本文介绍: MQ(MessageQueue),中文是消息队列,字面来看就是存放消息的队列。也就是事件驱动架构中的Broker。简单来讲,Kafka对并发场景性能更高,但是没有RabbitMQ安全,所以一般情况下就用RabbitMQ就可,中规中矩。流程如下:1.在父工程中引入spring–amqp的依赖2.在publisher服务中利用RabbitTemplate发送消息到simple.queue这个队列3.在consumer服务中编写消费逻辑,绑定simple.queue这个队列。
初识MQ
同步通讯和异步通讯
同步通讯是实时性质的,就好像你用手机与朋友打视频电话,但是,别人再想与你视频就不行了,异步通讯不要求实时性,就好像你用手机发短信,好多人都能同时给你发短信,你都可以收到,而且不用及时回复。

同步调用的问题
比如用户调用支付服务时,它需要先后调用订单服务、仓储服务、短信服务等,都调用结束后,支付服务再返回用户相关信息,故这个过程的响应时间实际上就是所有这些相关服务执行之后所用时间之和,这样是非常影响效率的。但是也有优点,时效性较强,可以立即得到结果

同步调用存在的问题
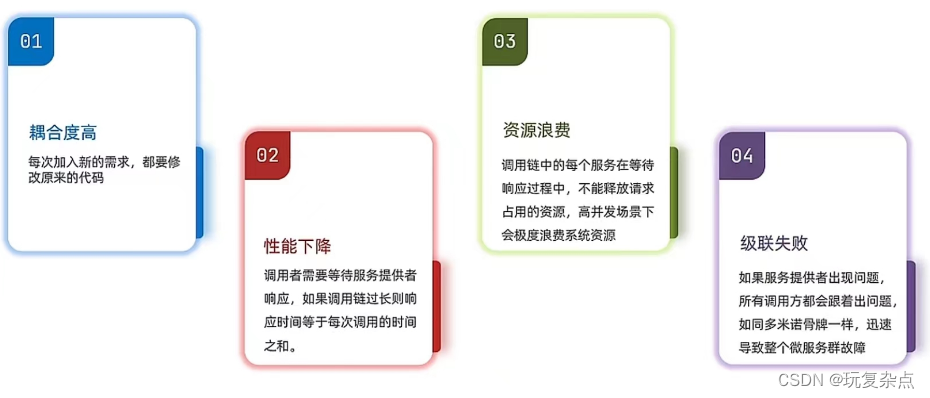
1.如果我们想对支付服务增加一些功能,增加一些别的服务,为了让支付功能调用这个新服务,我们需要改动相关的代码
异步调用方案
异步调用常见实现就是事件驱动模式

优势一:服务解耦
优势二:性能提升,吞吐量提高
优势三:服务没有强依赖,不担心级联失败问题
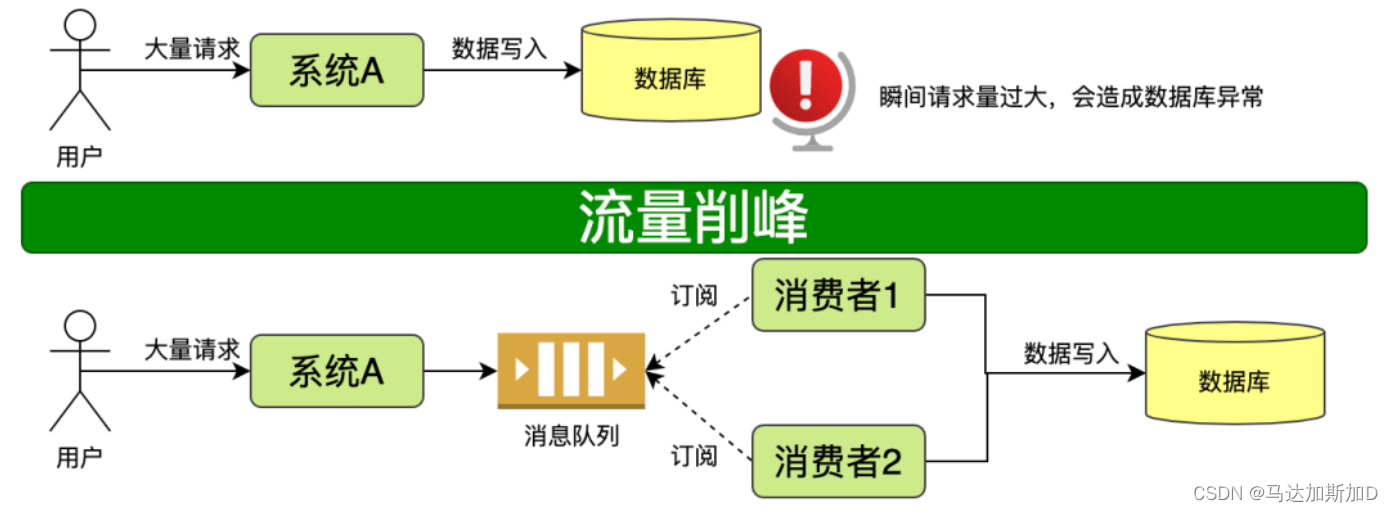
优势四:流量削峰

异步通信的缺点
什么是MQ?

RabbitMQ快速入门
单机部署
方式一:在线拉取

方式二:从本地加载


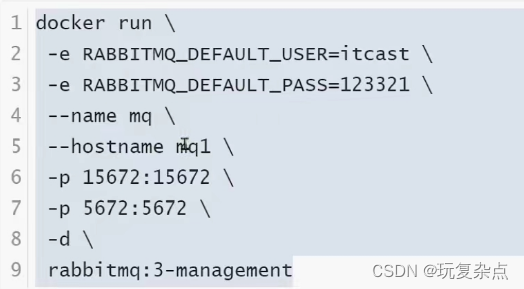
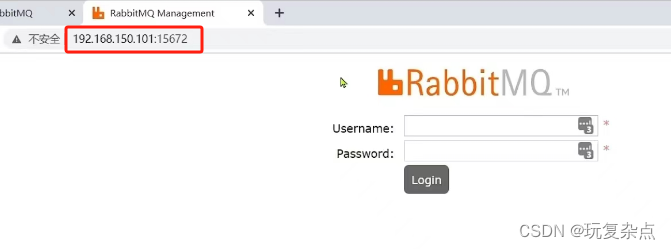
安装MQ
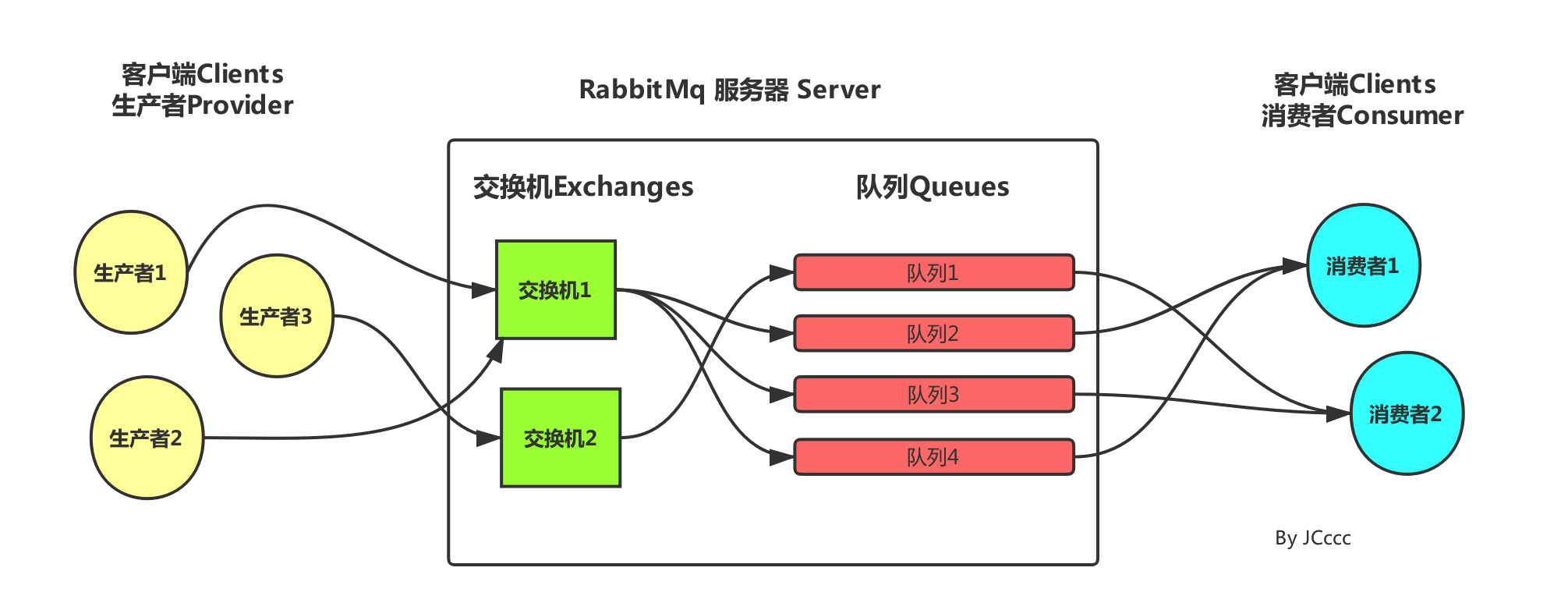
RabbitMQ的结构和概念

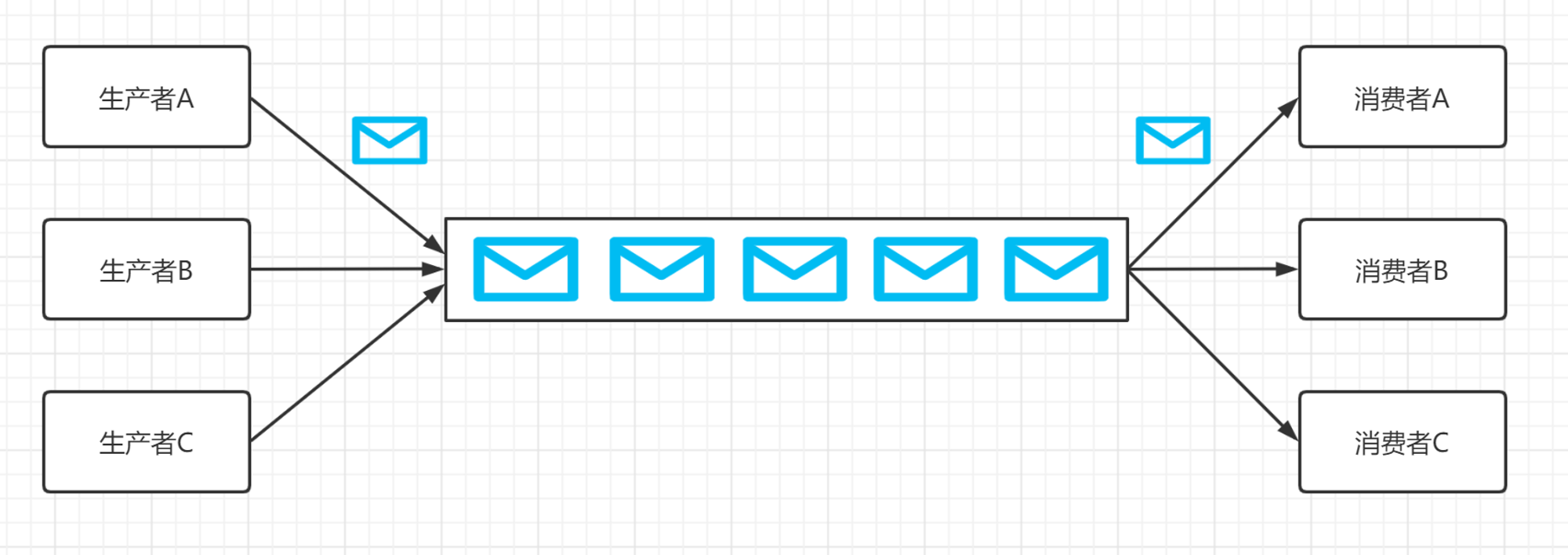
常见消息模型

HelloWorld案例








SpringAMQP
什么是SpringAMQP

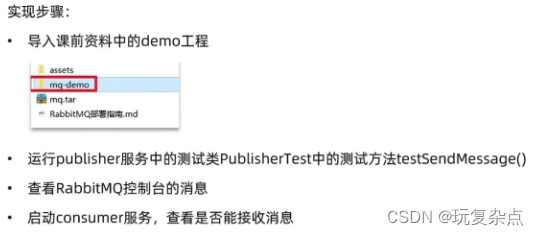
案例:利用SpringAMQP实现HelloWorld中的基础消息队列功能
步骤1: 引入AMQP依赖

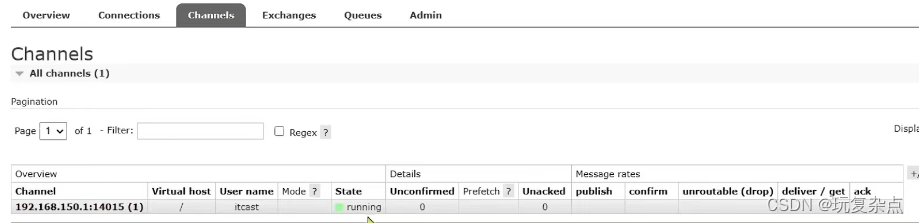
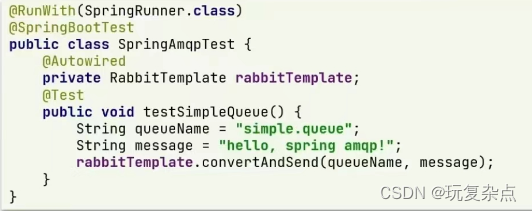
步骤2: 在publisher中编写测试方法,向simple.queue发送消息
1.在publisher服务中编写application.yml,添加mq连接信息

2.在publisher服务中新建一个测试类,编写测试方法

步骤3: 在consumer中编写消费逻辑,监听simple.queue
1.在consumer服务中编写application.yml,添加mq连接信息

2.在consumer服务中新建一个类,编写消费逻辑

Work Queue 工作队列

案例:模拟WorkQueue,实现一个队列绑定多个消费者




消费预取限制


Work模型的使用
发布 ( Publish )、订阅 ( Subscribe )

发布订阅-Fanout Exchange

案例:利用SpringAMQP演示FanoutExchange的使用

步骤1: 在consumer服务声明Exchange、Queue、 Binding

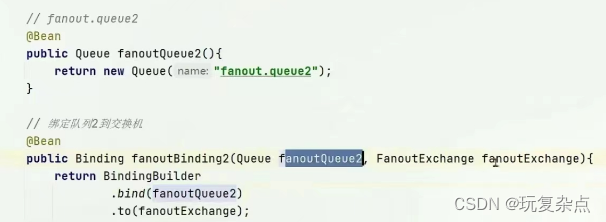

步骤2: 在consumer服务声明两个消费者

步骤3: 在publisher服务发送消息到FanoutExchange


发布订阅-DirectExchange

案例:利用SpringAMQP演示DirectExchange的使用

步骤1: 在consumer服务声明Exchange、Queue

步骤2: 在publisher服务发送消息到DirectExchange

发布订阅-TopicExchange

案例:利用SpringAMQP演示TopicExchange的使用

步骤1: 在consumer服务声明Exchange、Queue

步骤2: 在publisher服务发送消息到TopicExchange

消息转换器
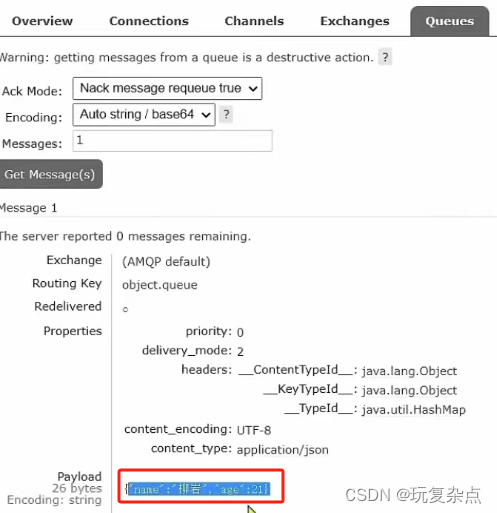
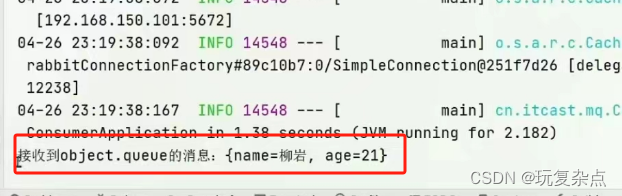
案例:测试发送Object类型消息








声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。