt("id");
String name = rs.getString("name");
double money = rs.getDouble("money");
//6.3 赋值
account.setId(id);
account.setName(name);
account.setMoney(money);
// 6.4 存入集合
list.add(account);
}
// 输出集合数据
System.out.println(list);
//7. 释放资源
rs.close();
stmt.close();
conn.close();
}
5. PreparedStatement 接口
PreparedStatement接口的作用:预编译SQL语句并执行SQL语句;预防SQL注入问题。
对上面的作用中SQL注入问题大家肯定不理解。那我们先对 SQL注入问题进行说明。
5.1 什么是SQL注入
SQL注入是指不法分子通过操作输入的内容,来修改事先定义好的SQL语句,以达到执行代码对服务器进行攻击的方法。
5.2 代码模拟SQL注入问题
SQL注入漏洞场景:假如某个网站的数据库中的用户表中存储了该网站所有用户的用户名和密码,我们在登录某个网页时必须要输入用户表中存在的用户名和密码才能成功登录。若该网站在对用户表的数据执行SQL 查询的方式和我们上面使用Statement 对象的一样,则会存在SQL注入漏洞,即非网站用户的不法分子可以通过输入某种特殊的密码成功登录该网站。
代码如下:
@Test
public void testLogin() throws Exception {
// 1. 注册驱动
Class.forName("com.mysql.cj.jdbc.Driver");
// 2. 获取连接:如果连接的是本机mysql并且端口是默认的 3306 可以简化书写
String url = "jdbc:mysql:///db1?useSSL=false";
String username = "root";
String password = "1234";
Connection conn = DriverManager.getConnection(url, username, password);
// 3.假设下面的用户名和密码是不法分子输入的,用户表中不存在该用户
String name = "sjdljfld";// 用户名随便
String pwd = "' or '1' = '1";// 密码要和此处的密码一样(逻辑类似也行)
// 定义 SQL语句,这个语句是网站去用户表中查询用户记录的语句
String sql = "select * from tb_user where username = '" + name + "' and password = '" + pwd + "'";
// 4.获取stmt对象
Statement stmt = conn.createStatement();
// 5.执行sql语句
ResultSet rs = stmt.executeQuery(sql);
// 6.判断登录是否成功,如果rs 中存在数据,即代表能在表中查询到用户记录,则可以登录成功
if(rs.next()) {
System.out.println("登录成功~");
} else {
System.out.println("登录失败~");
}
//7. 释放资源
rs.close();
stmt.close();
conn.close();
}
上面控制台输出的结果是 “登陆成功~”。明明用户表中并不存在不法分子输入的用户名和密码,为什么执行SQL 语句后返回的结果集中竟然会有数据呢?这就是上面所说的 SQL注入漏洞。
SQL注入漏洞的原理:上面代码中最终进行查询的sql 语句是将不法分子输入的用户名和密码拼接后的 sql 语句,拼接后的 sql语句如下:
select * from tb_user where username = 'sjdljfld' and password = '' or '1' = '1';
从上面语句可以看出,条件 username = 'sjdljfld' and password = '' 无论是否满足,or 后面的条件 '1' = '1' 是始终满足的,因此最终该查询条件是一定成立的,所以返回的查询结果为 true。按照逻辑,不法分子就可以正常的进行登陆了。而这就是SQL注入漏洞问题。
那么该如何解决?这里就可以将SQL语句的执行对象 Statement 换成 PreparedStatement 对象。
接下来我们来学习另一个执行SQL语句的对象 PreparedStatement ,该对象可以预防 SQL注入的问题,并且还可以预编译SQL 语句,提高性能。
5.3 PreparedStatement 概述
PreparedStatement 作用:(1)预编译 SQL语句并执行语句;(2)预防 SQL注入问题。
1. 获取 PreparedStatement 对象:
// 定义SQL语句, SQL语句中的参数值,使用占位符 ?替代
String sql = "select * from user where username = ? and password = ?";
// 通过 Connection 对象获取执行SQL语句的对象 PreparedStatement,并传入对应的SQL语句,此时会对SQL 语句进行预编译
PreparedStatement pstmt = conn.prepareStatement(sql);
2. 设置参数值
上面的 sql语句中的参数使用了?进行占位,在正式执行 sql 语句之前肯定要设置这些占位符? 的值。
3. 执行SQL语句
executeUpdate();执行DDL语句和DML语句
executeQuery();执行DQL查询语句
注意:调用这两个方法时不需要再传递SQL语句了,是因为在获取 SQL语句执行对象 PreparedStatement时已经对 SQL语句进行预编译了。
5.4 使用 PreparedStatement 改进刚才存在SQL注入漏洞的代码
1. 改进 DQL 查询语句(版本一),代码如下:
@Test
public void testPreparedStatement() throws Exception {
// 1. 注册驱动
Class.forName("com.mysql.jdbc.Driver");
// 2. 获取连接:如果连接的是本机mysql并且端口是默认的 3306 可以简化书写
String url = "jdbc:mysql:///db1?useSSL=false";
String username = "root";
String password = "1234";
Connection conn = DriverManager.getConnection(url, username, password);
// 假设下面的用户名和密码是不法分子输入的,用户表中不存在该用户
String name = "zhangsan";
String pwd = "' or '1' = '1";
// 3.定义sql语句
String sql = "select * from tb_user where username = ? and password = ?";
// 4.获取执行sql语句的 PreparedStatement 对象,注意此处要传递 sql语句
PreparedStatement pstmt = conn.prepareStatement(sql);
// 5.设置占位符 ?的值,下面的1和2 分别代表占位符的序号
pstmt.setString(1, name);// 给第一个? 赋值 name
pstmt.setString(2, pwd);// 给第二个? 赋值 pwd
// 6.执行sql语句,不需要再传入 sql语句了
// 注意:执行DQL查询语句使用 executeQuery()方法;如果执行的是 DML语句(update, insert, delete。。。),则使用的是 executeUpdate()方法。
// ResultSet resultSet = pstmt.executeQuery(sql); 该语句会报错
ResultSet rs = pstmt.executeQuery();
// 判断登录是否成功
if(rs.next()){
System.out.println("登录成功~");
}else{
System.out.println("登录失败~");
}
//7. 释放资源
rs.close();
pstmt.close();
conn.close();
}
那么PreparedStatement又是如何解决该漏洞的?原来它是将特殊字符进行了转义,转义后的SQL语句如下:
select * from tb_user where username = 'sjdljfld' and password = '' or '1' = '1';
2. 执行 DML语句,代码如下::
/**
* 演示PreparedStatement使用 dml语句
*/
@SuppressWarnings({"all"})
public class PreparedStatementDML_ {
public static void main(String[] args) throws Exception {
// 1. 注册驱动
Class.forName("com.mysql.cj.jdbc.Driver");//建议写上
// 2. 获取连接:如果连接的是本机mysql并且端口是默认的 3306 可以简化书写
String url = "jdbc:mysql:///db1?useSSL=false";
String username = "root";
String password = "1234";
Connection connection = DriverManager.getConnection(url, username, password);
// 3. 组织SqL语句
// 删除表中记录
String sql = "delete from admin where name = ?";
// 4. 获取执行sql语句的 PreparedStatement 对象,注意此处要传递 sql语句
PreparedStatement preparedStatement = connection.prepareStatement(sql);
// 5. 给占位符 ? 赋值
preparedStatement.setString(1, "zhangsan");
// 6. 执行 dml 语句使用 executeUpdate()方法
int rows = preparedStatement.executeUpdate();
System.out.println(rows > 0 ? "执行成功" : "执行失败");
// 7. 关闭连接
preparedStatement.close();
connection.close();
}
}
5.5 PreparedStatement 对象的原理
PreparedStatement对象的好处:

-
MySQL服务端会对SQL语句进行如下操作:
接下来我们通过查询日志来看一下PreparedStatement 对象预编译SQL语句的原理。
1. 开启PreparedStatement 对象的预编译功能
在代码中编写数据库的 url 时需要加上以下参数键值对来开启预编译功能。而我们之前根本就没有开启预编译功能,只是解决了SQL注入漏洞。开启预编译功能参数键值对如下:
useServerPrepStmts=true
log-output=FILE
general-log=1
general_log_file="D:mysql.log"
slow-query-log=1
slow_query_log_file="D:mysql_slow.log"
long_query_time=2
3. Java测试代码如下:
/**
* PreparedStatement 预编译SQL语句原理
*/
@Test
public void testPreparedStatement2() throws Exception {
// 1. 注册驱动
Class.forName("com.mysql.cj.jdbc.Driver");// 建议写上
//2. 获取连接:如果连接的是本机mysql并且端口是默认的 3306 可以简化书写
// 在 url 中添加 useServerPrepStmts=true 参数键值对开启预编译功能
String url = "jdbc:mysql:///db1?useSSL=false&useServerPrepStmts=true";
String username = "root";
String password = "1234";
Connection conn = DriverManager.getConnection(url, username, password);
// 3.接收用户输入的用户名和密码
String name = "zhangsan";
String pwd = "' or '1' = '1";
// 4.定义sql语句
String sql = "select * from tb_user where username = ? and password = ?";
// 获取 pstmt对象
PreparedStatement pstmt = conn.prepareStatement(sql);
// 设置占位符 ?的值
pstmt.setString(1, name);
pstmt.setString(2, pwd);
ResultSet rs = null;
// 执行sql语句
rs = pstmt.executeQuery();
// 重新设置占位符 ?的值
pstmt.setString(1, "aaa");
pstmt.setString(2, "bbb");
// 再次执行sql语句
rs = pstmt.executeQuery();
// 判断登录是否成功
if(rs.next()){
System.out.println("登录成功~");
}else{
System.out.println("登录失败~");
}
//7. 释放资源
rs.close();
pstmt.close();
conn.close();
}
4. 执行SQL语句,查看 D:mysql.log 日志如下:

上图中第三行中的 Prepare 是对SQL语句进行了预编译。第四行和第五行是执行了两次SQL语句,而第二次执行SQL语句前并没有再对SQL语句进行预编译。由此可以看出PreparedStatement对象可以提前对 SQL语句进行预编译,提高了性能。
5.6 小结
在获取PreparedStatement对象的同时,便会将 sql语句发送给 mysql服务器进行检查和编译(检查和编译这些步骤若在执行sql 语句时才进行会很耗时)。
因此在执行sql语句时就不用对其再进行检查和编译了,速度更快。
如果 sql语句的模板一样,则只需要进行一次检查和编译,而更改语句的参数多次执行查询时便不再需要进行检查和编译,这样会大大提高性能。
6. JDBC API 小结


四. 封装 JDBCUtils 工具类
1. JDBCUtils 的封装
在 JDBC 中,获取数据库的连接和释放资源的操作是经常使用到的,因此可以将连接数据库和释放资源的操作封装为一个工具类 JDBCUtils,这样会简化我们的代码。
JDBCUtils :是一个工具类,完成 mysql 的连接和关闭资源。
/**
* 这是一个工具类,完成与 mysql的连接和关闭资源
*/
public class JDBCUtils {
// 定义相关的属性(4个), 因为只需要一份,因此使用 static
private static String user; //用户名
private static String password; //密码
private static String url; //url
private static String driver; //驱动名
// 在静态代码块初始化
static {
try {
// 从配置文件导入数据库的信息
Properties properties = new Properties();
properties.load(new FileInputStream("src\mysql.properties"));
// 获取数据库相关的属性值
user = properties.getProperty("user");
password = properties.getProperty("password");
url = properties.getProperty("url");
driver = properties.getProperty("driver");
} catch (IOException e) {
// 在实际开发中,可以这样处理
// 1. 将编译异常转成 运行异常
// 2. 调用者,可以选择捕获该异常,也可以选择默认处理该异常,比较方便
throw new RuntimeException(e);
}
}
// 定义一个静态方法用于连接数据库, 返回与数据库的一个连接对象 Connection
public static Connection getConnection() {
try {
return DriverManager.getConnection(url, user, password);
} catch (SQLException e) {
//1. 将编译异常转成 运行异常
//2. 调用者,可以选择捕获该异常,也可以选择默认处理该异常,比较方便.
throw new RuntimeException(e);
}
}
// 定义一个静态方法用于关闭数据库相关资源
/*
1. ResultSet 结果集
2. Statement 或者 PreparedStatement 执行SQL语句的对象
3. Connection 数据库连接
4. 如果需要关闭资源,就传入对象,否则传入 null
*/
public static void close(ResultSet set, Statement statement, Connection connection) {
// 判断是否为 null
try {
if (set != null) {
set.close();
}
if (statement != null) {
statement.close();
}
if (connection != null) {
connection.close();
}
} catch (SQLException e) {
// 将编译异常转成运行异常抛出
throw new RuntimeException(e);
}
}
}
将获取数据库的连接和释放资源的操作成功封装为一个工具类后,在之后我们如果需要这些操作,就只需要调用该工具类中的相关方法,简化代码开发。
2. JDBCUtils 测试

测试代码如下:
/**
* 该类演示如何使用JDBCUtils工具类,完成dml 语句和 select查询语句的使用
*/
public class JDBCUtils_Use {
// 完成 DQL 查询语句
@Test
public void testSelect() {
//1. 声明JDBC 中需要用到的几个变量
Connection connection = null;
PreparedStatement preparedStatement = null;
ResultSet set = null;
//2. 组织一个sql语句
String sql = "select * from actor where id = ?";
//3. 调用JDBCUtils工具类中的方法,获取数据库的连接,并获取执行sql语句的对象 PreparedStatement
try {
connection = JDBCUtils.getConnection();
System.out.println(connection.getClass());// com.mysql.jdbc.JDBC4Connection
preparedStatement = connection.prepareStatement(sql);
preparedStatement.setInt(1, 5);// 给占位符 ? 赋值
// 执行sql, 得到结果集
set = preparedStatement.executeQuery();
// 遍历该结果集,打印输出数据
while (set.next()) {
int id = set.getInt("id");
String name = set.getString("name");
String sex = set.getString("sex");
Date borndate = set.getDate("borndate");
String phone = set.getString("phone");
System.out.println(id + "t" + name + "t" + sex + "t" + borndate + "t" + phone);
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
// 调用JDBCUtils工具类中的方法关闭相关资源
JDBCUtils.close(set, preparedStatement, connection);
}
}
// 完成 DML 语句,insert , update, delete
@Test
public void testDML() {
//1. 声明JDBC 中需要用到的几个变量
Connection connection = null;
PreparedStatement preparedStatement = null;
//2. 组织一个sql
String sql = "update actor set name = ? where id = ?";
//3. 调用JDBCUtils工具类中的方法,获取数据库的连接,并获取执行sql语句的对象 PreparedStatement
try {
connection = JDBCUtils.getConnection();
preparedStatement = connection.prepareStatement(sql);
// 给占位符 ? 赋值
preparedStatement.setString(1, "周星驰");
preparedStatement.setInt(2, 4);
// 执行sql语句
preparedStatement.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
} finally {
// 调用JDBCUtils工具类中的方法关闭相关资源
JDBCUtils.close(null, preparedStatement, connection);
}
}
}
经过测试不难看出,将获取数据库的连接和释放资源的操作成功封装为一个工具类后,大大方便了我们使用 JDBC。
五. JDBC 事务管理
数据库事务(Transaction) 是由若干个SQL语句构成的一个操作序列,有点类似于Java 线程中的synchronized同步。数据库系统保证在一个事务中的所有SQL语句要么全部执行成功,要么全部不执行,即数据库事务具有ACID特性:
数据库事务可以并发执行,而数据库系统从效率考虑,对事务定义了不同的4种隔离级别。分别对应可能出现的数据不一致的情况:
| Isolation Level | 脏读(Dirty Read) | 不可重复读(Non Repeatable Read) | 幻读(Phantom Read) |
|---|---|---|---|
| Read Uncommitted | Yes | Yes | Yes |
| Read Committed | – | Yes | Yes |
| Repeatable Read | – | – | Yes |
| Serializable | – | – | – |
对应用程序来说,数据库事务非常重要,很多运行着关键任务的应用程序,都必须依赖数据库事务,来保证程序运行的结果正确。
举个例子:假设小明准备给小红支付100元,两人在数据库中对应的用户id 分别是
123和456,那么用两条SQL语句操作如下:
UPDATE accounts SET balance = balance - 100 WHERE id = 123 AND balance >= 100;
UPDATE accounts SET balance = balance + 100 WHERE id = 456;
这两条语句必须以事务方式执行才能保证业务的正确性,因为一旦第一条SQL执行成功而第二条SQL失败的话,系统的钱就会凭空减少100。而有了事务,要么这笔转账全部成功;要么转账操作失败,双方账户的钱都不变。
先回顾一下MySQL事务管理的操作:
开启事务 : BEGIN; 或者 START TRANSACTION
提交事务 : COMMIT
回滚事务 : ROLLBACK
要在 JDBC中执行事务,本质上就是如何把多条SQL语句包裹在一个数据库事务中执行。接下来学习 JDBC 中事务管理的方法。Connection 接口中定义了3个对应事务管理的方法:
1. 开启事务
参数 autoCommit :表示是否自动提交事务,true 表示自动提交事务,false 表示手动提交事务。而开启事务需要将该参数设为为 false。
void setAutoCommit(boolean autoCommit) // 将此连接的事务自动提交模式设置为给定状态
2. 提交事务
void commit() // 使上次提交/回滚以来所做的所有更改成为永久状态,并释放此 Connection对象当前持有的所有数据库锁。
3. 回滚事务
void rollback() // 撤销当前事务中所做的所有更改,并释放此 Connection对象当前持有的所有数据库锁。
举一个案例,代码实现如下:
/**
* JDBC 事务:Connection,管理事务
*/
public class JDBCDemo3_Connection {
public static void main(String[] args) throws Exception {
//1. 注册驱动
Class.forName("com.mysql.cj.jdbc.Driver");
//2. 获取连接:如果连接的是本机mysql并且端口是默认的 3306 可以简化书写
String url = "jdbc:mysql:///db1?useSSL=false";
String username = "root";
String password = "1234";
Connection conn = DriverManager.getConnection(url, username, password);
//3. 定义sql
String sql1 = "update account set money = 3000 where id = 1";
String sql2 = "update account set money = 3000 where id = 2";
//4. 获取普通执行sql语句的对象 Statement
Statement stmt = conn.createStatement();
// 事务管理
try {
// ============开启事务==========
conn.setAutoCommit(false);
// 执行sql
int count1 = stmt.executeUpdate(sql1);//受影响的行数
// 处理结果
System.out.println(count1);
int i = 3/0;// 此处会产生异常
// 执行sql
int count2 = stmt.executeUpdate(sql2);//受影响的行数
// 处理结果
System.out.println(count2);
// ============提交事务==========
// 程序运行到此处,说明没有出现任何问题,则需求提交事务
conn.commit();
} catch (Exception e) {
// ============回滚事务==========
// 程序在执行过程中如果出现了异常,就会tiao到这个地方,此时就需要回滚事务
conn.rollback();
e.printStackTrace();
System.out.println("执行过程发生了异常,撤销执行的 sql语句。");
} finally {
conn.setAutoCommit(true);
// 关闭资源
JDBCUtils.close(null, stmt, conn);
}
}
}
-
其中,开启事务的关键代码是
conn.setAutoCommit(false),表示关闭事务的自动提交。手动提交事务的代码在执行完指定的若干条SQL语句后,调用conn.commit()方法手动提交事务。 -
要注意事务不是总能成功的,如果事务提交失败,会抛出SQL异常(也可能在执行SQL语句的时候就抛出了),此时我们必须捕获该异常并调用
conn.rollback()方法来进行回滚事务。最后,在finally中通过conn.setAutoCommit(true)方法把自动提交事务的状态恢复到初始值并关闭数据库的资源。
实际上,默认情况下,我们获取到Connection连接后,总是处于事务“自动提交”模式,也就是每执行一条SQL语句,都会作为一个事务自动提交。只要关闭了Connection的autoCommit模式,那么就可以在一个事务中执行多条SQL语句,一个事务以commit()方法手动提交结束。
如果要设定事务的隔离级别,可以使用如下代码:
// 设定事务的隔离级别为 READ COMMITTED:
conn.setTransactionIsolation(Connection.TRANSACTION_READ_COMMITTED);
六. JDBC 批处理
使用 JDBC操作数据库的时候,经常会执行一些批量操作。例如,一次性给某个会员增加若干张优惠券,我们可以执行以下SQL语句:
INSERT INTO coupons (user_id, type, expires) VALUES (123, 'DISCOUNT', '2030-12-31');
INSERT INTO coupons (user_id, type, expires) VALUES (234, 'DISCOUNT', '2030-12-31');
INSERT INTO coupons (user_id, type, expires) VALUES (345, 'DISCOUNT', '2030-12-31');
INSERT INTO coupons (user_id, type, expires) VALUES (456, 'DISCOUNT', '2030-12-31');
...
实际上在使用 JDBC 的PreparedStatement对象执行上面的SQL语句时,只有占位符?不同,SQL语句实际上是一样的:
// paramsList 集合中存储了若干个优惠券对象。
for (var params : paramsList) {
PreparedStatement ps = connection.preparedStatement("INSERT INTO coupons (user_id, type, expires) VALUES (?,?,?)");
ps.setLong(1, params.get(0));
ps.setString(2, params.get(1));
ps.setString(3, params.get(2));
int i = ps.executeUpdate();
}
通过一个循环来执行每个SQL语句虽然可行,但是性能很低。MySQL数据库对SQL语句结构相同,只有参数不同的若干条SQL语句可以作为一次batch执行,即批量执行。MySQL对于这种操作有特别优化,速度远远快于使用循环执行多条SQL语句。
在 JDBC代码中,我们可以利用MySQL数据库的这一特性,把同一个SQL语句但参数不同的若干次操作合并为一次batch 执行操作(批处理操作)。JDBC 的批处理操作中包含以下几个方法:
addBatch():添加需要批量处理的SQL语句或者参数进批处理包
@Test
public void batch() throws Exception {
Connection connection = JDBCUtils.getConnection();
String sql = "insert into admin values(null, ?, ?)";// admin表结构不重要
PreparedStatement preparedStatement = connection.prepareStatement(sql);
System.out.println("开始执行");
for (int i = 0; i < 5000; i++) {
// 设置每条sql 语句的参数
preparedStatement.setString(1, "jack" + i);
preparedStatement.setString(2, i);
// 逐条将 sql 语句加入到批处理包中,此时还没有执行sql语句
preparedStatement.addBatch();
// 当有1000条记录时,再一次批量执行sql语句
if((i + 1) % 1000 == 0) {
// 将批处理包里面的sql语句全部执行
int[] ns = preparedStatement.executeBatch();
// 执行完成后,清空批处理包中所有的sql语句
preparedStatement.clearBatch();
}
}
// 关闭连接
JDBCUtils.close(null, preparedStatement, connection);
}
执行批处理操作和执行单条SQL语句的不同点在于,执行批处理操作需要对同一个PreparedStatement对象反复设置参数并调用addBatch()方法,这样就相当于给一条SQL语句加上了多组参数,相当于变成了 “多条” SQL语句。
第二个不同点是批处理操作执行SQL语句时调用的不是executeUpdate()方法,而是executeBatch()方法,因为我们给一条SQL语句设置了多组参数,相应的,执行后的返回结果也是多个int值,因此返回类型为int[]数组。遍历int[]数组即可获取SQL语句的每组参数执行后影响的结果数量。
七. 数据库连接池
1. 数据库连接池简介
之前我们代码中使用的数据库连接都是新建一个Connection对象,而我们在使用完毕后就会将其销毁。这样重复创建销毁的过程其实是特别耗费计算机的性能以及时间的。
而使用了数据库连接池后,就能复用Connection对象,如下图:
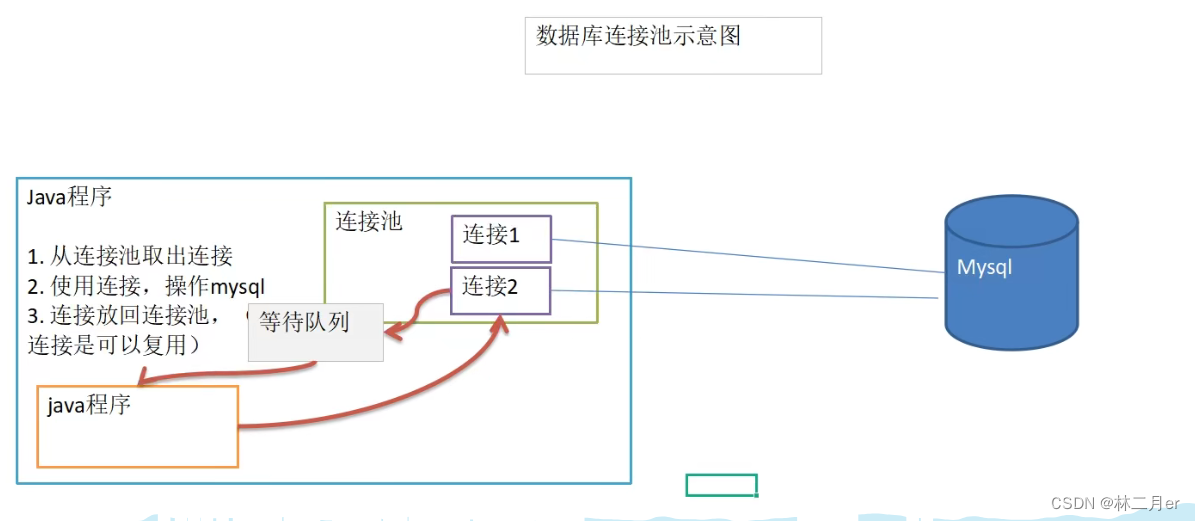
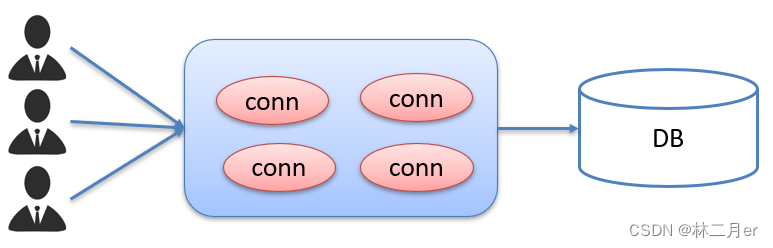
数据库连接池是在一开始就创建好了一些连接(Connection)对象存储起来。当用户需要连接数据库时,不需要再创建新的连接,只需要从连接池中获取一个空闲的连接进行使用即可。在连接使用完毕后,用户再将连接归还给连接池。
这样就可以起到资源复用的效果,也节省了频繁创建连接、销毁连接所花费的时间,从而提升了系统响应的速度。
2. 数据库连接池种类
JDBC 连接池有一个标准的接口**javax.sql.DataSource**,注意这个类位于Java标准库中,但仅仅是接口。要使用 JDBC连接池,我们必须选择一个 JDBC连接池接口的实现类。常用的 JDBC 连接池有:
- DBCP
- C3P0
- Druid
有了数据库连接池后,以后我们就不需要通过 DriverManager 对象获取 Connection 对象了,而是通过连接池(DataSource) 来获取 Connection 对象。
目前常用的连接池是:Druid 连接池,它的性能比其他两个会好一些。
Druid(德鲁伊)连接池
3. Druid 的使用
第一步,现在想要通过代码实现druid连接池获取连接,首先需要先将druid的 jar包放到项目下的 lib下并添加为库文件。 如下图:

第二步,接着就需要创建一个配置文件druid.properties,其中包含数据库的信息。项目结构如下:
编写的配置文件druid.properties如下:
driverClassName=com.mysql.cj.jdbc.Driver
url=jdbc:mysql:///db1?useSSL=false&useServerPrepStmts=true
username=root
password=1234
# 初始化连接数量
initialSize=5
# 最大连接数
maxActive=10
# 最大等待时间
maxWait=3000
通常连接池提供了大量的参数可以配置,例如,维护的最小、最大活动的连接数;指定一个连接在空闲一段时间后自动关闭等,我们需要根据应用程序的负载合理地配置这些参数。此外,大多数连接池都提供了详细的实时状态以便进行监控。
4. 代码实现连接池
1. 使用druid的代码如下(版本一):
/**
* Druid数据库连接池演示
*/
public class DruidDemo {
public static void main(String[] args) throws Exception {
// 1. 导入jar包
// 2. 定义配置文件
// 3. 加载配置文件
Properties prop = new Properties();
prop.load(new FileInputStream("jdbc-demo/src/druid.properties"));// 注意这个路径是你存放文件的路径
// 4. 创建一个指定参数的数据库连接池, 即获取Druid 连接池
DataSource dataSource = DruidDataSourceFactory.createDataSource(prop);
// 5. 获取数据库连接 Connection
Connection connection = dataSource.getConnection();
System.out.println(connection); // 获取到了连接后就可以继续做其他操作了
// 6. 释放连接
connection.close();
}
}
通过连接池获取连接时,并不需要指定 JDBC 的相关URL、用户名、密码等信息,因为这些信息已经存储在连接池内部了(也就是我们一开始定义的的配置文件druid.properties中了)。
一开始,连接池内部并没有连接,所以,第一次调用dataSource.getConnection(),会迫使连接池内部先创建一个Connection对象,再返回给客户端使用。当我们调用connection.close()方法时,不是真正 “关闭” 了Connection对象,而是将Connection对象释放回连接池中,以便下次获取Connection对象时能直接得到。
因此,连接池内部维护了若干个Connection对象,每当有程序调用了dataSource.getConnection()方法,连接池就会选择一个空闲的连接,并把它标记为 “正在使用” ,然后返回给程序。如果对程序中调用了Connection.close()方法,那么连接池就会把该连接标记为 “空闲” 状态,等待下次调用。这样一来,我们就通过连接池维护了少量Connection对象,但可以频繁地和多个程序进行连接了。
2. 使用druid的代码如下(版本二:创建一个基于druid数据库连接池的工具类)
有了数据库连接池后,我们就可以改进我们之前创建的用于简化我们开发操作的JDBCUtils工具类了。新的工具类JDBCUtilsByDruid如下:
/**
* 基于druid数据库连接池的工具类
*/
public class JDBCUtilsByDruid {
private static DataSource dataSource;
// 在静态代码块完成数据库连接池的初始化
static {
Properties properties = new Properties();
try {
properties.load(new FileInputStream("jdbc-demo/src/druid.properties"));
dataSource = DruidDataSourceFactory.createDataSource(properties);
} catch (Exception e) {
e.printStackTrace();
}
}
// 编写 getConnection 方法
public static Connection getConnection() throws SQLException {
return dataSource.getConnection();
}
// 关闭资源, 注意:在数据库连接池技术中,close()方法不是真的断掉连接,而只是将连接Connection对象归还给连接池
public static void close(ResultSet resultSet, Statement statement, Connection connection) {
try {
if (resultSet != null) {
resultSet.close();
}
if (statement != null) {
statement.close();
}
if (connection != null) {
connection.close();
}
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}
测试使用 druid 工具类获取数据库连接
/**
* 测试使用druid 工具类获取连接
*/
@SuppressWarnings({"all"})
public class JDBCUtilsByDruid_USE {
@Test
public void testSelect() {
// 1. 得到连接
Connection connection = null;
// 2. 组织一个sql
String sql = "select * from actor where id >= ?";
PreparedStatement preparedStatement = null;
ResultSet set = null;
// 3. 创建PreparedStatement 对象
try {
connection = JDBCUtilsByDruid.getConnection();
System.out.println(connection.getClass());// 看一下获取到的连接的运行类型 com.alibaba.druid.pool.DruidPooledConnection
preparedStatement = connection.prepareStatement(sql);
preparedStatement.setInt(1, 1);// 给占位符 ? 赋值
// 4. 执行sql, 得到结果集
set = preparedStatement.executeQuery();
// 5. 遍历该结果集
while (set.next()) {
int id = set.getInt("id");
String name = set.getString("name");// getName()
String sex = set.getString("sex");// getSex()
Date borndate = set.getDate("borndate");
String phone = set.getString("phone");
System.out.println(id + "t" + name + "t" + sex + "t" + borndate + "t" + phone);
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
// 6. 关闭资源,即将连接放回连接池中
JDBCUtilsByDruid.close(set, preparedStatement, connection);
}
}
}
八. Apache–dbutils 工具类开发
1. Apache–dbutils 的引入
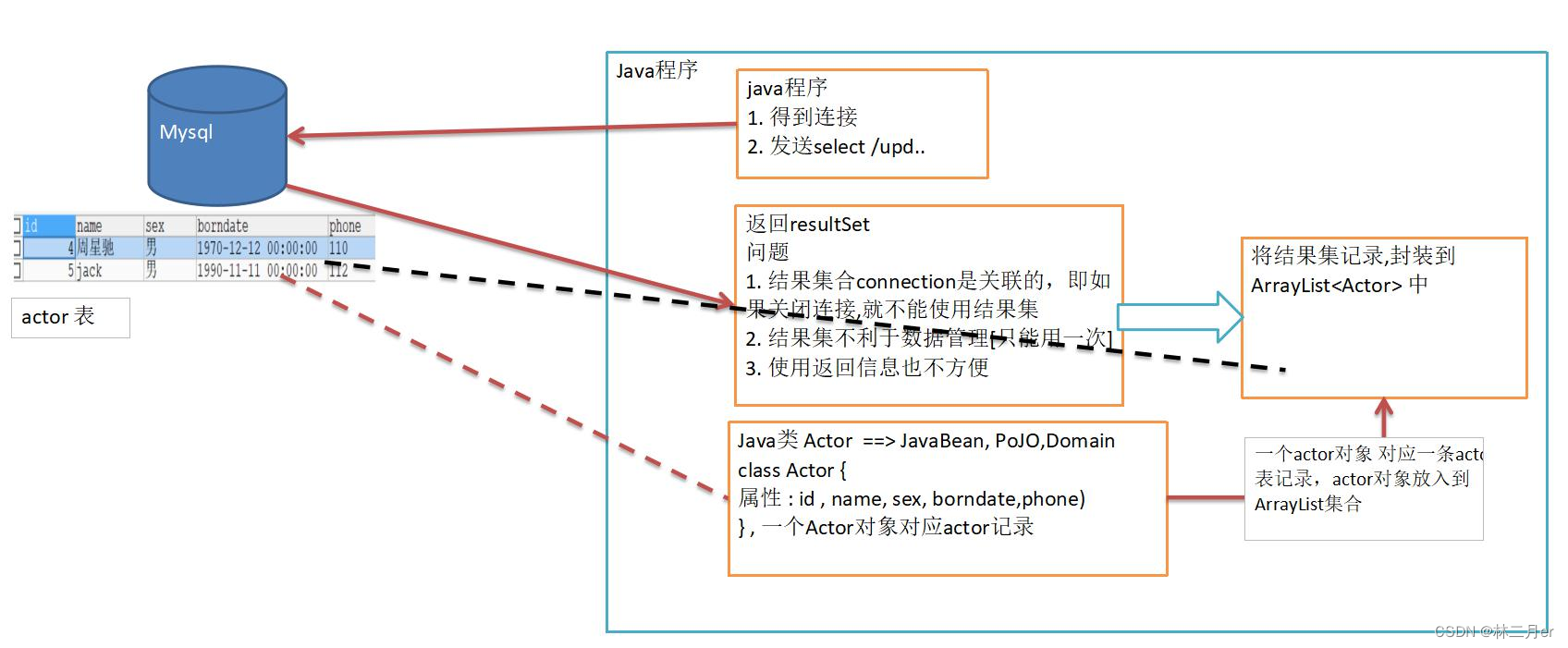
我们之前在使用PreparedStatement对象的executeQuery()方法查询数据库表中的数据时,返回的结果是ResultSet类型,可是在使用原始的ResultSet结果集时,会出现一些问题:
ResultSet结果集和Connection连接是相关联的,在关闭Connection连接后,我们得到的ResultSet结果集也不能使用了。- 使用
ResultSet结果集不利于管理获取到的数据。
这些问题的解决方法是将数据库中的一张表映射为 Java 中的一个类,这些和表相映射的Java 类我们称为JavaBean/ PoJo/ Domain类。我们再将 ResultSet 结果集中的每条记录数据封装成 JavaBean类的一个个对象,最后将这些对象存储到 ArrayList 集合中。示意图如下:
创建一个Java 类对应数据库中的一张表。代码如下:
/**
* Actor对象和 actor表的记录对应
*/
public class Actor { // Java中的 Bean, POJO, Domain 类,三种叫法
private Integer id;
private String name;
private String sex;
private Date borndate;
private String phone;
// 一定要定义一个无参构造器[反射需要]
public Actor() {
}
public Actor(Integer id, String name, String sex, Date borndate, String phone) {
this.id = id;
this.name = name;
this.sex = sex;
this.borndate = borndate;
this.phone = phone;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public Date getBorndate() {
return borndate;
}
public void setBorndate(Date borndate) {
this.borndate = borndate;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
@Override
public String toString() {
return "nActor{" +
"id=" + id +
", name='" + name + ''' +
", sex='" + sex + ''' +
", borndate=" + borndate +
", phone='" + phone + ''' +
'}';
}
}
将查询得到的ResultSet结果集数据封装成一个Arraylist 集合。代码演示:
/**
* 用土方法演示将查询得到的结果集数据封装成一个Arraylist 集合
*/
@SuppressWarnings({"all"})
public class JDBCUtilsByDruid_USE {
@Test
public ArrayList<Actor> testSelectToArrayList() {
// 1. 得到连接
Connection connection = null;
// 2. 组织一个sql
String sql = "select * from actor where id >= ?";
PreparedStatement preparedStatement = null;
ResultSet set = null;
// 创建 ArrayList对象,存放actor对象
ArrayList<Actor> list = new ArrayList<>();
// 3. 通过JDBCUtilsByDruid 获取数据库连接池中的一个连接,并获取一个 PreparedStatement 对象
try {
connection = JDBCUtilsByDruid.getConnection();
preparedStatement = connection.prepareStatement(sql);
preparedStatement.setInt(1, 1);// 给占位符 ?赋值
// 4. 执行sql, 得到结果集
set = preparedStatement.executeQuery();
// 5. 遍历该结果集,取出每条记录,封装成对应的 JavaBean类对象
while (set.next()) {
int id = set.getInt("id");
String name = set.getString("name");
String sex = set.getString("sex");
Date borndate = set.getDate("borndate");
String phone = set.getString("phone");
// 6. 把得到的resultset 的一条记录,封装成一个 Actor对象,并放入到list集合中
list.add(new Actor(id, name, sex, borndate, phone));
}
// 遍历list 集合,输出每个actor 对象
for(Actor actor : list) {
System.out.println("id=" + actor.getId() + "t" + actor.getName());
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
// 7. 关闭资源
JDBCUtilsByDruid.close(set, preparedStatement, connection);
}
// 返回该list集合。因为ArrayList 集合和 Connection连接没有任何关联,所以在释放连接后该集合可以复用
return list;
}
}
2. dbutils 的使用
dbutils:commons-dbutils 是 Apache 组织提供的一个开源 JDBC 工具类库,它是对 JDBC 的封装,使用dbutils 能极大简化 JDBC编码的工作量。常用的类和接口如下:
| 类或接口 | 功能 |
|---|---|
| QueryRunner | 该类封装了SQL的执行,是线程安全的。可以实现增、删、改、查、批处理等操作 |
| ResultSetHandler | 该接口用于处理Java.sql.ResultSet结果集,将数据按要求转换为另一种形式 |
| ArrayHandler | 把结果集中的第一行数据转成对象数组 |
| ArrayListHandler | 把结果集中的每一行数据都转成一个数组,再存放到 List中 |
| BeanHandler | 将结果集中的第一行数据封装到一个对应的 JavaBean 实例中 |
| BeanListHandler | 将结果集中的每一行数据都封装到一个对应的 JavaBean 实例中,存放到 List中 |
| ColumnListHandler | 将结果集中某一列的数据存放到 List中 |
| KeyedHandler(name) | 将结果集中的每行数据都封装到 Map 里,再把这些 Map 再存到一个Map 里,其 key为指定的 key |
| MapHandler | 将结果集中的第一行数据封装到一个Map 里 ,key 是列名,value 就是对应的值 |
| MapListHandler | 将结果集中的每一行数据都封装到一个Map 里,然后再存放到 List中 |
应用实例:使用dbutils和Druid 连接池,完成对数据库中actor表的增删改查操作。表结构如下:
2.1 使用 dbutils 执行 DQL(查询)操作
注意:需要先引入 dbutils 相关的 jar包,将其加入到 Project中。添加 JAR
包的步骤和上面我们添加的一样,此处不再介绍。
2.1.1 查询的结果是多行记录
代码如下:
/**
* 演示查询的结果是多行记录的情况
*/
@SuppressWarnings({"all"})
public class DBUtils_USE {
@Test
public void testQueryMany() throws SQLException {
// 1. 得到 连接 (druid)
Connection connection = JDBCUtilsByDruid.getConnection();
// 2. 创建 QueryRunner 对象
QueryRunner queryRunner = new QueryRunner();
// 3. 定义sql 语句
String sql = "select * from actor where id >= ?";
// 4. 执行 QueryRunner 对象中的方法进行查询,将查询到的多行记录结果集封装成 List集合
List<Actor> list =
queryRunner.query(connection, sql, new BeanListHandler<>(Actor.class), 1);
/*解读 query()方法:
(1) query() 方法就是执行sql 语句,得到 Resultset结果集 ---封装到 --> ArrayList 集合中,最后返回 ArrayList 集合。
(2) query() 方法中的参数含义:
* connection: 连接
* sql : 执行的sql语句
* new BeanListHandler<>(Actor.class): 在将 resultset -> Actor 对象 -> 封装到 ArrayList 。底层使用了反射机制 去获取Actor 类的属性,然后进行封装
* 1 :就是给 sql 语句中的占位符 ? 赋值,可以有多个值,因为是可变形参 Object... params
(3) query()方法结束后, 底层会自动销毁 PreparedStatment 和 Resultset对象
*/
System.out.println("输出集合的信息:");
for (Actor actor : list) {
System.out.print(actor);
}
// 5. 释放资源
JDBCUtilsByDruid.close(null, null, connection);
}
}
// 分析 queryRunner.query() 方法:
public <T> T query(Connection conn, String sql, ResultSetHandler<T> rsh, Object... params) throws SQLException {
PreparedStatement stmt = null;// 定义PreparedStatement
ResultSet rs = null;// 接收返回的 ResultSet
T result = null;// 返回 ArrayList
try {
stmt = this.prepareStatement(conn, sql);// 创建PreparedStatement
this.fillStatement(stmt, params);// 对 sql 进行 ? 占位符赋值
rs = this.wrap(stmt.executeQuery());// 执行sql,返回resultset
// 将返回的 resultset 转换成 arrayList[result] [使用到反射,对传入class对象处理]
result = rsh.handle(rs);
} catch (SQLException var33) {
this.rethrow(var33, sql, params);
} finally {
try {
this.close(rs);//关闭resultset
} finally {
this.close((Statement)stmt);//关闭preparedstatement对象
}
}
// 返回 List 集合
return result;
}
2.1.2 查询的结果是单行记录(即单个对象)
代码如下:
// 演示 apache-dbutils + druid 完成 查询的结果是单行记录(单个对象)
@Test
public void testQuerySingle() throws SQLException {
// 1. 得到 连接 (druid)
Connection connection = JDBCUtilsByDruid.getConnection();
// 2. 创建 QueryRunner
QueryRunner queryRunner = new QueryRunner();
// 3. 定义sql语句
String sql = "select * from actor where id = ?";
// 4. 执行相关的方法,返回单个对象。解读:因为返回的是单行记录<--->单个对象, 因此使用的参数 Hander 是 BeanHandler
Actor actor = queryRunner.query(connection, sql, new BeanHandler<>(Actor.class), 10);
// 输出对象信息
System.out.println(actor);
// 5. 释放资源
JDBCUtilsByDruid.close(null, null, connection);
}
2.1.3 查询的结果是单行单列(返回的就是 object对象)
代码如下:
// 演示apache-dbutils + druid 完成查询结果是单行单列-返回的就是object
@Test
public void testScalar() throws SQLException {
// 1. 得到 连接 (druid)
Connection connection = JDBCUtilsByDruid.getConnection();
// 2. 创建 QueryRunner
QueryRunner queryRunner = new QueryRunner();
// 3. 定义sql语句
String sql = "select name from actor where id = ?";
// 4. 执行相关的方法,返回单行单列 , 返回的就是Object。解读: 因为返回的是一个对象, 使用的参数 Handler 就是 ScalarHandler
Object obj = queryRunner.query(connection, sql, new ScalarHandler(), 4);
// 输出对象信息
System.out.println(obj);
// 5. 释放资源
JDBCUtilsByDruid.close(null, null, connection);
}
2.2 使用 dbutils 执行 DML 操作(update, insert, delete 增删改)
表和 JavaBean 类的类型映射关系如下:

代码如下:
// 演示 apache-dbutils + druid 完成 dml 操作(update, insert ,delete)
@Test
public void testDML() throws SQLException {
// 1. 得到 连接 (druid)
Connection connection = JDBCUtilsByDruid.getConnection();
// 2. 创建 QueryRunner
QueryRunner queryRunner = new QueryRunner();
// 3. 这里组织sql 完成 update, insert, delete
// String sql = "update actor set name = ? where id = ?";
// String sql = "insert into actor values(null, ?, ?, ?, ?)";
String sql = "delete from actor where id = ?";
/* 4.
解读:
(1) 执行dml 操作所使用的方法是 queryRunner.update()
(2) 返回的值是受影响的行数 (affected: 受影响)
*/
int affectedRow = queryRunner.update(connection, sql, 1000);
System.out.println(affectedRow > 0 ? "执行成功" : "执行没有影响到表");
// 5. 释放资源
JDBCUtilsByDruid.close(null, null, connection);
}
3. dbutils 小结
为了方便管理我们执行sql 语句后获取到的结果数据,我们使用一个JavaBean 类来映射数据库中的一张表。我们再将 ResultSet 结果集中的每条记录数据封装成 JavaBean类的一个个对象,最后将这些对象存储到 ArrayList 集合中。
而这些查询、封装和存储的操作,dbutils 已经帮我们封装好了,我们只需要使用 dbutils 中的API,便可以快捷完成开发。
使用 dbutils 执行 DQL(查询)操作,需要创建一个QueryRunner 对象,所使用的方法是:query(Connection conn, String sql, ResultSetHandler<T> rsh, Object... params)方法。
使用 dbutils 执行 DML(增、删、改)操作,需要创建一个QueryRunner 对象,所使用的方法是:update(Connection conn, String sql, Object... params)方法。
九. DAO类和 BasicDao类
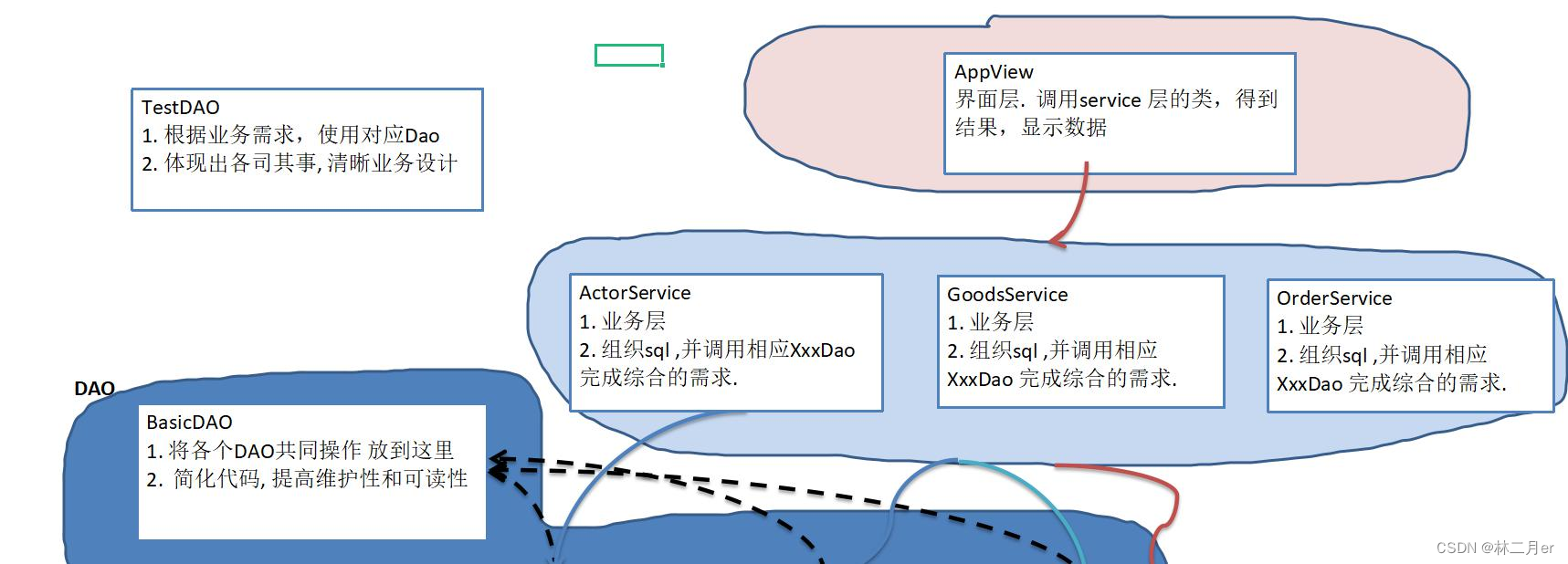
1. DAO 类的引入
apache-dbutils工具类库和Druid连接池简化了 JDBC 开发,但还有不足:
由此引出DAO类 和BasicDAO类,看看在实际开发中,应该如何处理,示意图如下:

1. DAO: data access object 数据访问对象
2.BasicDAO:通用DAO类,是专门和数据库交互的,即完成对数据库(表)的 crud 操作。
3. 在BaiscDao的基础上,实现一张表对应一个JavaBean实体类并对应一个专门操作该表的Dao类,更好的完成功能。比如:Customer表 <==> Customer.Java类(JavaBean)<==> CustomerDao.Java。
2. BasicDAO 应用实例

完成一个简单设计,使用apache-dbutils工具类库和Druid连接池,对数据库中的actor表进行增删改查操作。actor表映射Actor实体类,要求使用ActorDAO类和BasicDAO类对表进行增删改查操作。
actor表结构如下:

2.1 utils 包(存放工具类)
/**
* 基于druid数据库连接池的工具类
*/
public class JDBCUtilsByDruid {
private static DataSource ds;
// 在静态代码块完成 ds初始化
static {
Properties properties = new Properties();
try {
properties.load(new FileInputStream("src\druid.properties"));
ds = DruidDataSourceFactory.createDataSource(properties);
} catch (Exception e) {
e.printStackTrace();
}
}
// 编写getConnection方法
public static Connection getConnection() throws SQLException {
return ds.getConnection();
}
// 关闭连接, 老师再次强调: 在数据库连接池技术中,close 不是真的断掉连接
// 而是把使用的Connection对象放回连接池
public static void close(ResultSet resultSet, Statement statement, Connection connection) {
try {
if (resultSet != null) {
resultSet.close();
}
if (statement != null) {
statement.close();
}
if (connection != null) {
connection.close();
}
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}
2.2 javabean/ pojo/ domain 包(存放与表映射的 JavaBean实体类)
/**
* Actor类的对象和 actor表的记录对应
*/
public class Actor { // JavaBean, POJO, Domain 对象
private Integer id;
private String name;
private String sex;
private Date borndate;
private String phone;
public Actor() { //一定要定义一个无参构造器[反射需要]
}
public Actor(Integer id, String name, String sex, Date borndate, String phone) {
this.id = id;
this.name = name;
this.sex = sex;
this.borndate = borndate;
this.phone = phone;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public Date getBorndate() {
return borndate;
}
public void setBorndate(Date borndate) {
this.borndate = borndate;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
@Override
public String toString() {
return "nActor{" +
"id=" + id +
", name='" + name + ''' +
", sex='" + sex + ''' +
", borndate=" + borndate +
", phone='" + phone + ''' +
'}';
}
}
2.3 dao 包(存放操作表的 DAO 类和通用的 BasicDAO 类)
BasicDAO 类如下:
/**
* 开发BasicDAO 类, 是其他所有 DAO类 的父类
*/
public class BasicDAO<T> { // 泛型指定具体类型
private QueryRunner qr = new QueryRunner();
// 开发通用的 dml 方法, 针对任意表(增删改操作)
public int update(String sql, Object... parameters) {
Connection connection = null;
try {
connection = JDBCUtilsByDruid.getConnection();
int update = qr.update(connection, sql, parameters);
return update;
} catch (SQLException e) {
throw new RuntimeException(e);// 将编译异常->运行异常 ,抛出
} finally {
JDBCUtilsByDruid.close(null, null, connection);
}
}
// 查询操作:返回结果为多个对象(即查询的结果是多行记录)的通用方法, 针对任意表
/**
*
* @param sql sql 语句,可以有 ?
* @param clazz 传入一个类的Class对象 比如 Actor.class
* @param parameters 传入 ? 的具体的值,可以是多个
* @return 根据 Actor.class 返回对应的 ArrayList 集合
*/
public List<T> queryMulti(String sql, Class<T> clazz, Object... parameters) {
Connection connection = null;
try {
connection = JDBCUtilsByDruid.getConnection();
return qr.query(connection, sql, new BeanListHandler<T>(clazz), parameters);
} catch (SQLException e) {
throw new RuntimeException(e);// 将编译异常->运行异常 ,抛出
} finally {
JDBCUtilsByDruid.close(null, null, connection);
}
}
// 查询操作:返回结果为单行记录 的通用方法,针对任意表
public T querySingle(String sql, Class<T> clazz, Object... parameters) {
Connection connection = null;
try {
connection = JDBCUtilsByDruid.getConnection();
return qr.query(connection, sql, new BeanHandler<T>(clazz), parameters);
} catch (SQLException e) {
throw new RuntimeException(e);// 将编译异常->运行异常 ,抛出
} finally {
JDBCUtilsByDruid.close(null, null, connection);
}
}
// 查询操作:返回结果为单行单列,即返回单值(Object 对象)的通用方法,针对任意表
public Object queryScalar(String sql, Object... parameters) {
Connection connection = null;
try {
connection = JDBCUtilsByDruid.getConnection();
return qr.query(connection, sql, new ScalarHandler(), parameters);
} catch (SQLException e) {
throw new RuntimeException(e);// 将编译异常->运行异常 ,抛出
} finally {
JDBCUtilsByDruid.close(null, null, connection);
}
}
}
ActorDAO 类如下:
/**
* 专门操作 actor表的 DAO 类,继承了 BasicDAO 类
*/
public class ActorDAO extends BasicDAO<Actor> {
// 1. 继承了 BasicDAO 类中所有的方法
// 2. 根据业务需求,可以编写特有的方法
...
}
2.4 test 包(存放测试类)
/**
* 测试类
*/
public class TestDAO {
// 测试ActorDAO 对 actor表 crud操作
@Test
public void testActorDAO() {
ActorDAO actorDAO = new ActorDAO();
// 1. 查询多行记录
List<Actor> actors = actorDAO.queryMulti("select * from actor where id >= ?", Actor.class, 1);
System.out.println("===查询结果===");
for (Actor actor : actors) {
System.out.println(actor);
}
// 2. 查询单行记录
Actor actor = actorDAO.querySingle("select * from actor where id = ?", Actor.class, 6);
System.out.println("====查询单行结果====");
System.out.println(actor);
// 3. 查询单行单列
Object o = actorDAO.queryScalar("select name from actor where id = ?", 6);
System.out.println("====查询单行单列值===");
System.out.println(o);
// 4. dml 操作:insert ,update, delete
int update = actorDAO.update("insert into actor values(null, ?, ?, ?, ?)", "张无忌", "男", "2000-11-11", "999");
System.out.println(update > 0 ? "执行成功" : "执行没有影响表");
}
}
十. JDBC 案例练习
最后让我们来通过一个案例来练习一下我们的 JDBC 吧。
1. 需求
2. 案例实现
2.1 环境准备
1. 创建案例所需的数据库,数据库表 tb_brand如下:
-- 删除tb_brand表
drop table if exists tb_brand;
-- 创建tb_brand表
create table tb_brand (
-- id 主键
id int primary key auto_increment,
-- 品牌名称
brand_name varchar(20),
-- 企业名称
company_name varchar(20),
-- 排序字段
ordered int,
-- 描述信息
description varchar(100),
-- 状态:0:禁用 1:启用
status int
);
-- 添加数据
insert into tb_brand (brand_name, company_name, ordered, description, status)
values ('三只松鼠', '三只松鼠股份有限公司', 5, '好吃不上火', 0),
('华为', '华为技术有限公司', 100, '华为致力于把数字世界带入每个人、每个家庭、每个组织,构建万物互联的智能世界', 1),
('小米', '小米科技有限公司', 50, 'are you ok', 1);
2. 在pojo包下创建与tb_brand表映射的实体类 Brand
/**
* 品牌
* alt + 鼠标左键:整列编辑
* 在实体类中,基本数据类型建议使用其对应的包装类型
*/
public class Brand {
// id 主键
private Integer id;
// 品牌名称
private String brandName;
// 企业名称
private String companyName;
// 排序字段
private Integer ordered;
// 描述信息
private String description;
// 状态:0:禁用 1:启用
private Integer status;
public Brand() {
}
public Brand(int id, String brandName, String companyName, int ordered, String description, int status) {
this.id = id;
this.brandName = brandName;
this.companyName = companyName;
this.ordered = ordered;
this.description = description;
this.status = status;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getBrandName() {
return brandName;
}
public void setBrandName(String brandName) {
this.brandName = brandName;
}
public String getCompanyName() {
return companyName;
}
public void setCompanyName(String companyName) {
this.companyName = companyName;
}
public int getOrdered() {
return ordered;
}
public void setOrder(int ordered) {
this.ordered = ordered;
}
public String getDescription() {
return description;
}
public void setDescription(String description) {
this.description = description;
}
public int getStatus() {
return status;
}
public void setStatus(int status) {
this.status = status;
}
@Override
public String toString() {
return "nBrand{" +
"id=" + id +
", brandName='" + brandName + ''' +
", companyName='" + companyName + ''' +
", order=" + ordered +
", description='" + description + ''' +
", status=" + status +
'}';
}
}
在dao包下创建BasicDAO和BrandDAO类。如下:
public class BasicDAO<T> {
private final QueryRunner queryRunner = new QueryRunner();
/**
* 开发通用的 dml 方法, 针对任意表(增删改操作)
* @param sql
* @param parameters
* @return
*/
public int update(String sql, Object... parameters) {
Connection connection = null;
try {
connection = JDBCUtilByDruid.getConnection();
return queryRunner.update(connection, sql, parameters);
} catch (SQLException e) {
throw new RuntimeException(e);
} finally {
JDBCUtilByDruid.close(null, null, connection);
}
}
/**
* 查询操作:返回结果为多个对象(即查询的结果是多行记录)的通用方法, 针对任意表
* @param sql
* @param clazz
* @param parameters
* @return
*/
public List<T> queryMulti(String sql, Class<T> clazz, Object... parameters) {
Connection connection = null;
try {
connection = JDBCUtilByDruid.getConnection();
return queryRunner.query(connection, sql, new BeanListHandler<>(clazz), parameters);
} catch (SQLException e) {
throw new RuntimeException(e);
} finally {
JDBCUtilByDruid.close(null, null, connection);
}
}
/**
* 查询操作:返回结果为单行记录 的通用方法,针对任意表
* @param sql
* @param clazz
* @param parameters
* @return
*/
public T querySingle(String sql, Class<T> clazz, Object... parameters) {
Connection connection = null;
try {
connection = JDBCUtilByDruid.getConnection();
return queryRunner.query(connection, sql, new BeanHandler<>(clazz), parameters);
} catch (SQLException e) {
throw new RuntimeException(e);// 将编译异常->运行异常 ,抛出
} finally {
JDBCUtilByDruid.close(null, null, connection);
}
}
/**
* 查询操作:返回结果为单行单列,即返回单值(Object 对象)的通用方法,针对任意表
* @param sql
* @param parameters
* @return
*/
public Object queryScalar(String sql, Object... parameters) {
Connection connection = null;
try {
connection = JDBCUtilByDruid.getConnection();
return queryRunner.query(connection, sql, new ScalarHandler(), parameters);
} catch (SQLException e) {
throw new RuntimeException(e);// 将编译异常->运行异常 ,抛出
} finally {
JDBCUtilByDruid.close(null, null, connection);
}
}
}
BrandDAO类继承自BasicDAO类,此处无需额外再定义方法。
public class BrandDAO extends BasicDAO<Brand>{
}
注意:还需要创建utils包,存放JDBCUtilsByDruid工具类,该工具类的代码上面已经给出,此处不提供了。
2.2 查询表中所有记录
在test包下创建测试类testBrand:
public class testBrand {
private BrandDAO brandDAO = new BrandDAO();
@Test
public void testSelectMulti() {
String sql = "select * from tb_brand;";
List<Brand> brands = brandDAO.queryMulti(sql, Brand.class);
System.out.println(brands);
}
}
2.3 添加数据
public class testBrand {
private BrandDAO brandDAO = new BrandDAO();
@Test
public void testInsert() {
String sql = "insert into tb_brand(brand_name, company_name, ordered, description, status) values(?,?,?,?,?);";
int insert = brandDAO.update(sql, "腾讯", "腾讯公司", 50, "我们是鹅厂", 1);
System.out.println(insert);
}
}
2.4 修改数据
public class testBrand {
private BrandDAO brandDAO = new BrandDAO();
@Test
public void testUpdate() {
String sql = "update tb_brandn" +
"set brand_name = ?,n" +
"company_name= ?,n" +
"ordered = ?,n" +
"description = ?,n" +
"status = ?n" +
"where id = ?";
int update = brandDAO.update(sql, "腾讯", "腾讯公司", 50, "我们是鹅厂,我们的工资很高", 1, 8);
System.out.println(update);
}
}
2.5 删除数据
public class testBrand {
private BrandDAO brandDAO = new BrandDAO();
@Test
public void testDelete() {
String sql = " delete from tb_brand where id = ?";
int delete = brandDAO.update(sql, 7);
System.out.println(delete);
}
}
原文地址:https://blog.csdn.net/weixin_45395059/article/details/129704333
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_18537.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!


![[设计模式Java实现附plantuml源码~行为型]请求的链式处理——职责链模式](https://img-blog.csdnimg.cn/direct/699aac3ed0c446d088772a0ed4c444ed.png)
![[设计模式Java实现附plantuml源码~结构型]处理多维度变化——桥接模式](https://img-blog.csdnimg.cn/direct/8e811a73550d49e6a55c49a070a733e8.png)