1. 加载 CIFAR-10 数据库
2. 可视化前 24 个训练图像

3. 通过将每幅图像中的每个像素除以 255 来调整图像比例
事实上,代价函数的形状是一个碗,但如果特征的比例非常不同,它也可能是一个拉长的碗。下图显示了梯度下降法在特征 1 和特征 2 比例相同的训练集上的应用(左图),以及在特征 1 的值远小于特征 2 的训练集上的应用(右图)。
Tips : 使用梯度下降法时,应确保所有特征的比例相似,以加快训练速度,否则收敛时间会更长。
4. 将数据集分为训练集、测试集和验证集

5. 定义模型架构
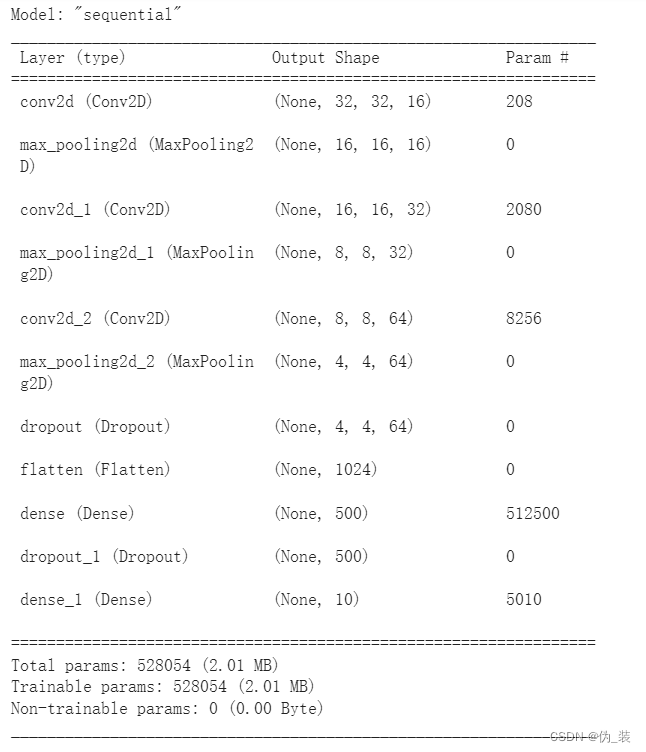
6. 编译模型
7. 训练模型

8. 加载验证精度最高的模型
9. 计算测试集的分类精度
10. 可视化一些预测

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
![[Lucene]核心类和概念介绍](http://www.7code.cn/wp-content/uploads/2023/11/ee6748cbc735e6105405f8a984d954c804b93f34bc916-Z0IqTf_fw1200.png)