CBAM
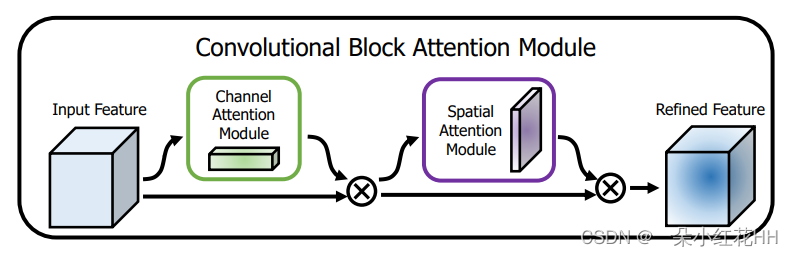
本文提出了一种卷积块注意力模块(CBAM),它是卷积神经网络(CNN)的一种轻量级、高效的注意力模块。该模块沿着通道和空间两个独立维度依次推导注意力图,然后将这些注意力图与输入特征图相乘,进行自适应特征细化。CBAM 可以无缝集成到任何 CNN 架构中,开销几乎可以忽略不计,并且可以与基本 CNN 一起进行端到端训练。作者通过在 ImageNet-1K、MS COCO 检测和 VOC 2007 检测数据集上的大量实验验证了 CBAM,结果表明各种模型在分类和检测性能上都有一致的提高。论文还讨论了网络工程和注意力机制方面的相关工作,并强调了所提出的 CBAM 模块的贡献。
CBAM 模块由两个分支组成:通道注意力分支和空间注意力分支。
Channer Attention Module
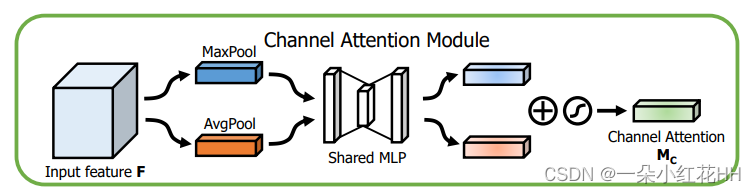
通道注意力分支旨在捕捉特征图不同通道之间的相互依存关系。它使用全局平均池化操作来获取通道统计信息,然后应用两个全连接层来生成通道注意图。然后将这些注意力图与原始特征图按要素相乘,以突出重要通道。
Spatial Attention Module
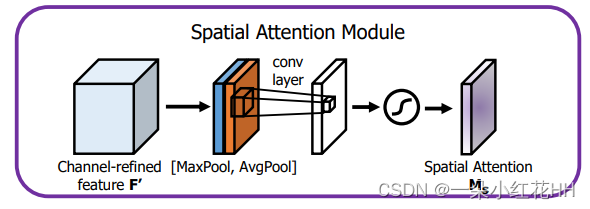
另一方面,空间注意力分支侧重于捕捉每个通道内的空间依赖性。它采用挤压-激发操作,首先使用全局平均池化技术对输入特征图进行挤压,以获得通道统计信息。然后,应用两个全连接层生成空间注意力图。这些图随后与原始特征图按元素相乘,以强调重要的空间位置。
CBAM 模块通过元素相加的方式将通道和空间注意力图结合起来。这样,该模块就能在网络中学习 “关注什么 “和 “关注哪里”,从而有效改善信息流并增强 CNN 的表示能力。
就是这么简单!!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。





