这篇文章是复习Django学习了那些内容,做一个总结,查缺补漏
一、Web应用
web应用程序是一种可以通过web访问的应用程序,用户只需有浏览器即可,不需要再安装其他软件
比如:淘宝网、京东网、博客园等都是基于web应用的程序
Web应用程序的优点
Web应用程序的缺点
严重依赖服务端正常运行,一旦服务端出现问题,客户端就会收到影响
应用程序有两种模式C/S、B/S
C/S是客户端/服务端程序,也就是说这类程序一般独立运行。
而B/S就是浏览器端/服务端应用程序,这类应用程序一般借助IE等浏览器来运行。web应用程序一般是B/S模式。
在MySQL的情境下,客户端和服务器可以存在于同一台计算机上,也可以分布在不同的计算机上,通过网络进行通信。这种C/S架构提供了更好的灵活性和可伸缩性,使得多个客户端可以同时连接到同一个数据库服务器,实现数据的共享和集中管理。
总体而言,MySQL作为关系型数据库管理系统,通过C/S架构提供了一种有效的方式来处理数据库操作,使得应用程序和数据库之间的交互更为灵活和高效。
C/S 客户端/服务端
我们之前学习的MySQL也是C/S架构,将客户端和服务端装在同一台机器上。
局域网连接其他电脑的MySQL数据库
1.先用其他电脑再cmd命令行ping本机ip
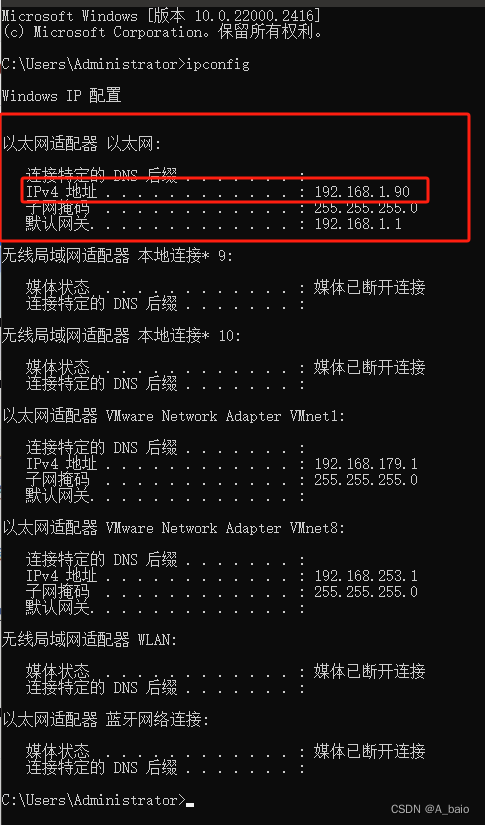
若是ping不通的话就需要关闭防火墙,打开控制面板—–防火墙—-关闭所有防火墙
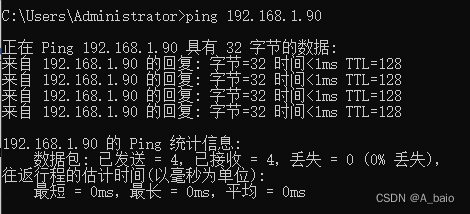
2.开放MySQL的访问
打开MySQL 命令行链接mysql:mysql –hlocalhost -uroot –p
输入密码:Enter password: ******(自己的密码)
打开 mysql 数据库:use mysql(因为MySQL的权限存在这个里面)
将user=‘root’的用户访问权限为all:update user set host=’%’ where user=‘root’;(把host改为%,相当于任何用户都可以连接。)
让赋予的权限立即生效:flush privileges;
C:Usersut>mysql -hlocalhost -uroot -p
Enter password: ******
Welcome to the MySQL monitor. Commands end with ; or g.
Your MySQL connection id is 11
Server version: 8.0.15 MySQL Community Server - GPL
Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or 'h' for help. Type 'c' to clear the current input statement.
mysql> use mysql
Database changed
mysql> update user set host='%' where host= 'localhost';
Query OK, 4 rows affected (0.01 sec)
Rows matched: 4 Changed: 4 Warnings: 0
mysql> flush privileges ;
Query OK, 0 rows affected (0.01 sec)
不出意外的话重启一下自己的mysql服务,同事电脑就能连上自己的库了,如果不行试下下面的命令
GRANT ALL PRIVILEGES ON *.* TO root @'%' IDENTIFIED BY "mypassword";
FLUSH PRIVILEGES;
% 表示所有的IP都能访问,也可以修改为专属的
mypassword 为连接密码 需要修改为你自己的
B/S 浏览器/服务端
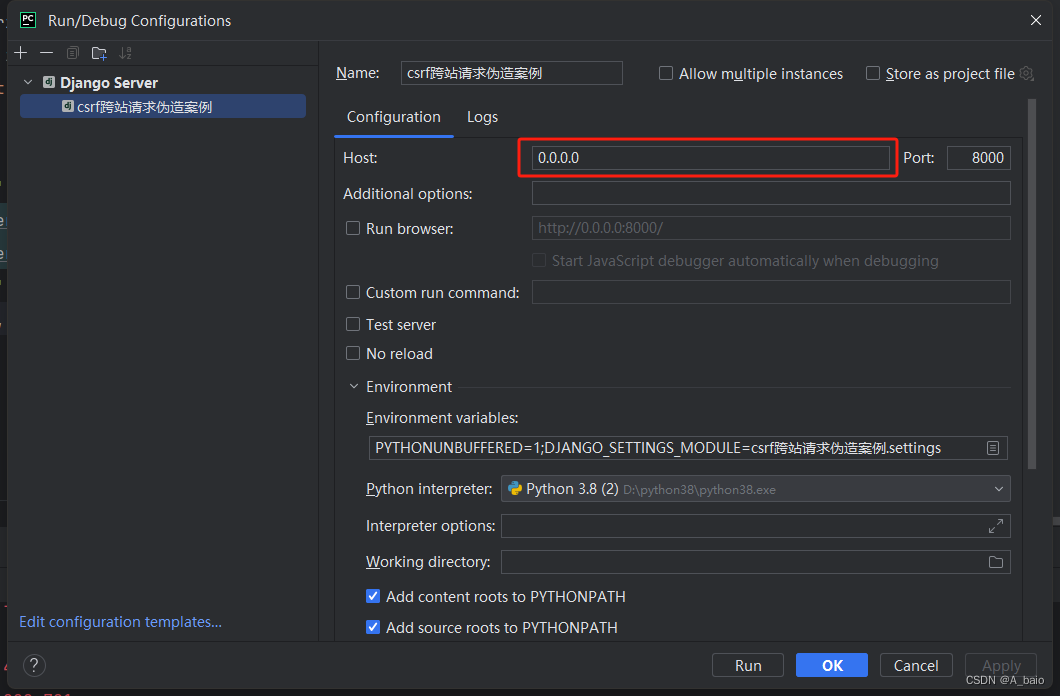
如何让同局域网别的电脑访问你写的网页:
首先搭建好你的网页,自己访问无问题,同上关闭你的防火墙。
2.将setting.py下的ALLOWED_HOSTS=[‘*’]接受所有的
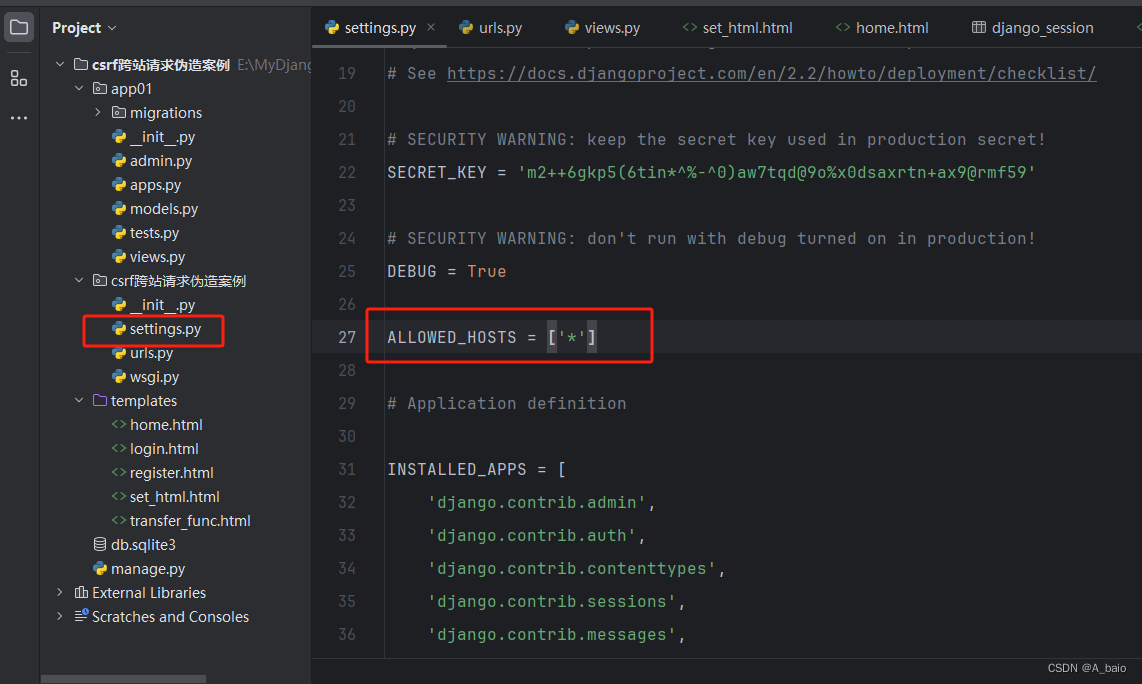
做完以上操作就可以让别人访问你的页面
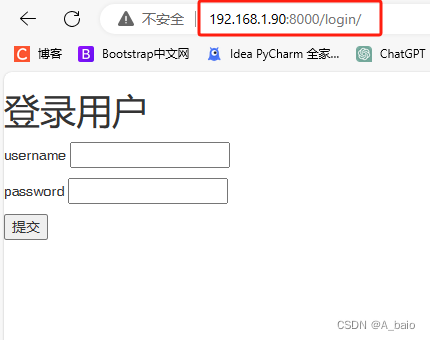
输入IP地址加上端口号,再加上需要访问的页面
基于socket编写一个Web应用
import socket, time
def run():
server = socket.socket()
server.bind(('127.0.0.1', 8000))
server.listen(3)
while True:
sock, addr = server.accept()
server_data = sock.recv(1024)
now = time.strftime('%Y-%m-%d %X', time.localtime())
with open('index.html', 'r', encoding='utf-8') as f:
data = f.read()
data = data.replace('sb', now)
sock.send(('HTTP/1.1 200 ok rnrn%s' % data).encode('utf-8'))
if __name__ == '__main__':
run()
二、Http协议
1.http协议是什么
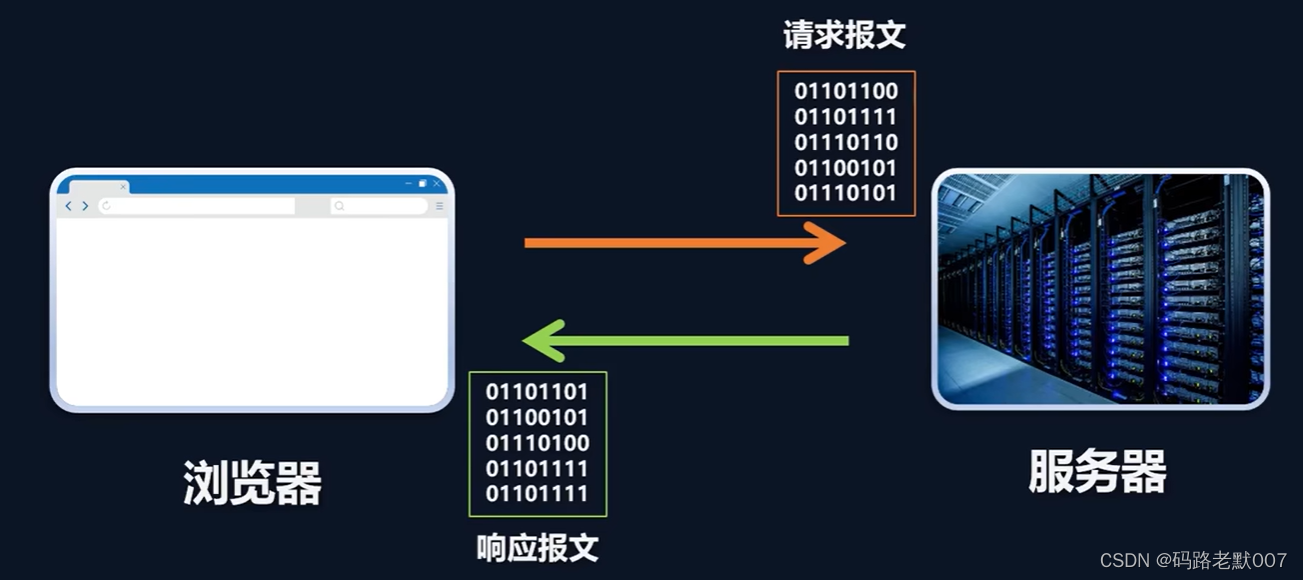
http协议是超文本传输协议,服务器与本地浏览器之间传输超文本的传送协议
2.http协议特性
1. 基于TCP/IP协议之上的应用层协议
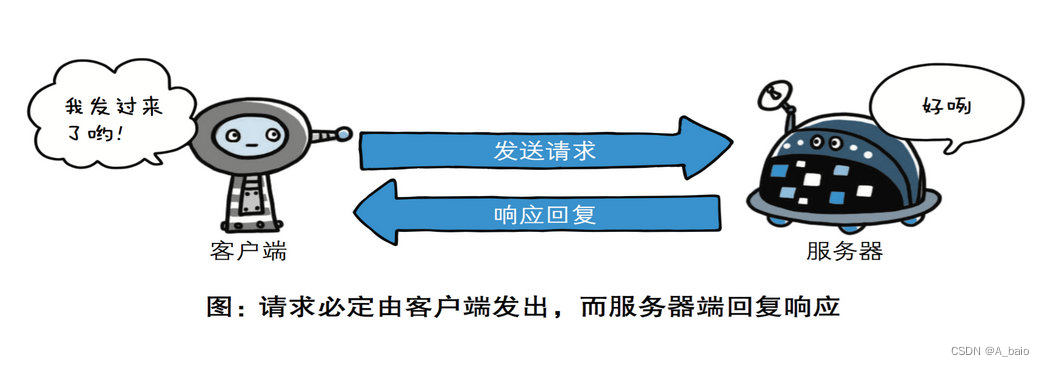
2. 基于请求–响应模式
HTTP协议规定,请求从客户端发出,最后服务器端响应该请求并 返回。
换句话说,肯定是先从客户端开始建立通信的,服务器端在没有 接收到请求之前不会发送响应
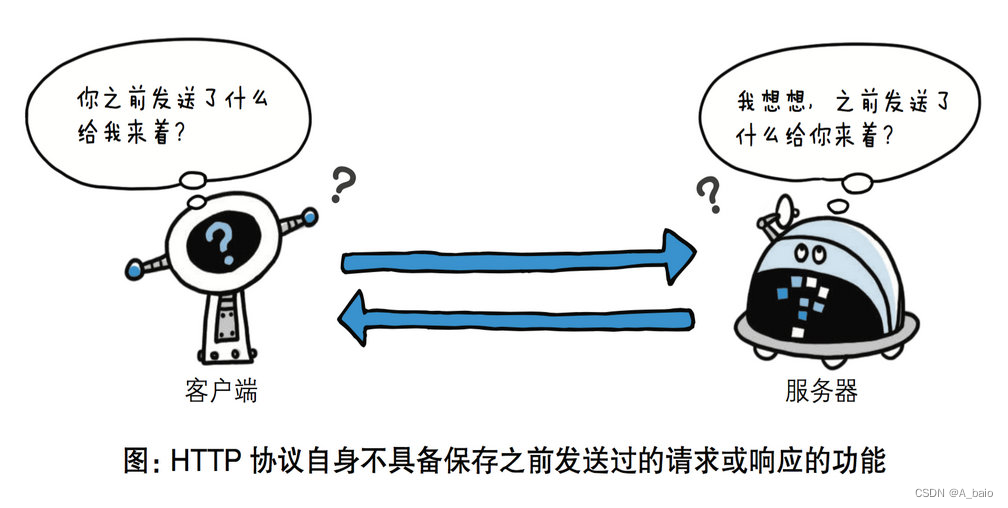
3. 无状态保存
HTTP是一种不保存状态,即无状态(stateless)协议。HTTP协议 自身不对请求和响应之间的通信状态进行保存。也就是说在HTTP这个 级别,协议对于发送过的请求或响应都不做持久化处理。
4.无连接
就是每次连接处理一个请求,服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
3.Http请求协议与响应协议
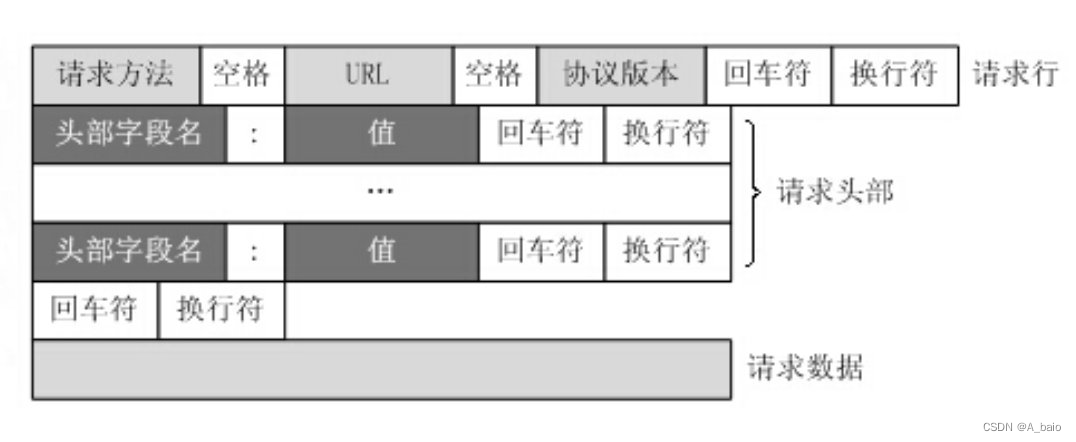
请求协议:
请求头:有K/V键值对组成 rn
请求体:get请求没有请求体,post请求有请求体
get请求
'''
------请求首行------
b'GET / HTTP/1.1rn
------请求头-----
Host: 127.0.0.1:8000rn
Connection: keep-alivern
Cache-Control: max-age=0rn
sec-ch-ua: "Microsoft Edge";v="119", "Chromium";v="119", "Not?A_Brand";v="24"rn
sec-ch-ua-mobile: ?0rn
sec-ch-ua-platform: "Windows"rn
Upgrade-Insecure-Requests: 1rn
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0rn
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7rn
Sec-Fetch-Site: nonern
Sec-Fetch-Mode: navigatern
Sec-Fetch-User: ?1rn
Sec-Fetch-Dest: documentrn
Accept-Encoding: gzip, deflate, brrn
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6rn
Cookie: o2State={%22webp%22:true%2C%22avif%22:false};csrftoken=X7rlh2l36LXbjh0COtpHqlaJOZFxjDzhbx8XPh0k9Ncl9in9VCemv4OIfyjFo1T4rnrn'
------请求体-----
'''
post请求
'''
------请求首行------
b'POST / HTTP/1.1rn
------请求头-----
Host: 127.0.0.1:8000rn
Connection: keep-alivern
Content-Length: 26rn
Cache-Control: max-age=0rn
sec-ch-ua: "Microsoft Edge";v="119", "Chromium";v="119", "Not?A_Brand";v="24"rn
sec-ch-ua-mobile: ?0rn
sec-ch-ua-platform: "Windows"rn
Upgrade-Insecure-Requests: 1rn
Origin: http://127.0.0.1:8000rn
Content-Type: application/x-www-form-urlencodedrn
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0rn
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7rn
Sec-Fetch-Site: same-originrn
Sec-Fetch-Mode: navigatern
Sec-Fetch-User: ?1rn
Sec-Fetch-Dest: documentrn
Referer: http://127.0.0.1:8000/rn
Accept-Encoding: gzip, deflate, brrn
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6rn
Cookie: o2State={%22webp%22:true%2C%22avif%22:false};csrftoken=X7rlh2l36LXbjh0COtpHqlaJOZFxjDzhbx8XPh0k9Ncl9in9VCemv4OIfyjFo1T4rnrn
------请求体-----
username=jack&password=123'
'''
响应式协议
响应首行:HTTP/1.1 200 OKrn
协议版本
响应状态码
响应描述符
响应头:有K/V键值对组成
Http有哪些版本
HTTP 0.9
HTTP 0.9 是最早发布出来的一个版本,于1991年发布。
它只接受 GET 一种请求方法,没有在通讯中指定版本号,且不支持请求头。由于该版本不支持 POST 方法,因此客户端无法向服务器传递太多信息。
HTTP 0.9 具有典型的无状态性,每个事务独立进行处理,事务结束时就释放这个连接。HTTP 协议的无状态特点在其第一个版本中已经成型。
HTTP 1.0
HTTP 1.0是HTTP协议的第二个版本,于1996年发布,如今仍然被广泛使用,尤其是在代理服务器中。
这是第一个在通讯中指定版本号的HTTP协议版本,具有以下特点:
- 不仅仅支持 GET 命令,还支持 POST 和 HEAD 等请求方法。
HTTP 的请求和回应格式也发生了变化,除了要传输的数据之外,每次通信都包含头信息,用来描述一些信息。 - 不再局限于 0.9 版本的纯文本格式
根据头信息中的 Content-Type 属性,可以支持多种数据格式,这使得互联网不仅仅可以用来传输文字,还可以传输图像、音频、视频等二进制文件。 - 开始支持cache,就是当客户端在规定时间内访问同一网站,直接访问cache即可。
- 其他的新增功能还包括状态码(status code)、多字符集支持、多部分发送(multi–part type)、权限(authorization)、缓存(cache)、内容编码(content encoding)等。
1.0 版本的工作方式是每次 TCP 连接只能发送一个请求,当服务器响应后就会关闭这次连接,下一个请求需要再次建立 TCP 连接。 TCP 连接的建立成本很高,因为需要客户端和服务器三次握手,并且开始时发送速率较慢(slow start)。
HTTP 1.0 版本的性能比较差。随着网页加载的外部资源越来越多,这个问题就愈发突出了。为了解决这个问题,有些浏览器在请求时,即在请求头部加上 Connection 字段:
HTTP1.1
默认采用持续连接(Connection: keep-alive),能很好地配合代理服务器工作。
还支持以管道方式在同时发送多个请求,以便降低线路负载,提高传输速度。
HTTP 1.1 具有以下特点:
- 引入了持久连接(persistent connection)
即 TCP 连接默认不关闭,可以被多个请求复用,不用声明 Connection: keep-alive。客户端和服务器发现对方一段时间没有活动,就可以主动关闭连接。不过,规范的做法是,客户端在最后一个请求时,发送 Connection: close,明确要求服务器关闭 TCP 连接。 - 加入了管道机制
在同一个 TCP 连接里,允许多个请求同时发送,增加了并发性,进一步改善了 HTTP 协议的效率。
举例来说,客户端需要请求两个资源。以前的做法是,在同一个 TCP 连接里面,先发送 A 请求,然后等待服务器做出回应,收到后再发出 B 请求。
管道机制则是允许浏览器同时发出 A 请求和 B 请求,但是服务器还是按照顺序,先回应 A 请求,完成后再回应 B 请求。
一个 TCP 连接现在可以传送多个回应,势必就要有一种机制,区分数据包是属于哪一个回应的。这就是 Content-length 字段的作用,声明本次回应的数据长度。 - 分块传输编码
使用 Content-Length 字段的前提条件是,服务器发送回应之前,必须知道回应的数据长度。对于一些很耗时的动态操作来说,这意味着,服务器要等到所有操作完成,才能发送数据,显然这样的效率不高。
更好的处理方法是,产生一块数据,就发送一块,采用“流模式“(stream)取代”缓存模式“(buffer)。
因此,HTTP 1.1 版本规定可以不使用 Content-Length 字段,而使用“分块传输编码“(chunked transfer encoding)。只要请求或回应的头信息有 Transfer-Encoding 字段,就表明回应将由数量未定的数据块组成。 - 新增了请求方式 PUT、PATCH、OPTIONS、DELETE 等。
- 客户端请求的头信息新增了 Host 字段,用来指定服务器的域名。
- HTTP 1.1 支持文件断点续传,RANGE:bytes,HTTP 1.0 每次传送文件都是从文件头开始,即 0 字节处开始。RANGE:bytes=XXXX 表示要求服务器从文件 XXXX 字节处开始传送,断点续传。即返回码是 206(Partial Content)
HTTP/2.0
这也是最新的 HTTP 版本,于 2015 年 5 月作为互联网标准正式发布。
它具有以下特点:
- 二进制协议
HTTP 1.1 版的头信息肯定是文本(ASCII 编码),数据体可以是文本,也可以是二进制。
HTTP 2.0 则是一个彻底的二进制协议,头信息和数据体都是二进制,并且统称为”帧”(frame):头信息帧和数据帧。 - 多工
HTTP 2.0 复用 TCP 连接,在一个连接里,客户端和浏览器都可以同时发送多个请求或回应,而且不用按照顺序一一对应,这样就避免了”队头堵塞”(HTTP 2.0 使用了多路复用的技术,做到同一个连接并发处理多个请求,而且并发请求的数量比 HTTP 1.1大了好几个数量级)。
举例来说,在一个 TCP 连接里面,服务器同时收到了 A 请求和 B 请求,于是先回应 A 请求,结果发现处理过程非常耗时,于是就发送 A 请求已经处理好的部分, 接着回应 B 请求,完成后,再发送 A 请求剩下的部分。 - 头信息压缩
HTTP 协议不带有状态,每次请求都必须附上所有信息。所以,请求的很多字段都是重复的,比如 Cookie 和 User Agent,一模一样的内容,每次请求都必须附带,这会浪费很多带宽,也影响速度。
HTTP 2.0 对这一点做了优化,引入了头信息压缩机制(header compression)。一方面,头信息使用 gzip 或c ompress 压缩后再发送;另一方面,客户端和服务器同时维护一张头信息表,所有字段都会存入这个表,生成一个索引号,以后就不发送同样字段了,只发送索引号,这样就提高速度了。 - 服务器推送
HTTP 2.0 允许服务器未经请求,主动向客户端发送资源,这叫做服务器推送(server push)。意思是说,当我们对支持 HTTP 2.0 的 web server 请求数据的时候,服务器会顺便把一些客户端需要的资源一起推送到客户端,免得客户端再次创建连接发送请求到服务器端获取。这种方式非常合适加载静态资源。 服务器端推送的这些资源其实存在客户端的某处地方,客户端直接从本地加载这些资源就可以了,不用走网络,速度自然是快很多的。
HTTP/3.0
基于Google的QUIC,HTTP3 背后的主要思想是放弃 TCP,转而使用基于 UDP 的 QUIC 协议。
为了解决HTTP/2.0中TCP造成的队头阻塞问题,HTTP/3.0直接放弃使用TCP,将传输层协议改成UDP;但是因为UDP是不可靠传输,所以这就需要QUIC实现可靠机制
QUIC 也是需要三次握手来建立连接的,主要目的是为了确定连接 ID。
在 UDP 报文头部与 HTTP 消息之间,共有 3 层头部:
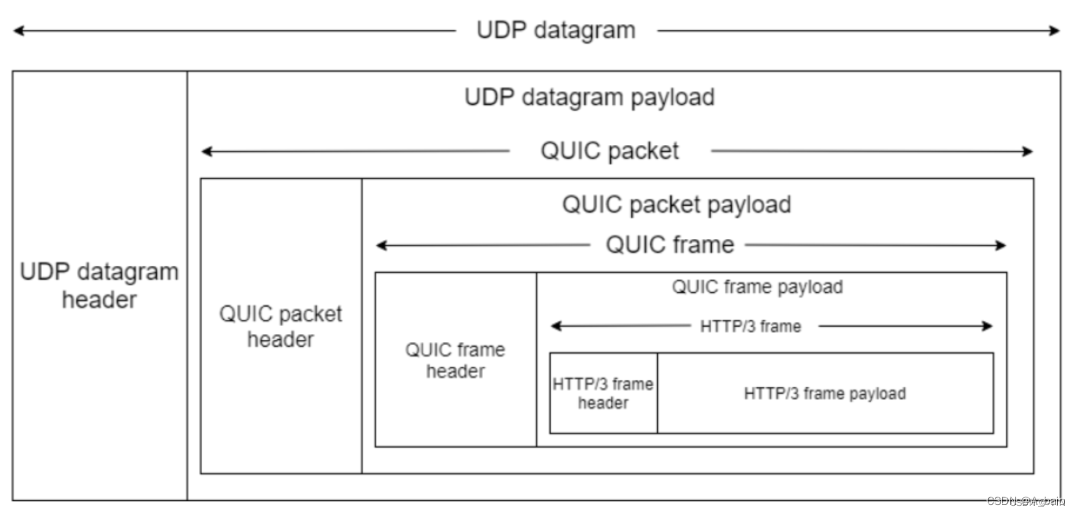
QUIC特点:
无队头阻塞
QUIC 协议也有类似 HTTP/2 Stream 与多路复用的概念,也是可以在同一条连接上并发传输多个 Stream,Stream 可以认为就是一条 HTTP 请求。
QUIC 有自己的一套机制可以保证传输的可靠性的。当某个流发生丢包时,只会阻塞这个流,其他流不会受到影响,因此不存在队头阻塞问题。这与 HTTP/2 不同,HTTP/2 只要某个流中的数据包丢失了,其他流也会因此受影响。
所以,QUIC 连接上的多个 Stream 之间并没有依赖,都是独立的,某个流发生丢包了,只会影响该流,其他流不受影响。
连接建立
HTTP/3 在传输数据前虽然需要 QUIC 协议握手,这个握手过程只需要 1 RTT,握手的目的是为确认双方的「连接 ID」,连接迁移就是基于连接 ID 实现的。
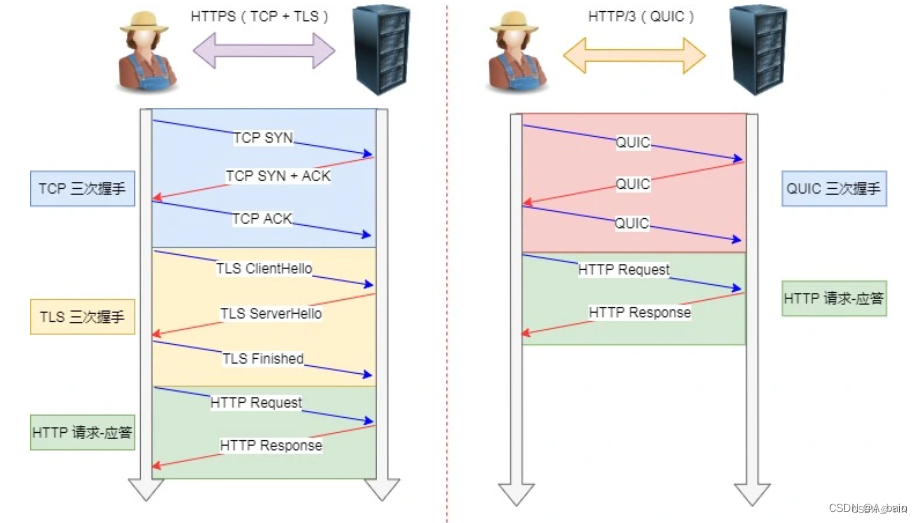
连接迁移
基于 TCP 传输协议的 HTTP 协议,由于是通过四元组(源 IP、源端口、目的 IP、目的端口)确定一条 TCP 连接,例如设备要连接wifi(IP地址改变)就必须要重新建立连接,而建立连接包含TCP三次握手和TSL四次握手,以及TCP慢启动所以会造成使用者卡顿的感觉
而QUIC通过连接ID标记自己,客户端和服务器可以各自选择一组 ID 来标记自己,因此即使移动设备的网络变化后,导致 IP 地址变化了,只要有上下文信息(比如连接 ID、TLS 密钥等),就可以“无缝”地复用原连接,消除重连的成本,没有丝毫卡顿感,达到了连接迁移的功能。
其实, QUIC 是一个在 UDP 之上的伪 TCP + TLS + HTTP/2 的多路复用的协议。
总结
HTTP/0.9:功能简陋,只支持GET方法,只能发送HTML格式字符串。
HTTP/1.0:支持多种数据格式,增加POST、HEAD等方法,增加头信息,每次只能发送一个请求(无持久连接)
HTTP/1.1:默认持久连接、请求管道化、增加缓存处理、增加Host字段、支持断点传输分块传输等。
HTTP/2.0:二进制分帧、多路复用、头部压缩、服务器推送
HTTP/3.0: 将传输层协议改成UDP;但是因为UDP是不可靠传输,所以这就需要QUIC实现可靠机制,QUIC 也是需要三次握手来建立连接的,主要目的是为了确定连接 ID。
常见的请求头
1. User-Agent:标识客户端使用的浏览器和操作系统信息。可以通过$_SERVER['HTTP_USER_AGENT']获取。
2. Accept:指定客户端能够处理的内容类型,即可接受的媒体类型。可以通过$_SERVER['HTTP_ACCEPT']获取。
3. Content-Type:指定请求体中的数据格式类型。常见的取值有application/json、application/x-www-form-urlencoded等。可以通过$_SERVER['CONTENT_TYPE']获取。
4. Authorization:用于进行身份验证的凭证信息。常见的取值有Bearer Token、Basic Authentication等。可以通过$_SERVER['HTTP_AUTHORIZATION']获取。
5. Cookie:包含来自客户端的Cookie信息。可以通过$_SERVER['HTTP_COOKIE']获取。
6. Referer:指示当前请求是从哪个URL页面发起的。可以通过$_SERVER['HTTP_REFERER']获取。、
8.Host:指定服务器的域名或IP地址。可以通过$_SERVER['HTTP_HOST']获取。
8. X-Requested-With:指示请求是否由Ajax发起的。通常在Ajax请求中会设置该头部字段,取值为"XMLHttpRequest"。可以通过$_SERVER['HTTP_X_REQUESTED_WITH']获取。
9. Content-Length:指定请求体的长度。可以通过$_SERVER['CONTENT_LENGTH']获取。
10. Cache-Control:控制缓存行为的指令。用于指定客户端和代理服务器如何缓存响应。可以通过$_SERVER['HTTP_CACHE_CONTROL']获取。
常见响应头
1.Cache-Control(对应请求中的Cache-Control)Cache-Control:private 默认为private 响应只能够作为私有的缓存,不能再用户间共享Cache-Control:public 浏览器和缓存服务器都可以缓存页面信息。Cache-Control:must-revalidate 对于客户机的每次请求,代理服务器必须想服务器验证缓存是否过时。Cache-Control:no-cache 浏览器和缓存服务器都不应该缓存页面信息。Cache-Control:max-age=10 是通知浏览器10秒之内不要烦我,自己从缓冲区中刷新。Cache-Control:no-store 请求和响应的信息都不应该被存储在对方的磁盘系统中。
2.Content-Type:text/html;charset=UTF-8 告诉客户端,资源文件的类型,还有字符编码,客户端通过utf-8对资源进行解码,然后对资源进行html解析。通常我们会看到有些网站是乱码的,往往就是服务器端没有返回正确的编码。
3.Content-Encoding:gzip 告诉客户端,服务端发送的资源是采用gzip编码的,客户端看到这个信息后,应该采用gzip对资源进行解码。
4.Date: Tue, 03 Apr 2018 03:52:28 GMT 这个是服务端发送资源时的服务器时间,GMT是格林尼治所在地的标准时间。http协议中发送的时间都是GMT的,这主要是解决在互联网上,不同时区在相互请求资源的时候,时间混乱问题。
5.Server:Tengine/1.4.6 这个是服务器和相对应的版本,只是告诉客户端服务器信息。
6.Transfer-Encoding:chunked 这个响应头告诉客户端,服务器发送的资源的方式是分块发送的。一般分块发送的资源都是服务器动态生成的,在发送时还不知道发送资源的大小,所以采用分块发送,每一块都是独立的,独立的块都能标示自己的长度,最后一块是0长度的,当客户端读到这个0长度的块时,就可以确定资源已经传输完了。
7.Expires:Sun, 1 Jan 2000 01:00:00 GMT 这个响应头也是跟缓存有关的,告诉客户端在这个时间前,可以直接访问缓存副本,很显然这个值会存在问题,因为客户端和服务器的时间不一定会都是相同的,如果时间不同就会导致问题。所以这个响应头是没有Cache-Control:max-age=*这个响应头准确的,因为max-age=date中的date是个相对时间,不仅更好理解,也更准确。
8.Last-Modified: Dec, 26 Dec 2015 17:30:00 GMT 所请求的对象的最后修改日期(按照 RFC 7231 中定义的“超文本传输协议日期”格式来表示)
9.Connection:keep-alive 这个字段作为回应客户端的Connection:keep-alive,告诉客户端服务器的tcp连接也是一个长连接,客户端可以继续使用这个tcp连接发送http请求。
10.EtagETag: "737060cd8c284d8af7ad3082f209582d" 就是一个对象(比如URL)的标志值,就一个对象而言,比如一个html文件,如果被修改了,其Etag也会别修改,所以,ETag的作用跟Last-Modified的作用差不多,主要供WEB服务器判断一个对象是否改变了。比如前一次请求某个html文件时,获得了其 ETag,当这次又请求这个文件时,浏览器就会把先前获得ETag值发送给WEB服务器,然后WEB服务器会把这个ETag跟该文件的当前ETag进行对比,然后就知道这个文件有没有改变了。
11.Refresh: 5; url=http://baidu.com 用于重定向,或者当一个新的资源被创建时。默认会在5秒后刷新重定向。
12.Access-Control-Allow-Origin: * *号代表所有网站可以跨域资源共享,如果当前字段为*那么Access-Control-Allow-Credentials就不能为trueAccess-Control-Allow-Origin: www.baidu.com 指定哪些网站可以跨域资源共享
13.Access-Control-Allow-Methods:GET,POST,PUT,DELETE 允许哪些方法来访问
14.Access-Control-Allow-Credentials: true 是否允许发送cookie。默认情况下,Cookie不包括在CORS请求之中。设为true,即表示服务器明确许可,Cookie可以包含在请求中,一起发给服务器。这个值也只能设为true,如果服务器不要浏览器发送Cookie,删除该字段即可。如果access-control-allow-origin为*,当前字段就不能为true
15.Content-Range: bytes 0-5/7877 指定整个实体中的一部分的插入位置,他也指示了整个实体的长度。在服务器向客户返回一个部分响应,它必须描述响应覆盖的范围和整个实体长度。
常见的响应状态码
HTTP状态码负责表示客户端HTTP请求的返回结果、标记服务器的处理是否正常、通知出现的错误工作等。借助状态码,用户可以知道服务器端是正常处理了请求,还是出现了错误。
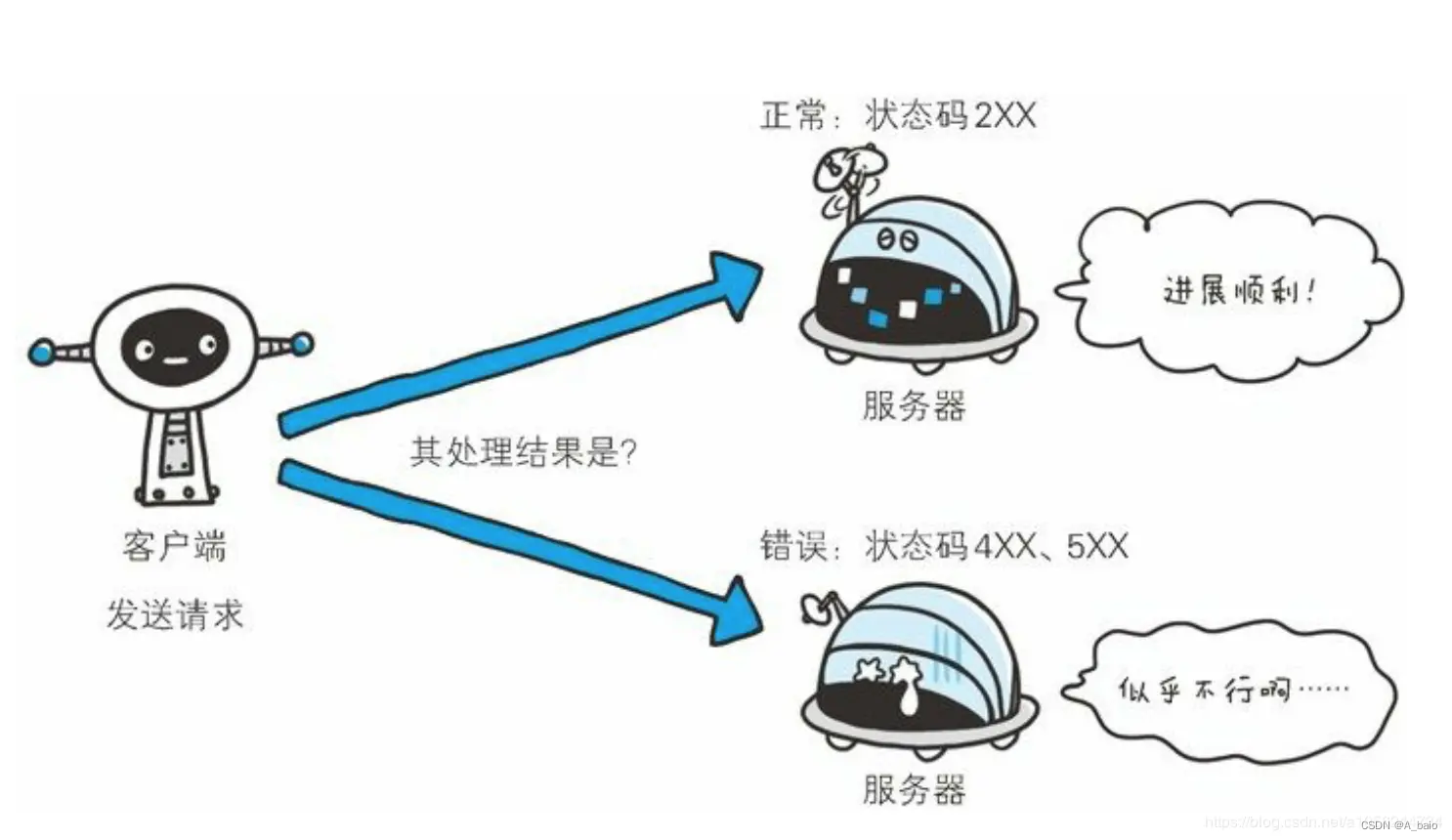
状态码如200 OK,由3位数字和原因短语组成。数字中的第一位指定了响应类别,后两位无分类。相应类别由以下五种:
1xx Informational(信息状态码) 接受请求正在处理
2xx Success(成功状态码) 请求正常处理完毕
3xx Redirection(重定向状态码) 需要附加操作已完成请求
4xx Client Error(客户端错误状态码) 服务器无法处理请求
5xx Server Error(服务器错误状态码) 服务器处理请求出错
HTTP的状态码总数达60余种,但是常用的大概只有14种。接下来,我们就介绍一下这些具有代表性的14个状态码。
200 OK 请求成功。一般用于GET与POST请求
204 No Content 无内容。服务器成功处理,但未返回内容。在未更新网页的情况下,可确保浏览器继续显示当前文档
206 Partial Content 是对资源某一部分的请求,服务器成功处理了部分GET请求,响应报文中包含由Content-Range指定范围的实体内容。
301 Moved Permanently 永久性重定向。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替
302 Found 临时性重定向。与301类似。但资源只是临时被移动。客户端应继续使用原有URI
303 See Other 查看其它地址。与302类似。使用GET请求查看
304 Not Modified 未修改。所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源
307 Temporary Redirect 临时重定向。与302类似。使用GET请求重定向,会按照浏览器标准,不会从POST变成GET。
400 Bad Request 客户端请求报文中存在语法错误,服务器无法理解。浏览器会像200 OK一样对待该状态吗
401 Unauthorized 请求要求用户的身份认证,通过HTTP认证(BASIC认证,DIGEST认证)的认证信息,若之前已进行过一次请求,则表示用户认证失败
402 Payment Required 保留,将来使用
403 Forbidden 服务器理解请求客户端的请求,但是拒绝执行此请求
404 Not Found 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置“您所请求的资源无法找到”的个性页面。也可以在服务器拒绝请求且不想说明理由时使用
500 Internal Server Error 服务器内部错误,无法完成请求,也可能是web应用存在bug或某些临时故障
501 Not Implemented 服务器不支持请求的功能,无法完成请求
503 Service Unavailable 由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的Retry-After头信息中
web框架
1.web框架是什么
简单来说就是别人帮咱写了一些基础代码,我们只需要在固定位置写固定的代码,就能实现一个web应用
Web框架(Web framework)是一种开发框架,用来支持动态网站、网络应用和网络服务的开发。这大多数的web框架提供了一套开发和部署网站的方式,也为web行为提供了一套通用的方法。web框架已经实现了很多功能,开发人员使用框架提供的方法并且完成自己的业务逻辑,就能快速开发web应用了。浏览器和服务器的是基于HTTP协议进行通信的。也可以说web框架就是在以上十几行代码基础张扩展出来的,有很多简单方便使用的方法,大大提高了开发的效率
2.wsgi协议
客户端浏览器和python web框架之间通讯需要遵守这个协议,客户端发出的是http请求,通过符合wsgi协议的web服务器通讯
应用程序,是一个可重复调用的可调用对象,在Python中可以是一个函数,也可以是一个类,如果是类的话要实现__call__方法,要求这个可调用对象接收2个参数,返回一个内容结果
接收的2个参数分别是environ和start_response。
environ是web服务器解析HTTP协议的一些信息,例如请求方法,请求URI等信息构成的一个Dict对象。
start_response是一个函数,接收2个参数,一个是HTTP状态码,一个HTTP消息中的响应头。
Django
1.MVC与MTV模型
所有的web框架都是遵守MVC架构
MVC
模型(M:数据层)
控制器(C: 逻辑判断)
视图(V: 用户看到的)
他们之间以一种插件式的、松耦合的方式连接在一起,模型负责业务对象与数据库的映射(ORM),视图负责与用户的交互(页面),控制器接受用户的输入调用模型和视图完成用户的请求
MTV
M 代表模型(Model): 负责业务对象和数据库的关系映射(ORM)。
M就是原来的M
T 代表模板 (Template):负责如何把页面展示给用户(html)。
T就是原来的V
V 代表视图(View): 负责业务逻辑,并在适当时候调用Model和Template
V+路由 是原来的C
3. 下载与使用
下载…
命令创建项目
django–admin startproject 项目名
命令创建应用
python manage.py startapp 应用名
4.django框架的目录结构

5.启动项目
6.django请求生命周期图
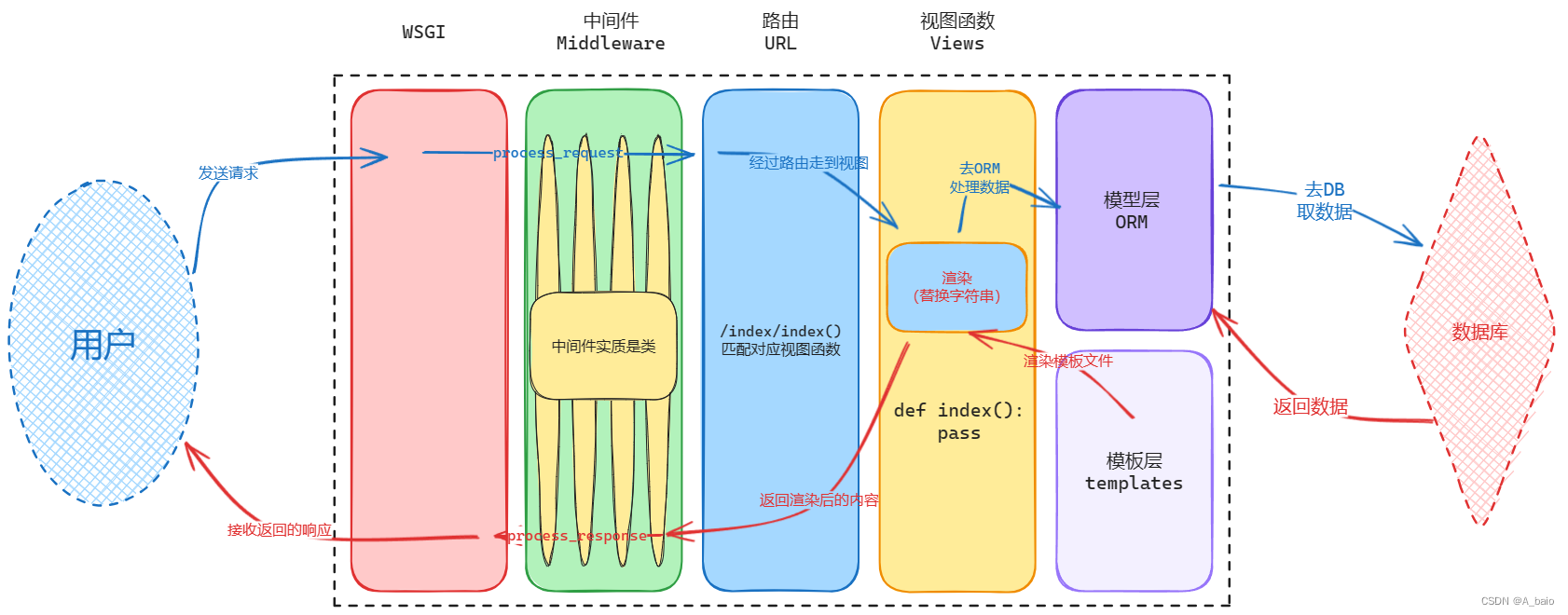
路由控制
1.路由是什么
URL配置(URLconf)就像Django 所支撑网站的目录。它的本质是URL与要为该URL调用的视图函数之间的映射表;你就是以这种方式告诉Django,对于客户端发来的某个URL调用哪一段逻辑代码对应执行
请求路径和要执行的视图函数的对应关系
2.如何使用
path:准确路径,精准匹配——–>以后基本都是path
re_path—-就是1.xx版本的url——>支持正则匹配—–>不安全,非常少用
都是放在setting下的urlpatterns=[]列表中,必须是path或re_path执行完的结果
3. path详细使用
path(‘admin/’,login)等价于_path(route, view, kwargs=None, name=None)
第一个参数:
准确路径,字符串
转换器:‘<int:pk>’ , ‘<str:name>’
127.0.0.1:8080/login/jack—->path(‘login/<str:name>’, views.login)
视图函数:def login(request,name)
第二个参数:
视图函数的内存地址,不能加括号
路由一旦匹配成功,就会执行你写的这个视图函数加上(),并且把request对象传入
如果有分组的参数[有名,无名],或者转换器的参数,都会被传递到视图函数中作为参数
总结:放要放视图函数地址—》但是视图函数的参数:第一个是固定必须是request,后续的取决于写没写转换器,写没写有名无名分组
re_path的详细使用
跟path除了第一个参数不一样,其他完全一样
第一个参数是正则表达式
后期用的很少,危险性大—》原来之所以支持正则的目的是为了分组出参数
path通过转换器能完成这个操作–》于是–》这个几乎不用
5.反向解析,用在视图函数中,用在模版中
- 没有转换器的情况:
path(‘login/’, login,name=‘login’)
res=reverse(‘login’) #当时 定义路径传入的name参数对应的字符串 - 有转换器的情况:
path(‘login/<str:name>’, login,name=‘login’)
res=reverse(‘login’,kwargs={name:jack}) #当时 定义路径传入的name参数对应的字符串
生成这种路径:‘login/jack’
6.路由分发
每一个app有自己的路由
导入模块 from django.urls import include
视图层
1.views.py这个文件就是写视图函数的
2.视图函数编写
3.request对象
它是http请求对象(数据包,字符串形式)拆分成了django中得request对象
常用的有:
request.path
reuqest.method
request.GET
request.POST
reuqest.body
reqeust.get_full_path()
request.files 前端传过来文件,转成字典,根据文件的名字取到文件对象
不常用的
reqeust.cookie
request.session
request.contnet_type
request.MEAT:请求头中的数据
user-agent:HTTP_USER_AGENT
referer:
客户端IP地址:REMOTE_ADDR
用户自定义的
定义:name=jack
取:request.META.get('HTTP_NAME')# 前面加HTTP_ 把自定义的转成大写
request.user
request.is_ajax()
响应对象
响应对象四件套:
-
render 需要返回两个必传参数,一个是request,一个是模板,模板渲染是在后端完成,模板返回到浏览器,最终成为响应体,还可以传其他参数,可以去看源码。
模版渲染是在后端完成的,而js代码是在客户端渲染完成。
js想要用python中的变量,就需要使用模板语法 -
JsonResponse json格式数据
需要另外导入:from django.http import JsonResponse
读JsonResponse源码
1.现在返回一个JsonResponse({'name':'jack'})
def __init__(self, data, encoder=DjangoJSONEncoder, safe=True,json_dumps_params=None, **kwargs):
2.{'name':'jack'}就会传给data
if safe and not isinstance(data, dict):
3.判断safe成立,如果想返回一个列表,把safe改成False
isinstance,检查对象是否成立(对象,类)
所以以上if不成立,就不会走下面的代码
raise TypeError(
'In order to allow non-dict objects to be serialized set the '
'safe parameter to False.'
)
if json_dumps_params is None:
json_dumps_params = {}
kwargs.setdefault('content_type', 'application/json')
4.默认的请求头,setdefault,有则修改,无则新增
data = json.dumps(data, cls=encoder, **json_dumps_params)
5.这一句才是将数据序列化成json格式
super().__init__(content=data, **kwargs)
6.调用父类的__init__完成实例化得到一个HttpResponse的对象
现在传一个{'name':'张三'}
序列化的时候就需要转码:json.dump({'name':'张三'}, ensure_ascii=False)这样子才能是中文
而在JsonResponse中,是不能用ensure_ascii=False
而是用:
JsonResponse({'name':'张三'},json_dumps_params={'ensure_ascii':False})
''''''''''''''''''''''
还可以添加响应头,需要用到headers参数
JsonResponse({'name':'张三'},json_dumps_params={'ensure_ascii':False},headers={'xxx':'xxx'})
CBV和FBV
FBV:基于函数的视图,经常写的都是FBV
CBV:基于类的视图,后续全是CBV
CBV写法
class UseView(View):
def get(self,request):
return HttpResponse('from get')
def post(self,request):
return HttpResponse('from post')
path('index/', views.UseView.as_view())
CBV的执行流程
先去路由匹配,匹配成功执行,UserView.as_view(),一定会执行(request)
def view(request, *args, **kwargs): 本质就是在执行view(request)
self = cls(**initkwargs)
self.setup(request, *args, **kwargs)
if not hasattr(self, 'request'):
raise AttributeError(
"%s instance has no 'request' attribute. Did you override "
"setup() and forget to call super()?" % cls.__name__
)
return self.dispatch(request, *args, **kwargs)
实际上是在执行self.dispatch(request, *args, **kwargs),又会去类中找dispatch
dispatch代码:
def dispatch(self, request, *args, **kwargs):
if request.method.lower() in self.http_method_names: request请求来请求对象时,会在8大请求方法里找
handler = getattr(self, request.method.lower(), self.http_method_not_allowed)
# getattr 反射方法 通过字符串去对象中取属性或方法
# self是谁调用的就是谁的对象
# handler取出来的是Userview这个类的get方法
else:
handler = self.http_method_not_allowed
get(request)就会执行UserView这个类的get方法,才会真正执行原来的视图函数的内容
return handler(request, *args, **kwargs)
总结:写CBV,只需要在视图类写请求方式同名的方法即可,不同的请求方式,就会执行不同的方法
关于类中self是谁的问题
谁在调用就是谁,
原文地址:https://blog.csdn.net/shiyaopeng11/article/details/134648767
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_21310.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!