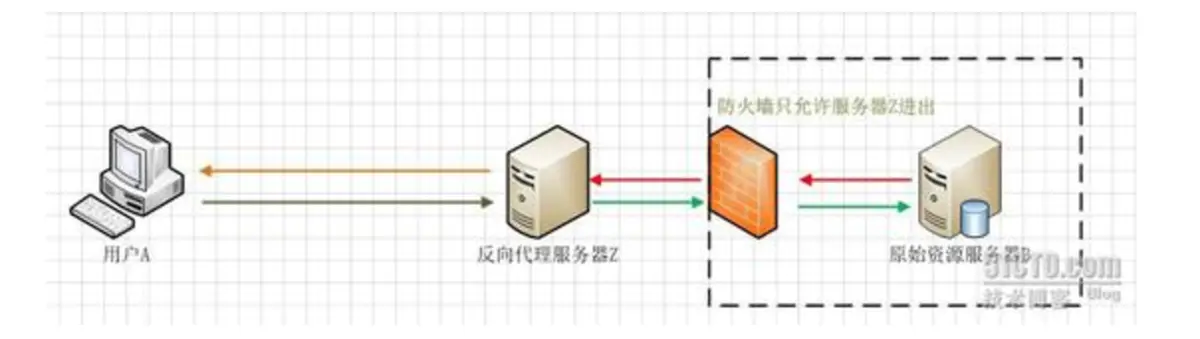
GPT原理:文字接龙,输入一个字,后面会接最有可能出现的文字。
Lee老师幽默的开场:
GPT:chat Generative Pre–trained Transformer
GPTS:专属的客制化的老师。
GPT原理:文字接龙,输入一个字,后面会接最有可能出现的文字。
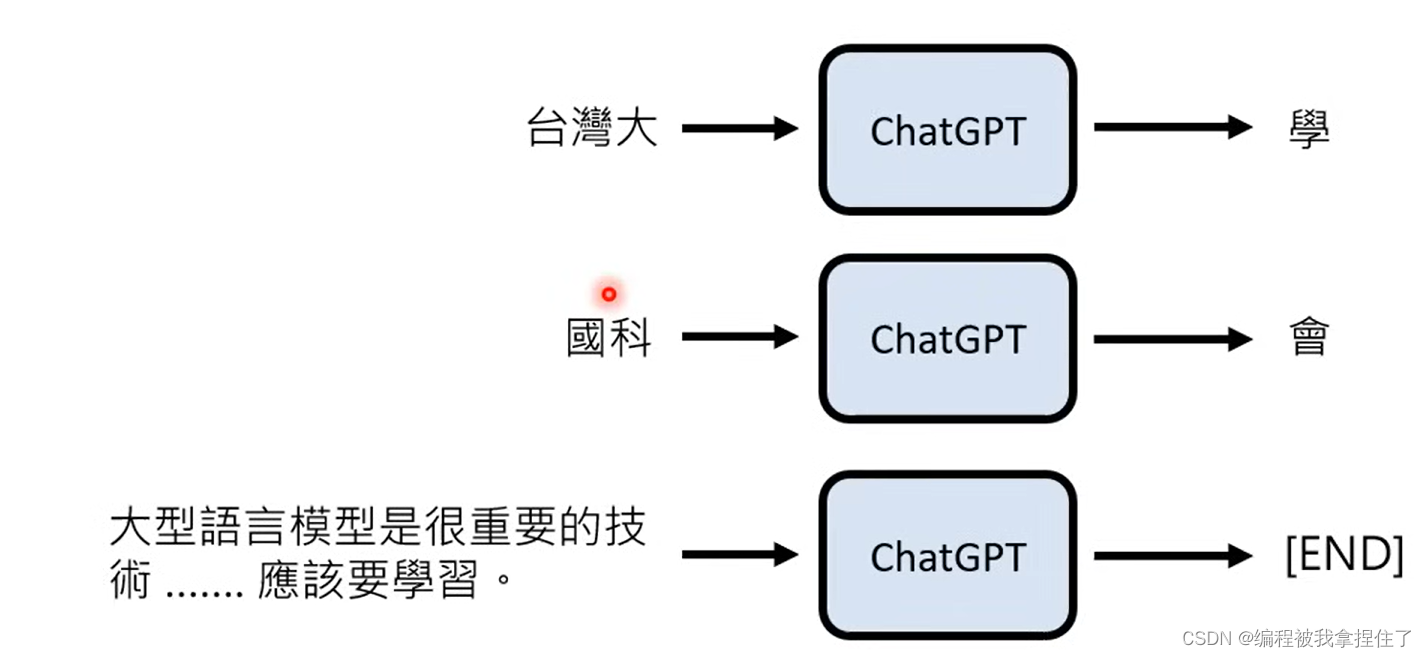
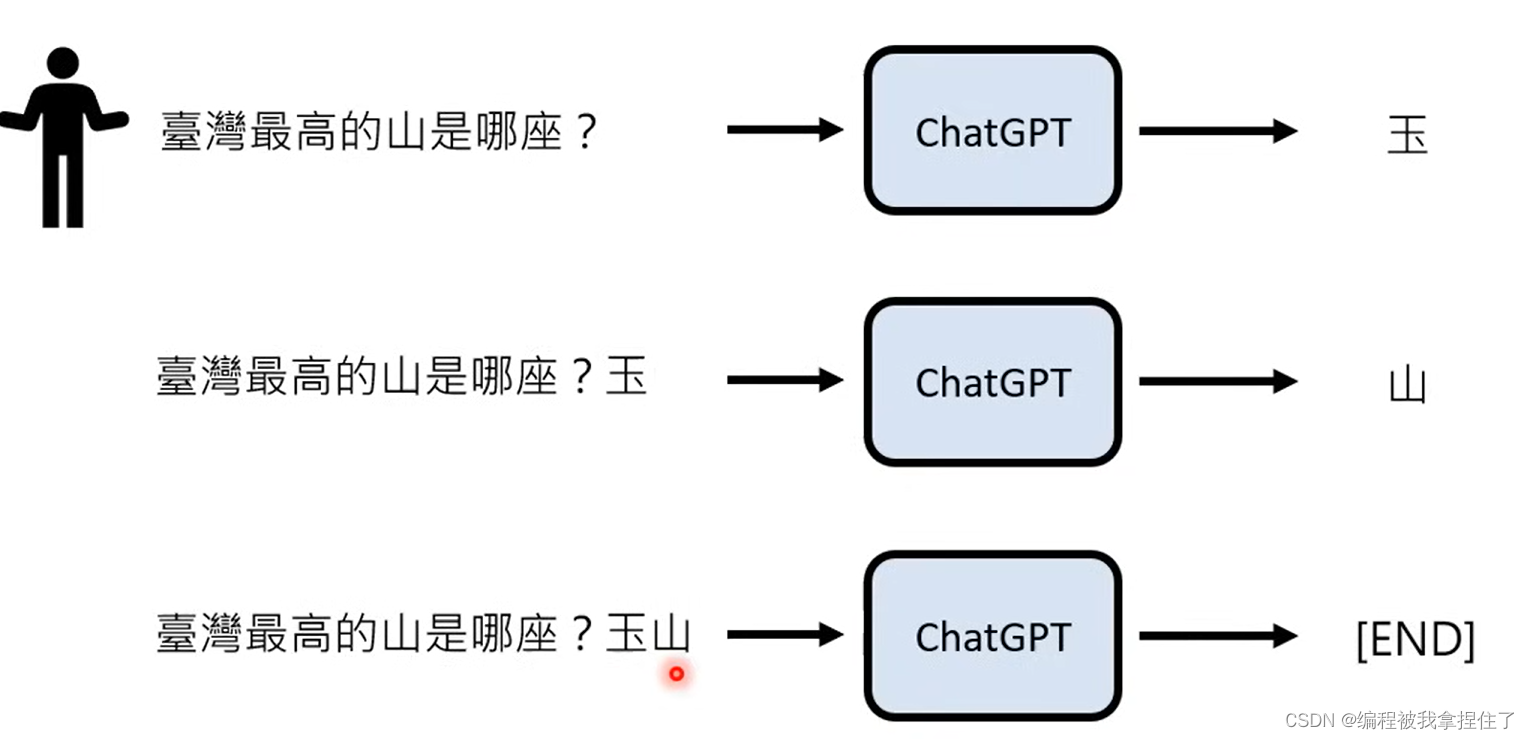

给每一个后面可能输出的符号一个概率值,输出概率最大的字符(token)。拆成token的方式也是比较有意思,会根据词性,词缀或者短语来生成token,那为什么这样子分呢?

因为英文单词是无法穷举的,他太多了,而token是一个可以进行穷举,类似的,中文方块字的token划分方式也是如此,可能将短语、不同词性的词划分成一个token。
而且输出一个词会将输出的词又添加到输入词的后面,然后又生成后续的一个token,直到end的几率是最高的就结束。其实最后的输出并不是概率最大就输出概率大的token,而是进行一个掷色子的操作,所以就导致每次输出的结果可能是不同的,那为什么每次不选概率最大的进行输出呢?

有论文验证,为什么要掷骰子 ,这篇论文就讲了如果每次选几率最大的token可能输出会出现左边的情况,每次说的一样的话,而右边就是比较正常的,所以chatGPT才会出现骗人的场景。

但是台湾省是没有玫瑰花节日的,但你告诉GPT是有的,GPT就会进行乱说,并生成一个假的网址。

是因为你问的问题,包括GPT输出的内容,GPT都会作为模型的输入,最后输出新的回答。
实际上模型所做的事情:
将最有可能输出的token的几率升高一点,将其他token的输出的几率降低一点,然后依次类推:


Transformer里面的每个方块其实就是线性袋鼠的矩阵运算,需要大量可学习的参数,里面有上亿个参数。
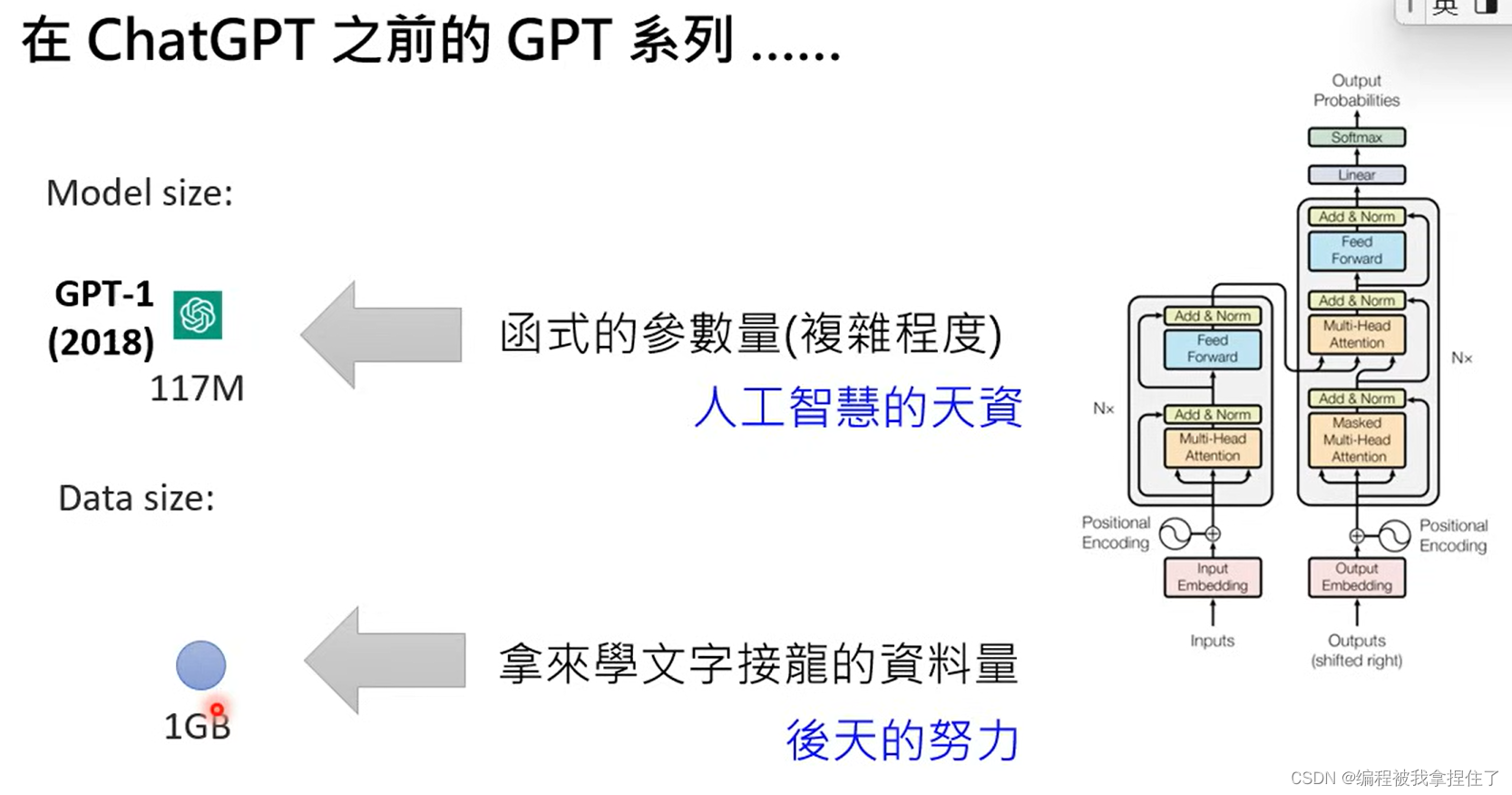
上图是第一代的GPT。
然后慢慢的:


这是当时与其他模型相比时的正确率,当时准确率还不算特别高。然后OPENAI还不善罢甘休,他们说GPT3其实已经很聪明了,他为什么准确率不高是因为他不知道人类社会的规则,他只是学习了网络上的很多资料,碰到什么学什么,根本不知道他要做什么事情,而且回答是毫无逻辑的,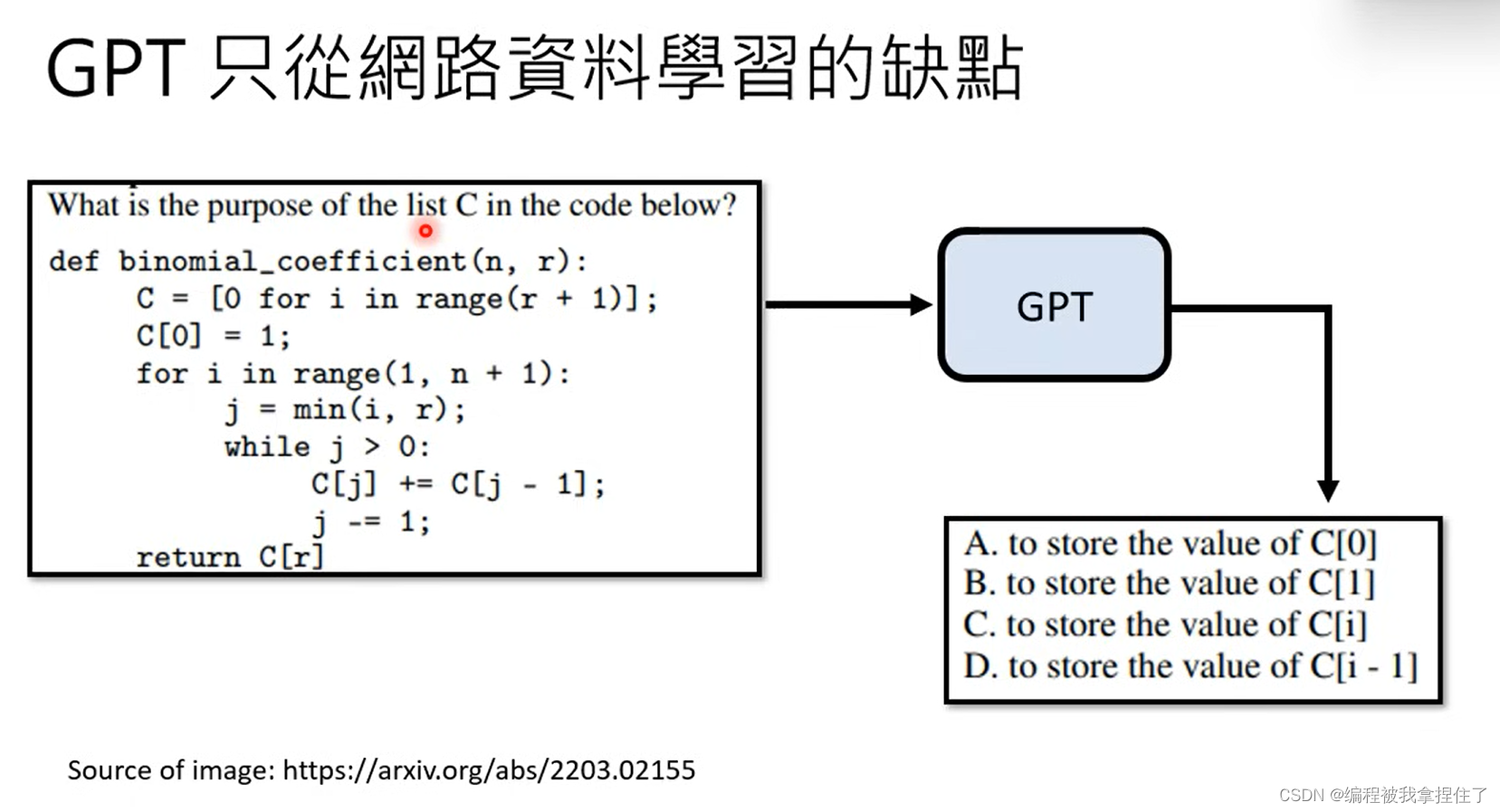
SO,下一个阶段:

那就是让他继续学习。引入人类老师来指导GPT进行学习,那这种方法叫做监督式学习,而前面的方法叫做自监督学习,所以前面就是预训练,后面老师的指导就是大模型微调!(我终于懂了
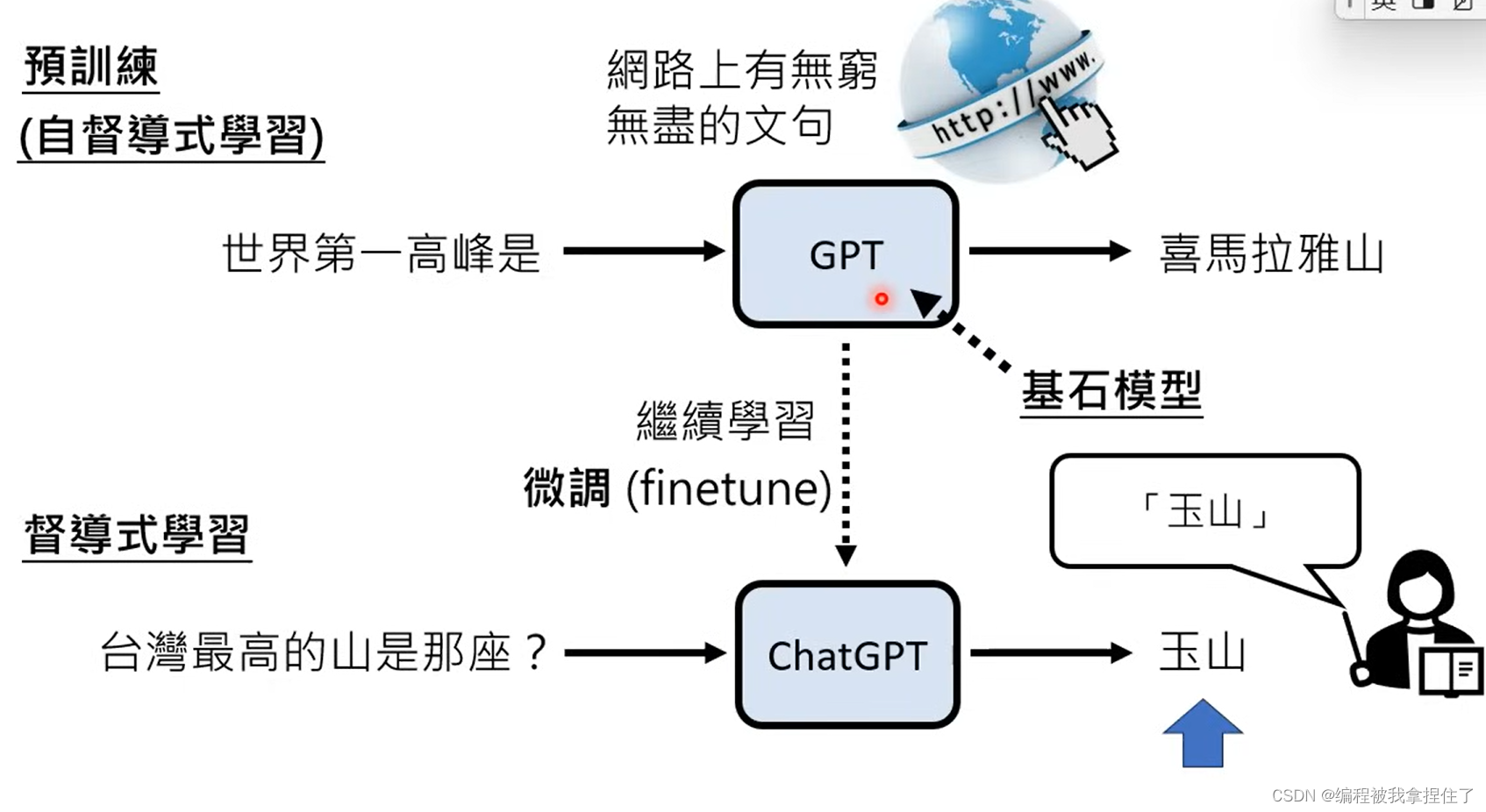
Fine-Tune!!!
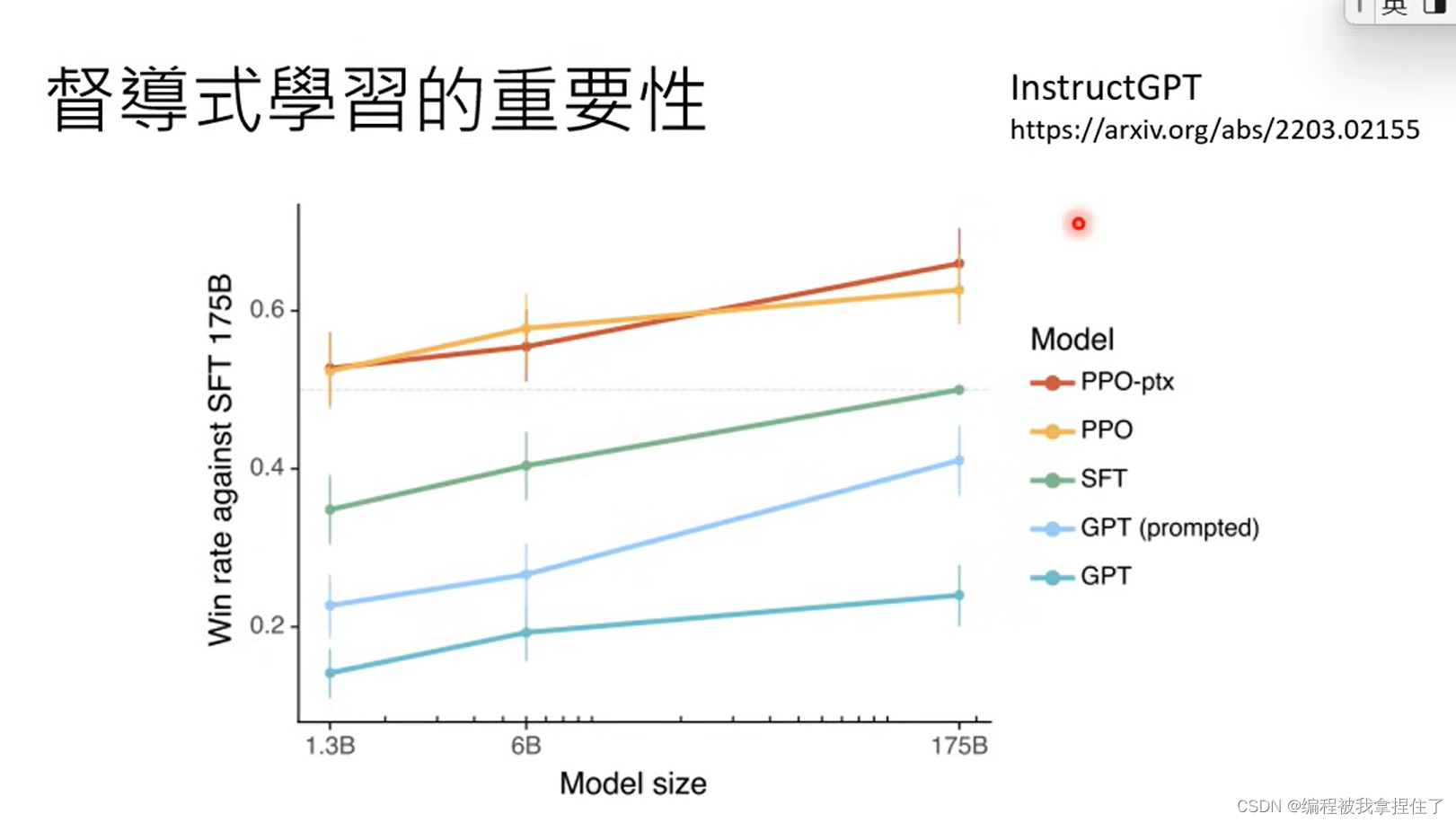
这里有篇论文论证了监督式学习的重要性,https://arxiv.org/abs/2203.02155, 上图说明的问题是:(1)大的模型没有监督式学习老师的监督也可能不会超过小模型通过好的监督式学习的方式(小模型也有机会胜过大模型



还有增强式学习(强化学习,不提供正确的答案,而是提供反馈,什么样的答案是好的,什么样的答案是不好的,监督式学习人类就需要花费比较多的时间或者精力,而增强式学习我们每个人都可以做出贡献,我们在提问的同时就可以隐式的引导GPT回答出更加准确的答案,强化学习这边的知识我还没学过,下次有机会学学。

强化学习一般放在网络的后端进行引导。
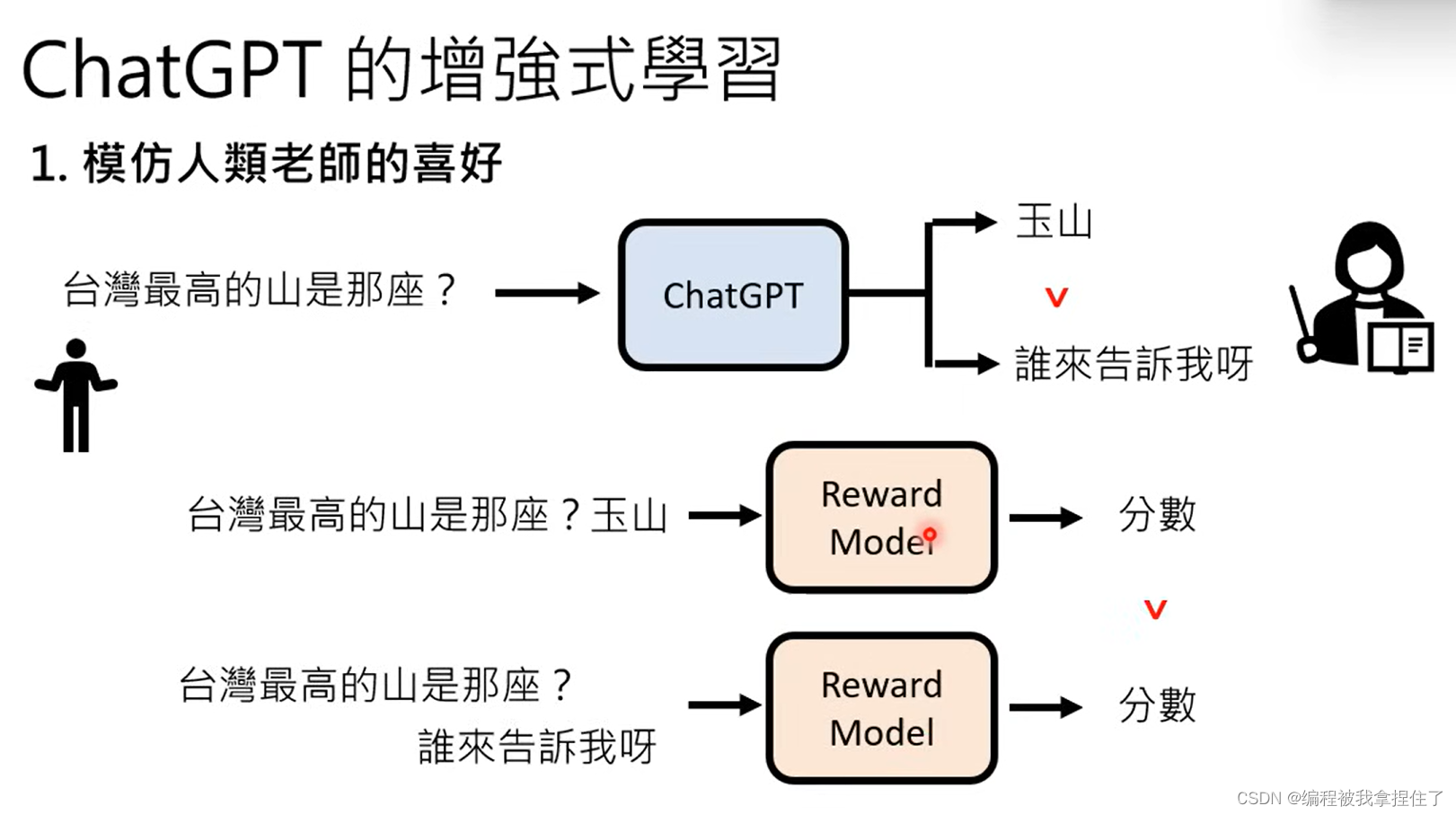
(1)模仿老师的偏好
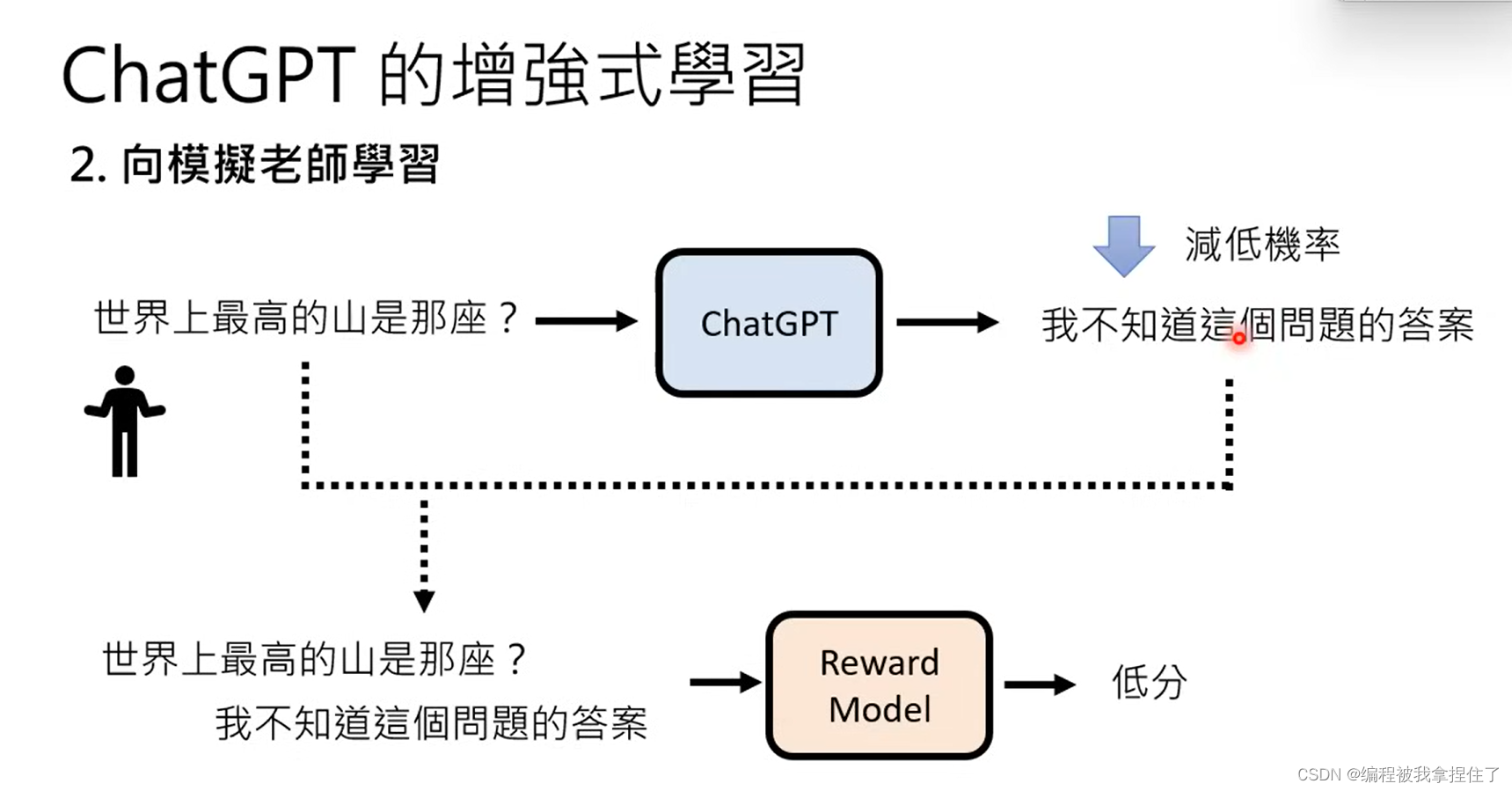
(2)向模拟老师学习
监督式学习+强化学习也就是Alignment!!!(原来如此),就是对齐的过程。
GPT4
然后,GPT4技术报告,长达近百页,作者就有3页,主要就是炫耀GPT4有多麽多麽强。但是技术细节论文里面是没有写的

发挥语言模型的最大能力
1.把需求写清楚
4.鼓励ChatGPT再想一想,让他解决问题时候,不要让他直接给答案,让他一步一步给出计算过程,那他答对的几率就会大大增加。
原文地址:https://blog.csdn.net/m0_61762695/article/details/134606178
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_18959.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!