了解了如何创建和运用模型之后,我们再来探讨下如何构造一个领域模型。这就需要我们对领域进行分离,了解领域对象的分类及生命周期的管理。
一 分离领域
与领域有关的代码分散在大量的其他代码之中,那么查看和分析领域代码就会变得异常困难。也难以进行领域驱动设计。所以我们首先应该对领域进行分层。
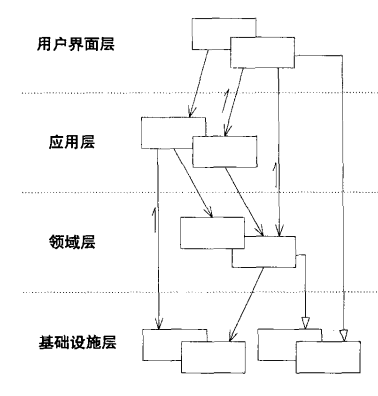
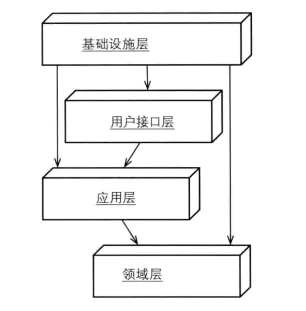
我们需要给复杂的应用程序划分层次。在每一层内分别进行设计,使其具有内聚性并且只依赖于它的下层。采用标准的架构模式,只与上层进行松散的耦合。将所有与领域模型相关的代码放在一个层中,并把它与用户界面层、应用层以及基础设施层的代码分开。领域对象应该将重点放在如何表达领域模型上,而不需要考虑自己的显示和存储问题,也无需管理应用任务等内容。这使得模型的含义足够丰富,结构足够清晰,可以捕捉到基本的业务知识,并有效地使用这些知识。
目前软件大都采用LAYERED ARCHITECTURE(分层架构)模式进行对领域进行分层,其中比较成熟的分层方式是以下4个概念层,或相应的某种变体:
用户界面层(或表示层)
负责向用户显示信息和解释用户指令。这里指的用户可以是另一个计算机系统,不一定是使用用户界面的人。
二 领域对象分类
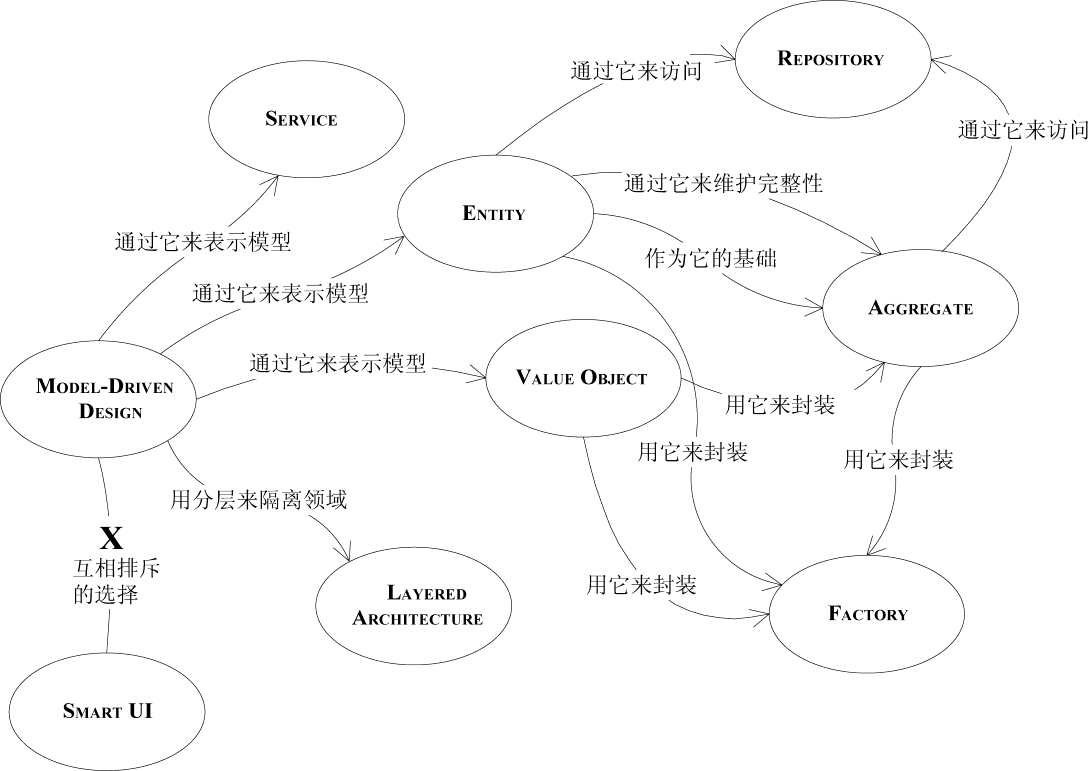
2.1 实体(ENTITY)
2.2 值对象(VALUE OBJECT)
2.3 服务(SERVICE)
2.4 模块(MODULE)
三 管理领域对象的生命周期
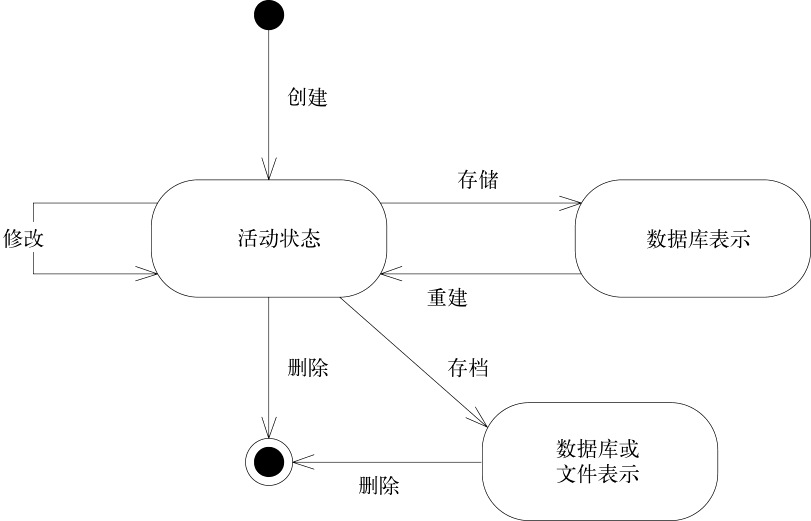
3.1 聚合(AGGREGATE)
3.2 工厂(FACTORY)
3.3 存储库(REPOSITORY)
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。





