一、什么是回归
机器学习中的回归是一种预测性分析任务,旨在找出因变量(目标变量)和自变量(预测变量)之间的关系。与分类问题不同,回归问题关注的是预测连续型或数值型数据,如温度、年龄、薪水、价格等。回归分析可以帮助我们理解当其他变量保持不变时,因变量的值如何随着自变量的变化而变化。
在机器学习中,回归问题通常采用监督学习方法,即利用已标记的数据集(包含输入和目标输出)来训练模型。训练完成后,模型可以对新数据进行预测。回归分析的应用广泛,包括广告投放效果评估、房价预测、股票价格预测等。
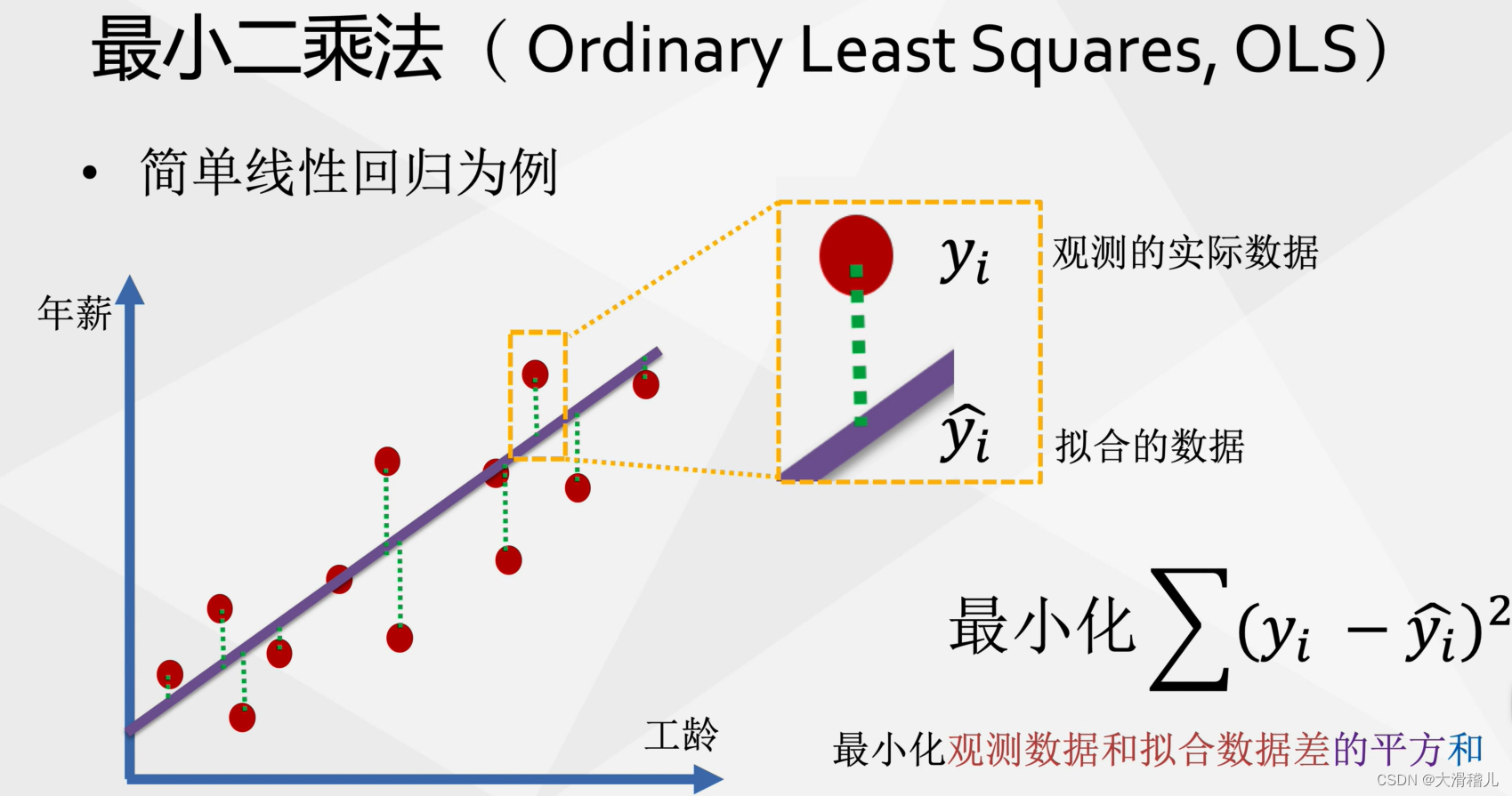
二、什么是拟合?
拟合是一种数学方法,用于描述一组数据之间的关系。它通过在平面上的点之间绘制一条曲线来实现。拟合的方法有很多,如最小二乘法、多项式拟合等。拟合程度可以通过决定系数(也称为R²)来衡量。决定系数越接近1,表示拟合程度越好。

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。