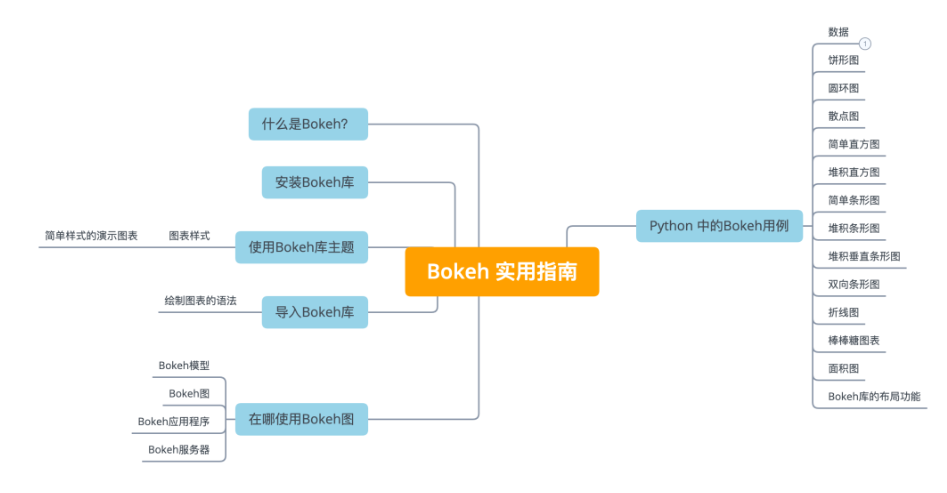
本文介绍: 本文描述爬取250的电影详细信息,包括对电影名、评分、评论人数、电影名言、导演演员信息、电影年份、电影国家、电影类型等详细爬取;并且针对爬取的数据使用Numpy、pandas等进行了数据处理、拆分、分组等操作,最后使用pyechatrs对数据进行柱状图、实时排序图、世界地图、饼图等可视化展示。
“与众不同”的TOP250详细数据采集,pyecharts世界地图多维可视化展示
前言:
本文描述爬取逗瓣250的电影详细信息,包括对电影名、评分、评论人数、电影名言、导演演员信息、电影年份、电影国家、电影类型等详细爬取;
并且针对爬取的数据使用Numpy、pandas等进行了数据处理、拆分、分组等操作,最后使用pyechatrs对数据进行柱状图、实时排序图、世界地图、饼图等可视化展示。
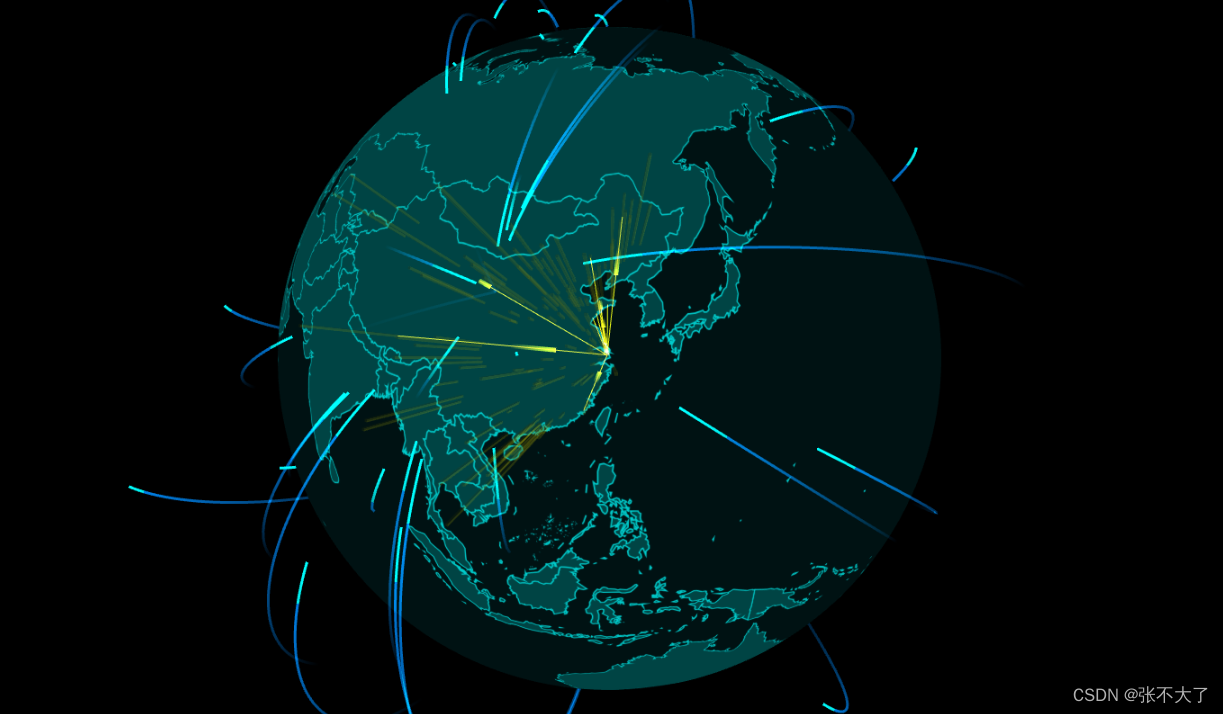
项目pyecharts可视化展示(部分)世界地图、实时排序图等:
1929至2013年每年发布的电影根据评分排序展示:

电影发布国家统计展示:

爬虫代码(.py文件):
数据处理可视化代码(.ipynb文件):
数据处理:
数据处理结果:

pyecharts可视化:
1、评价数最多的电影TOP10

2、评分排名可视化

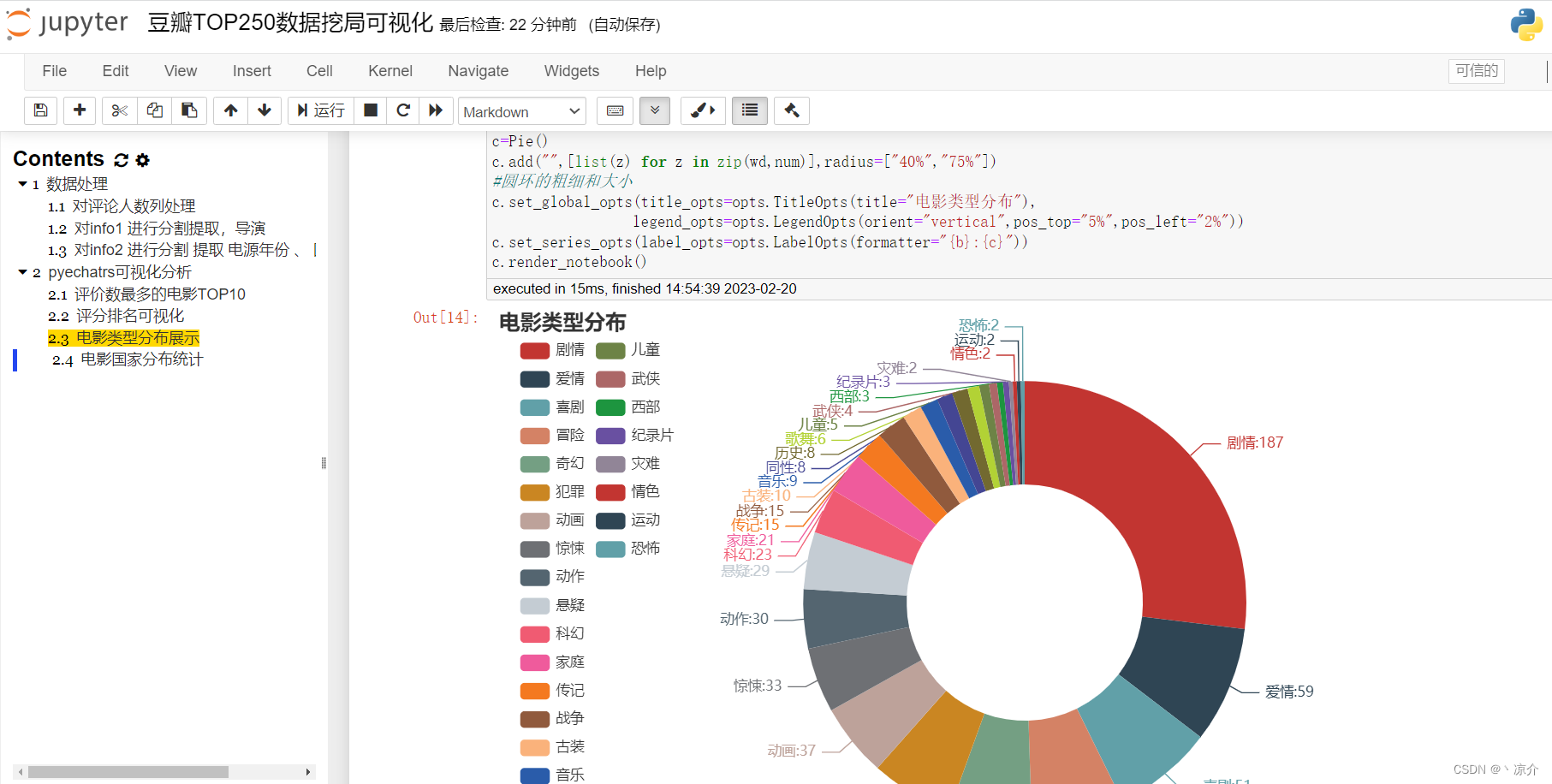
3、 电影类型分布展示

4、电影国家分布统计

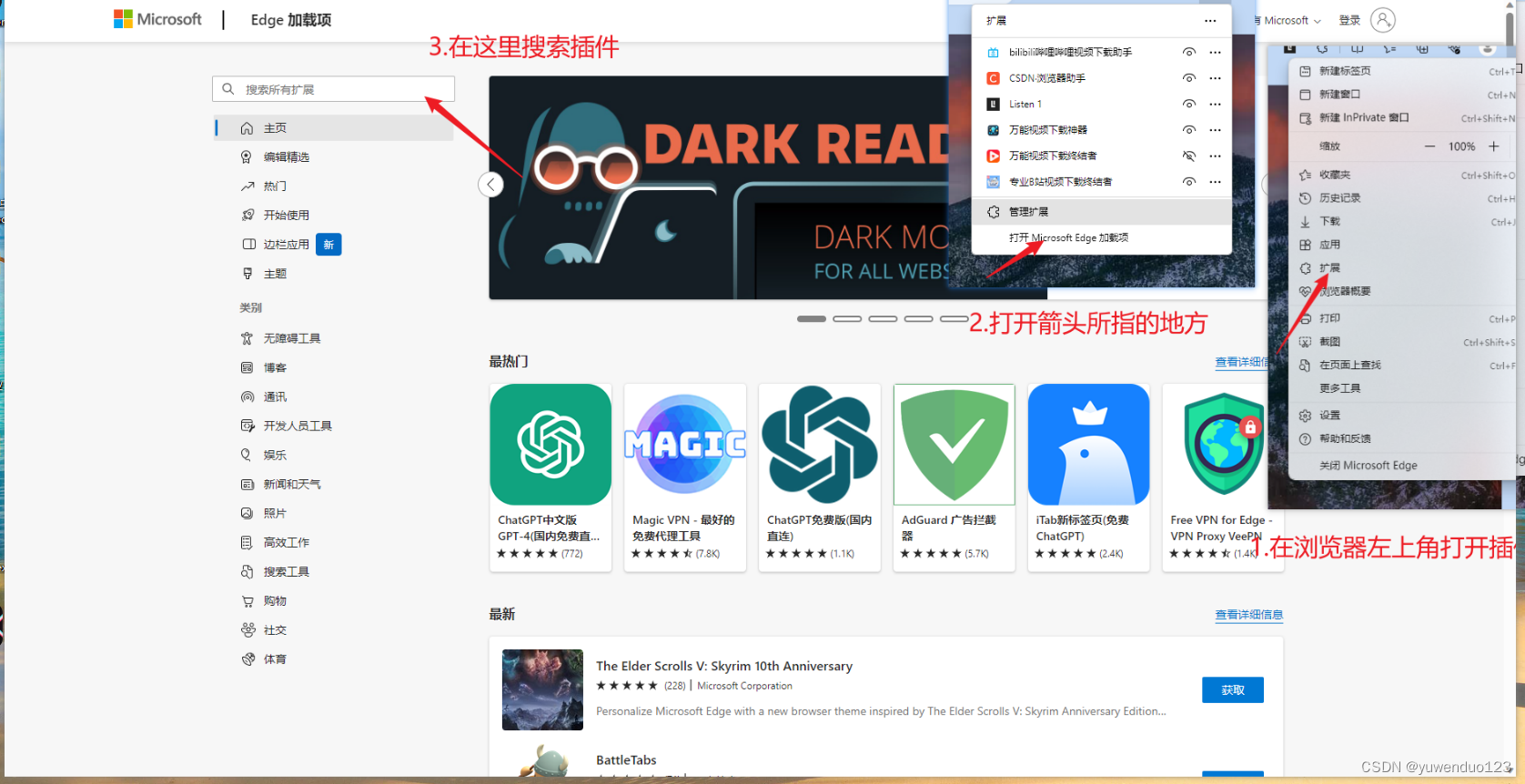
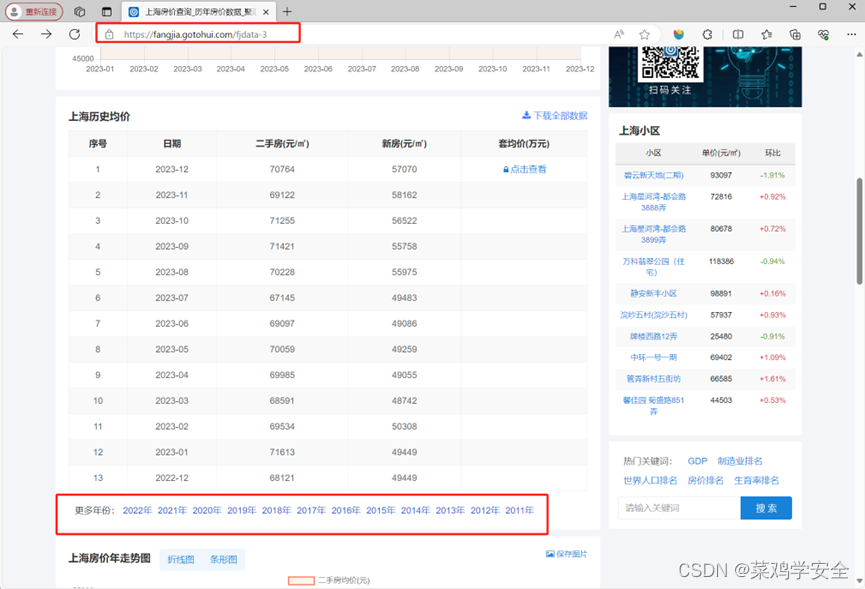
源码获取:
(求求点个关注呀,您的关注点赞是我持续创作的动力。求求点个关注呀,您的关注点赞是我持续创作的动力。求求点个关注呀,您的关注点赞是我持续创作的动力)

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。