介绍
在过去几年的探索中,业界发现了一个现象,在增大模型参数量和训练数据的同时,在多数任务上,模型的表现会越来越好。因而,现有的大模型LLM,最大参数量已经超过了千亿。
然而,增大模型参数规模,对于一些具有挑战的任务(例如算术、常识推理和符号推理)的效果,并没有太大提升。对于算术类推理任务,我们期望模型生成自然语言逻辑依据来指导并生成最终答案,但是获得逻辑依据是比较复杂昂贵的(标注成本层面)。
自从发现了大模型ICL(In-Context Learning)的能力后,这个问题有个新的解决思路:对某个任务Task,能否为大模型提供一些上下文in–context example作为Prompt,以此来提升模型的推理能力?实验表明,在复杂推理任务上加入ICL带来的增益不明显。因此,便衍生出了CoT的技术。
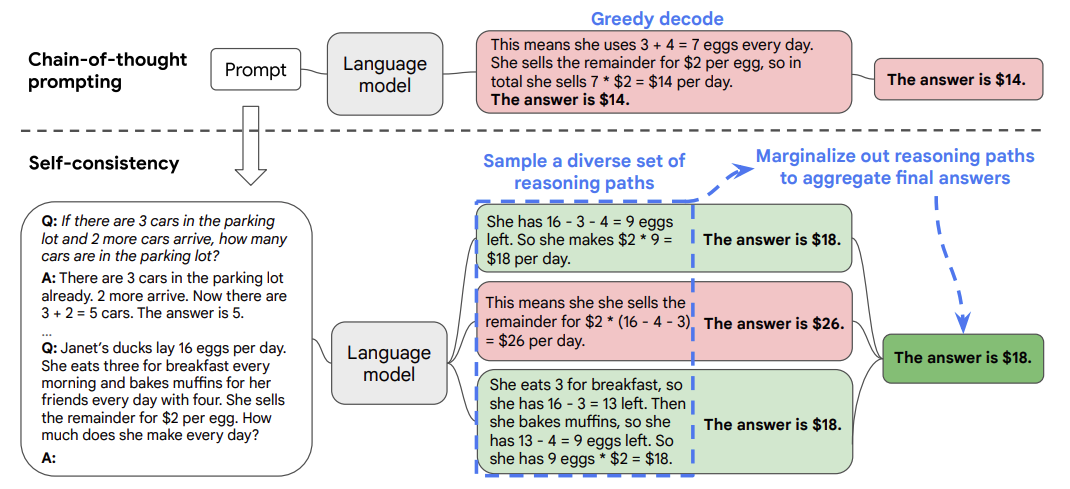
Chain–of-Thought(CoT)是一种改进的Prompt技术,目的在于提升大模型LLM在复杂推理任务上的表现,如算术推理(arithmetic reasoning)、常识推理(commonsense reasoning)、符号推理(symbolic reasoning)。思维链(CoT)便是一种用于设计 prompt 的方法,即 prompt 中除了有任务的输入和输出外,还包含推理的中间步骤(中间思维)。研究表明,CoT 能极大地提升 LLM 的能力,使之无需任何模型更新便能解决一些难题。
思路
ICL的思路是在新测试样本中加入示例(demonstration)来重构prompt。
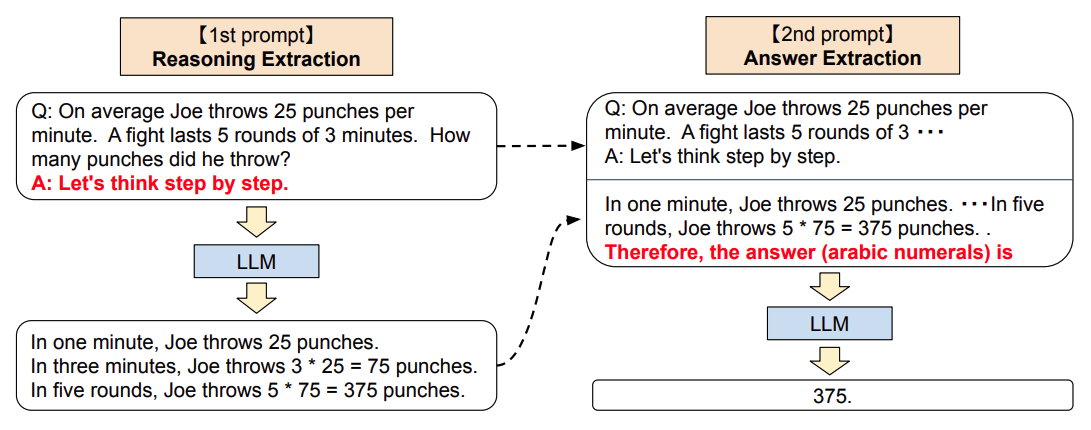
与ICL(In-Context Learning)有所不同,CoT对每个demonstration,会使用中间推理过程(intermediate reasoning steps)来重新构造demonstration,使模型在对新样本预测时,先生成中间推理的思维链,再生成结果,目的是提升LLM在新样本中的表现。
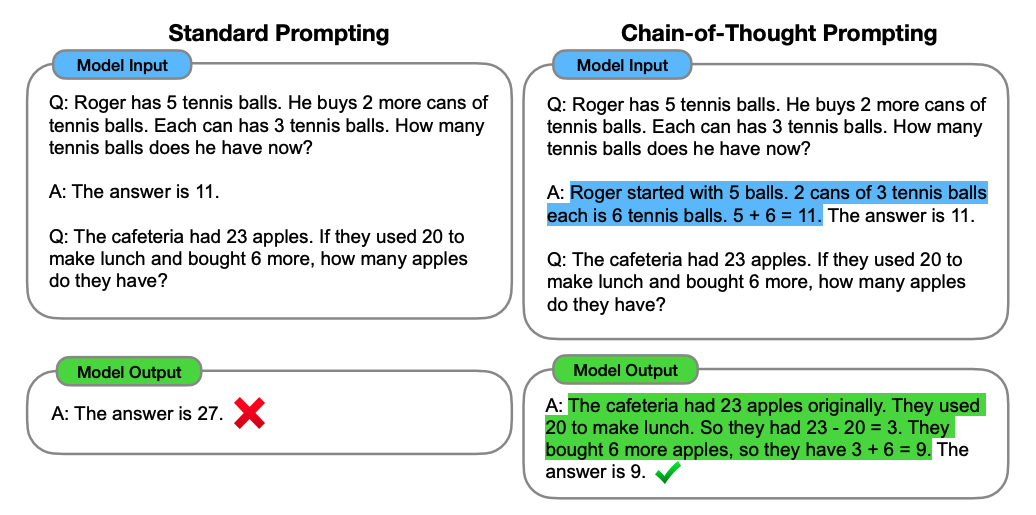
CoT方法
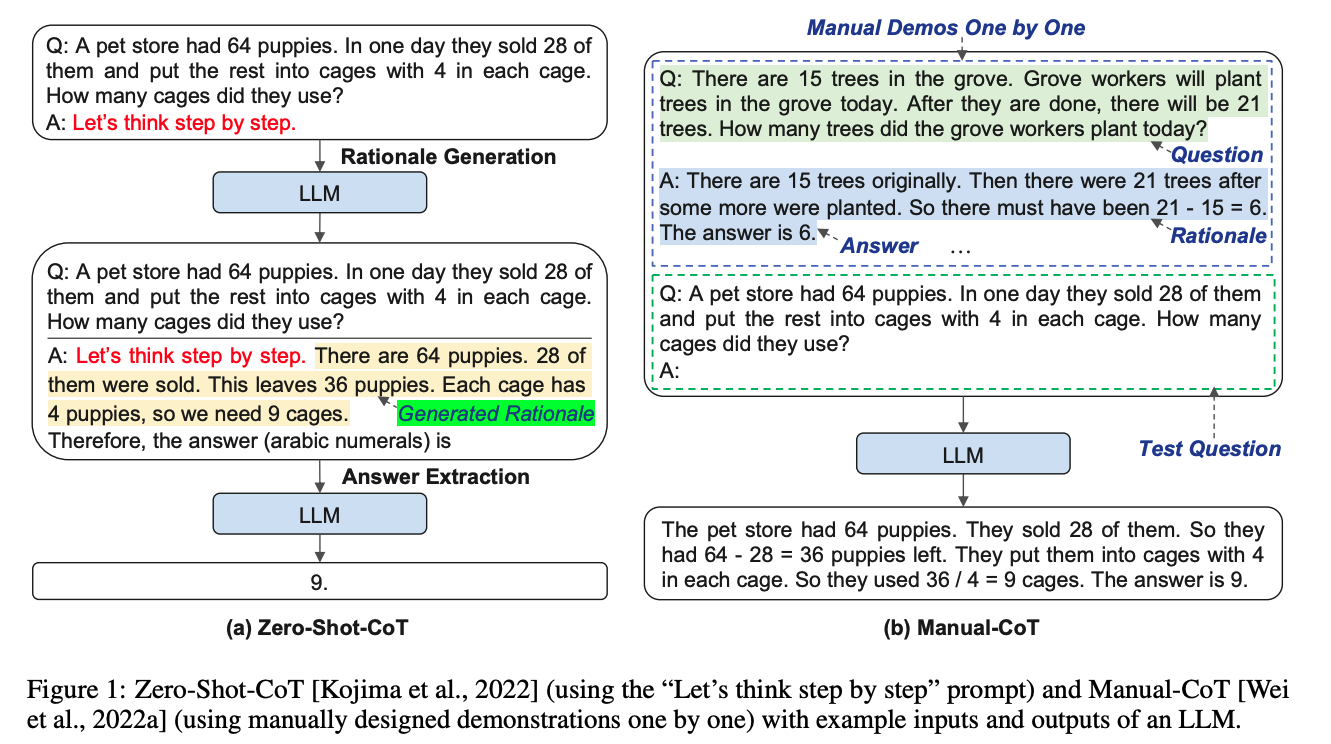
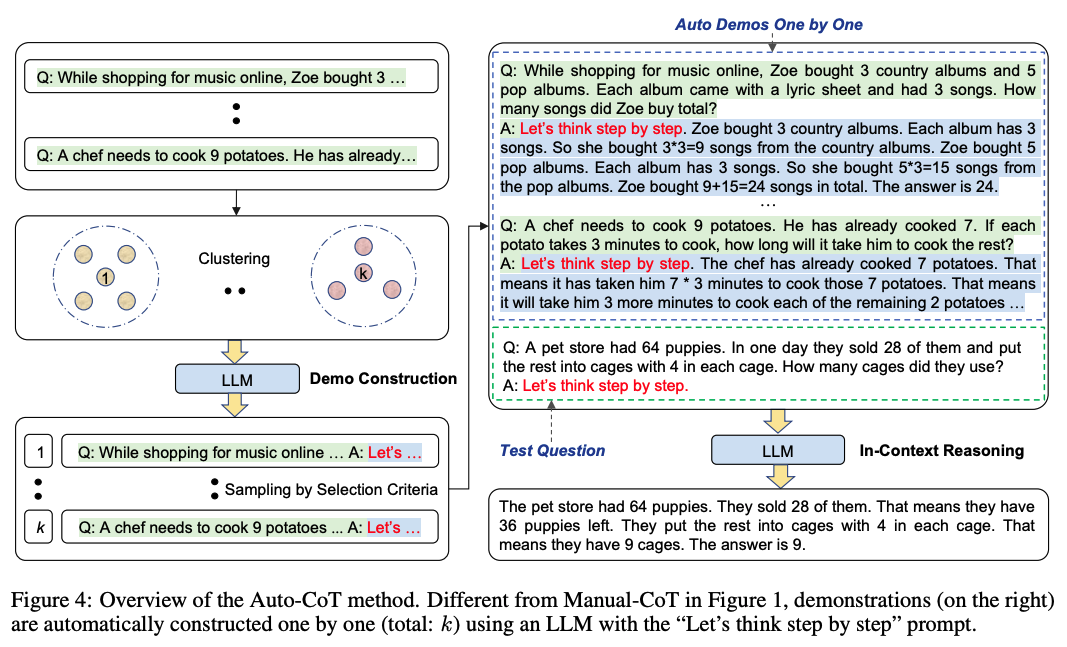
一般来说CoT会分为两种:基于人工示例标注的Few-shot CoT和无人工示例标注的Zero–shot CoT。下面将逐一介绍。