机器学习的分类问题常用评论指标有:准确率、精确度、召回率和F1值,还有kappa指标 。
每次调包去找他们的计算代码很麻烦,所以这里一次性定义一个函数,直接计算所有的评价指标。


Python计算代码
#导入数据分析常用包
import numpy as np
import pandas as pd
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
from sklearn.metrics import cohen_kappa_score
def evaluation(y_test, y_predict):
accuracy=classification_report(y_test, y_predict,output_dict=True)['accuracy']
s=classification_report(y_test, y_predict,output_dict=True)['weighted avg']
precision=s['precision']
recall=s['recall']
f1_score=s['f1-score']
#kappa=cohen_kappa_score(y_test, y_predict)
return accuracy,precision,recall,f1_score #, kappa这个函数就两个参数,真实值和预测值,放入就可以计算上面的所有指标了,函数的返回值就是accuracy,precision,recall,f1_score #, kappa。
画图展示:
#划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,stratify=y,test_size=0.2,random_state=0)标准化一下:
#数据标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train_s = scaler.transform(X_train)
X_test_s = scaler.transform(X_test)
print('训练数据形状:')
print(X_train_s.shape,y_train.shape)
print('验证集数据形状:')
print(X_test_s.shape,y_test.shape)from sklearn.linear_model import LogisticRegression
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
from xgboost.sklearn import XGBClassifier
from lightgbm import LGBMClassifier
from sklearn.svm import SVC
from sklearn.neural_network import MLPClassifier#逻辑回归
model1 = LogisticRegression(C=1e10,max_iter=10000)
#线性判别分析
model2 = LinearDiscriminantAnalysis()
#K近邻
model3 = KNeighborsClassifier(n_neighbors=10)
#决策树
model4 = DecisionTreeClassifier(random_state=77)
#随机森林
model5= RandomForestClassifier(n_estimators=1000, max_features='sqrt',random_state=10)
#梯度提升
model6 = GradientBoostingClassifier(random_state=123)
#极端梯度提升
model7 = XGBClassifier(use_label_encoder=False,eval_metric=['logloss','auc','error'],
objective='multi:softmax',random_state=0)
#轻量梯度提升
model8 = LGBMClassifier(objective='multiclass',num_class=3,random_state=1)
#支持向量机
model9 = SVC(kernel="rbf", random_state=77)
#神经网络
model10 = MLPClassifier(hidden_layer_sizes=(16,8), random_state=77, max_iter=10000)
model_list=[model1,model2,model3,model4,model5,model6,model7,model8,model9,model10]
model_name=['逻辑回归','线性判别','K近邻','决策树','随机森林','梯度提升','极端梯度提升','轻量梯度提升','支持向量机','神经网络']计算评价指标:用df_eval数据框装起来计算的评价指标数值
df_eval=pd.DataFrame(columns=['Accuracy','Precision','Recall','F1_score'])
for i in range(10):
model_C=model_list[i]
name=model_name[i]
model_C.fit(X_train_s, y_train)
pred=model_C.predict(X_test_s)
#s=classification_report(y_test, pred)
s=evaluation(y_test,pred)
df_eval.loc[name,:]=list(s)df_eval 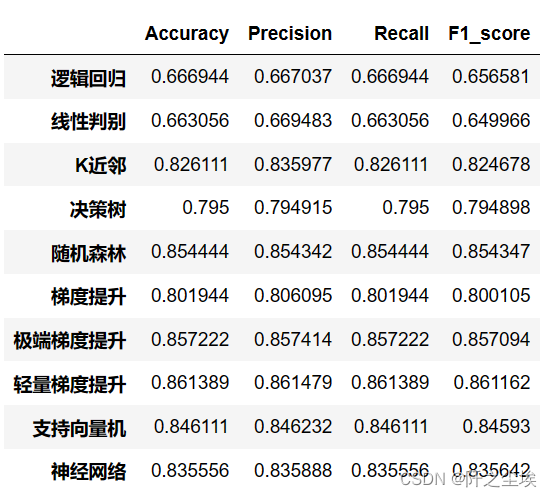
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['KaiTi'] #中文
plt.rcParams['axes.unicode_minus'] = False #负号
bar_width = 0.4
colors=['c', 'b', 'g', 'tomato', 'm', 'y', 'lime', 'k','orange','pink','grey','tan']
fig, ax = plt.subplots(2,2,figsize=(10,8),dpi=128)
for i,col in enumerate(df_eval.columns):
n=int(str('22')+str(i+1))
plt.subplot(n)
df_col=df_eval[col]
m =np.arange(len(df_col))
plt.bar(x=m,height=df_col.to_numpy(),width=bar_width,color=colors)
#plt.xlabel('Methods',fontsize=12)
names=df_col.index
plt.xticks(range(len(df_col)),names,fontsize=10)
plt.xticks(rotation=40)
plt.ylabel(col,fontsize=14)
plt.tight_layout()
#plt.savefig('柱状图.jpg',dpi=512)
plt.show()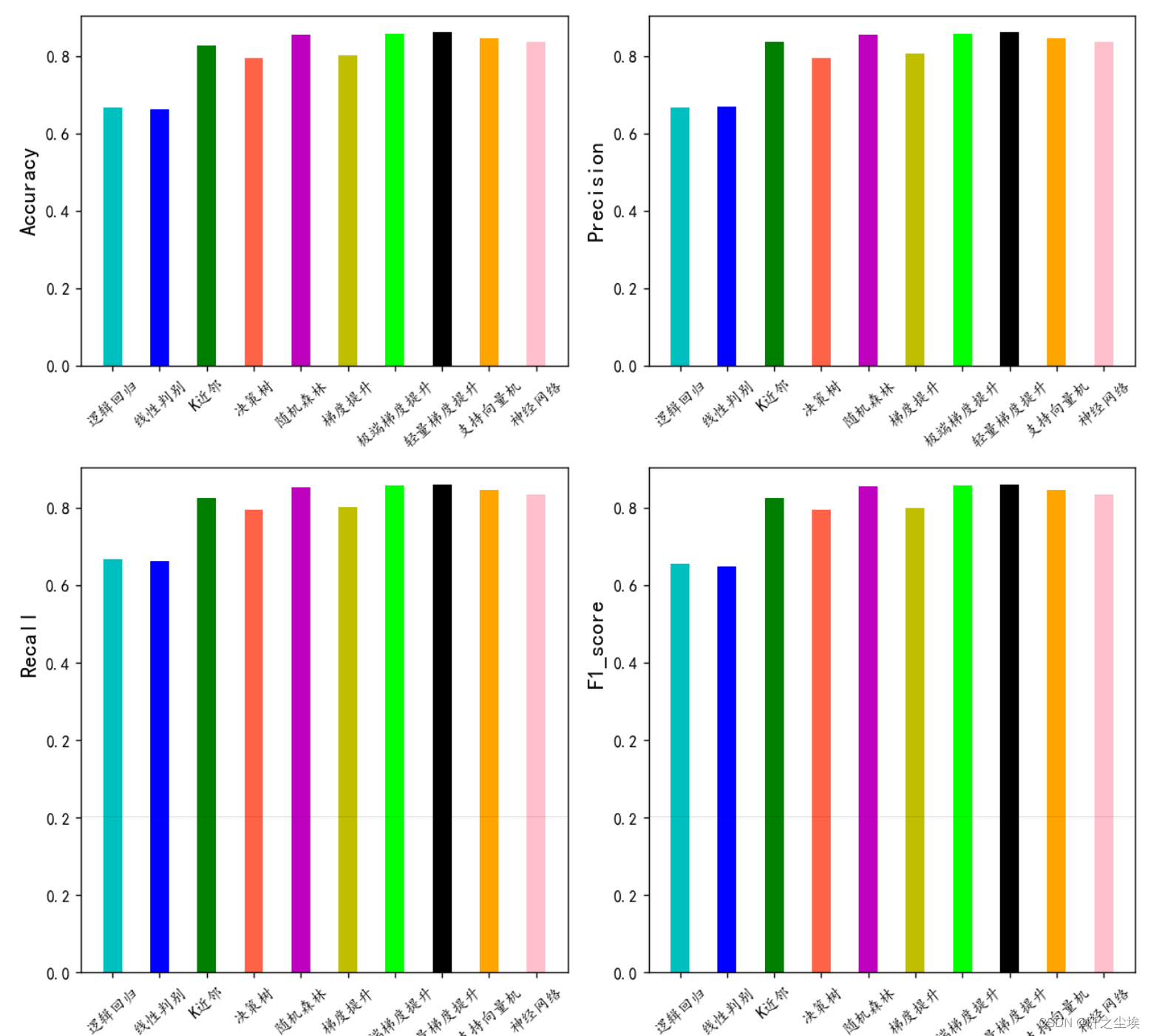
这个自定义计算分类评价指标函数还是很方便的,还可以用于交叉验证里面,全面评价模型的预测好坏程度。
原文地址:https://blog.csdn.net/weixin_46277779/article/details/129338660
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_21540.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。





