一、正则表达式
1.1 什么是正则表达式
正则表达式是一种用于匹配和操作文本的强大工具,它是由一系列字符和特殊字符组成的模式,用于描述要匹配的文本模式。 正则表达式可以在文本中查找、替换、提取和验证特定的模式。
正则表达式:匹配文章中的字符
1.2 元字符
| 符号 | 作用 |
| . | 代表任意字符 |
| [] | 代表单个字符 |
| [^] | 代表指定范围外的任意单个字符 |
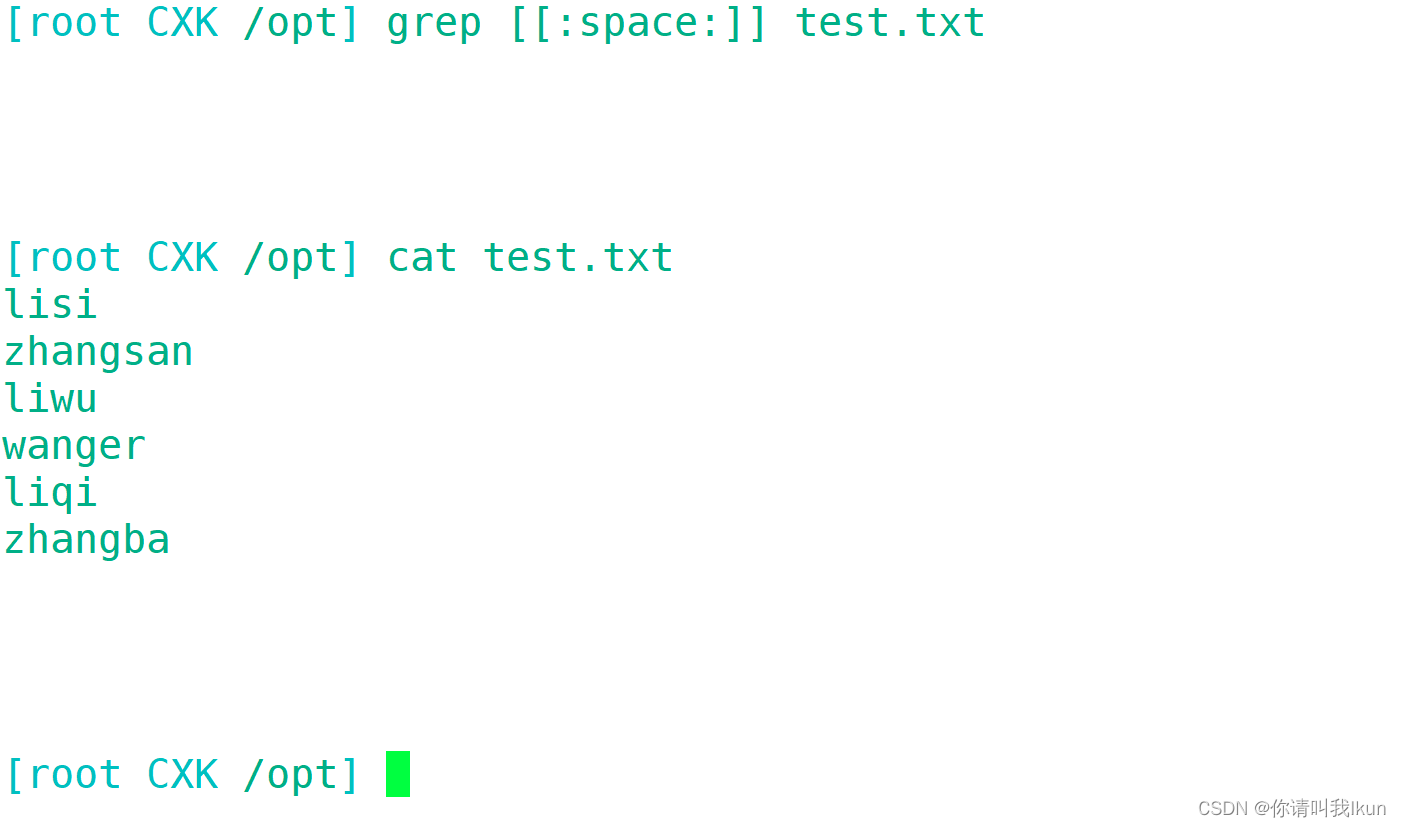
| [:space:] | 包括空格,制表符(tab键) |
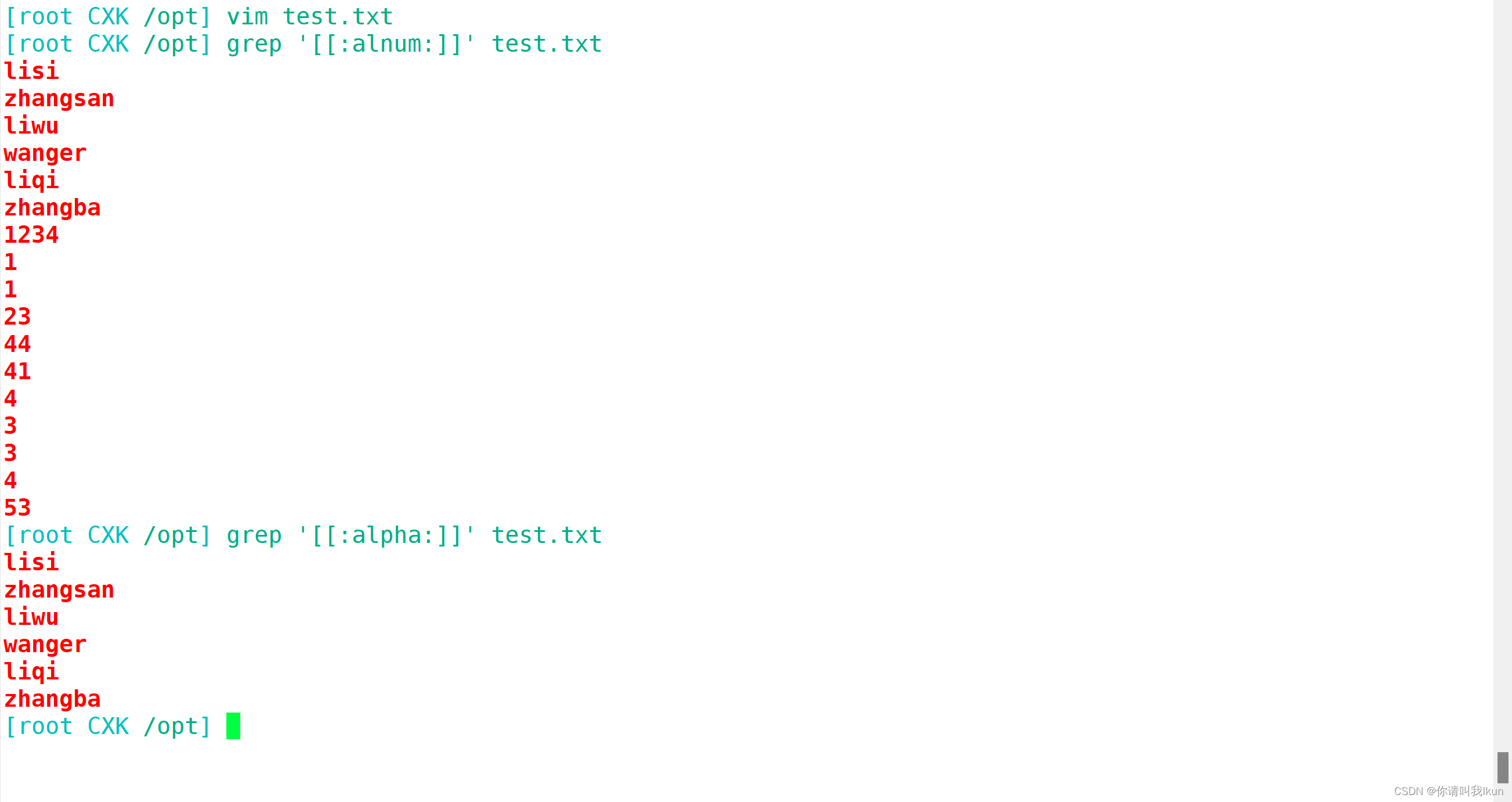
| [:alnum:] | 代表字母和数字 |
| [:alpha:] | 代表任意大小写英文字母 |
.
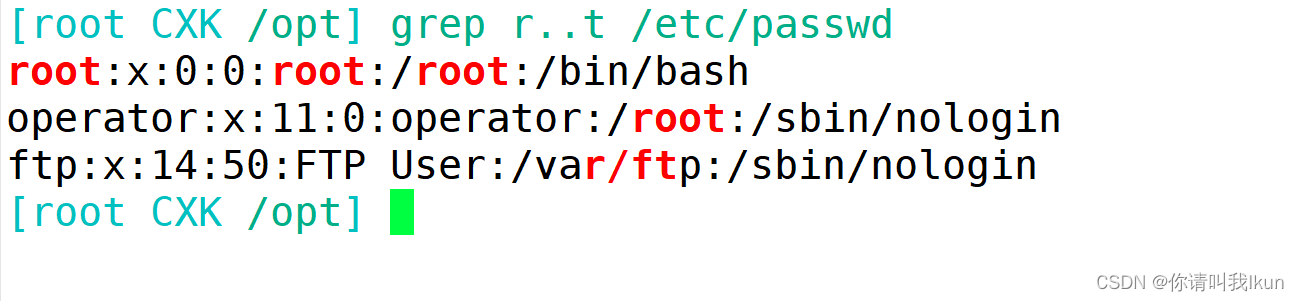
[a-z]
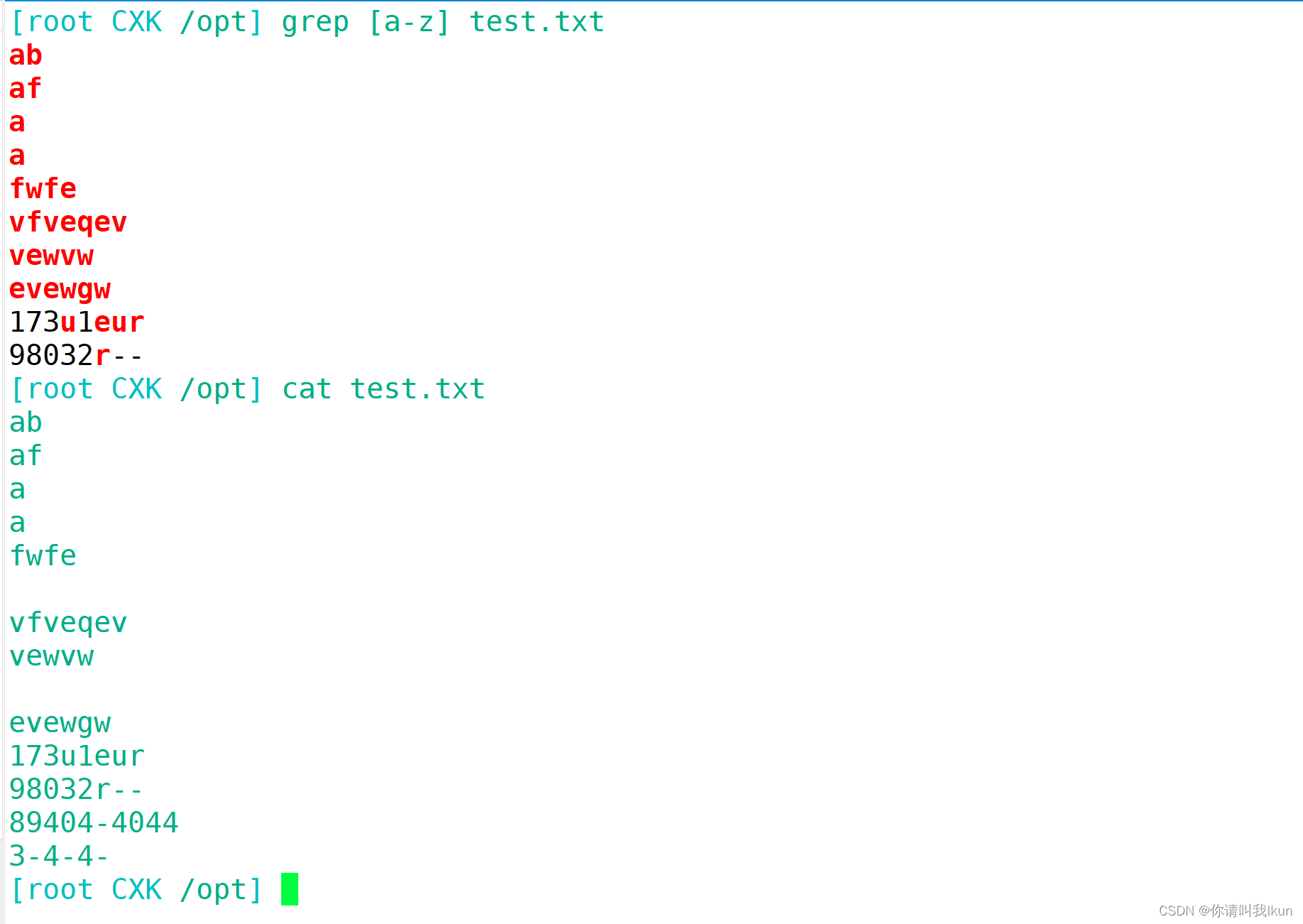 [^li]
[^li]

1.3 表示次数
| 符号 | 作用 |
| * | 0——正无穷次 |
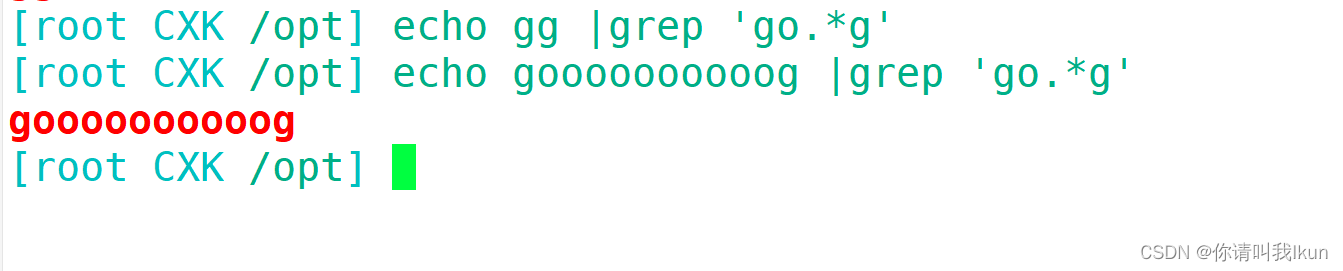
| .* | 任意长度的任意字符,不包括0次 |
| ? | 可有可无,代表一次或0次 |
| + | 1——正无穷 |
| {n} | 前面的字符出现了n次 |
| {n,m} | 前面的字符出现了n-m次 |
| {3,} | 前面的字符出现了最少3次 |
| {,5} | 前面的字符出现了最多5次 |
实际应用:


{n}前面的字符出现了n次

{3,}前面的字符出现了最少3次


*0——正无穷次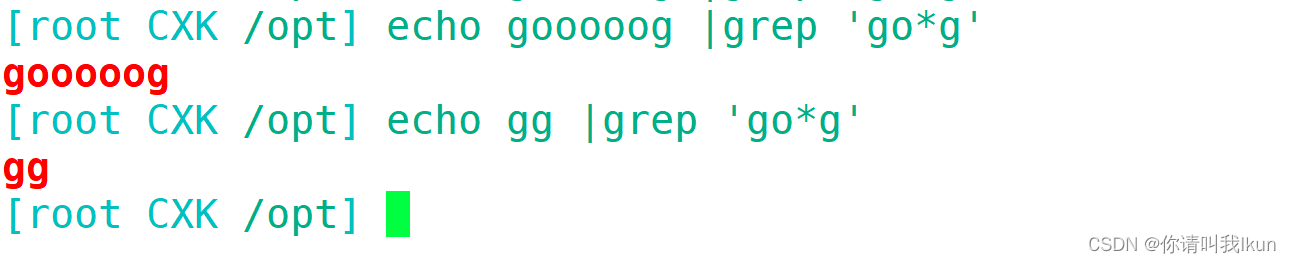
? 可有可无,代表一次或0次

+ 可有可无,代表一次到正无穷次

{,3}前面的字符出现了最多3次

1.4 位置锚定
| 符号 | 作用 |
| ^$ | 空行 |
| ^[[:space:]]*$ | 空白行 |
| <或b | 字符的开头 |
| >或b | 字符的结尾 |
实际应用:
过滤出不是以#号开头的行

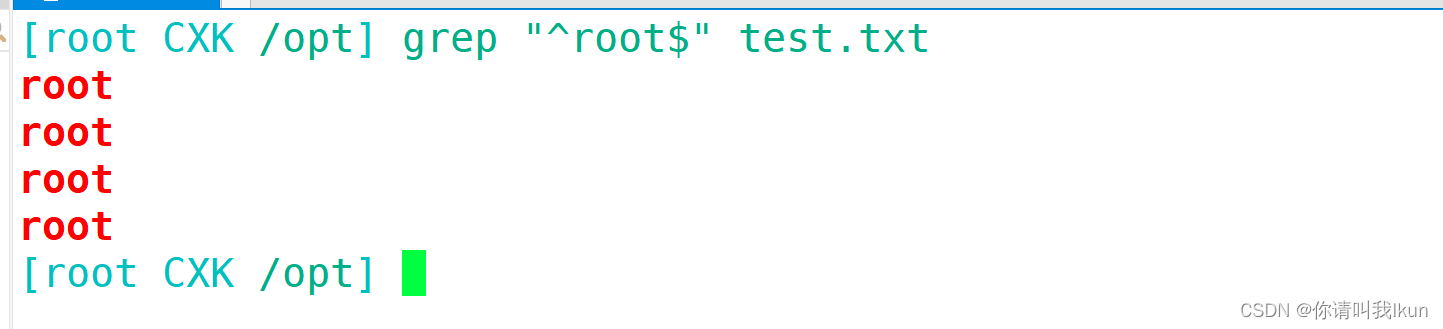
 1.5 分组或其他
1.5 分组或其他
实际应用:



1.6 扩展正则表达式
| 符号 | 作用 |
| * | 匹配前面字符任意次 |
| ? | 0或1次 |
| + | 1次或多次 |
| {n} | 匹配n次 |
| {m,n} | 至少m,至多n次 |
| {,n} | 匹配前面的字符至多n次,<=n,n可以为0 |
| {n,} | 匹配前面的字符至少n次,<=n,n可以为0 |
| 符号 | 作用 |
| () | 分组 |
| | | 或者 |
| a|b | a或b |
| C|cat | C或cat |
| (C|c)at | Cat或cat |
练习:
1.表示邮箱

2.表示qq号

3.表示手机号码

二、grep
选项:
-color=auto 对匹配到的文本着色显示
-m # 匹配#次后停止
grep -m 1 root /etc/passwd #多个匹配只取第一个
-v 显示不被pattern匹配到的行,即取反
grep -Ev '^[[:space:]]*#|^$' /etc/fstab
-i 忽略字符大小写
-n 显示匹配的行号
-c 统计匹配的行数
grep -c root /etc/passwd #统计匹配到的行数
-o 仅显示匹配到的字符串
-q 静默模式,不输出任何信息
-A # after, 后#行
grep -A3 root /etc/passwd #匹配到的行后3行业显示出来
-B # before, 前#行
-C # context, 前后各#行
-e 实现多个选项间的逻辑or关系,如:grep –e ‘cat ' -e ‘dog' file
grep -e root -e bash /etc/passwd #包含root或者包含bash 的行
grep -E root|bash /etc/passwd
-w 匹配整个单词
grep -w root /etc/passwd
useradd rooter
-E 使用ERE,相当于egrep
-F 不支持正则表达式,相当于fgrep
-f file 根据模式文件,处理两个文件相同内容 把第一个文件作为匹配条件
-r 递归目录,但不处理软链接
-R 递归目录,但处理软链接实际应用
过滤非空行





三、awk
3.1 什么是awk
AWK 是一款出色的文本处理工具。它是可用于任何环境(不仅仅是 Linux)的最强大的数据处理引擎之一。这种编程和数据处理语言(以其创始人 Alfred Aho、Peter Weinberger 和 Brian Kernighan 的姓氏首字母命名)只会随着知识的积累而变得更好,AWK 提供了强大的功能:样式加载 和流式处理、数学运算符、流程控制语句,甚至内置变量和函数。AWK 可以进行样式加载、流式处理、数学运算符、过程控制语句,甚至内置变量和函数。AWK 几乎拥有完整语言的所有强大功能。事实上,AWK 拥有自己的语言:AWK 编程语言被其三位创建者正式定义为 “样式扫描和处理语言”。可以创建无数的简短程序来读取输入文件、排序数据、处理数据、对输入进行计算、生成报告等。
3.2 awk的工作原理
逐行读取文本,默认以空格或tab键为分隔符进行分隔,将分隔所得的各个字段保存到内建变量中,并按模式或者条件执行编辑命令。
通常awk是将一行数据拆分为多个字段,操作者,可以选取指定的字段对其进行高效率的操作
3.3 awk的基础用法
| 符号 | 作用 |
| -F | 指定分隔符 |
| -v | 指定变量 |
实际应用:
再打印一遍



 先处理BEGIN 中的式子
先处理BEGIN 中的式子
连续的空白符
 取
取


3.4 awk 常见的内置变量
| 内置变量 | 作用 |
| $0 | 当前处理的行的整行内容 |
| $n | 当前处理行的第n个字段(第n列) |
| NR | 当前处理的行的行号(序数) |
| NF | 当前处理的行的字段个数。$NF代表最后一个字段 |
| FS | 列分割符。指定每行文本的字段分隔符,默认为空格或制表位。与”-F”作用相同 |
| OFS | 输出内容的列分隔符 |
| FILENAME | 被处理的文件名 |
| RS | 行分隔符。awk从文件中读取资料时,将根据RS的定义把资料切割成许多条记录, 而awk一次仅读入一条记录进行处理。预设值是”n” |
3.5 自定义变量
3.6 打印行内容及其行号

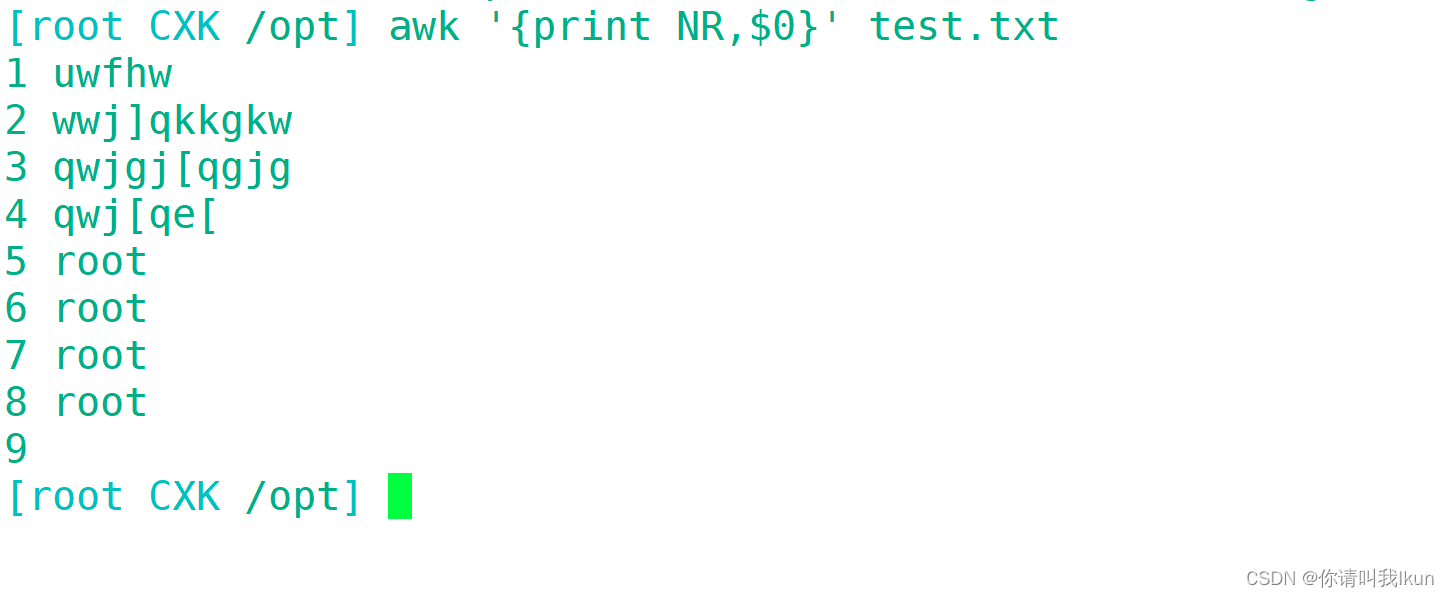
3.6.1 指定行和指定行范围打印
awk 'NR==3{print}' test.txt
awk 'NR==3,NR==5{print}' test.txt
awk '(NR>=3)&&(NR<=5){print}' test.txt 
3.6.2 奇偶行打印

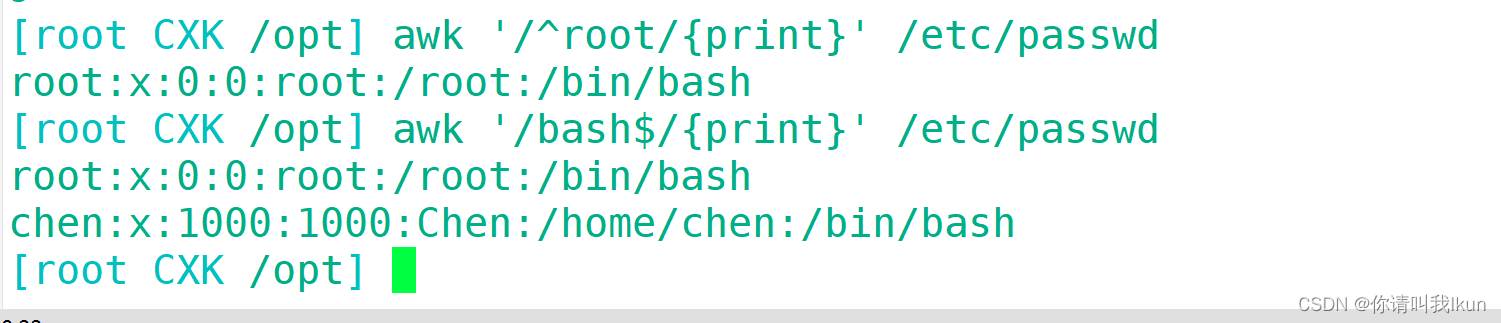
3.6.3 文本内容匹配过滤打印
3.7 BEGIN END
应用:

 3.8 条件判断打印
3.8 条件判断打印
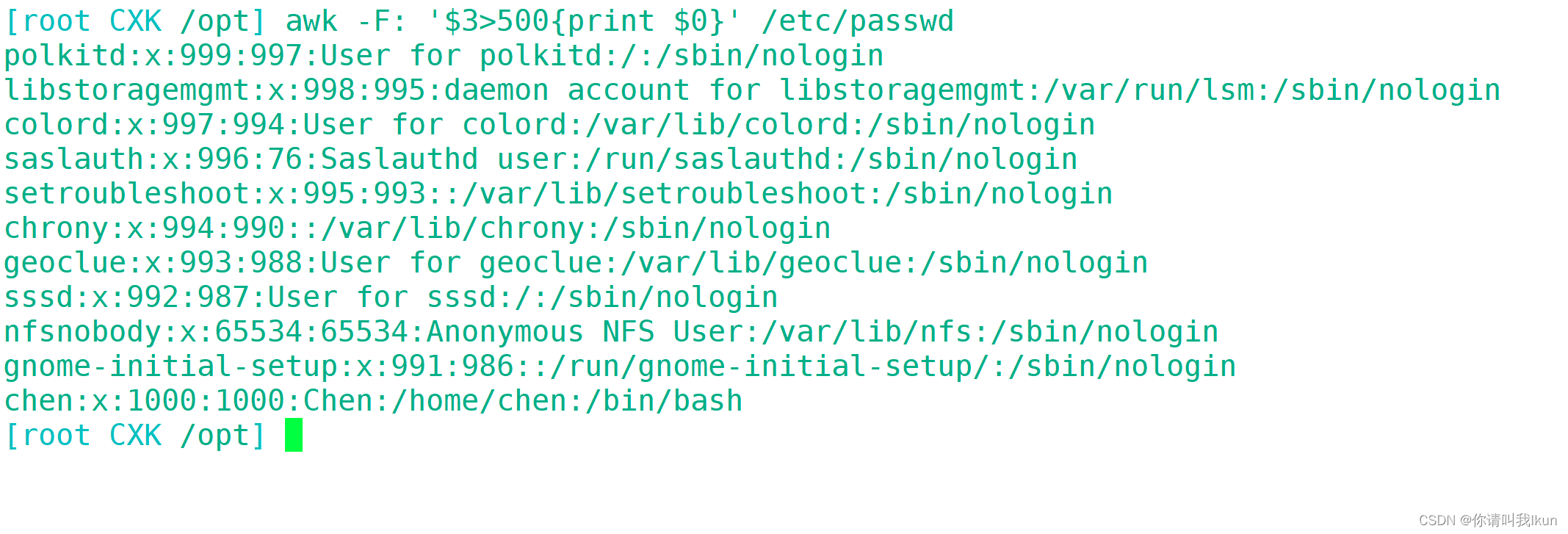
判断取反打印:
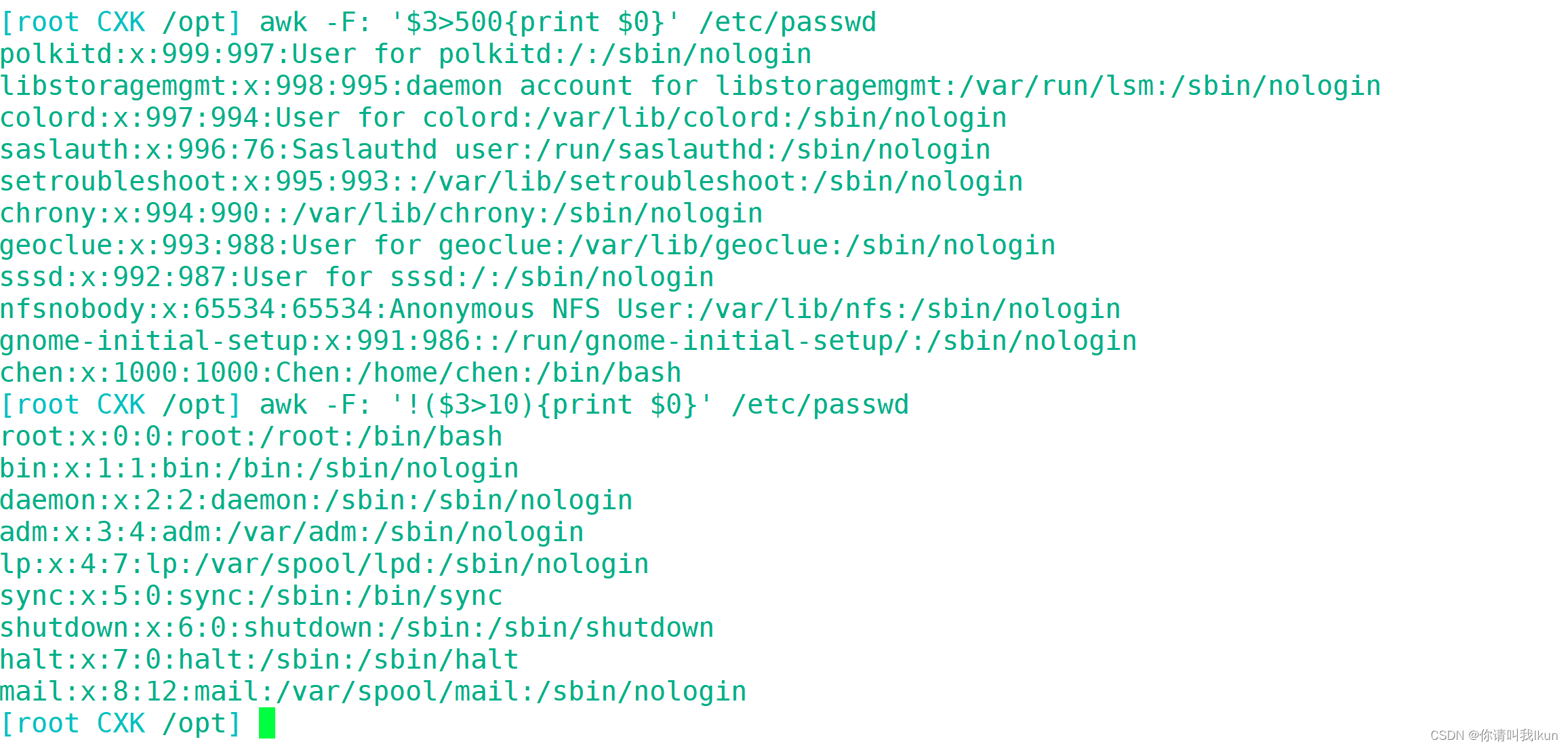

3.9 for

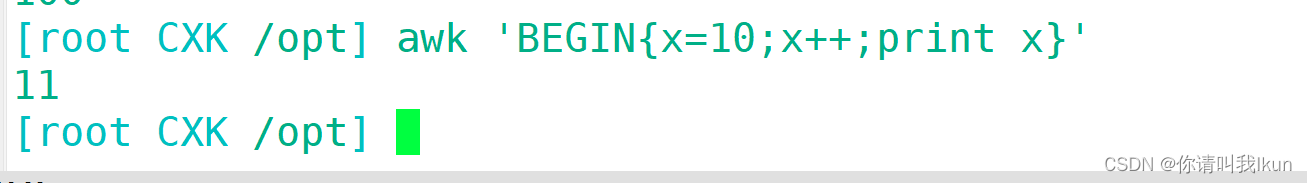

3.10 awk结合数组运用
3.10.1 awk中定义数组打印
awk 'BEGIN{a[0]=10 ; a[1]=20 ; a[2]=30;print a[1]} '
awk 'BEGIN{a[0]=10 ; a[1]=20 ; a[2]=30;print a[0]} '
awk 'BEGIN{a[0]=10 ; a[1]=20 ; a[2]=30;print a[2]} '
awk 'BEGIN{a[0]=10 ; a[1]=20 ; a[2]=30;for(i in a)print i,a[i]} '
定义数组及其元素 变量i读取数组a的下标 输出数组下标及其相对应的元素

3.10.2awk打印文件内容去重统计
去重打印数组
echo ${arry[@]}|awk -v RS=' ' '!a[$1]++'
指定分隔符为空格 筛选掉重复的元素
awk -v RS=' ' '!a[$1]++' <<< ${arry[@]}
表达式中重定向输入将右边的数组作为左边表达式子的处理对象
处理文件去重统计
awk '{a[$1]++};END{for(i in a){print i,a[i]}}' test.txt
题目:统计ssh登录失败的用户及其登录失败(日志:/var/log/secure中有记录)的次数(通常我们会认为失败三次,存在着暴力破解登录的可能,意味该主机存在隐患)解决方案:将其筛选出来就把IP加入到黑名单中 /etc/hosts.deny。
awk '/Failed password/{a[$11]++};END{for(i in a){print i,a[i]}}' /var/log/secure其他方式:
awk '/Failed password/{print $11}' /var/log/secure |sort -n
awk '/Failed password/{print $11}' /var/log/secure |sort -n |uniq -c一些题目:
awk '{print $1, $4}' log.txtcat access_log |awk '/2018:11:56:43/,/2018:11:56:44/{print $0}'awk '{print $2}' host.txt >> host.txt
cat host.txt|awk '{print $2}'|awk -F'.' '{print $1}' >> host.txt
cat host.txt|awk -F '[ .]' '{print $2}'cat /etc/fstab |awk '{print $3}'|grep -v "^#"|grep -v "^$"|tail -n +4|sort|uniq -cgrep -o -w -E 'b[[:alpha:]]+b' /etc/fstab | sort | uniq -c
提取出字符串Yd$C@M05MB%9&Bdh7dq+YVixp3vpw中的所有数字
echo "Yd$C@M05MB%9&Bdh7dq+YVixp3vpw" | grep -o -E '[0-9]+'
stat -c %a /tmp/
stat /tmp/|sed -nr '4s/.*((.*)/.*) Uid.*/1/p'
awk -F: '{print $1, $3, $7}' /etc/passwd | sort -t" " -k2 -n | tail -n 1
总结:
1. awk是一种对文件输出内容的字段(列),进行操作的工具,多数用来提取重要数据
2. awk 结合数组时可以进行数组定义,数组遍历,以及数组元素的去重统计
3.提取文件数据时,注意每行或列的分隔符,正确借用分隔符能够使提取的数据更加精确
原文地址:https://blog.csdn.net/Cnm_147258/article/details/134647825
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_20462.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!