本文介绍: 连续属性的离散化就是将连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数值代表落在每个子区间中的属性值。离散化有很多种方法。这里使用一种最简单的方式去操作:原始的身高数据:165,174,160,180,159,163,192,184。假设按照身高分几个区间段:(150,165],(165,180],(180,195]。分组与聚合通常是分析数据的一种方式,通常与一些统计函数一起使用,查看数据的分组情况。一步一个脚印,lyy加油!
学习Pandas 一(Pandas介绍、DataFrame结构、Series结构、Pandas基本数据操作、DataFrame运算、Pandas画图、文件读取与存储)
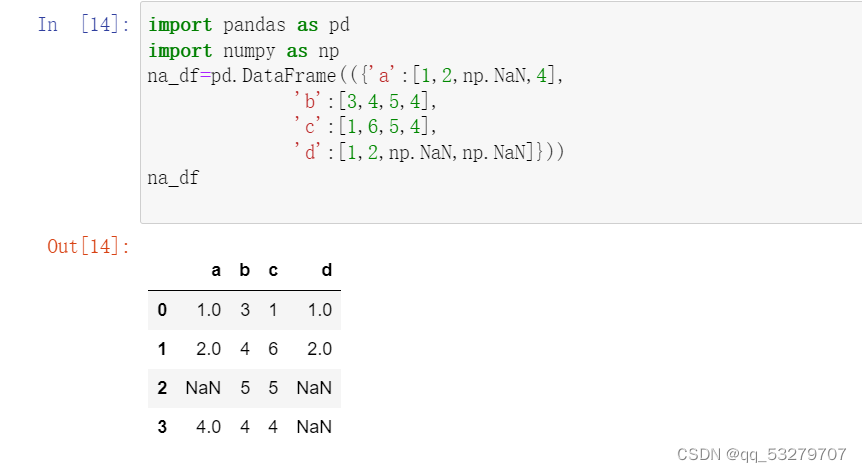
六、高级处理-缺失值处理
如何进行缺失值处理:
两种思路:
1、删除含有缺失值NaN的样本
2、替换/插补
判断数据是否存在NaN:
pd.isnull(df)
pd.notnull(df)
若存在缺失值:
1、删除存在缺失值的:dropna(axis=‘rows’, inplace=Ture/False)
inplace=True就地删除,False不会修改原数据,返回新的经过删除过缺失值的df,需要接受返回值
6.1 检查是否有缺失值
6.2 缺失值处理
6.3 不是缺失值NaN,有默认标记的
七、高级处理-数据离散化
7.1 什么是数据的离散化
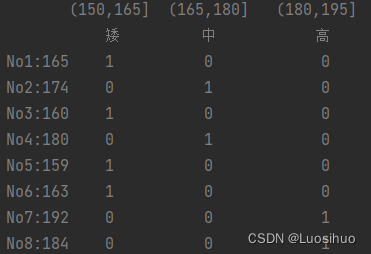
7.2 为什么要离散化
7.3 如何实现数据的离散化
八、高级处理-合并
8.1 pc.concat实现合并,按方向进行合并
8.2 pd.merge实现合并 按索引进行合并
九、高级处理-交叉表与透视表
9.1 交叉表与透视表有什么作用
9.2 使用crosstab(交叉表)实现
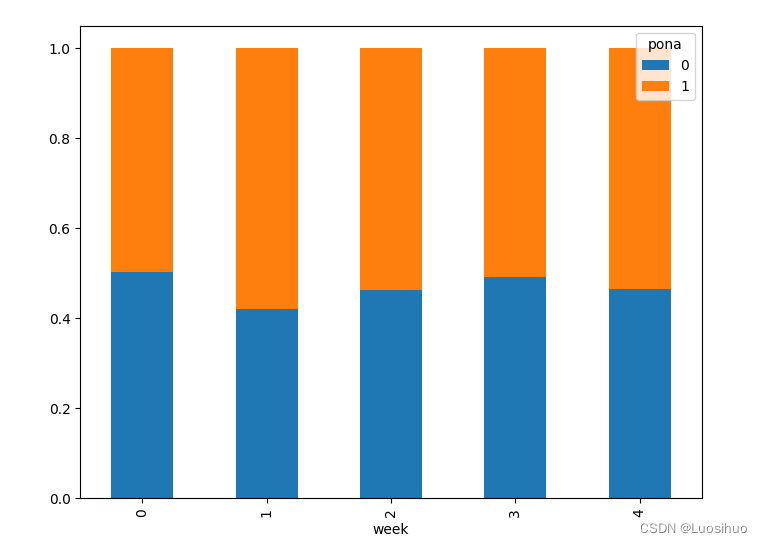
9.3 使用pivot_table(透视表)实现
十、高级处理-分组与聚合
10.1 什么是分组与聚合
10.2 分组与聚合API
10.3 星巴克零售店铺数据案例
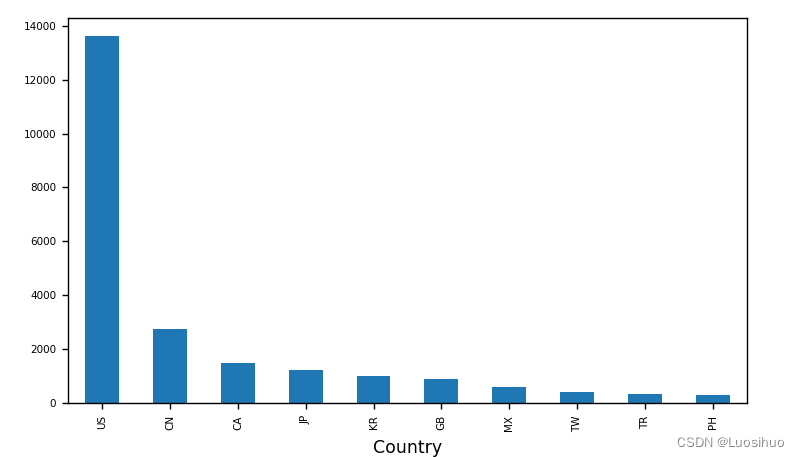
十一、综合案例
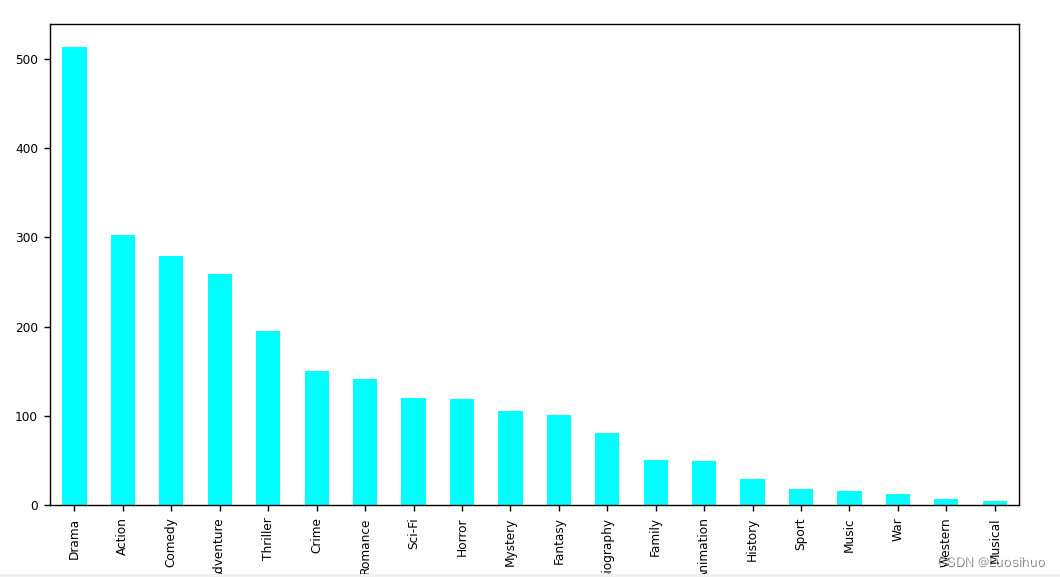
总结
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。