1.YOLOv8
2.模型详解
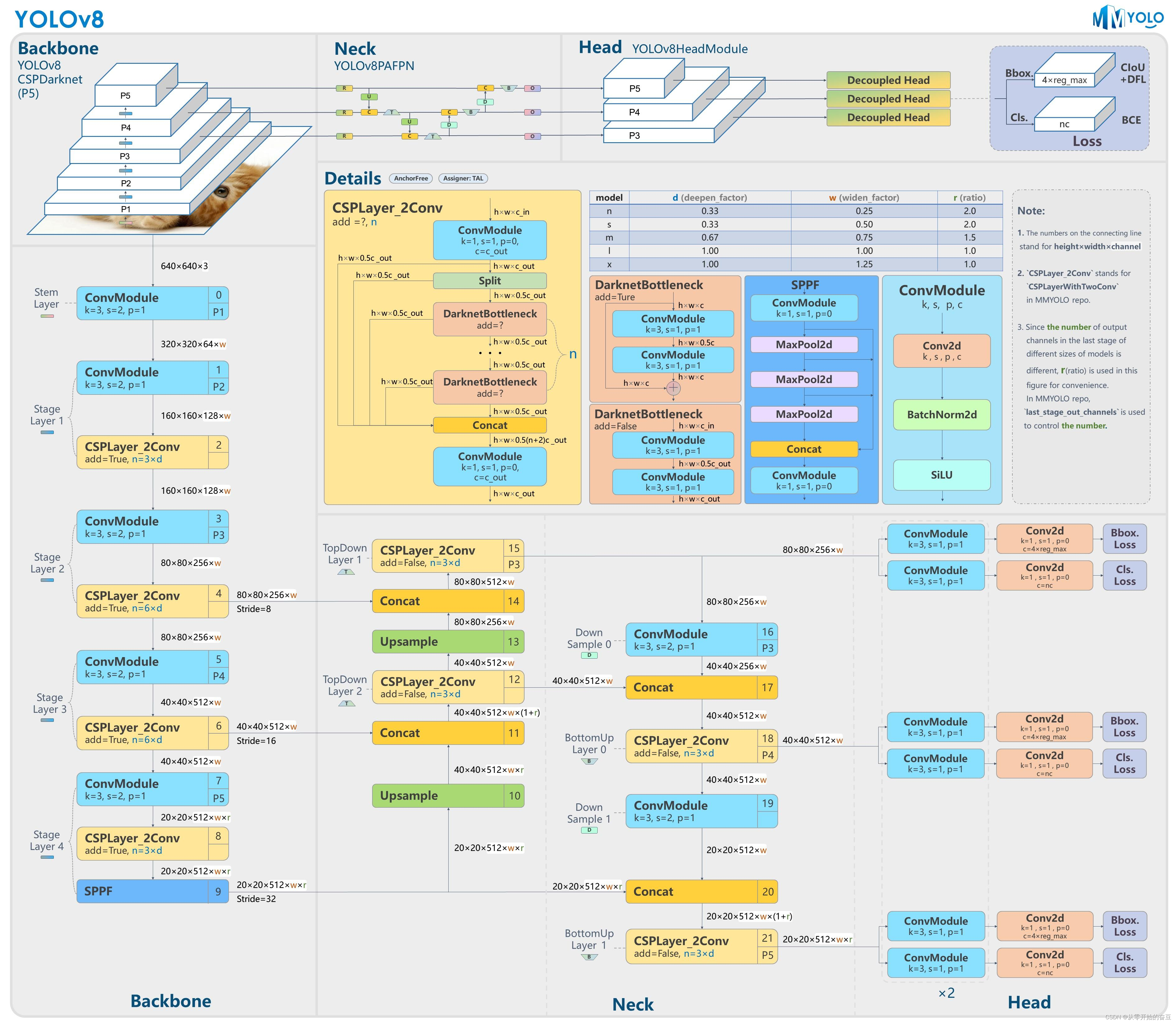
2.1模型结构设计
- 和YOLOv5对比:

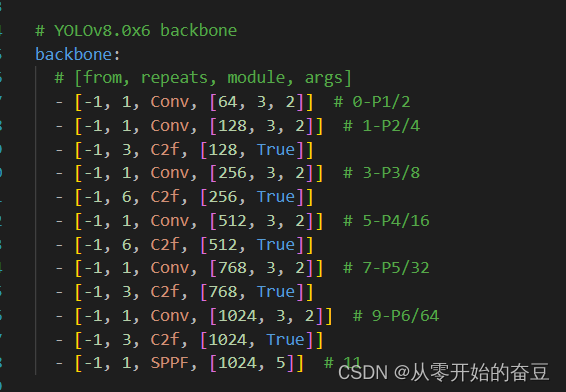
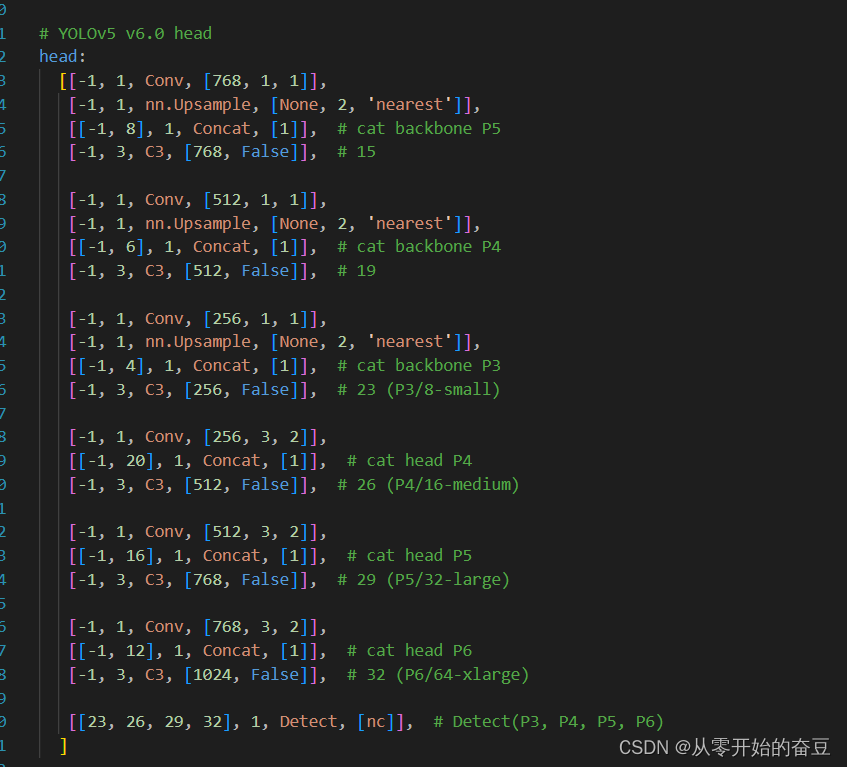

主要的模块:
1.第一个卷积层的 kernel 从 6x6 变成了 3x3
2. 所有的 C3 模块换成 C2f,可以发现多了更多的跳层连接和额外的 Split 操作
3.Backbone 中 C2f 的 block 数从 3-6-9-3 改成了 3-6-6-3
1.不再有之前的 objectness 分支,只有解耦的分类和回归分支,并且其回归分支使用了 Distribution Focal Loss 中提出的积分形式表示法。
2.2Loss 计算
2.2.1正负样本分配策略
YOLOv8 算法中直接引用了 TOOD 的 TaskAlignedAssigner
TOOD 的 TaskAlignedAssigner:https://arxiv.org/pdf/2108.07755.pdf
总结:TaskAligned使用分类得分和IoU的高阶组合来衡量Task-Alignment的程度
2.2.2分类损失(VFL)
样本不均衡,正样本极少,负样本极多,需要降低负样本对 loss 的整体贡献了,于是用了focal loss。VFL当然具备focal loss拥有的所有特性。
VFL独有的:
(1)学习 IACS 得分( localization-aware 或 IoU-aware 的 classification score)
(2)如果正样本的 gt_IoU 很高时,则对 loss 的贡献更大一些,可以让网络聚焦于那些高质量的样本上,也就是说训练高质量的正例对AP的提升比低质量的更大一些。
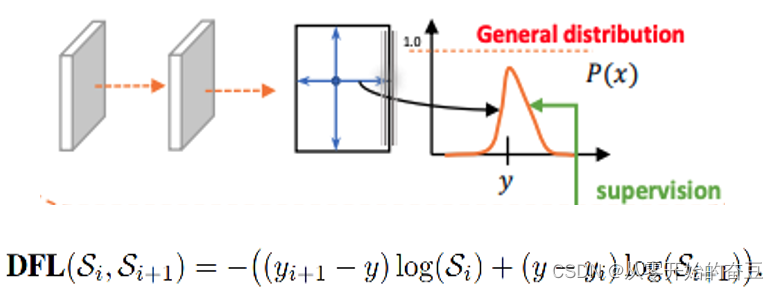
2.2.3目标识别损失1(DFL)
将框的位置建模成一个 general distribution,让网络快速的聚焦于和目标位置距离近的位置的分布。
2.2.4目标识别损失2(CIOU Loss)
2.2.5样本匹配
(1)抛弃了Anchor-Base方法,转而使用Anchor-Free方法
(2)找到了一个替代边长比例的匹配方法——TaskAligned
Anchor-Based是什么?——Anchor-Based是指的利用anchor匹配正负样本,从而缩小搜索空间,更准确、简单地进行梯度回传,训练网络。
Anchor-Based方法的劣势是什么?——但是因为下列这些劣势,我们抛弃掉了anchor 这一多余的步骤。
(1)如巡训练匹配时较高的开销
Anchor-free的优势是什么?——Anchor-free模型则摒弃或是绕开了锚的概念,用更加精简的方式来确定正负样本,同时达到甚至超越了两阶段anchor-based的模型精度,并拥有更快的速度。
为与NMS(non maximum suppression非最大抑制)搭配,训练样例的Anchor分配需要满足以下两个规则:——
基于上述两个目标,TaskAligned设计了一个新的Anchor alignment metric 来在Anchor level 衡量Task-Alignment的水平。并且,Alignment metric 被集成在了 sample 分配和 loss function里来动态的优化每个 Anchor 的预测。
3.代码实践

3.1目标检测
from ultralytics import YOLO
from PIL import Image
# 加载模型
model = YOLO('yolov8x.pt') # 加载官方模型
# 使用模型进行预测
results = model("E:BaiduNetdiskDownloadpeople.jpg") # 对图像进行预测
# 展示结果
for r in results:
im_array = r.plot(font_size=0.01,conf=False) # 绘制包含预测结果的BGR numpy数组
im = Image.fromarray(im_array[..., ::-1]) # RGB PIL图像
im.show() # 显示图像
im.save('results.jpg') # 保存图像
3.2目标分割
from ultralytics import YOLO
from PIL import Image
# 载入一个模型
model = YOLO('yolov8x-seg.pt') # 载入官方模型
# 使用模型进行预测
results = model("E:BaiduNetdiskDownloadpeople.jpg") # 对一张图像进行预测
for r in results:
im_array = r.plot(font_size=0.01,conf=False,labels=False) # 绘制包含预测结果的BGR numpy数组
im = Image.fromarray(im_array[..., ::-1]) # RGB PIL图像
im.show() # 显示图像
im.save('results.jpg') # 保存图像
3.3目标分类
from ultralytics import YOLO
from PIL import Image
# 加载模型
model = YOLO('yolov8n-cls.pt') # 加载官方模型
# 使用模型进行预测
results = model('E:BaiduNetdiskDownloadpeople.jpg') # 对图像进行预测
for r in results:
im_array = r.plot(font_size=0.01,conf=False,labels=False) # 绘制包含预测结果的BGR numpy数组
im = Image.fromarray(im_array[..., ::-1]) # RGB PIL图像
im.show() # 显示图像
im.save('results.jpg') # 保存图像
3.4目标姿态
from ultralytics import YOLO
from PIL import Image
# 加载模型
model = YOLO('yolov8n-pose.pt') # 加载官方模型
# 使用模型进行预测
results = model('E:BaiduNetdiskDownloadpeople.jpg') # 对图像进行预测
for r in results:
im_array = r.plot(font_size=0.01,conf=False,labels=False) # 绘制包含预测结果的BGR numpy数组
im = Image.fromarray(im_array[..., ::-1]) # RGB PIL图像
im.show() # 显示图像
im.save('results.jpg') # 保存图像
原文地址:https://blog.csdn.net/m0_68926749/article/details/134684530
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_20612.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!