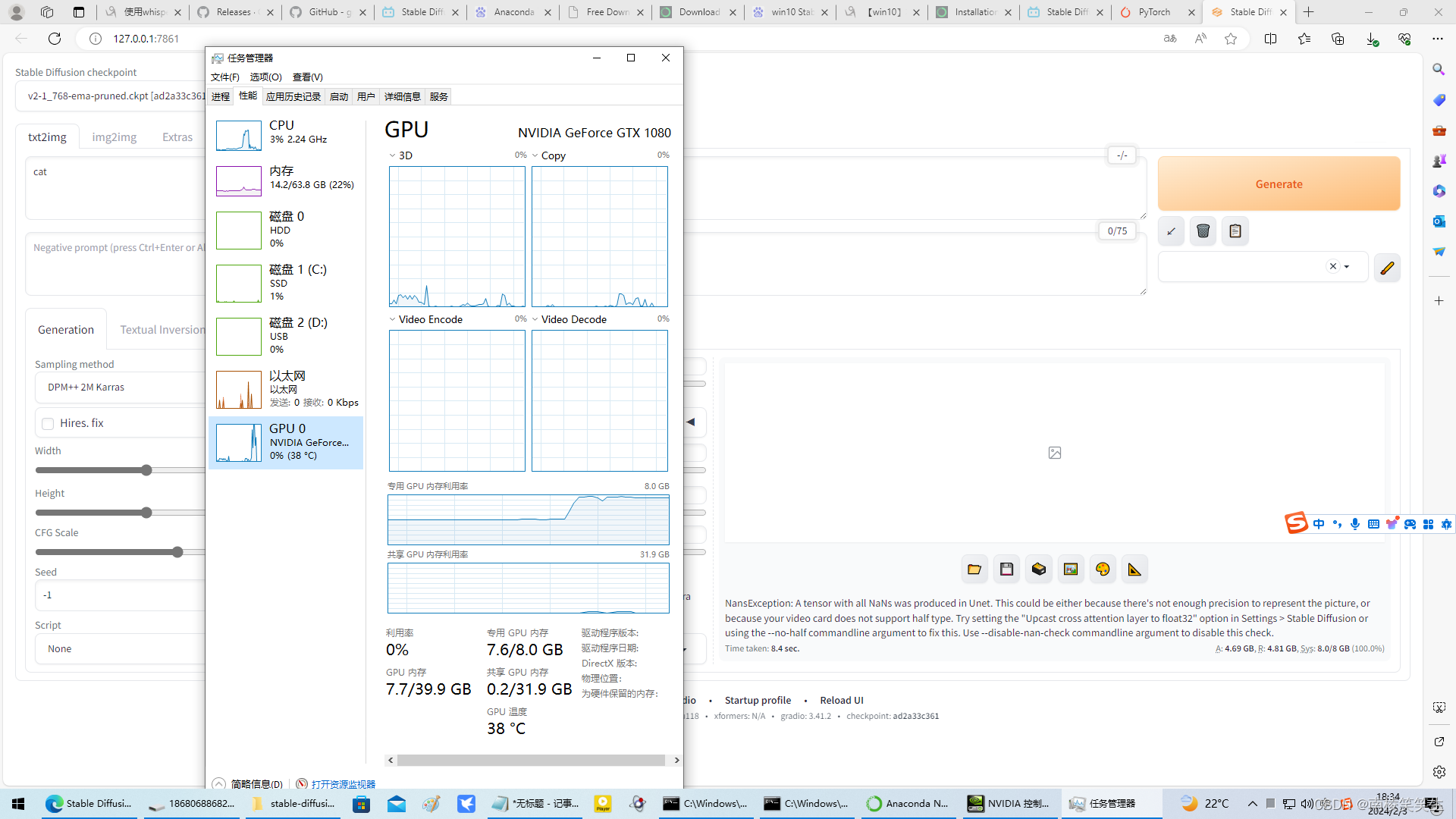
stable diffusion:
stable diffusion原理解读通俗易懂,史诗级万字爆肝长文,喂到你嘴里 – 知乎个人网站一、前言(可跳过)hello,大家好我是 Tian-Feng,今天介绍一些stable diffusion的原理,内容通俗易懂,因为我平时也玩Ai绘画嘛,所以就像写一篇文章说明它的原理,这篇文章写了真滴挺久的,如果对你有用…![]() https://zhuanlan.zhihu.com/p/634573765
https://zhuanlan.zhihu.com/p/634573765
https://zhuanlan.zhihu.com/p/645939505前言传送门: stable diffusion:Git|论文 stable–diffusion–webui:Git Google Colab Notebook部署stable–diffusion–webui:Git kaggle Notebook部署stable–diffusion–webui:Git今年AIGC实在是太火了,让人大呼…![]() https://zhuanlan.zhihu.com/p/645939505
https://zhuanlan.zhihu.com/p/645939505
stable diffusion的相关介绍与代码展示:CLIP text encoder、UNet、文生图、文生视频、inpainting
https://zhuanlan.zhihu.com/p/617134893通向AGI之路码字真心不易,求点赞! https://zhuanlan.zhihu.com/p/6424968622022年可谓是 AIGC(AI Generated Content)元年,上半年有文生图大模型DALL-E2和Stable Diffusion,下半年有OpenAI的文本对话大模型Ch…![]() https://zhuanlan.zhihu.com/p/617134893
https://zhuanlan.zhihu.com/p/617134893
AnimateDiff:
Dreambooth
Reuse-And-Diffuse
phenaki
maskgit
ViViT
IQA–VQA
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。