词云图
wordcloud 是什么? 词云图,也叫文字云,是对文本中出现频率较高的“关键词”予以视觉化的展现词云图过滤掉大量的低频低质的文本信息使得浏览者只要一眼扫过文本就可领略文本的主旨。
安装
pip install wordcloud
怎么使用?
from wordcloud import WordCloud #导入
with open("new.txt","r",encoding="utf-8") as file: #打开文件
txt = file.read() #读取文件
wordcloud = WordCloud(font_path="BASKVILL.TTF", #设置属性
collocations=False,
background_color="white",
width=800,
height=600,
max_words=50).generate(txt)
#生成图片
image = wordcloud.to_image()
#展示图片
image.show()
#保存图片
wordcloud.to_file("tag.jpg")
- font_path 字体路径。如果数据文件中包含的有中文的话,font_path必须指定字体,否则中文会乱码
- collocations: 是否包括两个词的搭配,默认为True,如果为true的时候会有重复的数据,这里我不需要重复数据,所以设置为False
- width 幕布的宽度,height 幕布的高度
- max _words 要显示的词的最大个数
- generate 读取文本文件
font_path 字体的路径
从文件中读取文本
from wordcloud import WordCloud
with open("new.txt","r",encoding="utf-8") as file:
txt = file.read()
wordcloud = WordCloud(font_path="BASKVILL.TTF", #这里我用的是相对路径,自己演示的时候可以做修改
collocations=False,
background_color="white",
width=800,
height=600,
max_words=50).generate(txt)
#generate(txt)这个方法的作用是把 txt 里面的信息传给wordcloud,让他绘制词云图
#生成图片
image = wordcloud.to_image()
#展示图片
image.show()
from wordcloud import WordCloud
# 第一个是包名,第二个是类名
txt ="The awesome yellow planet of Tatooine emerges from a totaleclipse,~her two moons glowing againstl"
wordcloud = WordCloud(
# font_path="C:WindowsFontsSTFANGSO.TTF",
collocations=False, #这些也可以不用设置,默认的也可以
background_color="black",
width=800,
height=600,
max_words=50).generate(txt)
#生成图片
image = wordcloud.to_image()
#展示图片
image.show()
from wordcloud import WordCloud
# wordcloud是包名,WordCloud是类名
txt = "这是我写的第一个词云图"
wordcloud = WordCloud(
# font_path="C:WindowsFontssimhei.ttf",
collocations=False,
background_color="white",
width=800,
height=600,
max_words=50).generate(txt)
#生成图片
image = wordcloud.to_image()
#展示图片
image.show()

把路径加上再演示一下
from wordcloud import WordCloud
# wordcloud是包名,WordCloud是类名
txt = "这是我写的第一个词云图"
wordcloud = WordCloud(
font_path="C:WindowsFontssimhei.ttf",
collocations=False,
background_color="white",
width=800,
height=600,
max_words=50).generate(txt)
#生成图片
image = wordcloud.to_image()
#展示图片
image.show()

怎么解决?
方法一:手动给中文分词
from wordcloud import WordCloud
# wordcloud是包名,WordCloud是类名
txt = "这 是我 写的 第一个 词云图"
wordcloud = WordCloud(
font_path="C:WindowsFontsSTFANGSO.TTF",
collocations=False,
background_color="white",
width=800,
height=600,
max_words=50).generate(txt)
#生成图片
image = wordcloud.to_image()
#展示图片
image.show()

方法二:
中文使用词云图—需要使用jieba分词模块
- 精确模式,试图将句子最精确地切开,适合文本分析
- 全模式,把句子中所有的可以成词的词语都扫描出来速度非常快,但是不能解决歧义
- 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引警分词。
- 支持繁体分词
- 支持自定义词典
安装
pip install jieba
- jieba.cut 方法接受三个输入参数: 需要分词的字符串;cut_all 参数用来控制是否采用全模e式,HMM 参数用来控制是否使用 HMM 模型。必须需要传入的参数:需要分词的字符串
- jieba.cut_for_seaich 方法接受两个参数: 需要分词的字符串;是否使用 HMM 模型。该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细待分词的字符串可以是 unicode 或 UTF-8 字符串、GBK 字符串。注意:不建议直接输入 GBK 字符串,可能无法预料地错误解码成 UTF-8
- jieba.cut 以及 jieba.cut_for_search 返回的结构都是一个可迭代的 generator,可以使用 for 循环来获得分词后得到的每一个词语(unicode),或者用 =jieba.lcut 以及 jieba.lcut_for_search 直接返回 list
import jieba
seg_list = jieba.cut("我来到北京清华大学") # 默认是精确模式
print(" ".join(seg_list))
seg_list = jieba.cut("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 默认
print("-".join(seg_list))
一般都是以空格相连

全模式
seg_list = jieba.cut("我来到北京清华大学",cut_all=True)
print("Full Mode:" + " ".join(seg_list))
精确模式
seg_list = jieba.cut("我来到北京清华大学",cut_all=False)
print("Default Mode:" + " ".join(seg_list)) #精确模式
cut_for_search
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造")
print(" ".join(seg_list))
import jieba # 数据文件
txt ="皇后区的友好邻居变成了宇宙的,现实世界资本的侵蚀之下,只有哥谭还维持着它的地域性"
txt_list =jieba.cut(txt) #jieba.cut()返回的是一个迭代器没法直接打印
print([i for i in txt_list])

txt_str = " ".join(txt_list) #把txt_list 这个列表里的数据用空格来拼接起来,前面" "里面是什么,就拿什么拼接
还有一点要注意:
import jieba # 数据文件
txt ="皇后区的友好邻居变成了宇宙的,现实世界资本的侵蚀之下,只有哥谭还维持着它的地域性"
txt_list =jieba.cut(txt) #jieba.cut()返回的是一个迭代器没法直接打印
print(type(txt_list))
print([i for i in txt_list])
txt_str = " ".join(txt_list) #把txt_list 这个列表里的数据用空格来拼接起来,前面" "里面是什么,就拿什么拼接
print(txt_str) # 这一步无法打印是因为前面使用了迭代器,前面迭代器已经走到最后了,再往后就没有了
from wordcloud import WordCloud
import jieba
import jieba.analyse
txt ="皇后区的友好邻居变成了宇宙的,现实世界资本的侵蚀之下,只有哥谭还维持着它的地域性"
txt_list = jieba.cut(txt) # 分词
txt_str = " ".join(txt_list) # 拼接
wordcloud = WordCloud(
font_path="C:WindowsFontsSTFANGSO.TTF",
collocations=False,
background_color="white",
width=800,
height=600,
max_words=50).generate(txt_str) #传入
#生成图片
image = wordcloud.to_image()
#展示图片
image.show()

但是它还有问题:像 的 了 着 这些我们不需要,怎么处理???
jieba.analyse的使用: 提取关键字
注意事项:必须引入的使用就引入jieba.analyse,才能使用. 不能导入jieba,然后使用jieba.analyse,会报错
试一试?
import jieba
# import jieba.analyse
text ="皇后区的友好邻居变成了宇宙的,现实世界资本的侵蚀之下,只有哥谭还维持着它的地域性"
seg_list = jieba.analyse.extract_tags(text, allowPOS=("v"))
print("analysea extract allowPOS:"+ str((seg_list))) # 分析提取

提取名词
import jieba
import jieba.analyse
text ="皇后区的友好邻居变成了宇宙的,现实世界资本的侵蚀之下,只有哥谭还维持着它的地域性"
seg_list = jieba.analyse.extract_tags(text, allowPOS=("n"))
print("analysea extract allowPOS:"+ str((seg_list))) # 分析提取
提取动词
import jieba
import jieba.analyse
text ="皇后区的友好邻居变成了宇宙的,现实世界资本的侵蚀之下,只有哥谭还维持着它的地域性"
seg_list = jieba.analyse.extract_tags(text, allowPOS=("v"))
print("analysea extract allowPOS:"+ str((seg_list))) # 分析提取
不设置词性
import jieba.analyse
text ="皇后区的友好邻居变成了宇宙的,现实世界资本的侵蚀之下,只有哥谭还维持着它的地域性"
seg_list = jieba.analyse.extract_tags(text)
print("analysea extract allowPOS:"+ str((seg_list))) # 分析提取
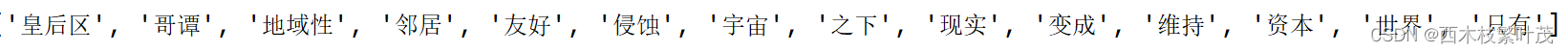
from wordcloud import WordCloud
import jieba.analyse
text ="皇后区的友好邻居变成了宇宙的,现实世界资本的侵蚀之下,只有哥谭还维持着它的地域性"
seg_list = jieba.analyse.extract_tags(text)
#将列表拼接成字符串
txt_str = " ".join(seg_list)
wordcloud = WordCloud(
font_path="C:WindowsFontsSTFANGSO.TTF",
collocations=False,
background_color="white",
width=800,
height=600,
max_words=50).generate(txt_str)
#生成图片
image = wordcloud.to_image()
#展示图片
image.show()

对比上面生成的没有像 的 了 着 的那些词了,相比之下好很多
综合案例
from wordcloud import WordCloud
import jieba.analyse
text ="皇后区的友好邻居变成了宇宙的,现实世界资本的侵蚀之下,只有哥谭还维持着它的地域性"
seg_list = jieba.analyse.extract_tags(text,topK=3,allowPOS=("v"))
#将列表拼接成字符串
txt_str = " ".join(seg_list)
wordcloud = WordCloud(
font_path="C:WindowsFontsSTFANGSO.TTF",
collocations=False,
background_color="white",
width=800,
height=600,
max_words=50).generate(txt_str)
#生成图片
image = wordcloud.to_image()
#展示图片
image.show()

原文地址:https://blog.csdn.net/m0_73282576/article/details/130724153
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_21892.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。