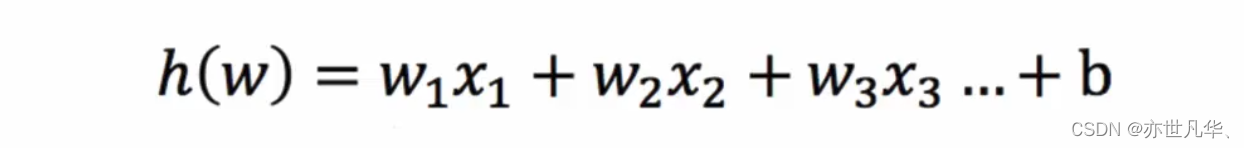本文介绍: 之前的处理方式是类别名字是文件夹名字,类别ID是按照文件夹名字的字母顺序。现在是类别名字是文件夹名字,按照文件列表名字顺序 例如。YOLOv5 分类模型 数据集加载 3 自定义类别。n02086240 类别ID是0。n02087394 类别ID是1。
flyfish
YOLOv5 分类模型 数据集加载 1 样本处理
YOLOv5 分类模型 数据集加载 2 切片处理
YOLOv5 分类模型的预处理(1) Resize 和 CenterCrop
YOLOv5 分类模型的预处理(2)ToTensor 和 Normalize
YOLOv5 分类模型 Top 1和Top 5 指标说明
YOLOv5 分类模型 Top 1和Top 5 指标实现
之前的处理方式是类别名字是文件夹名字,类别ID是按照文件夹名字的字母顺序
现在是类别名字是文件夹名字,按照文件列表名字顺序 例如
classes_name=['n02086240', 'n02087394', 'n02088364', 'n02089973', 'n02093754',
'n02096294', 'n02099601', 'n02105641', 'n02111889', 'n02115641']
n02086240 类别ID是0
n02087394 类别ID是1
代码处理是
if classes_name is None or not classes_name:
classes, class_to_idx = self.find_classes(self.root)
print("not classes_name")
else:
classes = classes_name
class_to_idx ={cls_name: i for i, cls_name in enumerate(classes)}
print("is classes_name")
完整
import time
from models.common import DetectMultiBackend
import os
import os.path
from typing import Any, Callable, cast, Dict, List, Optional, Tuple, Union
import cv2
import numpy as np
import torch
from PIL import Image
import torchvision.transforms as transforms
import sys
classes_name=['n02086240', 'n02087394', 'n02088364', 'n02089973', 'n02093754', 'n02096294', 'n02099601', 'n02105641', 'n02111889', 'n02115641']
class DatasetFolder:
def __init__(
self,
root: str,
) -> None:
self.root = root
if classes_name is None or not classes_name:
classes, class_to_idx = self.find_classes(self.root)
print("not classes_name")
else:
classes = classes_name
class_to_idx ={cls_name: i for i, cls_name in enumerate(classes)}
print("is classes_name")
print("classes:",classes)
print("class_to_idx:",class_to_idx)
samples = self.make_dataset(self.root, class_to_idx)
self.classes = classes
self.class_to_idx = class_to_idx
self.samples = samples
self.targets = [s[1] for s in samples]
@staticmethod
def make_dataset(
directory: str,
class_to_idx: Optional[Dict[str, int]] = None,
) -> List[Tuple[str, int]]:
directory = os.path.expanduser(directory)
if class_to_idx is None:
_, class_to_idx = self.find_classes(directory)
elif not class_to_idx:
raise ValueError("'class_to_index' must have at least one entry to collect any samples.")
instances = []
available_classes = set()
for target_class in sorted(class_to_idx.keys()):
class_index = class_to_idx[target_class]
target_dir = os.path.join(directory, target_class)
if not os.path.isdir(target_dir):
continue
for root, _, fnames in sorted(os.walk(target_dir, followlinks=True)):
for fname in sorted(fnames):
path = os.path.join(root, fname)
if 1: # 验证:
item = path, class_index
instances.append(item)
if target_class not in available_classes:
available_classes.add(target_class)
empty_classes = set(class_to_idx.keys()) - available_classes
if empty_classes:
msg = f"Found no valid file for the classes {', '.join(sorted(empty_classes))}. "
return instances
def find_classes(self, directory: str) -> Tuple[List[str], Dict[str, int]]:
classes = sorted(entry.name for entry in os.scandir(directory) if entry.is_dir())
if not classes:
raise FileNotFoundError(f"Couldn't find any class folder in {directory}.")
class_to_idx = {cls_name: i for i, cls_name in enumerate(classes)}
return classes, class_to_idx
def __getitem__(self, index: int) -> Tuple[Any, Any]:
path, target = self.samples[index]
sample = self.loader(path)
return sample, target
def __len__(self) -> int:
return len(self.samples)
def loader(self, path):
print("path:", path)
#img = cv2.imread(path) # BGR HWC
img=Image.open(path).convert("RGB") # RGB HWC
return img
def time_sync():
return time.time()
#sys.exit()
dataset = DatasetFolder(root="/media/a/flyfish/source/yolov5/datasets/imagewoof/val")
#image, label=dataset[7]
#
weights = "/home/a/classes.pt"
device = "cpu"
model = DetectMultiBackend(weights, device=device, dnn=False, fp16=False)
model.eval()
print(model.names)
print(type(model.names))
mean=[0.485, 0.456, 0.406]
std=[0.229, 0.224, 0.225]
def preprocess(images):
#实现 PyTorch Resize
target_size =224
img_w = images.width
img_h = images.height
if(img_h >= img_w):# hw
resize_img = images.resize((target_size, int(target_size * img_h / img_w)), Image.BILINEAR)
else:
resize_img = images.resize((int(target_size * img_w / img_h),target_size), Image.BILINEAR)
#实现 PyTorch CenterCrop
width = resize_img.width
height = resize_img.height
center_x,center_y = width//2,height//2
left = center_x - (target_size//2)
top = center_y- (target_size//2)
right =center_x +target_size//2
bottom = center_y+target_size//2
cropped_img = resize_img.crop((left, top, right, bottom))
#实现 PyTorch ToTensor Normalize
images = np.asarray(cropped_img)
print("preprocess:",images.shape)
images = images.astype('float32')
images = (images/255-mean)/std
images = images.transpose((2, 0, 1))# HWC to CHW
print("preprocess:",images.shape)
images = np.ascontiguousarray(images)
images=torch.from_numpy(images)
#images = images.unsqueeze(dim=0).float()
return images
pred, targets, loss, dt = [], [], 0, [0.0, 0.0, 0.0]
# current batch size =1
for i, (images, labels) in enumerate(dataset):
print("i:", i)
im = preprocess(images)
images = im.unsqueeze(0).to("cpu").float()
print(images.shape)
t1 = time_sync()
images = images.to(device, non_blocking=True)
t2 = time_sync()
# dt[0] += t2 - t1
y = model(images)
y=y.numpy()
#print("y:", y)
t3 = time_sync()
# dt[1] += t3 - t2
#batch size >1 图像推理结果是二维的
#y: [[ 4.0855 -1.1707 -1.4998 -0.935 -1.9979 -2.258 -1.4691 -1.0867 -1.9042 -0.99979]]
tmp1=y.argsort()[:,::-1][:, :5]
#batch size =1 图像推理结果是一维的, 就要处理下argsort的维度
#y: [ 3.7441 -1.135 -1.1293 -0.9422 -1.6029 -2.0561 -1.025 -1.5842 -1.3952 -1.1824]
#print("tmp1:", tmp1)
pred.append(tmp1)
#print("labels:", labels)
targets.append(labels)
#print("for pred:", pred) # list
#print("for targets:", targets) # list
# dt[2] += time_sync() - t3
pred, targets = np.concatenate(pred), np.array(targets)
print("pred:", pred)
print("pred:", pred.shape)
print("targets:", targets)
print("targets:", targets.shape)
correct = ((targets[:, None] == pred)).astype(np.float32)
print("correct:", correct.shape)
print("correct:", correct)
acc = np.stack((correct[:, 0], correct.max(1)), axis=1) # (top1, top5) accuracy
print("acc:", acc.shape)
print("acc:", acc)
top = acc.mean(0)
print("top1:", top[0])
print("top5:", top[1])
原文地址:https://blog.csdn.net/flyfish1986/article/details/134552641
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_2187.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。