Paraformer(Parallel Transformer)非自回归端到端语音系统需要解决两个问题:
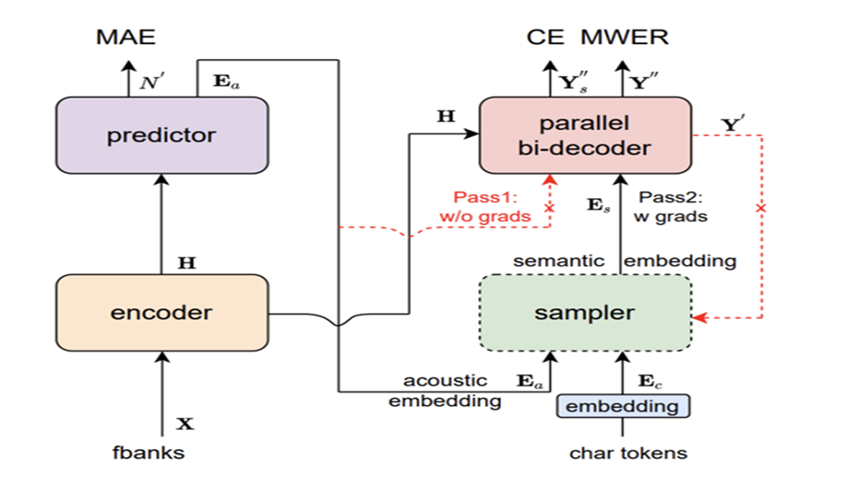
Paraformerr的组成:Encoder(编码器),Predictor(预测器),Sampler(采样器),Decoder(解码器),loss function。
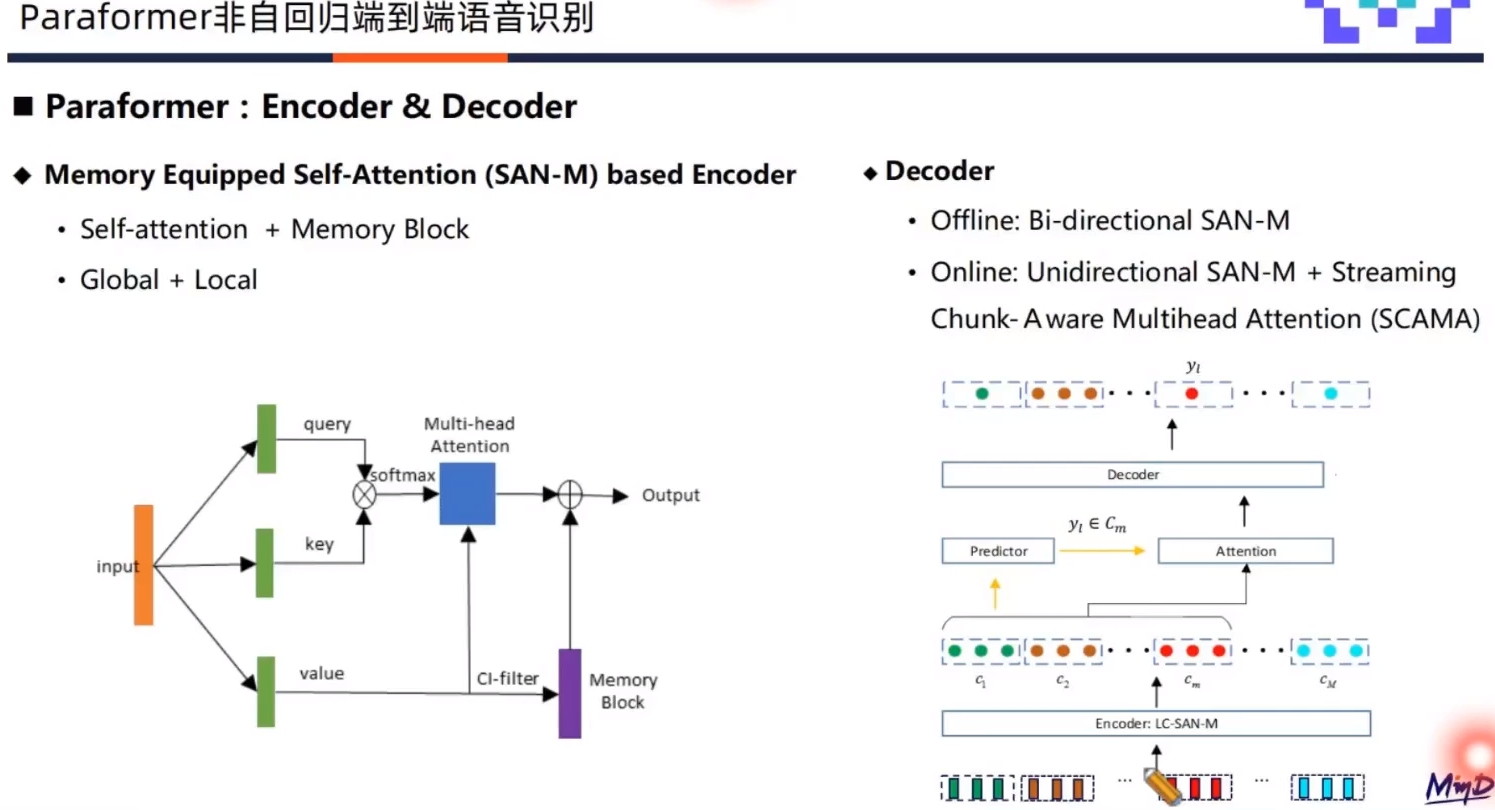
Encoder
采用SAN-M结构,对于语音建模来说,全局建模和局部建模都极为关键,所以标准的Self-attention层增加了局部建模模块Memory Block,从而增加Self-attention的局部建模能力。
Decoder
离线和流式系统采用不同结构。离线识别使用双向SAN-M,流式识别采用单向的SAN-M,并结合基于SCAMA的流式注意力机制来实现。SCAMA流式注意力机制原理如上图所示,首先针对语音特征进行分chunk操作,送入encoder建模后进入predictor分别预测每个chunk的输出token数目。Decoder在接受到token数目和隐层表征后,来基于SCAMA流式注意力机制预测每个chunk的输出。
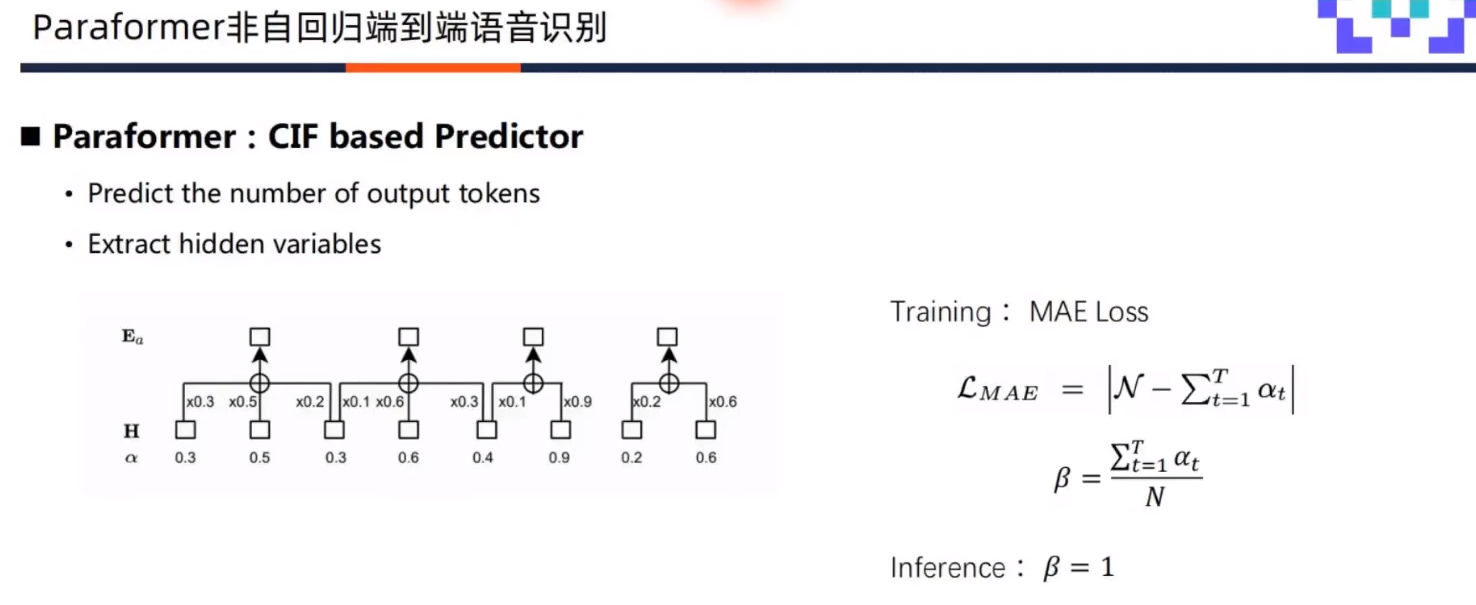
Predictor
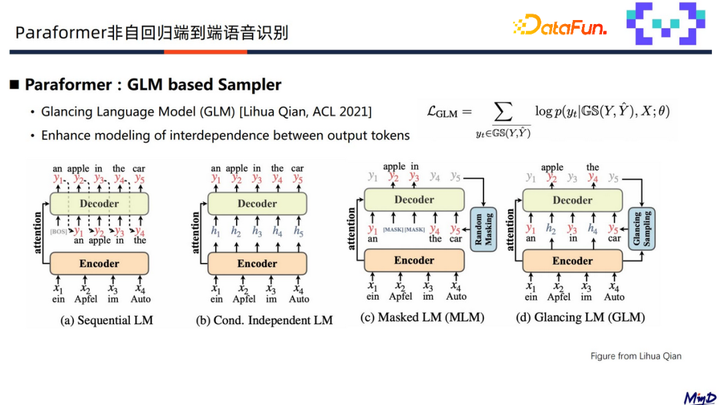
Sampler
loss
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。