论文链接:https://arxiv.org/pdf/2311.07919.pdf
开源代码:https://github.com/QwenLM/Qwen-Audio

一、背景
大型语言模型(LLMs)由于其良好的知识保留能力、复杂的推理和解决问题能力,在通用人工智能(AGI)领域取得了重大进展。然而,语言模型缺乏像人类一样感知非文本模态(如图像和音频)的能力。作为一种重要模态,语音提供了超越文本的多样且复杂的信号,如人声中的情感、语调和意图,自然声音中的火车汽笛、钟声和雷声,以及音乐中的旋律。使LLMs能够感知和理解丰富的音频信号以进行音频交互引起了广泛关注。
以前关于遵循指令的工作主要是通过继承大型(多模态)LLMs的能力,采用轻量级的监督微调来激活模型的能力以与用户意图对齐。然而,由于缺乏能够处理各种音频类型和任务的预训练音频语言模型,大多数工作在音频交互能力上受到限制。现有的代表性音频语言多任务语言模型,如SpeechNet、SpeechT5、VIOLA 、Whisper和Pengi,仅限于处理特定类型的音频,如人声或自然声音。
二、简介


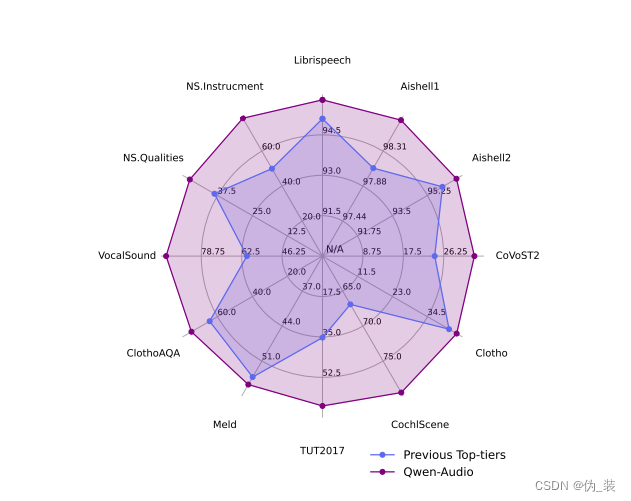
三、方法与模型
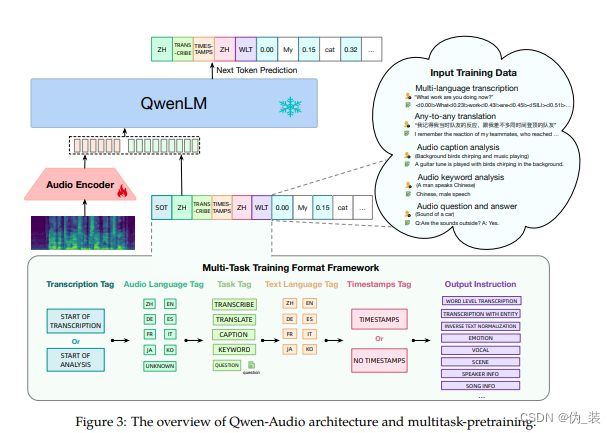
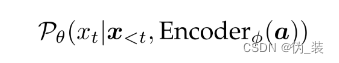
1、音频编码器
2、大语言模型
3、多任务预训练
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。