本文介绍: listpack(紧凑列表)时Redis5版本出现的,作用是为了代替ziplist。Redis7.0版本之后,listpack就完全替代了ziplist。ziplist的缺点是,在极端的情况下,可能会出现连锁更新的情况,时间复杂度是O(N^2),会带来不小的性能消耗。Redis压缩列表-CSDN博客虽然Redis在3.0版本后使用quicklist,通过quicklistNode来控制ziplist的大小和元素的个数,减少连锁更新带来的性能问题,但是它并没有避免连锁更新,使用的还是ziplist。
哈希对象的编码可以是ziplist或者hashtable。再redis5.0版本之后出现listpack,为了是代替ziplist。
一. 使用ziplist编码
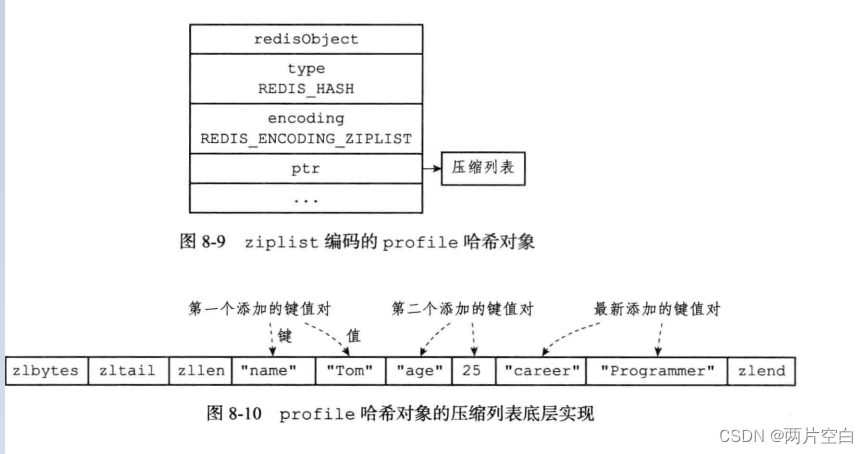
ziplist编码的哈希对象使用压缩列表作为底层实现,每当有新的键值对要加入到哈希对象时,程序都会先将保存了键值对的键的压缩列表节点推入到压缩列表表尾,再将保存了值的压缩列表节点推入到压缩列表表尾。
如果Redis使用ziplist作为哈希对象的的编码,那么对象和对象使用的压缩列表会如下图:
二.使用hashtable编码
当使用hashtable编码的作为哈希对象的编码,是使用字典作为底层实现,哈希对象的每一个键值对都使用一个字典键值对来保存。
举个例子,如果前面的profile键创建的不是ziplist编码的哈希对象,而是hashtable编码的哈希对象,那么这个哈希对象结构如下图:

三. 编码转换
四.哈希命令的实现

五. listpack编码
5.1 介绍
5.2 结构
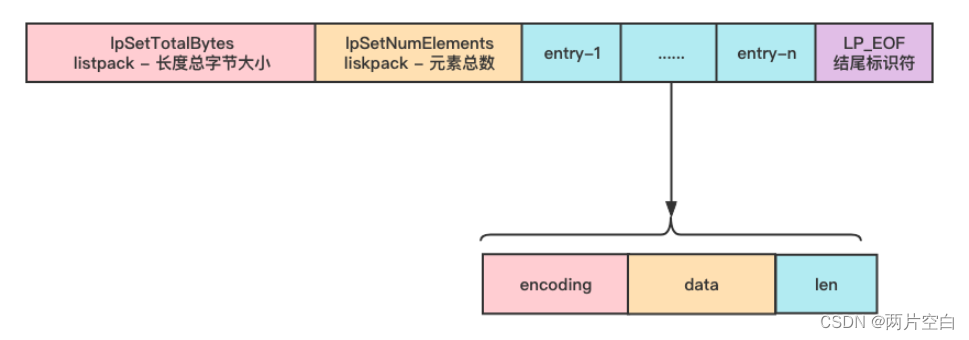
5.3 与ziplist的区别
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






