引言
本文的教程仅为个人的操作经验所写,每个人下载的版本不一样,所以会出现不同的情况异常等,如有问题可询问博主或百度查找解决方法。
本机的配置环境如下:
hadoop(3.3.1)
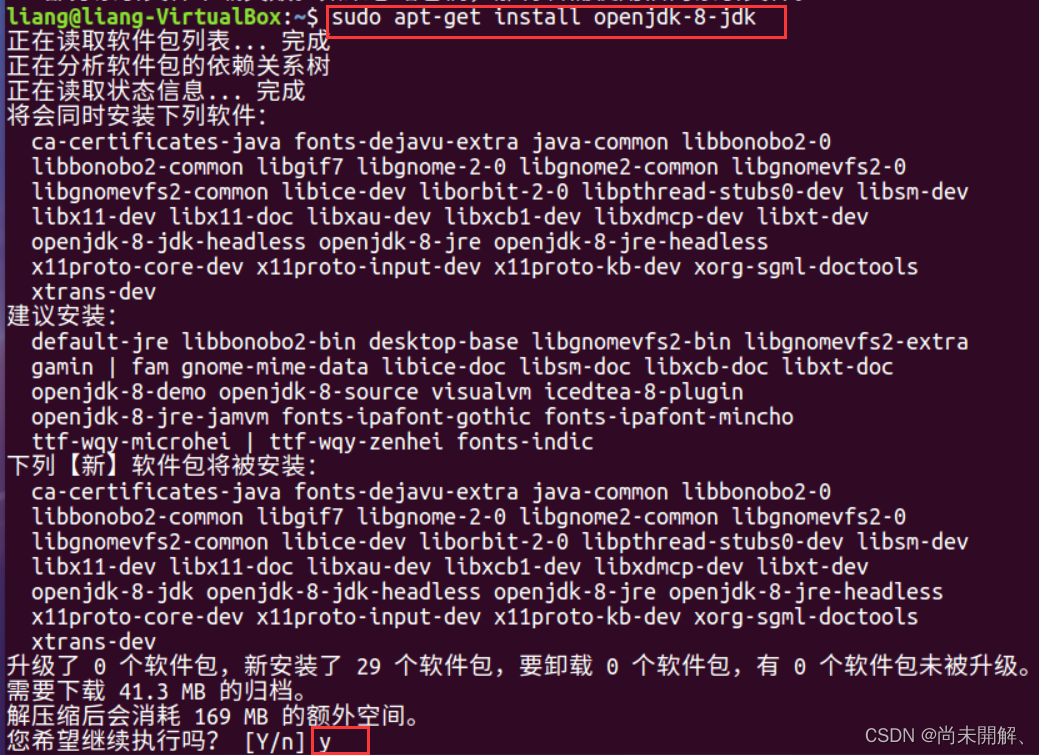
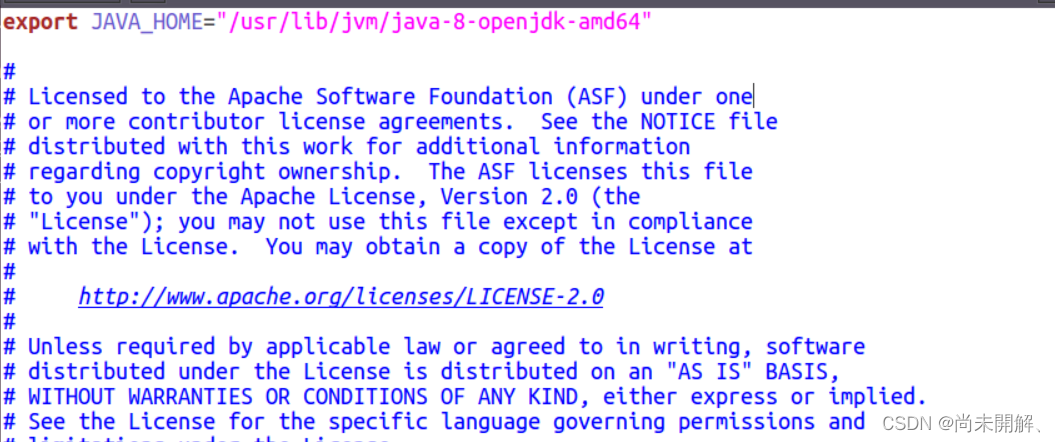
1、安装jdk
在Ubuntu中用压缩包安装jdk较为麻烦,需要配置系统环境变量和配置文件,一步出错可能无法使用。所以本文在Ubuntu中使用命令安装jdk。其他方法安装jdk也可。


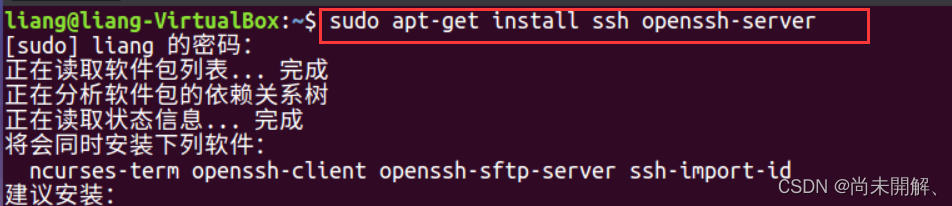
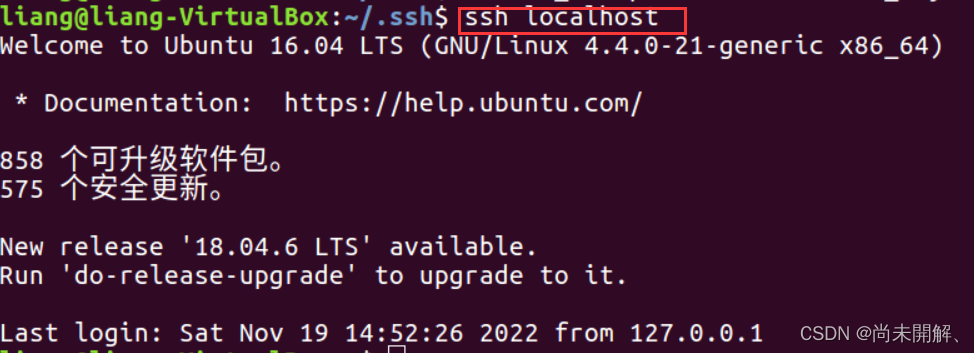
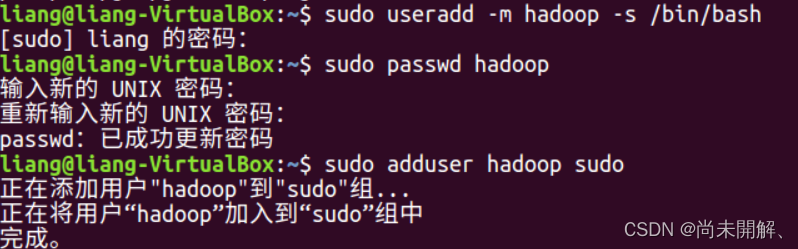
2、安装ssh免密码登录
3、安装hadoop


4、运行hadoop




5、配置yarn


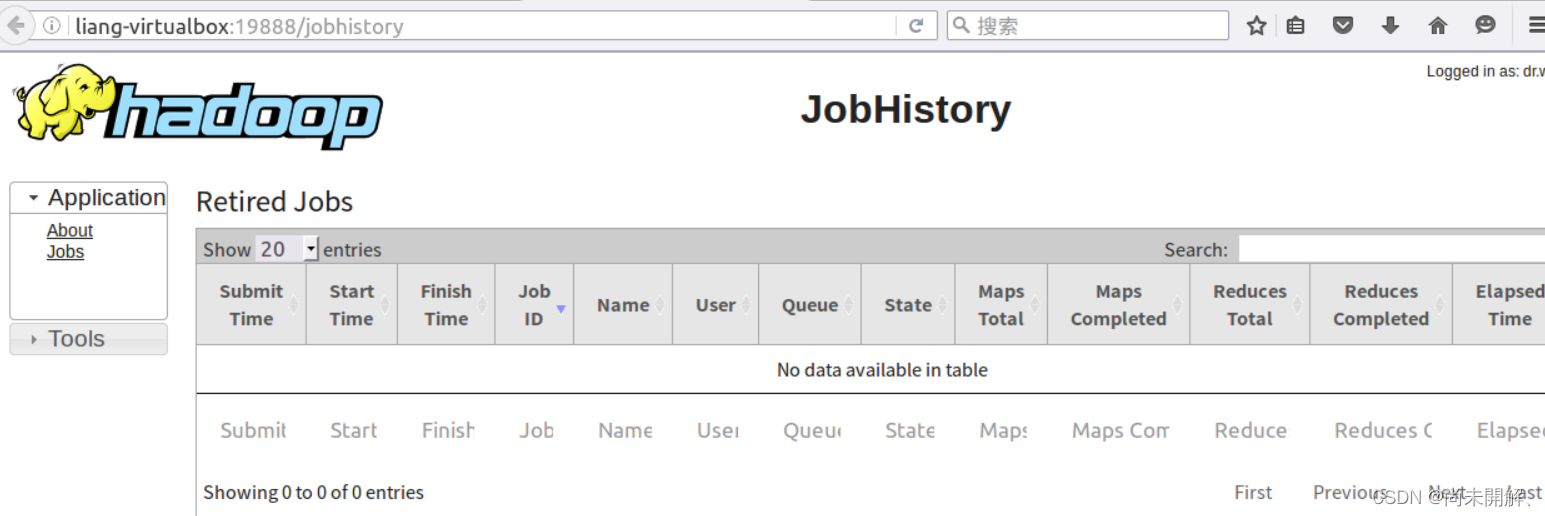
6、配置JobHistory(可不配)

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。