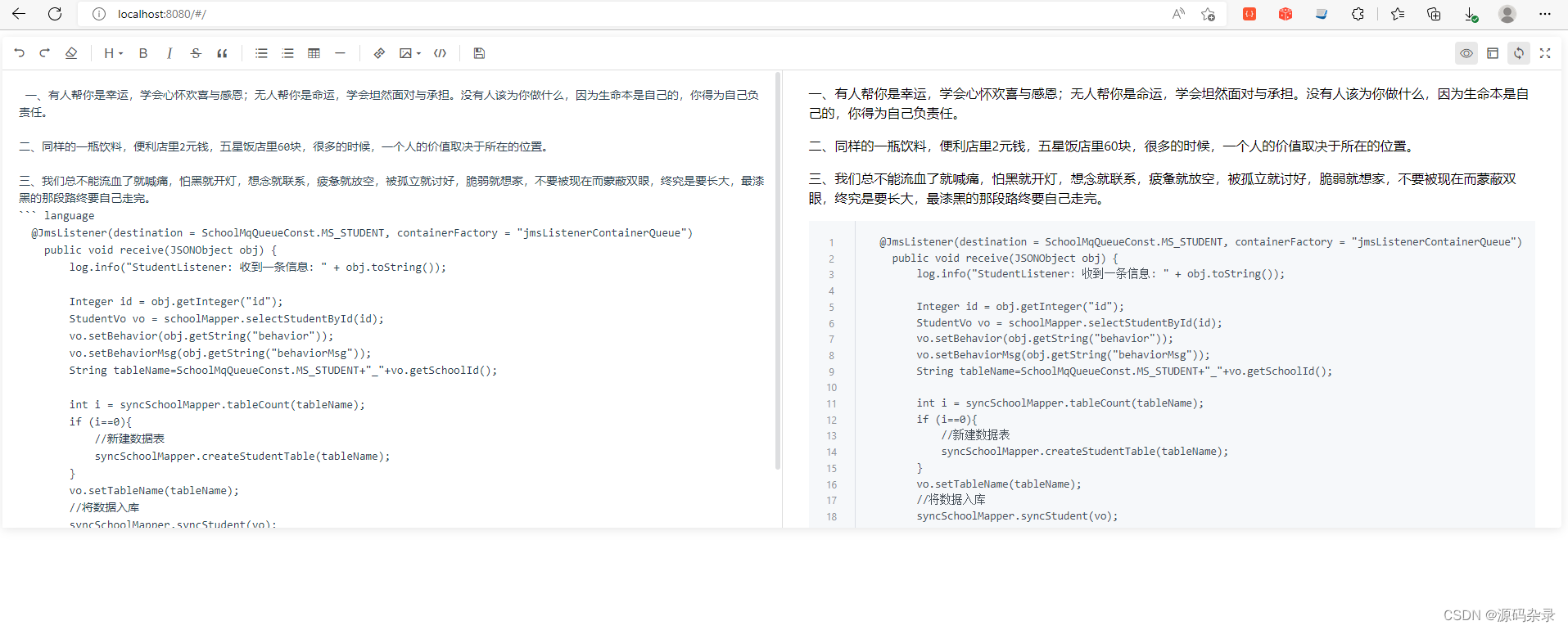
本文介绍: NLP 的一个分支,结合了视觉(空间和布局)特征和文档中存在的文本信息。大多数经典的 NLP 问题都处理文本数据,这些数据包含大量信息,但仍然缺乏帮助我们区分文本内容和含义的视觉队列。鉴于我们正处于像 ChatGPT、Bard、Claude 等人工智能LLM时代,它们本质上是多模式的,即接受图像和文本作为输入,我们确实看到了这些系统的潜力。转向 Visual NLP 的主要原因之一是需要对扫描文档进行信息提取。目前,IE 活动是通过将扫描文档转换为文本并在其上运行 NLP 来进行的。
本文旨在以简单的方式解释 Visual NLP 的关键概念,让你了解 Visual NLP 的含义、它的用例是什么、如何使用它以及为什么它是构建自动提取管道的未来 。

1、什么是Visual NLP?
NLP 的一个分支,结合了视觉(空间和布局)特征和文档中存在的文本信息。 大多数经典的 NLP 问题都处理文本数据,这些数据包含大量信息,但仍然缺乏帮助我们区分文本内容和含义的视觉队列。
鉴于我们正处于像 ChatGPT、Bard、Claude 等人工智能LLM时代,它们本质上是多模式的,即接受图像和文本作为输入,我们确实看到了这些系统的潜力。
转向 Visual NLP 的主要原因之一是需要对扫描文档进行信息提取。 目前,IE 活动是通过将扫描文档转换为文本并在其上运行 NLP 来进行的。
现在,让我们看看这种方法的局限性:
2、Visual NLP用例
2.1 从扫描收据中提取关键信息

2.2 视觉质量检查

3、基于 Visual NLP 的自动化信息提取流程
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。