本文介绍: 总结起来,Cluster Manager负责资源的分配和任务调度,Driver负责解析用户程序并协调任务的执行,而Executor负责实际执行任务并返回计算结果。它们三者一起协作,实现了Spark应用程序的分布式计算。是Spark提供的机器学习库,包含了常见的机器学习算法和工具,用于数据挖掘和模型训练。Cluster Manager(集群管理器)DataFrame和DataSet。弹性分布式数据集(RDD)Executor(执行器)分布式文件系统和数据源支持。Driver(驱动器)
首先先让chatgpt帮我规划学习路径,使用Markdown格式返回,并转成思维导图的形式
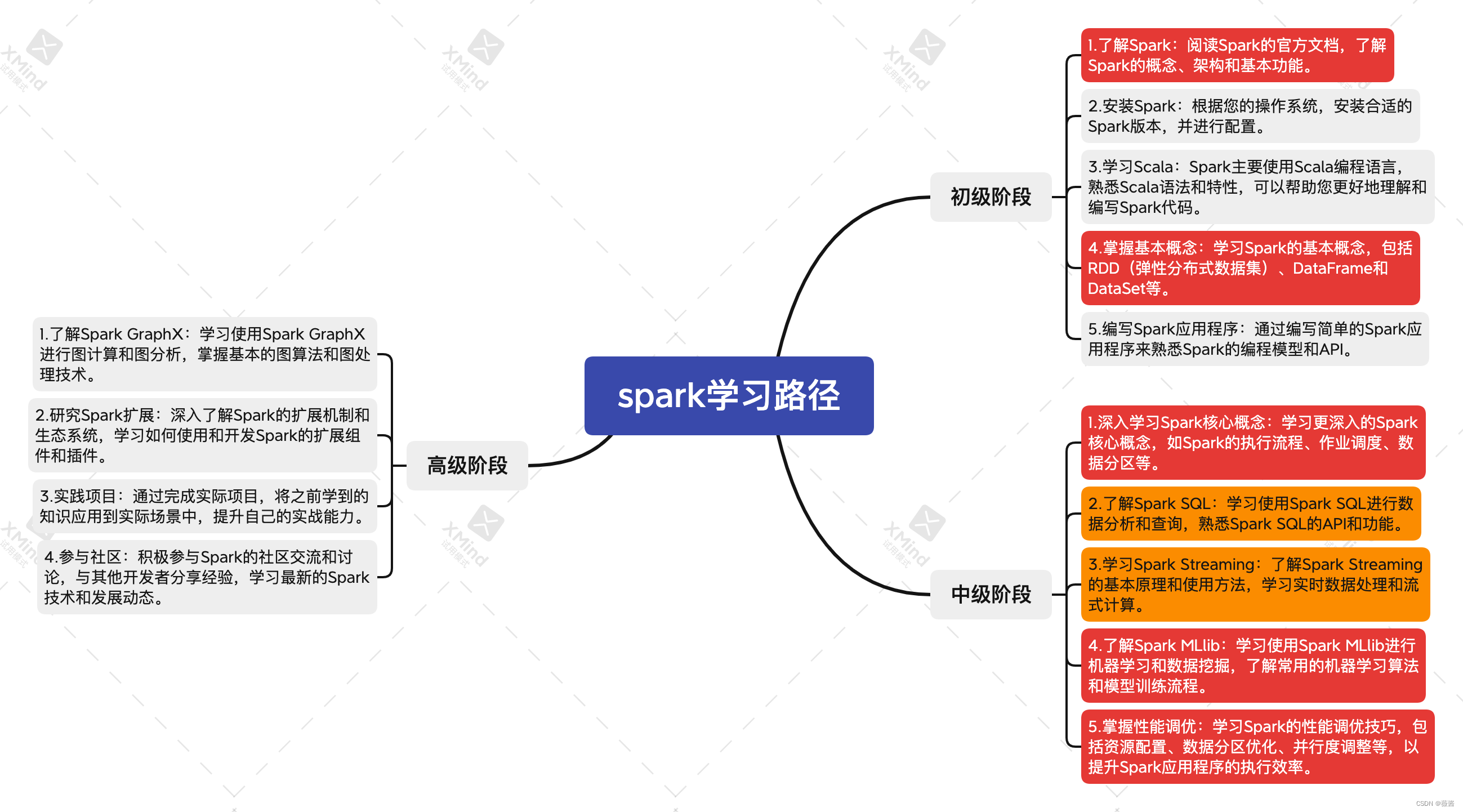
1. 了解spark
1.1 Spark的概念
1.2 Spark的架构
1.3 Spark的基本功能
2.spark中的数据抽象和操作方式
2.1.RDD(弹性分布式数据集)
2.2 DataFrame
2.3 DataSet
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






