InnoDB逻辑存储结构
InnoDB将所有数据都存放在表空间中,表空间又由段(segment)、区(extent)、页(page)组成。InnoDB存储引擎的逻辑存储结构大致如下图。下面我们就一个个来看看。
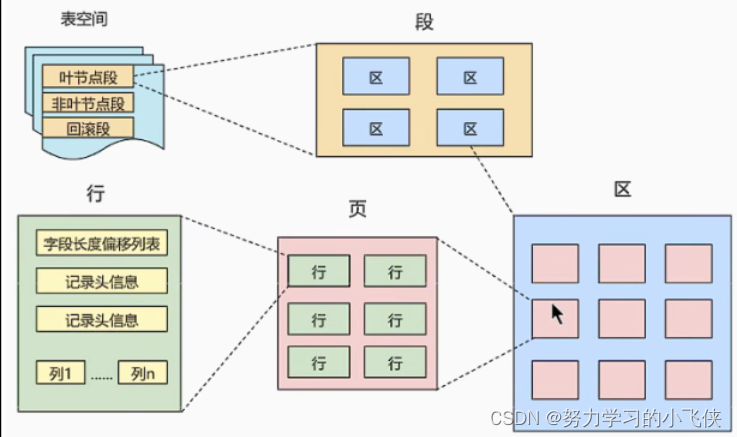
页( InnoDB 磁盘管理的最小单位)
页的组织方式
数据页之间在物理存储空间上不需要连续,只需要通过一个双向链表连接,在聚簇索引中数据页内数据按照主键大小顺序组成单向链表(每一个数据页会为它里面的数据生成一个页目录,避免单向链表的遍历)
页的内部结构
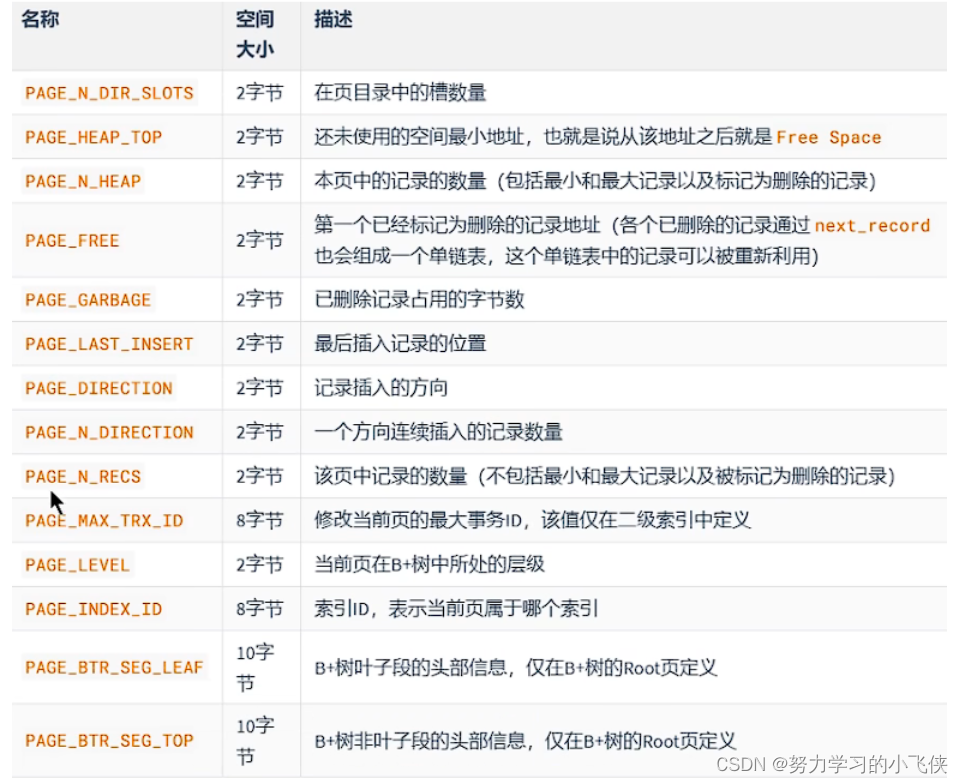
- FIL_PAGE_OFFSET(页号)
- FIL_PAGE_UNDO_LOG(事务回滚)
- FILE_PAGE_INDEX(索引页)
- FILE_PAGE_PRE+NEXT上一页下一页的页号
- FILE_PAGE_SPACE_OR_CHECKSUM(当前页面校验和)
- FILE_PAGE_LSN(页面最后被修改对应的日志序列位置)
校验和+LSN
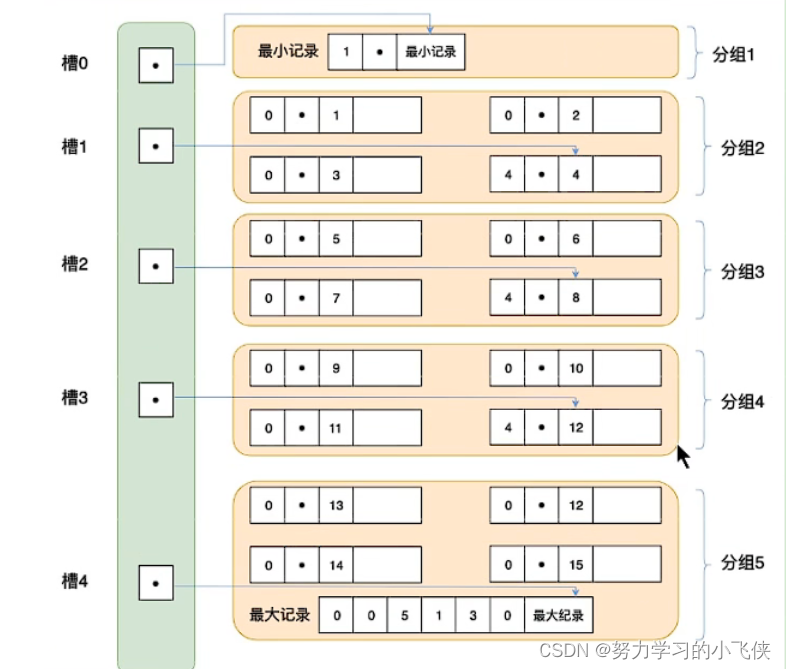


如何在页目录下快速查找数据
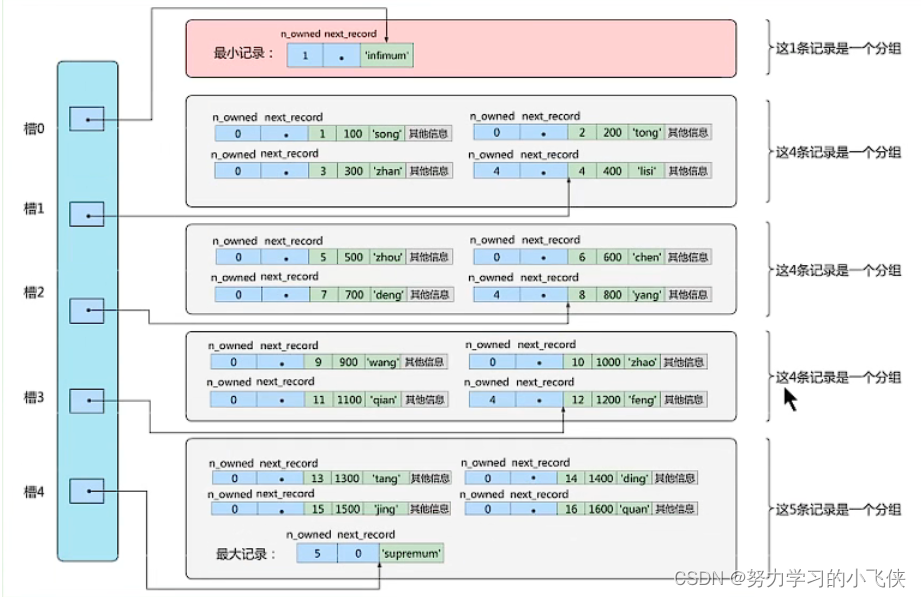
小结:
1.通过二分法确定所在的槽,并找到槽所在分组中主键最小的那个记录
我们自己存储的记录会按照指定的行格式存储到User Records中 ,但在一开始并没有User Records这个部分,当我们每插入一条数据就从Free Space申请一个记录大小的空间到User Records部分来存储这条记录,当Free Space的空间被用完后就意味着这个页的空间已经满了,需要申请新的页
行格式
种类:
COMPACT:
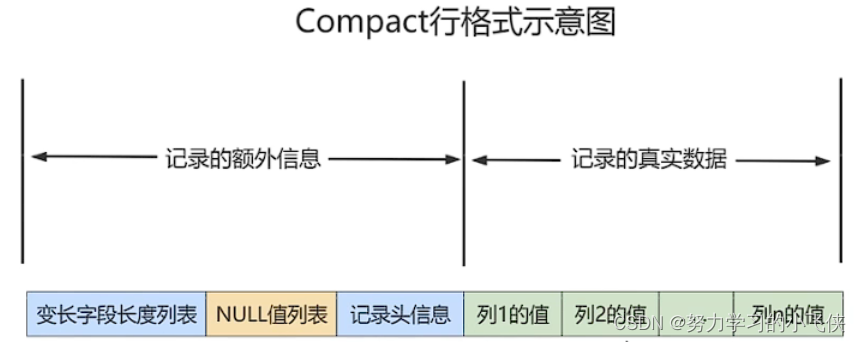
varchar 类型是变长的,例如 varchar(50),那么这个字段值的长度范围:0 ~ 50 个字符。但是,不是每个字段值都刚好50个字符,肯定会有的长有的短。
必须不会的,如果都按照最大长度存储,当出现值不满 50个字符长度时,会浪费磁盘空间和内存空间。
为什么也浪费内存空间,数据不是存放在磁盘么?大家不会忘了缓冲池的作用了吧?哈哈,要记得缓冲池和磁盘数据交换的单位就是数据页而数据行是存放在数据页中的
NULL值列表
记录头信息
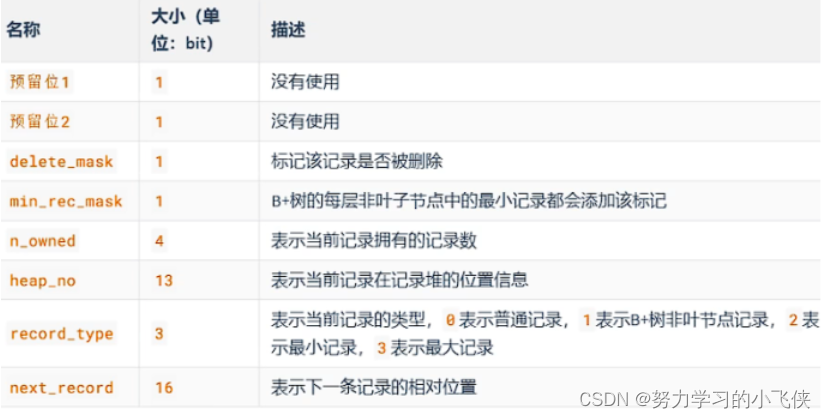
因为立即在磁盘上移除该记录会导致其他记录进行重新排列,导致性能消耗。将不需要的记录打上标记,这些删除记录会组成链表,这些垃圾链表中占用的空间变为可重用空间,之后有记录插入时可以直接覆盖垃圾链表中的记录
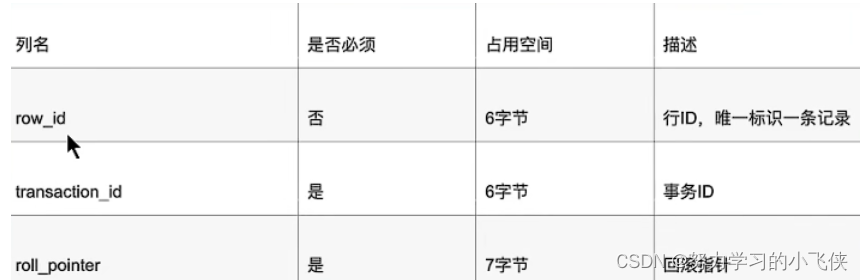
记录的真实数据
行溢出问题
数据页的默认大小是 16kb,但是某些字段的值可以远远大于 16kb。
例如变长字段类型 varchar(N):N 最大可为 65532(65kb),这就远远大于 16kb。
当然了,还有 text 和 blog 字段,这些都是大字段,都可以超过 16kb。
怎么解决?
当一行数据超了 16kb,会在超了大小的那个字段中,可能仅仅包含他的一部分数据,然后同时包含一个20个字节的指针,指向存储了这行数据超了的部分的其他数据页。
DYNAMIC和COMPARESSED
原文地址:https://blog.csdn.net/qq_62592925/article/details/134721945
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_19249.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!