1.导包
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
import pandas as pdmy_data=pd.read_excel("D:/棒/数据挖掘/basket.xlsx")
df_data=my_data.iloc[:,7:].copy()
df_data.head()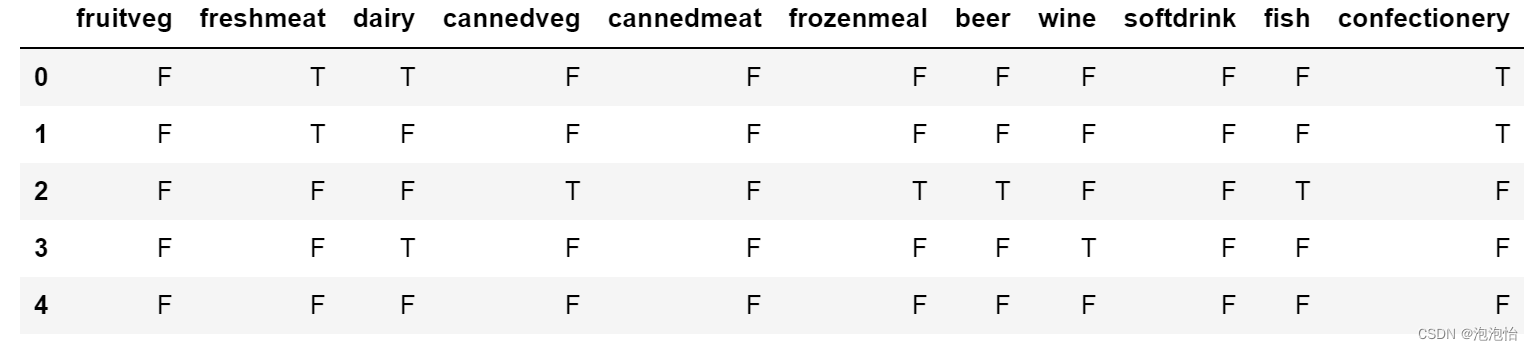
4.数据处理:
dict_data={'F':False,'T':True}
df_data['fruitveg']=df_data['fruitveg'].map(dict_data)
df_data['freshmeat']=df_data['freshmeat'].map(dict_data)
df_data['dairy']=df_data['dairy'].map(dict_data)
df_data['cannedveg']=df_data['cannedveg'].map(dict_data)
df_data['cannedmeat']=df_data['cannedmeat'].map(dict_data)
df_data['frozenmeal']=df_data['frozenmeal'].map(dict_data)
df_data['beer']=df_data['beer'].map(dict_data)
df_data['wine']=df_data['wine'].map(dict_data)
df_data['softdrink']=df_data['softdrink'].map(dict_data)
df_data['fish']=df_data['fish'].map(dict_data)
df_data['confectionery']=df_data['confectionery'].map(dict_data)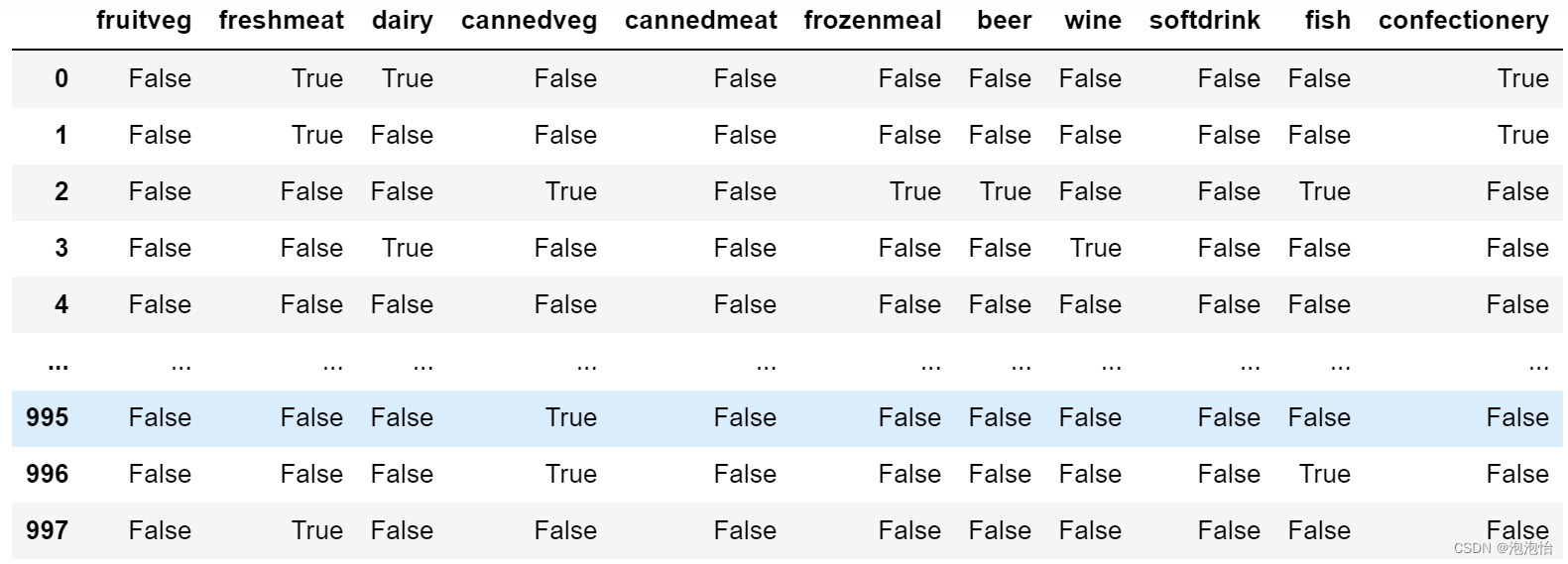
frequent_itemsets = apriori(df_data,min_support=0.1,use_colnames= True)
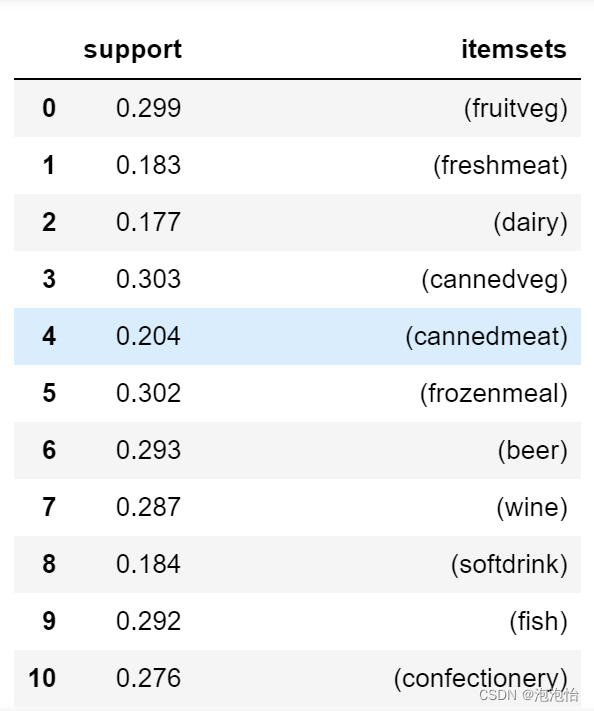
6.
rules = association_rules(frequent_itemsets,metric = ‘confidence‘,min_threshold = 0.15)
#设置最小提升度
rules = rules.drop(rules[rules.lift <1.0].index)
rules.rename(columns = {‘antecedents‘:’from’,’consequents‘:’to‘,’support‘:’sup’,’confidence‘:’conf‘},inplace = True)
结果如下:
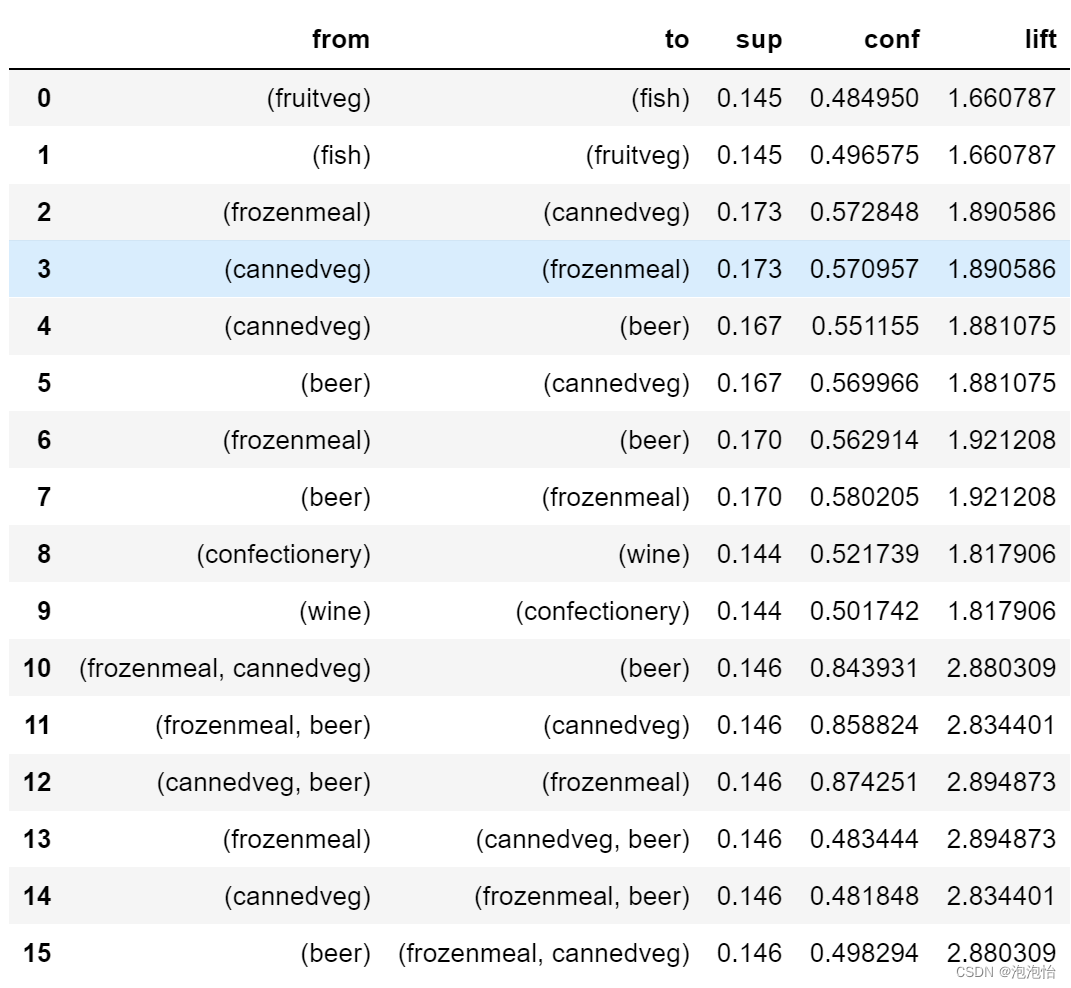
原文地址:https://blog.csdn.net/m0_72662900/article/details/126043494
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_22182.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。

![[Lucene]核心类和概念介绍](http://www.7code.cn/wp-content/uploads/2023/11/ee6748cbc735e6105405f8a984d954c804b93f34bc916-Z0IqTf_fw1200.png)