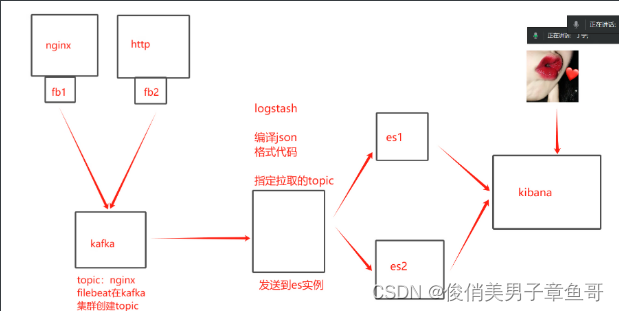
3台es+file,3台kafka
20.0.0.10 es+file
20.0.0.20 es+file
20.0.0.30 es+file
20.0.0.11 kafka
20.0.0.12 kafka
20.0.0.13 kafka
在es1主机上解压filebeat
cd filebeat
安装nginx服务
vim /usr/local/nginx/html/index.html
this is nginx
到浏览器测试一下页面访问
cp filebeat.yml filebeat.yml.bak
#做一个备份
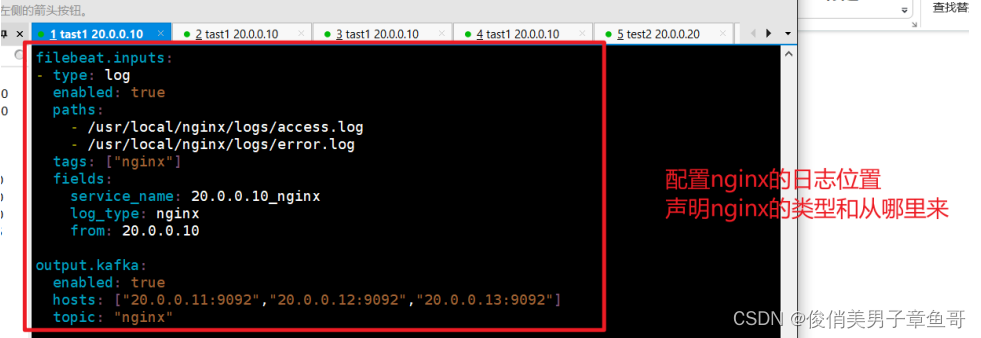
vim filebeat.yml
- type: log
enabled: true
paths:
- /usr/local/nginx/logs/access.log
- /usr/local/nginx/logs/error.log
tags: ["nginx"]
fields:
service_name: 20.0.0.10_nginx
log_type: nginx
from: 20.0.0.10
output.kafka:
enabled: true
hosts: ["20.0.0.11:9092","20.0.0.12:9092","20.0.0.13:9092"]
topic: "nginx"
nohup ./filebeat -e -c filebeat.yml > filebeat.out &
#运行filebeat.yml
tail -f filebeat.out
#查看日志
在es1主机上配置logstash
cd /opt/log
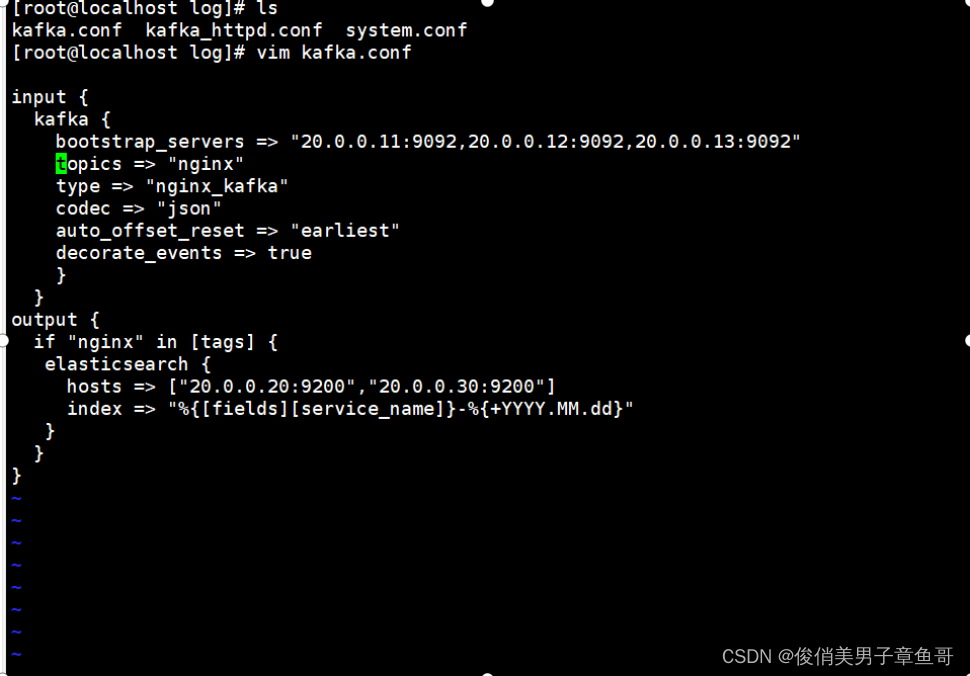
vim kafka.conf
input {
kafka {
bootstrap_servers => "20.0.0.11:9092,20.0.0.12:9092,20.0.0.13:9092"
topics => "nginx"
type => "nginx_kafka"
codec => "json"
#解析json格式的代码
auto_offset_reset => "earliest"
#从头拉取,latest
decorate_events => true
#传递给es实例中的信息包含kafka的属性数据
}
}
output {
if "nginx" in [tags] {
elasticsearch {
hosts => ["20.0.0.20:9200","20.0.0.30:9200"]
index => "%{[fields][service_name]}-%{+YYYY.MM.dd}"
}
}
}
配置完成
使用logstash拉起kafka.conf
logstash -f kafka.conf --path.data /opt/nginx1
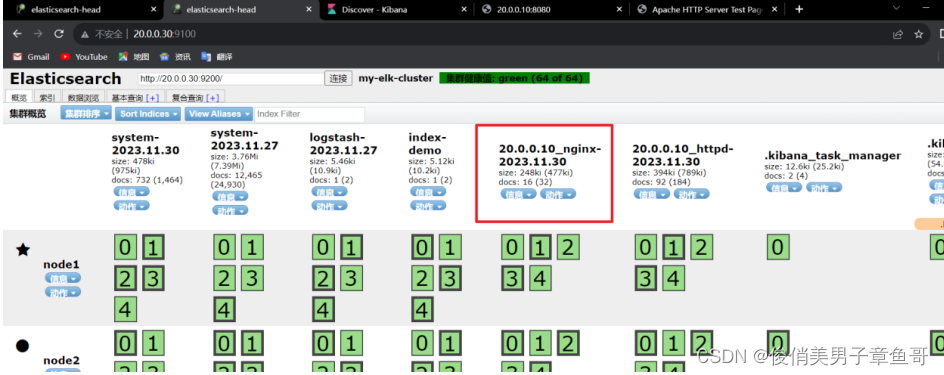
启动后到web页面查看是否生成节点文件
生成节点文件后到kibana页面创建索引
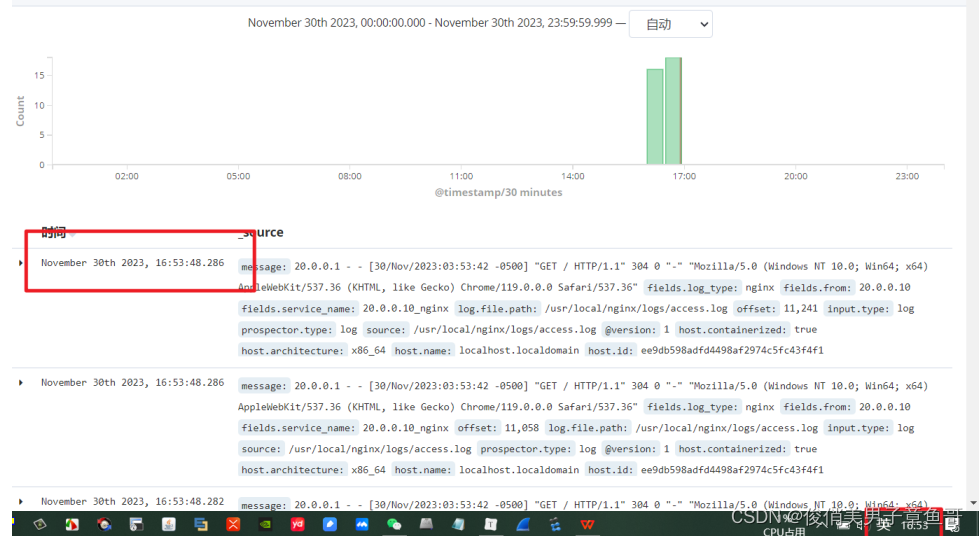
访问nginx的页面后到kibana页面查看数据是否同步



原文地址:https://blog.csdn.net/m0_75209491/article/details/134717481
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_19661.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。





