js反编译的代码需要解密之类的,直接给我干蒙圈了,借助selenium可以直接获取到调式工具中的源码,可以获取渲染后的链接,然后将链接交给下载函数(使用异步提高效率)即可。
后续学习完js反编译的话,我会再写一篇教学,介绍js反编译爬取。
主要还是,获取当前页面之后,找到按钮点击下一次,如果下载过程中出现验证码的话,可以加一个判断,使用超级鹰或者是图鉴的python脚本,就可以通过验证了,但是每次验证是需要消耗题分。如果不想花钱的可以找一个训练成功的模型下载使用。
代码:
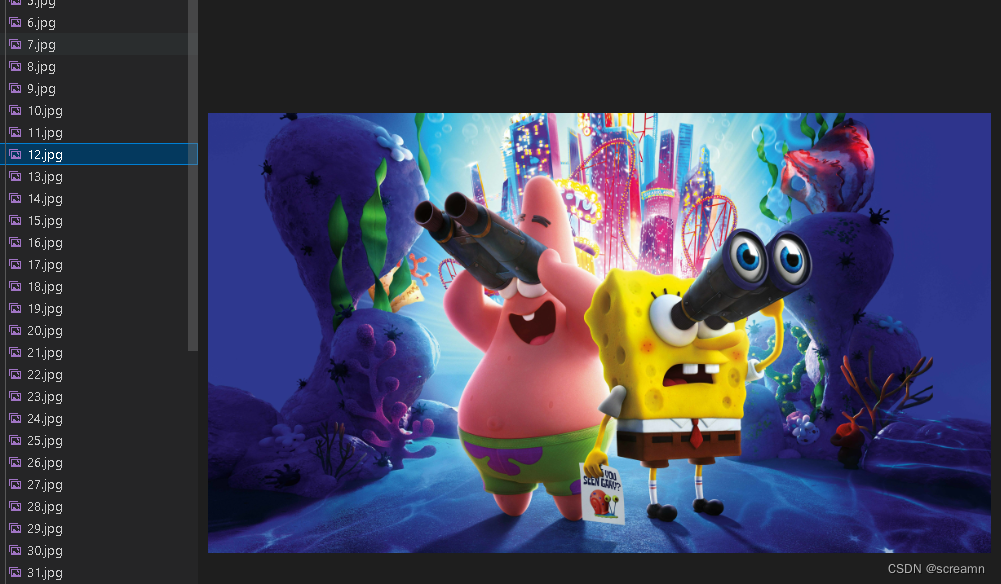
效果:
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。