Redis 节点之间的三次握手原理分析
比如多台 Redis 之间要建立集群,那么连接其中的一台 Redis 客户端,向其他 Redis 发送 meet 命令即可通知其他节点,那么发送 meet 命令给其他节点后,对方也会在内存中创建一个 ClusterNode 结构,来维护集群中的节点信息
这里的三次握手指的是 Redis 中的三次握手用来建立应用层的连接(即进行集群节点之间的连接),与 TCP 三次握手不同
那么 Redis 中集群的建立就是通过 三次握手 + Gossip 协议 来实现的
Gossip 协议也被称作是具有代表性的最终一致性的 分布式共识协议,特点就是需要同步的信息如同流言一般进行传播
Gossip 协议具体流程就是,对于需要同步的信息,从信息源节点开始,随机选择连接的 k 个节点来传播消息,每一个节点收到消息后,如果之前没有收到过,就也发送给除了之前节点的相邻的 k 个节点,直到最后整个网络中的所有节点都收到了消息,达到了最终一致性。
基于 slots 槽位机制的数据分片原理
在 Redis 分布式集群中,我们将数据分散的放在了各个 Redis 节点中,这样才可以更好利用分布式集群的优点(增加数据读写速度、分散存储数据的话,增加集群节点也就相当于扩大 Redis 内存),那么如何来组织数据的存放位置呢?
并且还存在一个问题,在集群扩容或者缩容时,也就是集群节点增加或者减少,那么就需要进行数据迁移
解释一下为什么要进行数据迁移:如果在集群中新增加一个节点,那么该节点中的数据是空的,那么肯定不合理,因此要将其他节点中的数据转移一部分数据到新的集群节点中去,缩容同理
那么对于 组织数据存放位置 以及 数据迁移 这两个问题是如何解决的呢?
我们先来了解一下数据分片的概念,数据分片通过将数据拆分为更小的块(即分片),并将其存储在多个数据库服务器上来解决海量数据的存储,那么在 Redis 中的数据分片是通过 槽位机制 来实现的,集群将所有的数据划分为 16384 个槽位,每个槽位就是一个数据分片,每个节点负责其中一部分,那么在集群扩容或缩容时,通过给新节点分配槽位来实现数据迁移
Redis 集群 slots 分配与内核数据结构
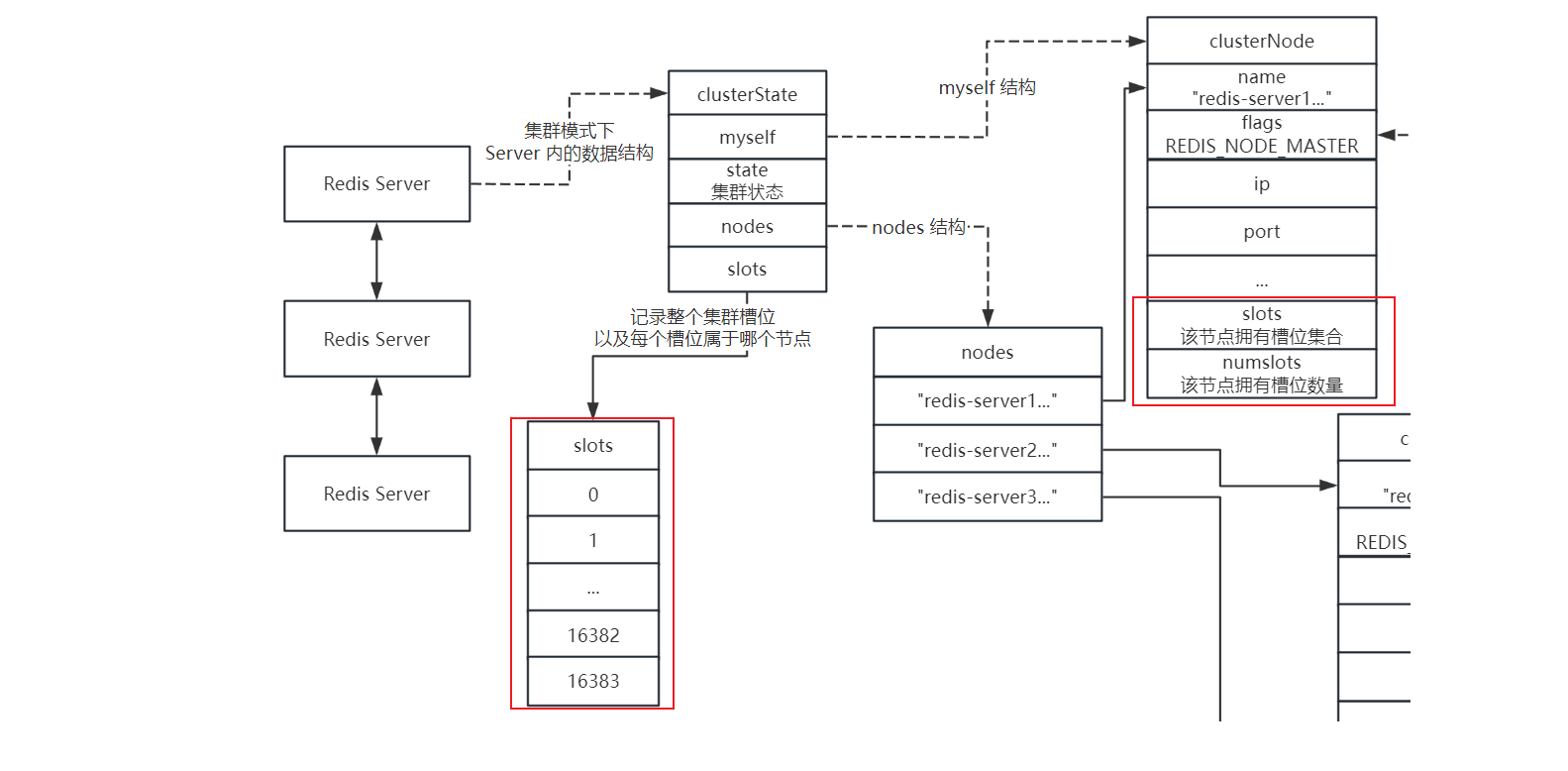
那么已经知道了 Redis 集群中通过 slots 来实现数据分片,那么集群中的每个节点不仅存储了自己拥有的槽位,还存储了整个集群槽位以及哪个槽位属于哪个节点
每个节点分配好了自己的槽位之后,会把自己的槽位信息同步给集群中的其他的所有节点
在集群中的每个节点中,以下边的数据结构来存储集群的槽位信息以及自己所拥有的槽位信息
基于 slots 槽位的命令执行流程分析
比如客户端需要插入一个 key–value,那么该键值对肯定属于一个 slot,slot 一定属于一个节点,那么我们通过客户端去插入这个键值对时,客户端会先随机找一个节点发送命令过去,节点内部会计算这个 slot 属于哪个节点
通过 CRC16 算法对 key 值进行哈希,并且对 16384 取模来获取具体的槽位,再随便找一个节点查看集群槽位分配情况,如果该节点需要存放的槽位属于当前节点,直接执行命令就可以;如果不是自己的节点,那么该节点会返回给客户端一个 MOVED(slot + 目标地址),再将请求进行重定向
基于跳跃表的 slots 和 key 关联关系
在集群模式中,所有的数据被划分到 16384 个槽位中,每一个槽位都有一部分的数据,客户端在发送命令的时候,在 server 端也会计算 key 所属的槽位,就可以把数据放在槽位里
每次操作完 key–value 数据之后,对于这个 key,会使用专门的 skipList 跳跃表数据结构,来跟 slot 做一个关联
那么 slot 和 key 之间的关联关系是通过 skipList 来实现的
skipList 的结构如下,包括 4 部分:header(头结点)、tail(尾结点)、level(跳表层级)、length(跳表长度)
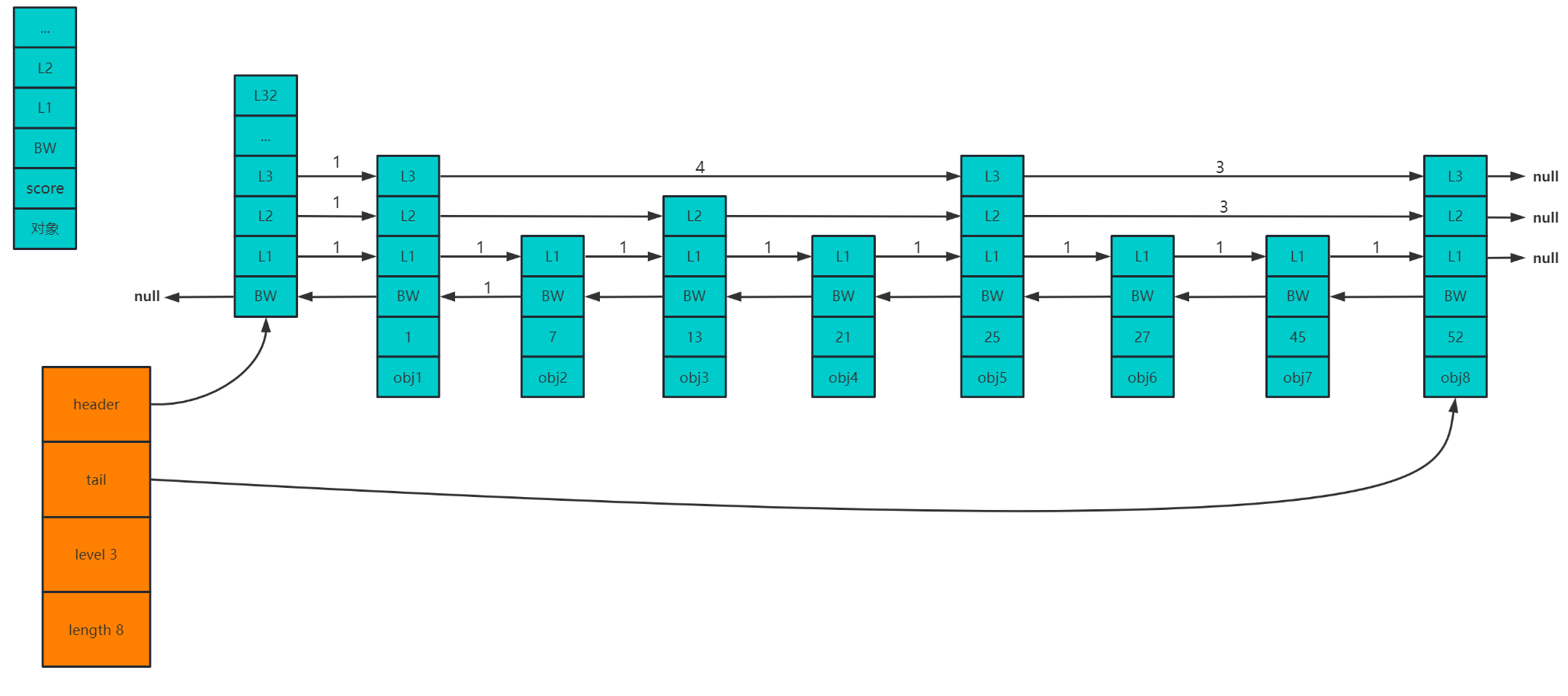
那么跳表中每个节点包含了:对象、score、BW、L1、L2…L32指针,那么在存储 key 与 slot 的对应关系时,对象字段存储的就是 key 的值,score字段存储的就是槽位的值,表示该 key 属于哪个 slot 槽位
集群扩容时的slots转移过程与ASK分析
如果在集群中加入新的节点,可以通过命令把某个节点上的一部分槽位转移到新的节点中去
那么 slots 的转移过程依赖于 clusterState 中的两个数据结构:clusterNode *migration_slots_to[16384] 和 clusterNode* importing_slots_from[16384]
importing_slots_from[] 记录了槽位从哪些节点中转移过来,如果 importing_slots_from[i] 不是 null,而是指向了一个 clusterNode,那么表示正在从这个 clusterNode 中导入槽位 i
migration_slots_to[] 记录了槽位转移到哪些节点中去,如果 migration_slots_to[i] 不是 null,而是指向了一个 clusterNode,表示正在向这个 cluster 转移该槽位
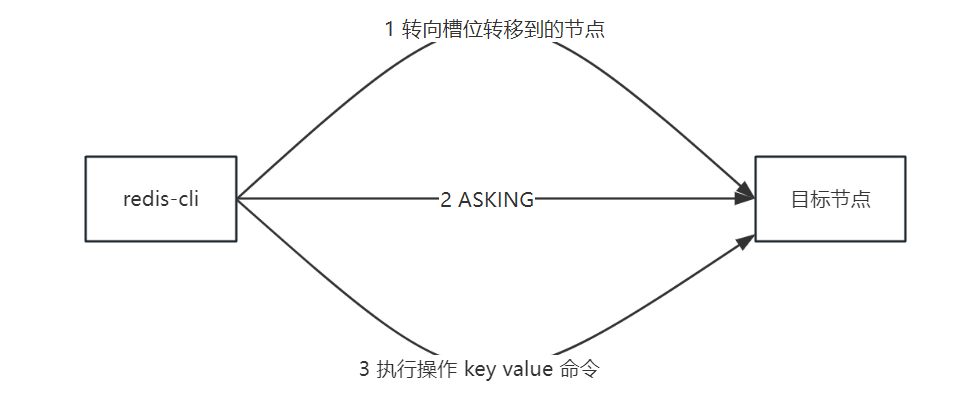
即如果在转移的过程中,对一个节点中进行 key–value 操作,计算槽位之后,发现槽位并不在当前节点(已经被迁移走了),那么就返回客户端 ASK 错误,引导客户端去操作该槽位转移到的节点,那么客户端接收到 ASK 错误后,根据错误提供的 IP 地址和端口号,再去操作目标节点,在操作目标节点之前,会先发送 ASKING 命令,因为此时正在迁移过程中,槽位还在新节点的 importing_slots_from 中,如果不发送 ASKING 命令,目标节点此时还没有完成槽位迁移,会以为槽位还不在自己这里,就返回给客户端 MOVED 命令,让客户端又去找原来的节点了,完整流程如下:
原文地址:https://blog.csdn.net/qq_45260619/article/details/134655090
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_20784.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!






