本文介绍: 如果你在使用MySQL时只会写sql语句的,那么你应该看一下《MySQL优化的底层逻辑》。如果你只了解到sql是如何优化的,那么你应该通过本文了解一下Mysql的体系结构以及sql语句的执行流程。
前言
如果你在使用MySQL时只会写sql语句的,那么你应该看一下《MySQL优化的底层逻辑》。如果你只了解到sql是如何优化的,那么你应该通过本文了解一下Mysql的体系结构以及sql语句的执行流程。
体系结构
先来看下MySQL的体系结构,下图是在MySQL官方网站上扒下来的,所以有很高的权威性和准确性。
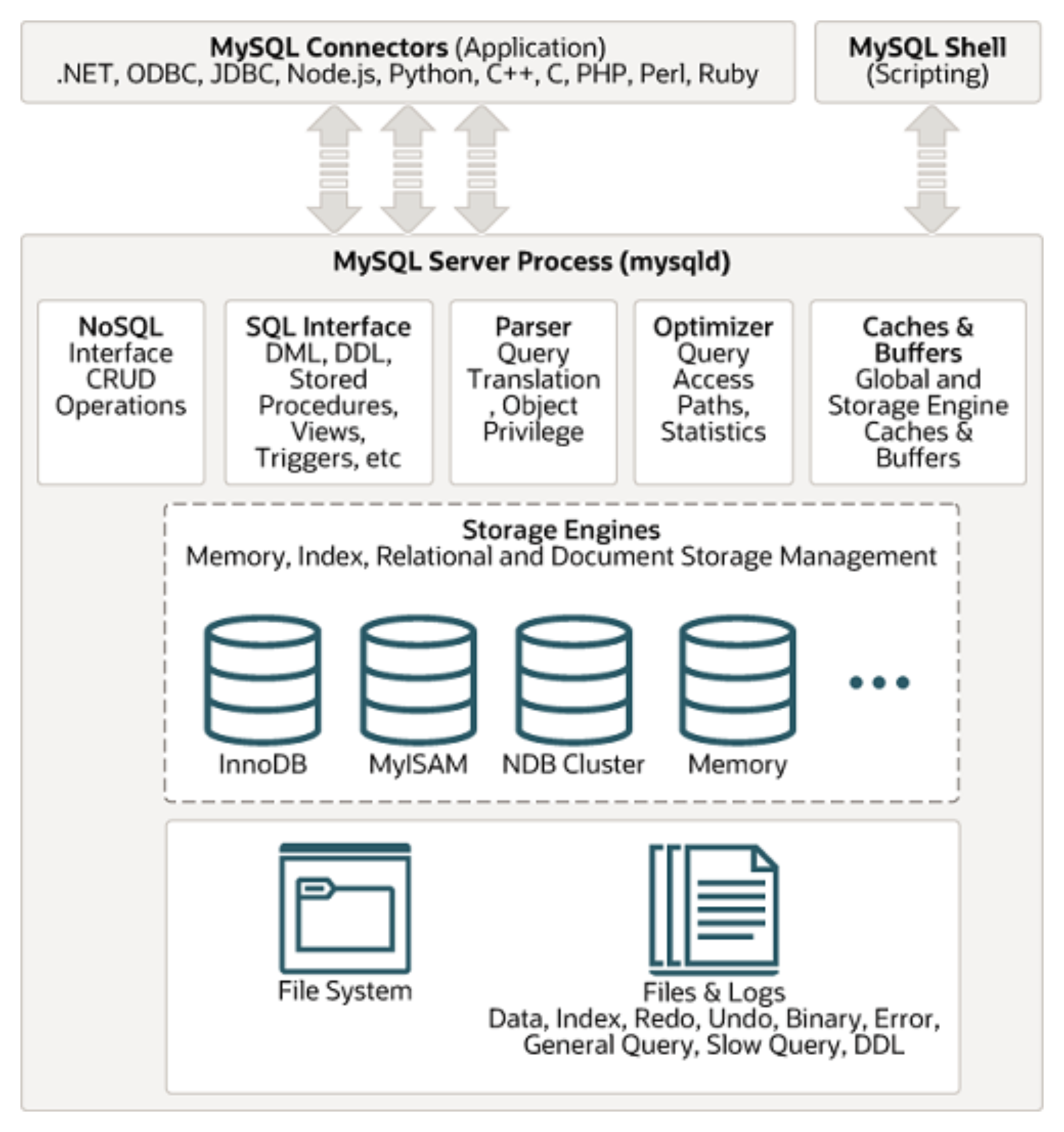
通过这张图,我们可以直观的看到MySQL的内部结构,包括连接器、缓存、解析器、优化器、存储引擎以及支持DDL、DML、存储过程、视图等功能的SQL接口。接下来,通过一条sql语句的执行来深入了解MySQL各个组件功能以及其作用。
SQL语句的执行流程
1、连接MySQL
通常我们会编写sql语句通过某个客户端来执行并且接受执行结果,比如命令行、JDBC、navicat。但是在执行前肯定需要先和MySQL服务成功建立连接,这个就是「连接器」的工作。

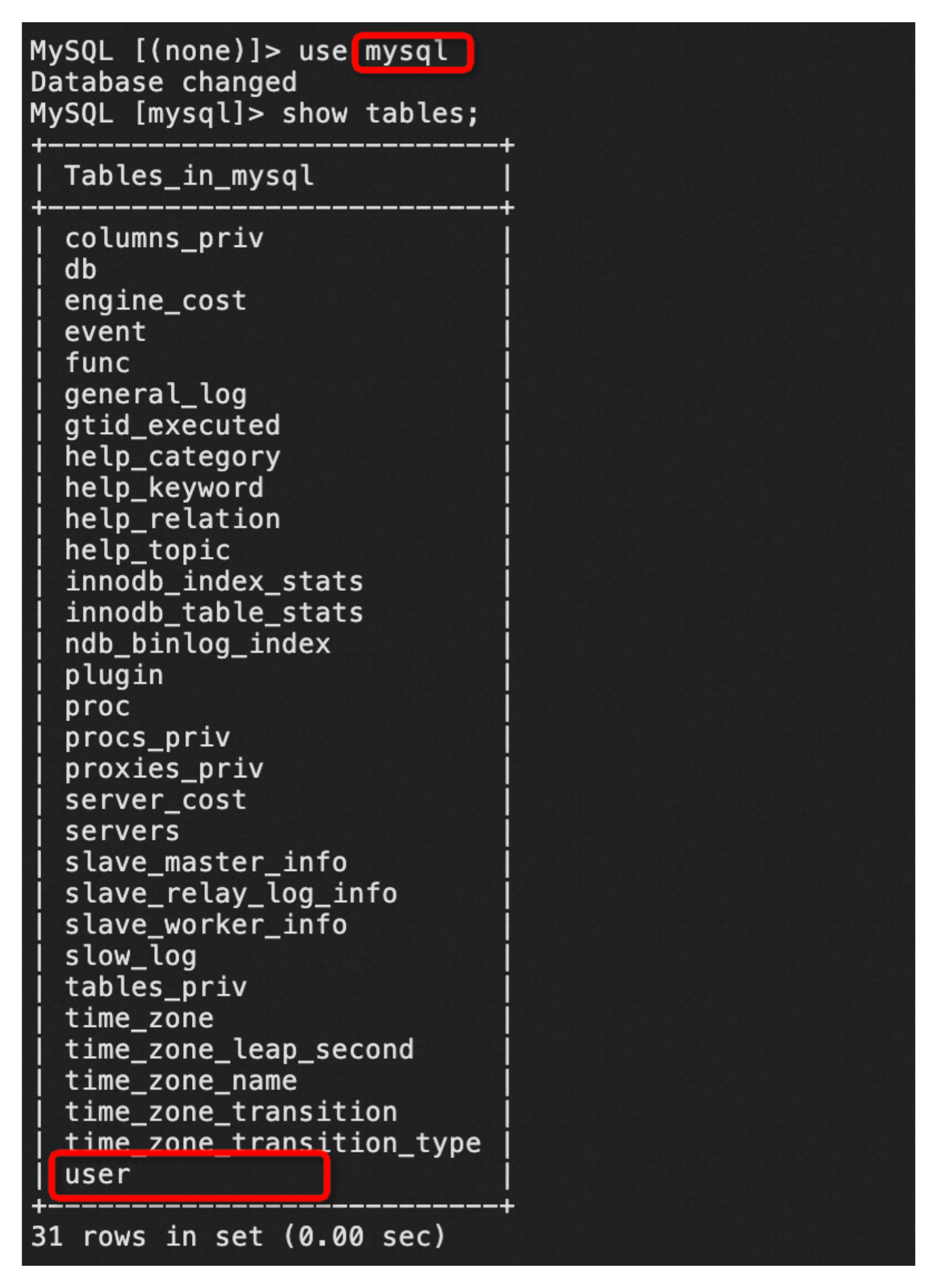
2、查询缓存
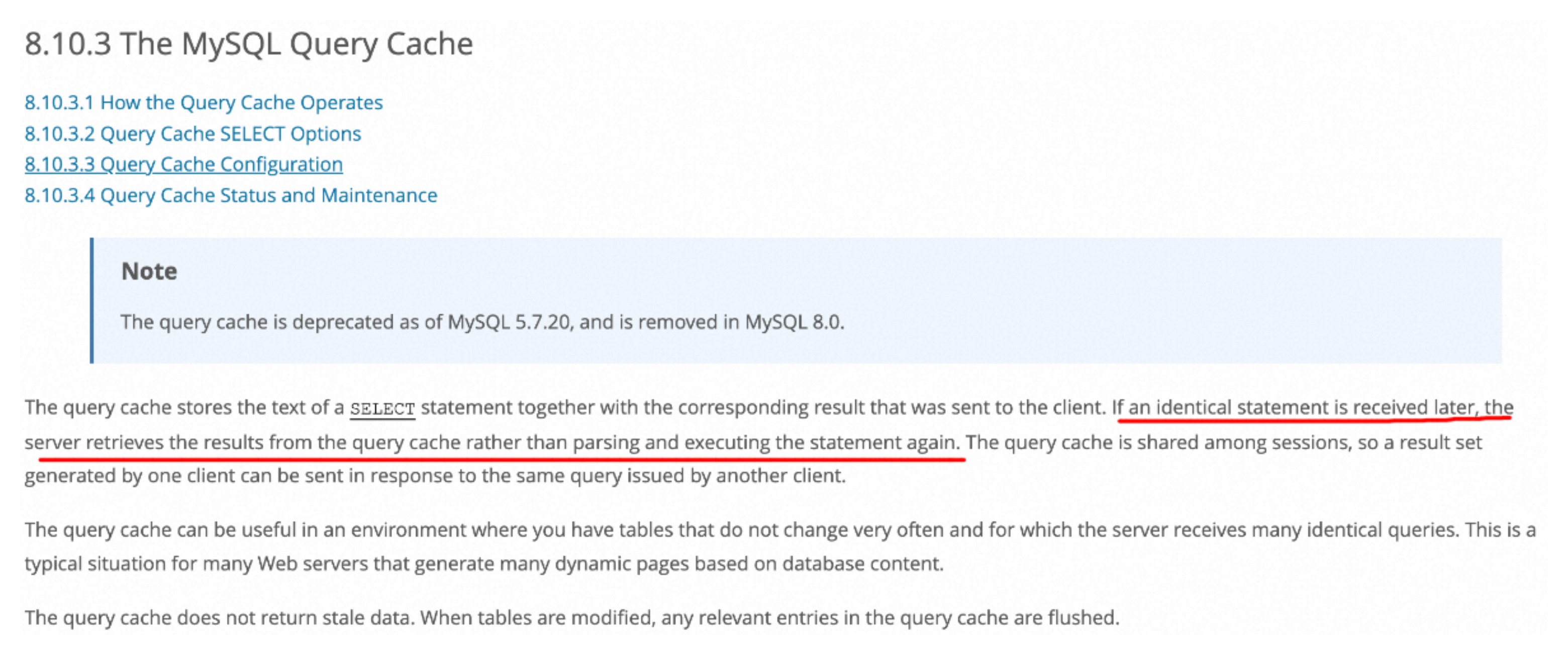
3、解析SQL语句

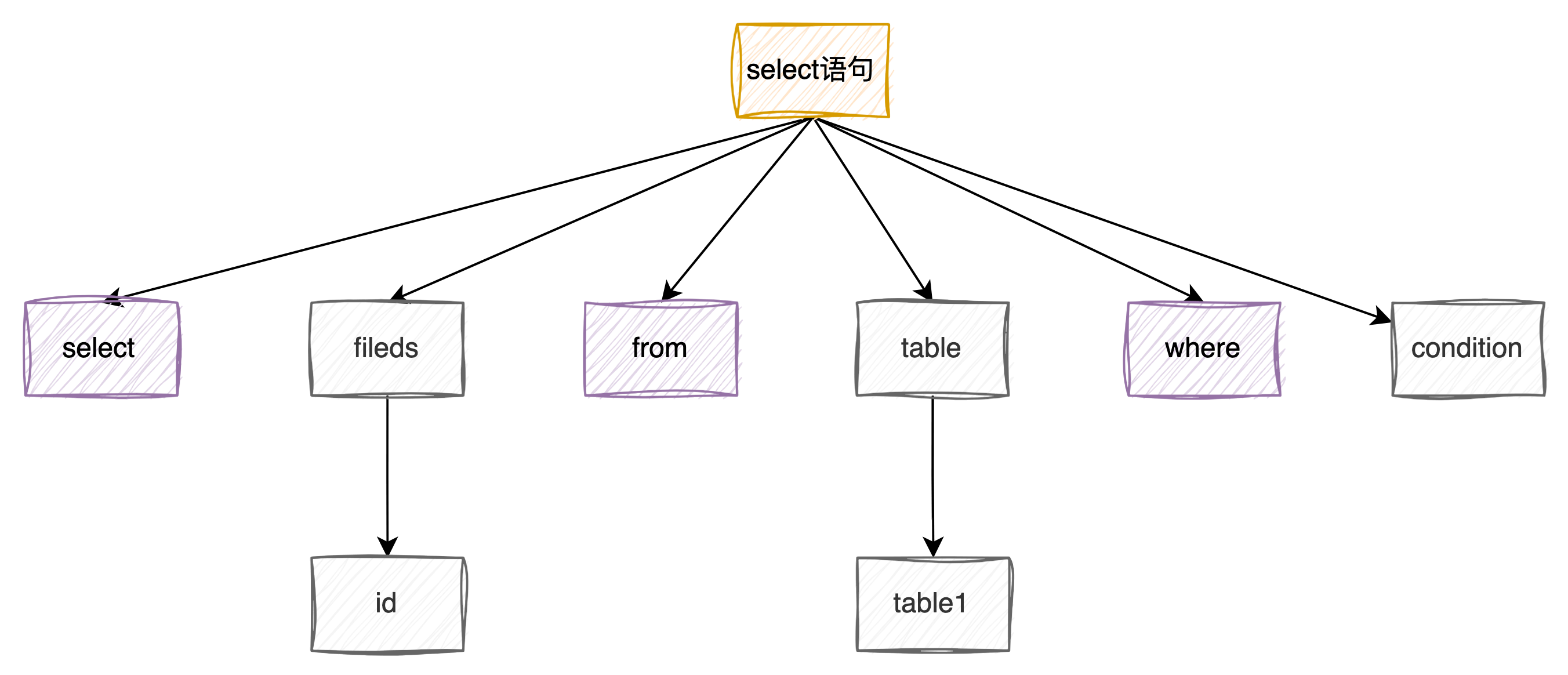
4、优化SQL语句
5、执行SQL语句
总结
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。