11月25日,第 16 届中国 R 会议暨 2023 X-AGI 大会在在中国人民大学逸夫会堂拉开帷幕,本次会议由中国人民大学统计学院、中国人民大学应用统计科学研究中心、统计之都、原灵科技和中国商业统计学会人工智能分会(筹)主办,中国人民大学统计学院数据科学与大数据统计系承办。和鲸科技作为国内领先的数据智能科技企业兼大会赞助方,出席本次大会。

大会致力于探讨数据科学在各学科、各行业的探索和实践。为更好地介绍和推广先进生产力,和鲸产品副总监童毅炜受邀在 25 日下午的计算平台专场发表主题报告,题目为《ModelOps 在数据科学平台中的实践与应用》,旨在分享和鲸在计算平台设计与搭建过程中的思考与经验。

ModelOps 是一种模型全生命周期的管理理念,指希望把数据科学、软件工程和具体业务的工作流程自动化、集成化,让模型的开发与部署变得更快更简单。
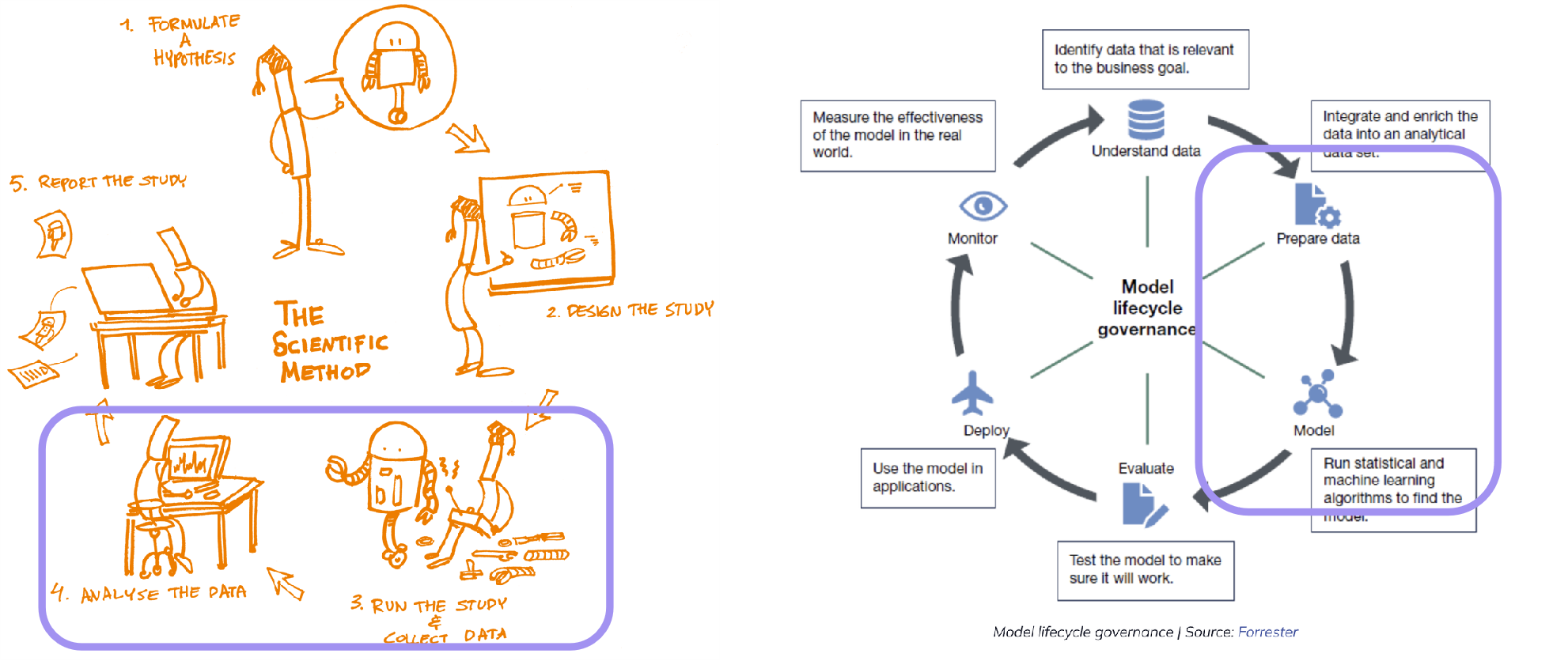
模型要素管理,也是科研要素管理


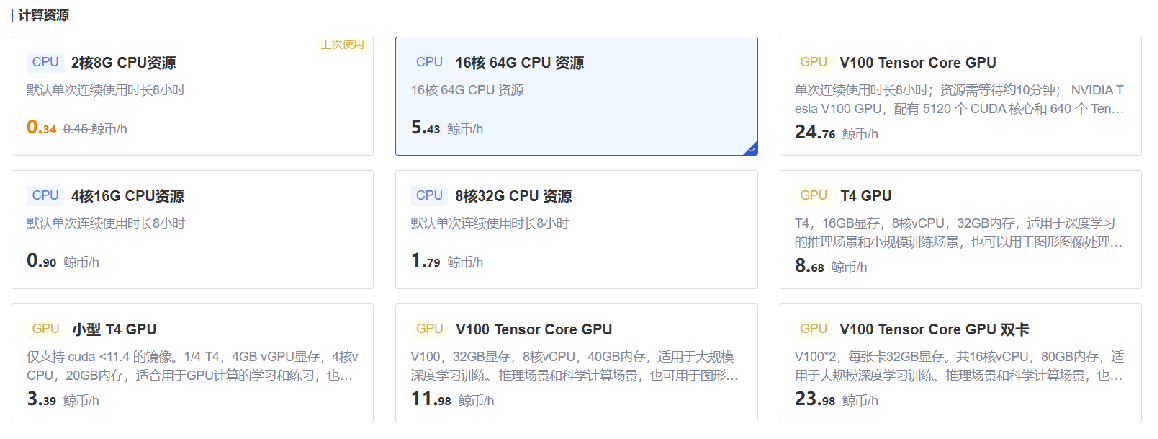
模型成果管理,也是科研成果管理?

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






![[软件工具]文档页数统计工具软件pdf统计页数word统计页数ppt统计页数图文打印店快速报价工具](https://img-blog.csdnimg.cn/direct/09dfbaff3e9a47a9a551dd65fef5d482.jpeg)