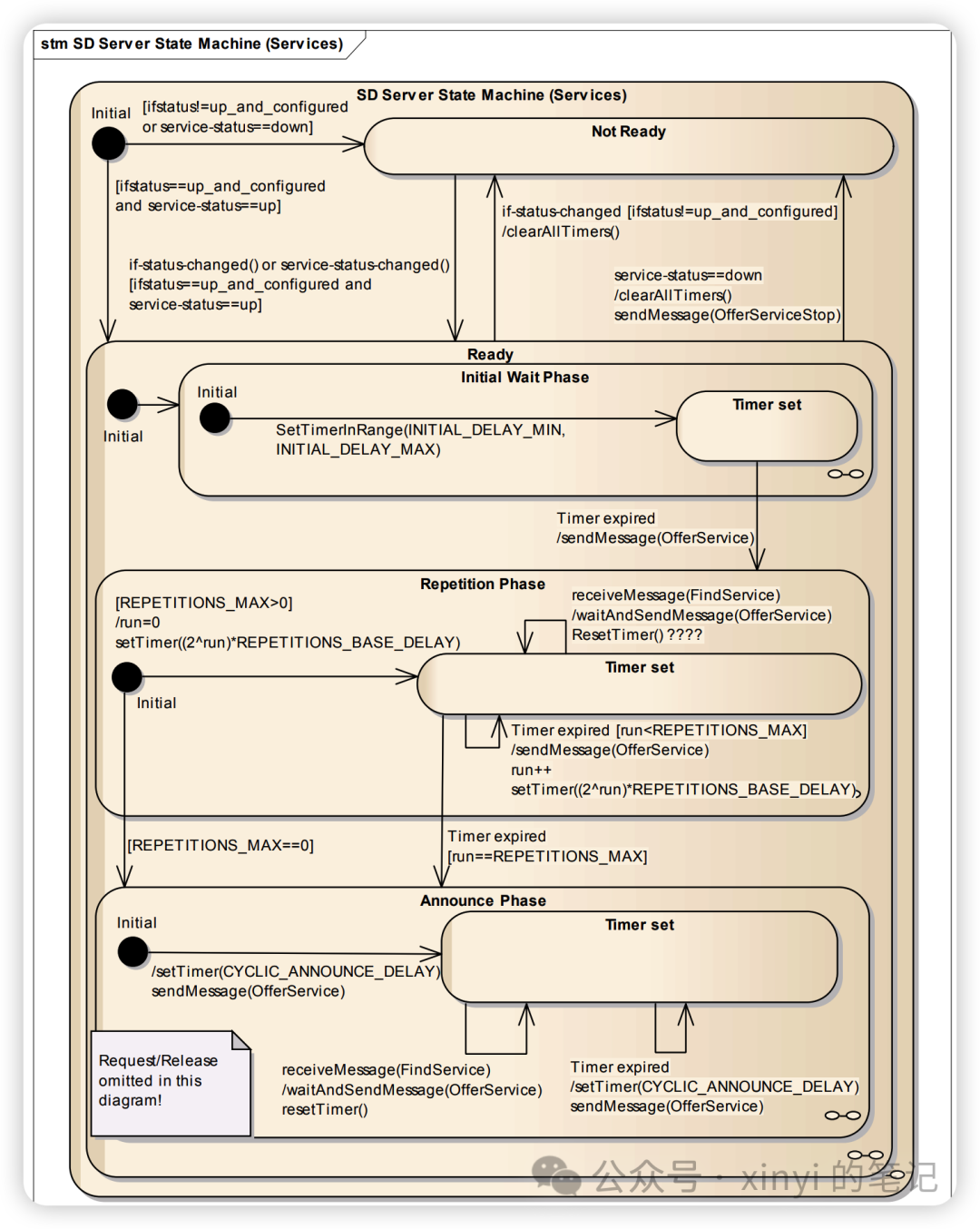
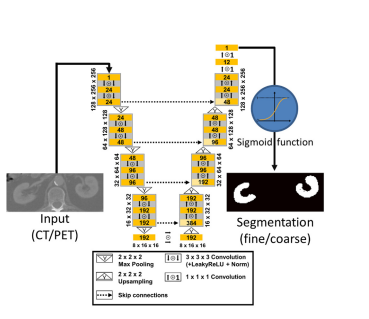
本文介绍: 对通用分割,训练阶段和推理阶段不太一样。Os是解码的分割查询特征(segmentation query features),Op是解码的目标视觉查询特征(target visual prompt features),M、B是预测的mask和box,Cg 和 Cr 是预测的通用分割和参考分割的匹配分数,这两个分数通过PromptClassifier计算Os和Op的相似性得到。对于通用分割的推理阶段采样策略,在推理阶段,以COCO数据集为例,基于训练阶段建立的所有语义类别的掩码提示,预提取相应的视觉提示特征。
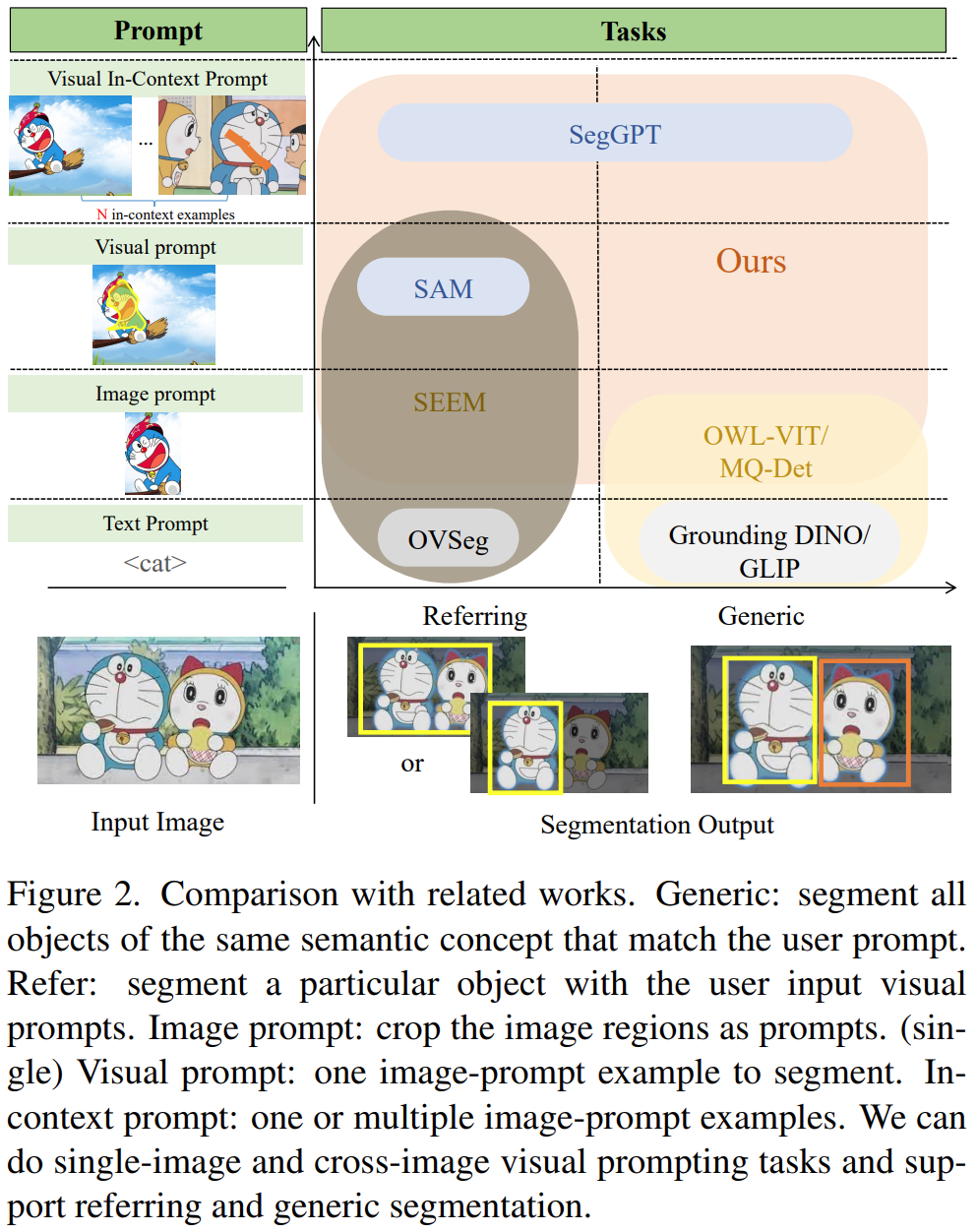
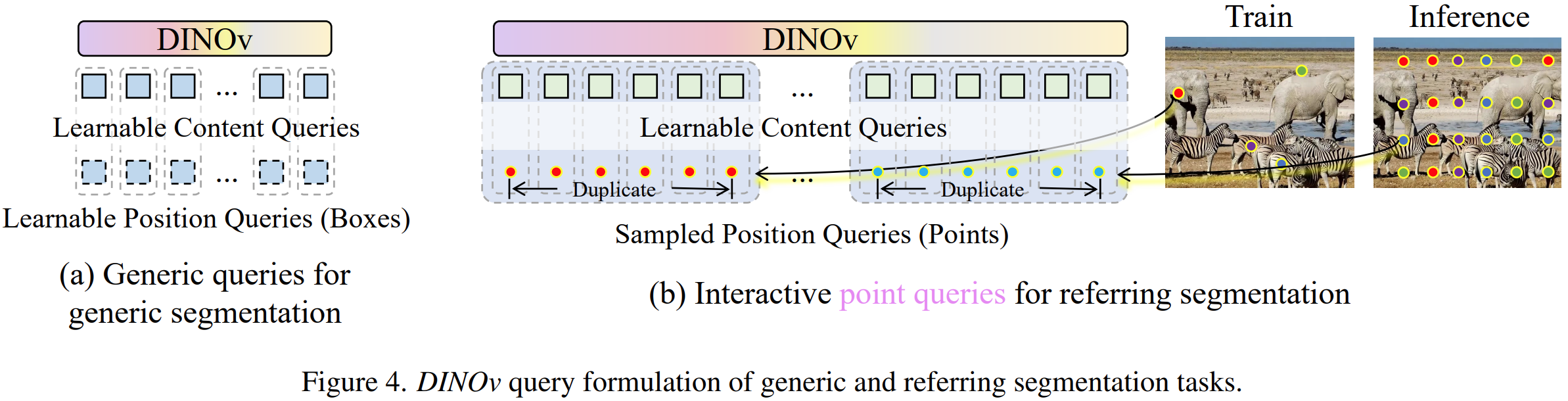
左边一列是prompt类型,右边一列是使用各个类型的prompt的模型。这些模型有分为两大类:Generic和Refer,通用分割和参考分割。Generic seg 是分割和提示语义概念一样的所有的物体,也就是提示是狮子,就把图片中所有狮子分割出来;Refer seg 是根据用户提示分割特定的物体,也就是提示是狗狗的一只耳朵,分割出来的也是狗狗的耳朵。可以看到,本文DINOv填补了视觉提示(Visual prompt)方法的空白。


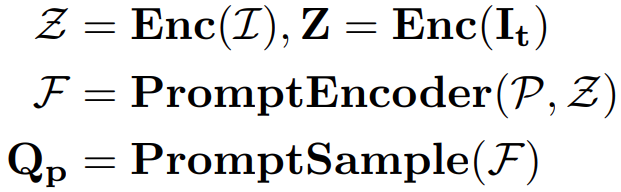





声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。