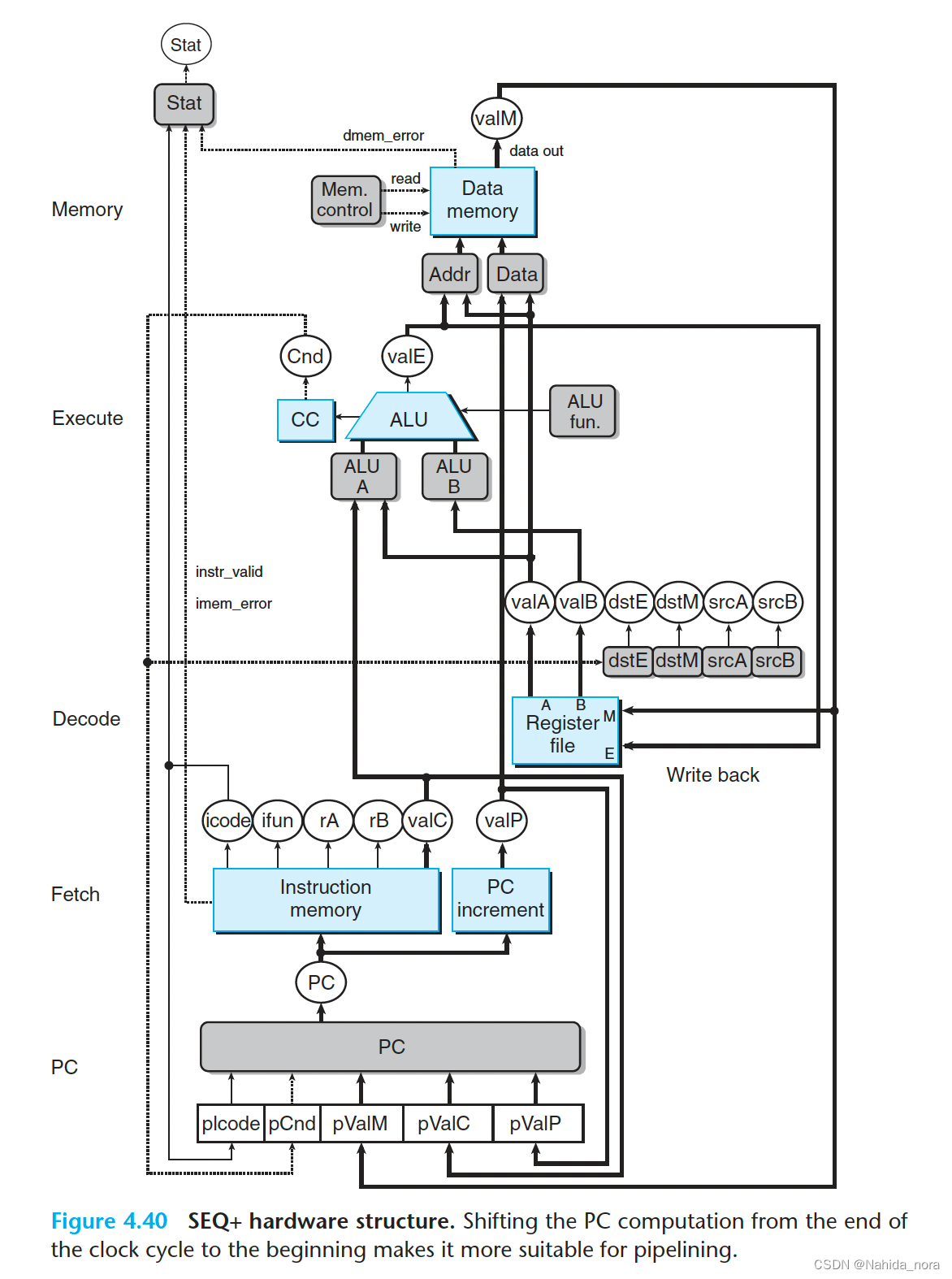
本文介绍: 在PIPE-中的一个块,在SEQ+中以完全相同的形式不存在,这个块被标记为“Select A”,位于解码阶段。这些指令中没有一个需要从寄存器文件中读取的值。在SEQ+的各个阶段之间插入了流水线寄存器,并稍微重新排列了信号,得到了PIPE−处理器,其中名称中的“−”表示该处理器的性能略低于我们的最终处理器设计。然后,当新的时钟周期开始时,这些值通过完全相同的逻辑传播,以计算当前指令的PC。在流水线设计中的目标是在每个时钟周期发出一个新指令,这意味着在每个时钟周期,一个新指令进入执行阶段,并最终完成。
General Principles of Pipelining
Computational Pipelines
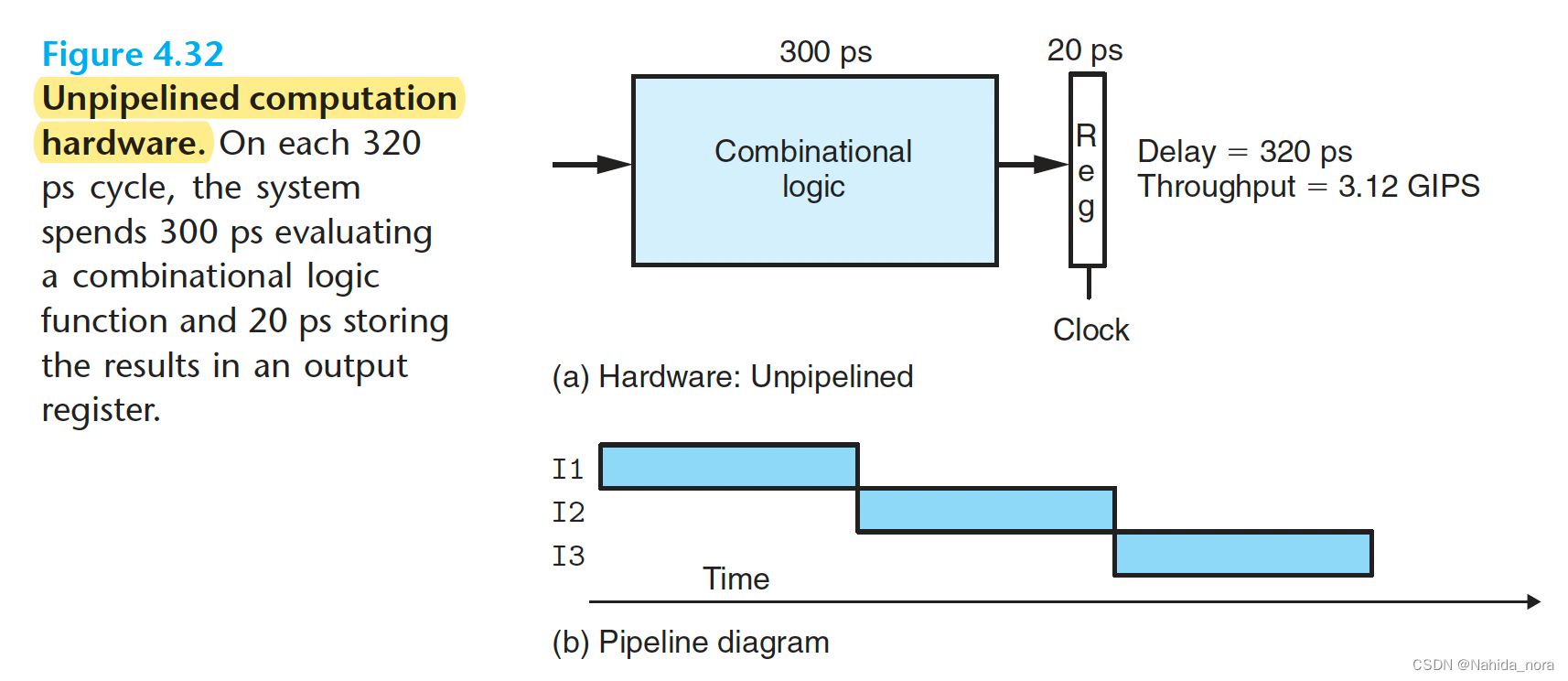
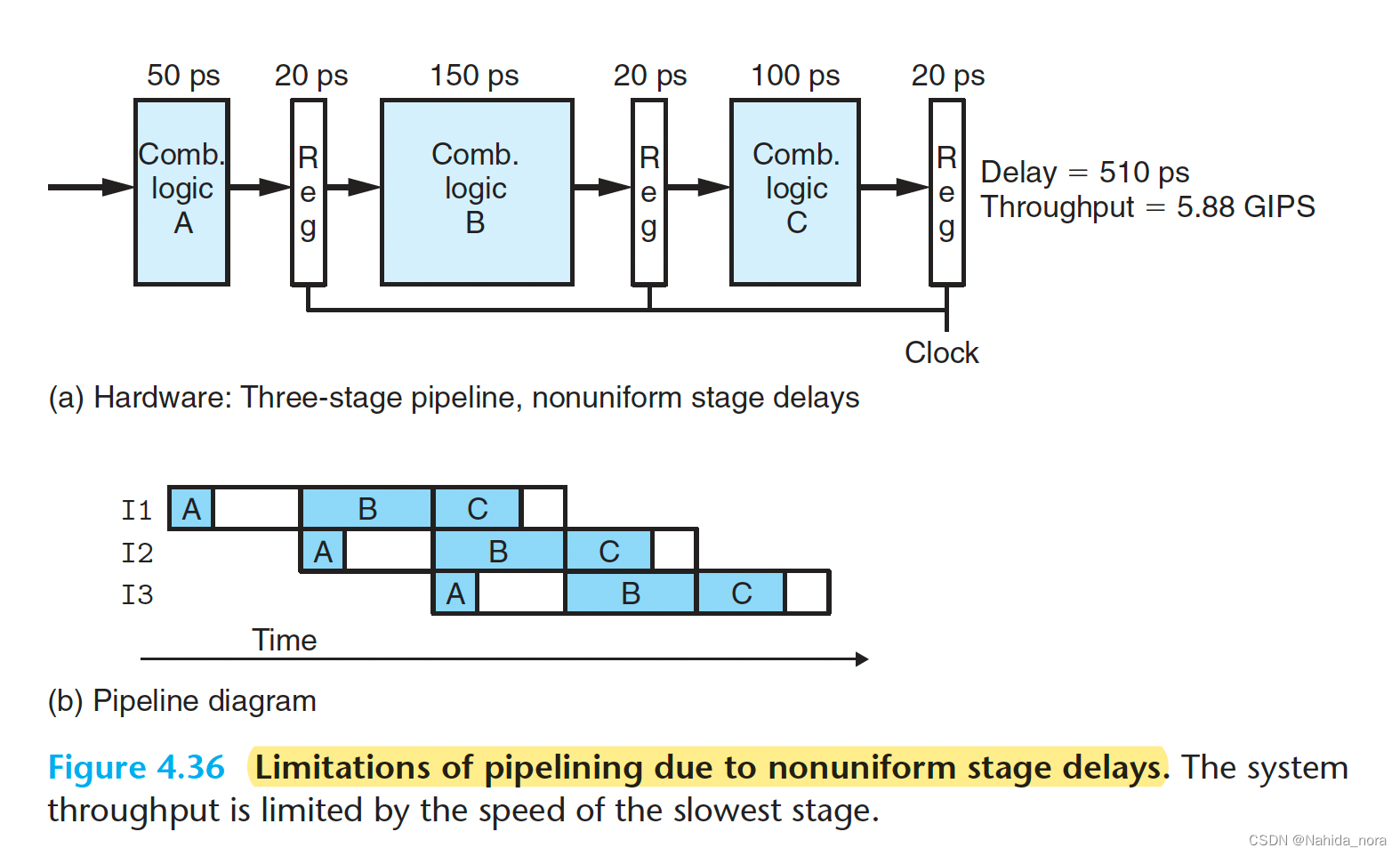
circuit delays in units of picoseconds (abbreviated “ps”), or 10−12 seconds.

throughput in units of giga–instructions per second (abbreviated GIPS), or billions of instructions per second.
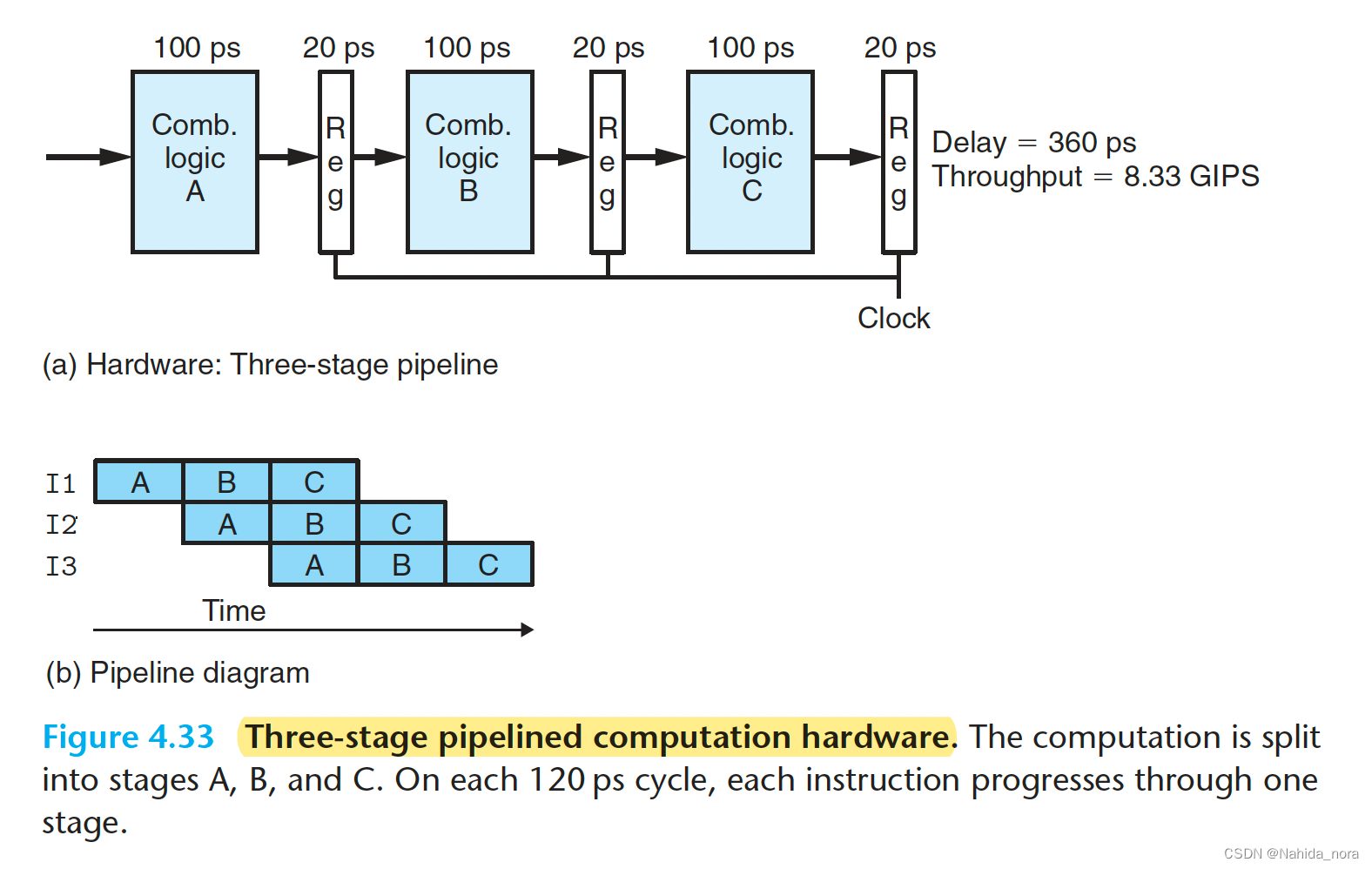
A Detailed Look at Pipeline Operation
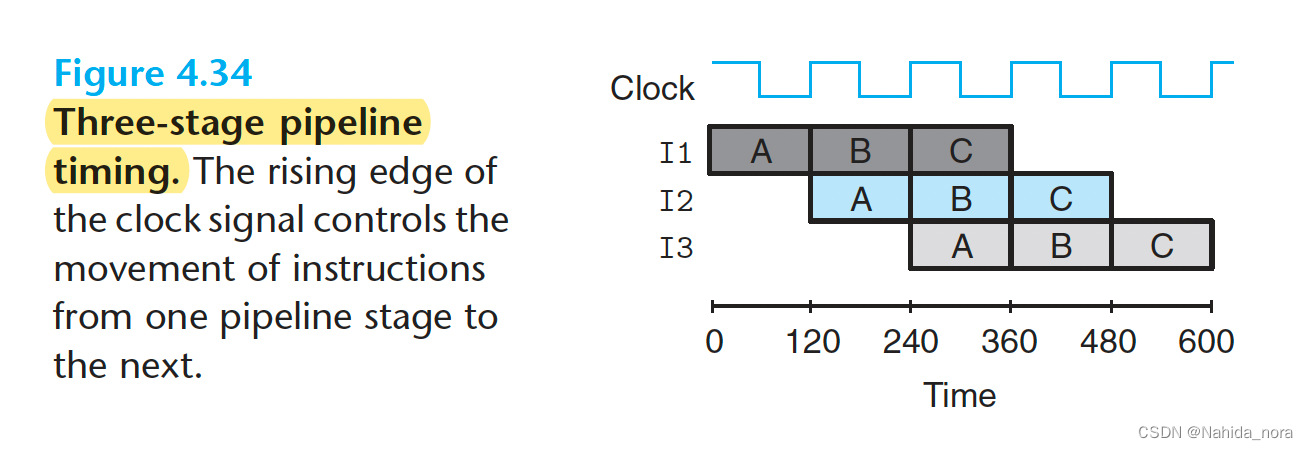

Limitations of Pipelining
Diminishing Returns of Deep Pipelining

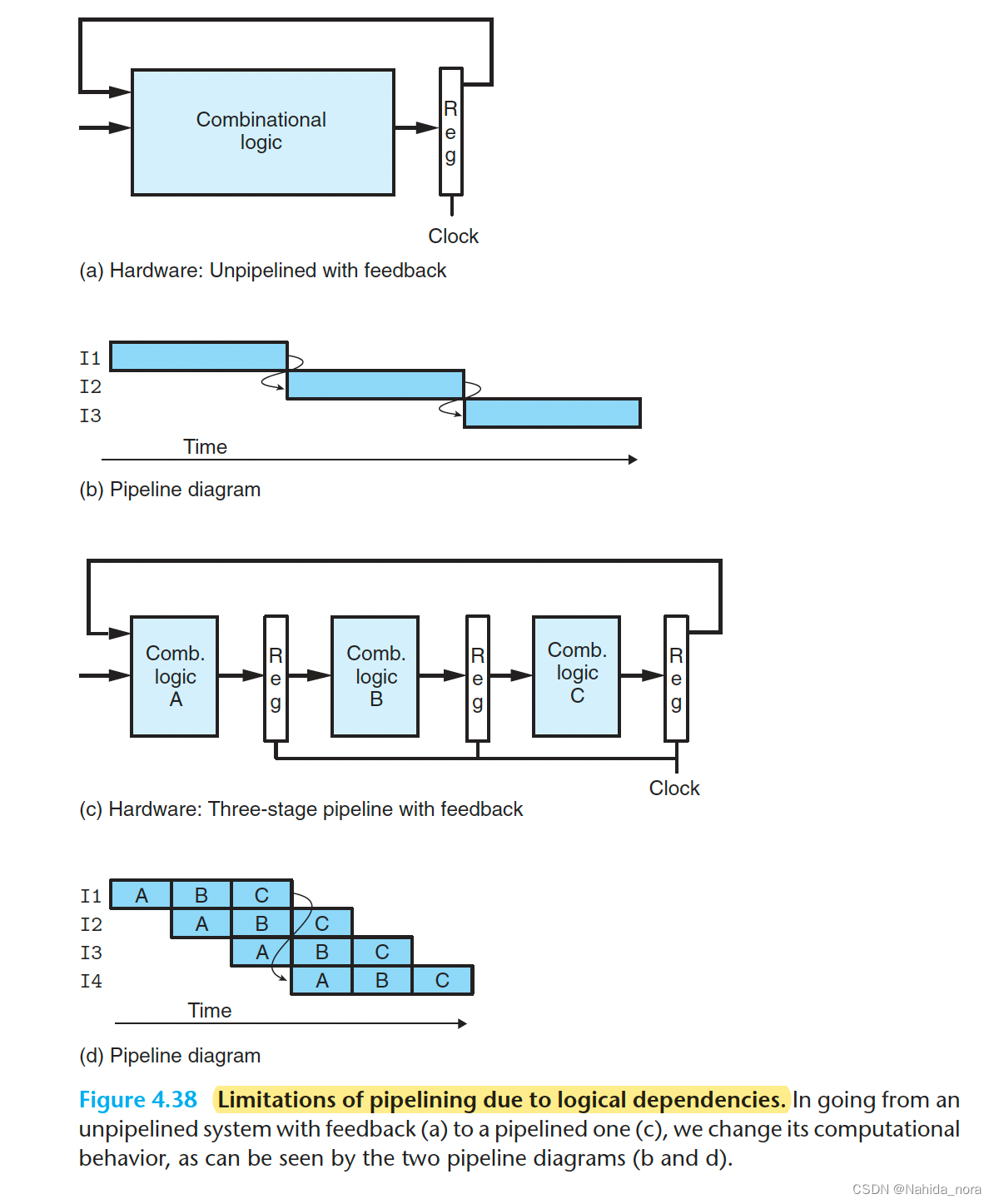
Pipelining a System with Feedback


Pipelined Y86-64 Implementations

SEQ+: Rearranging the Computation Stages

Inserting Pipeline Registers
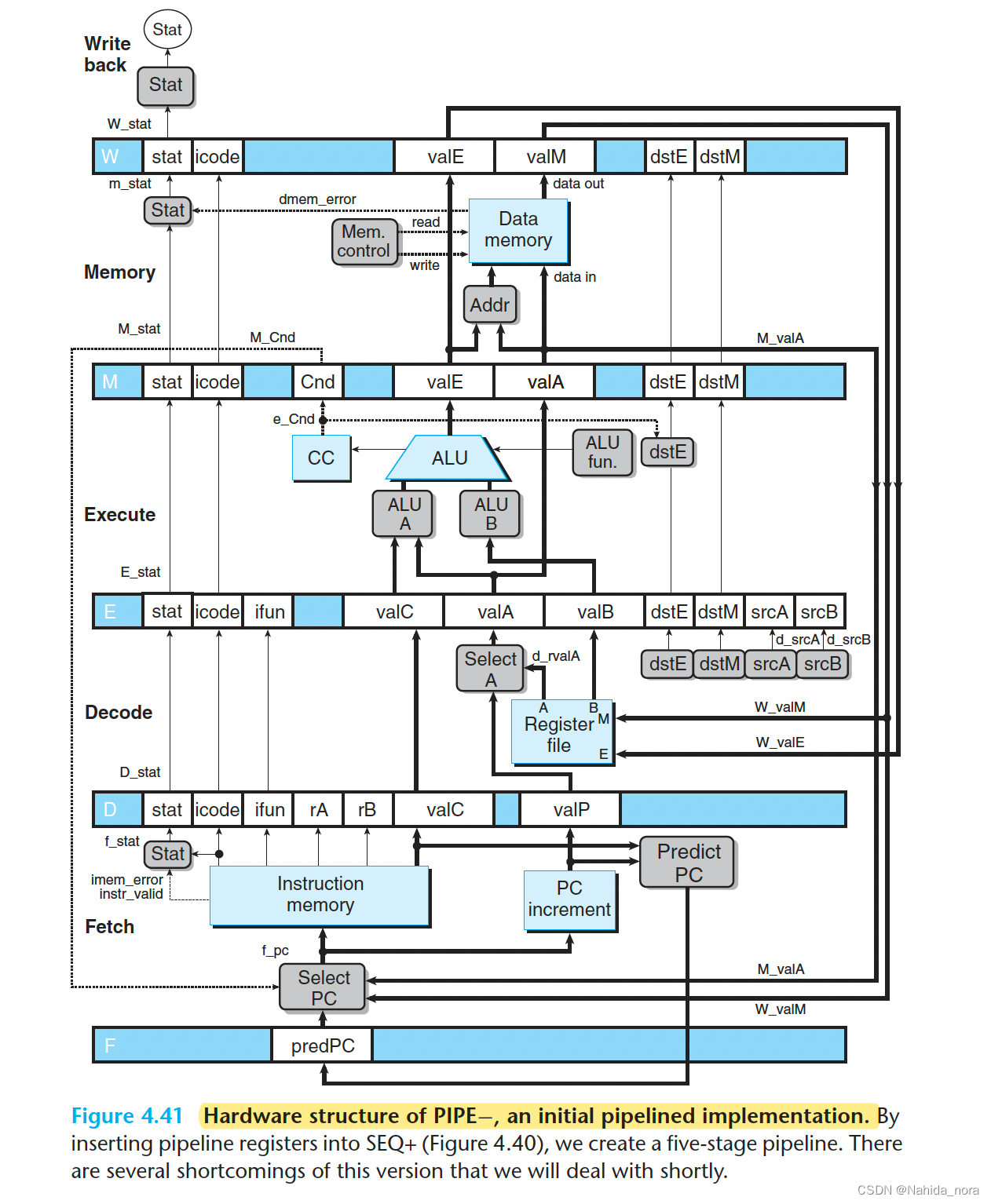
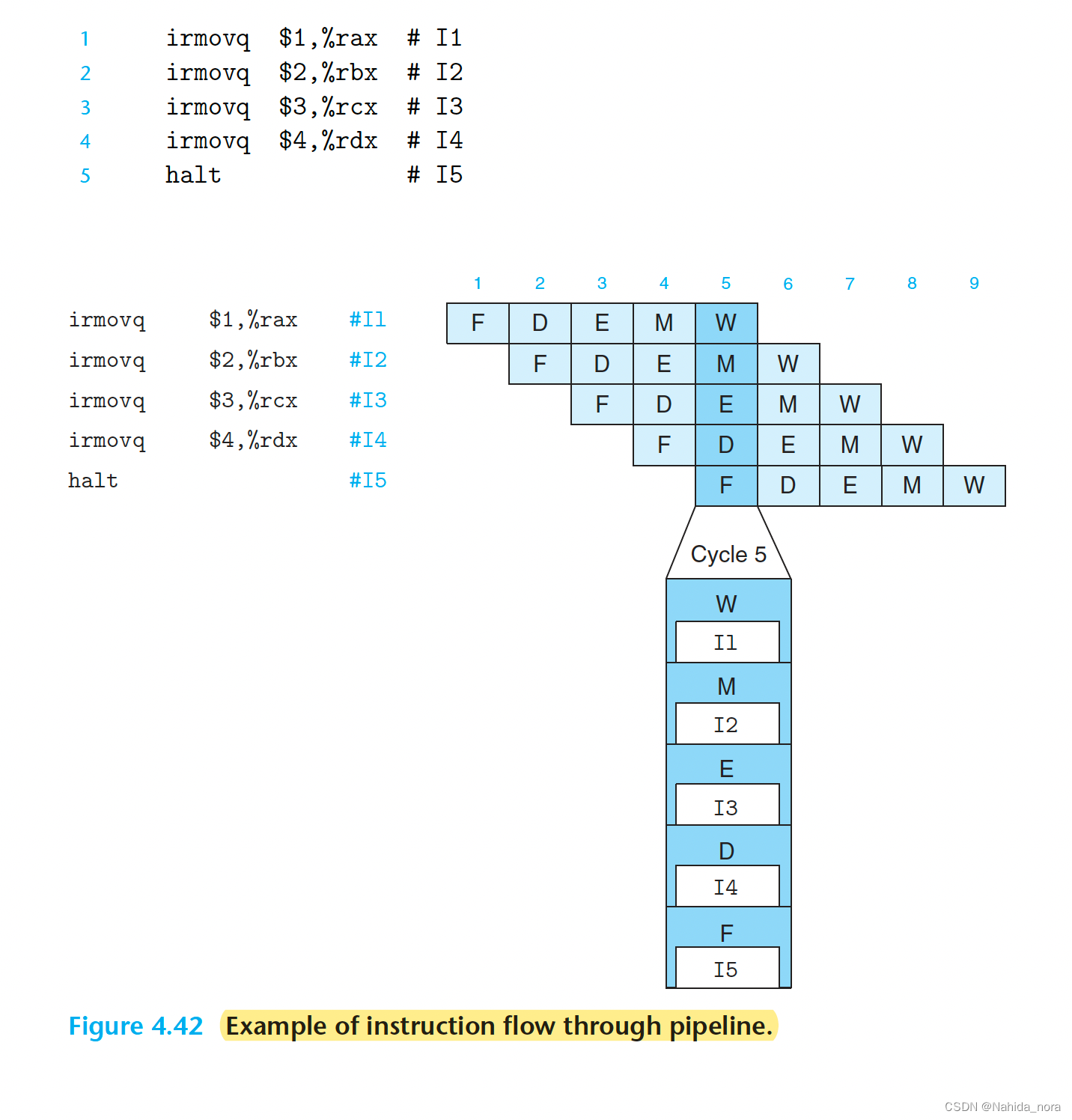
Rearranging and Relabeling Signals

Next PC Prediction

Pipeline Hazards
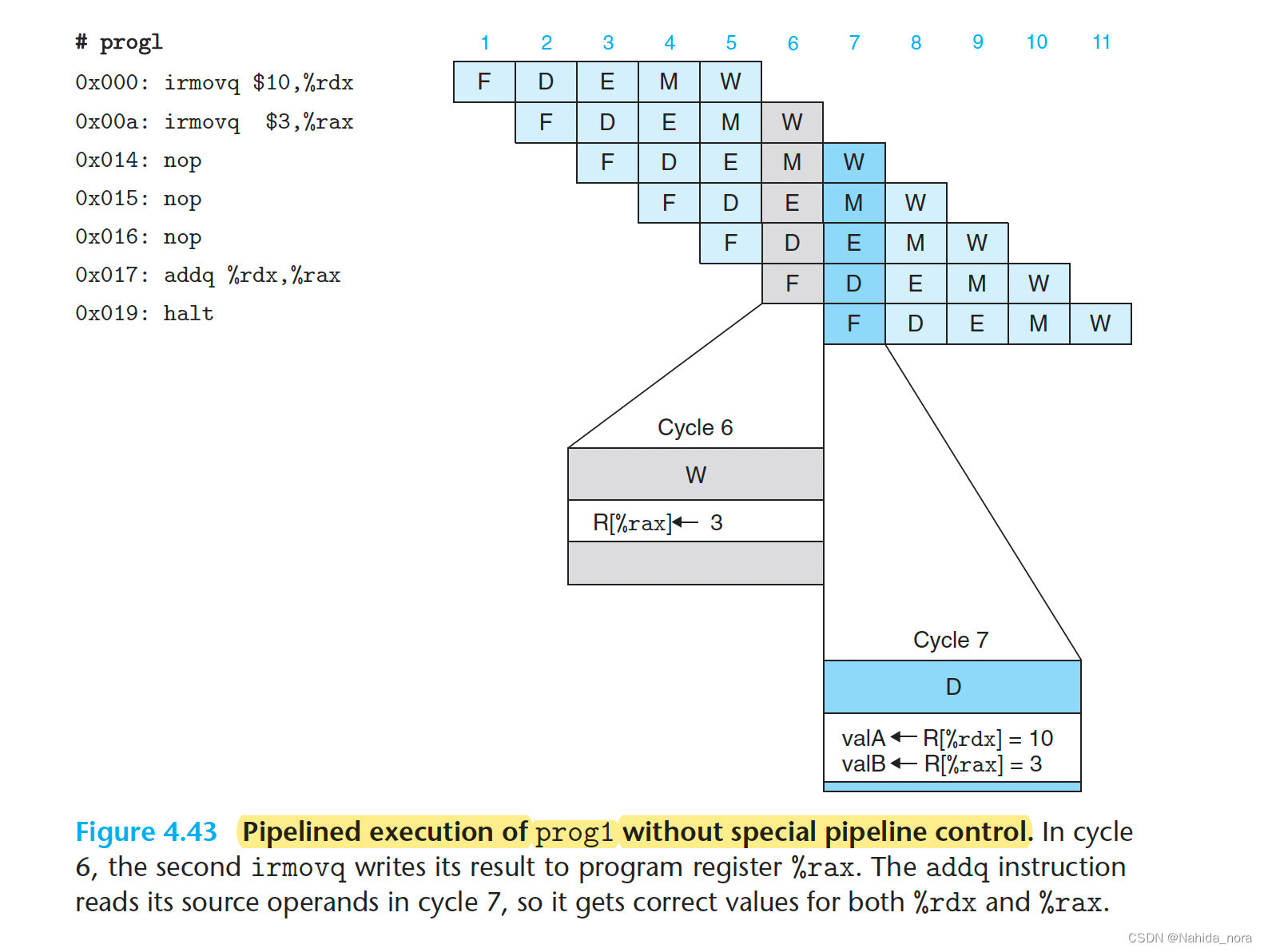



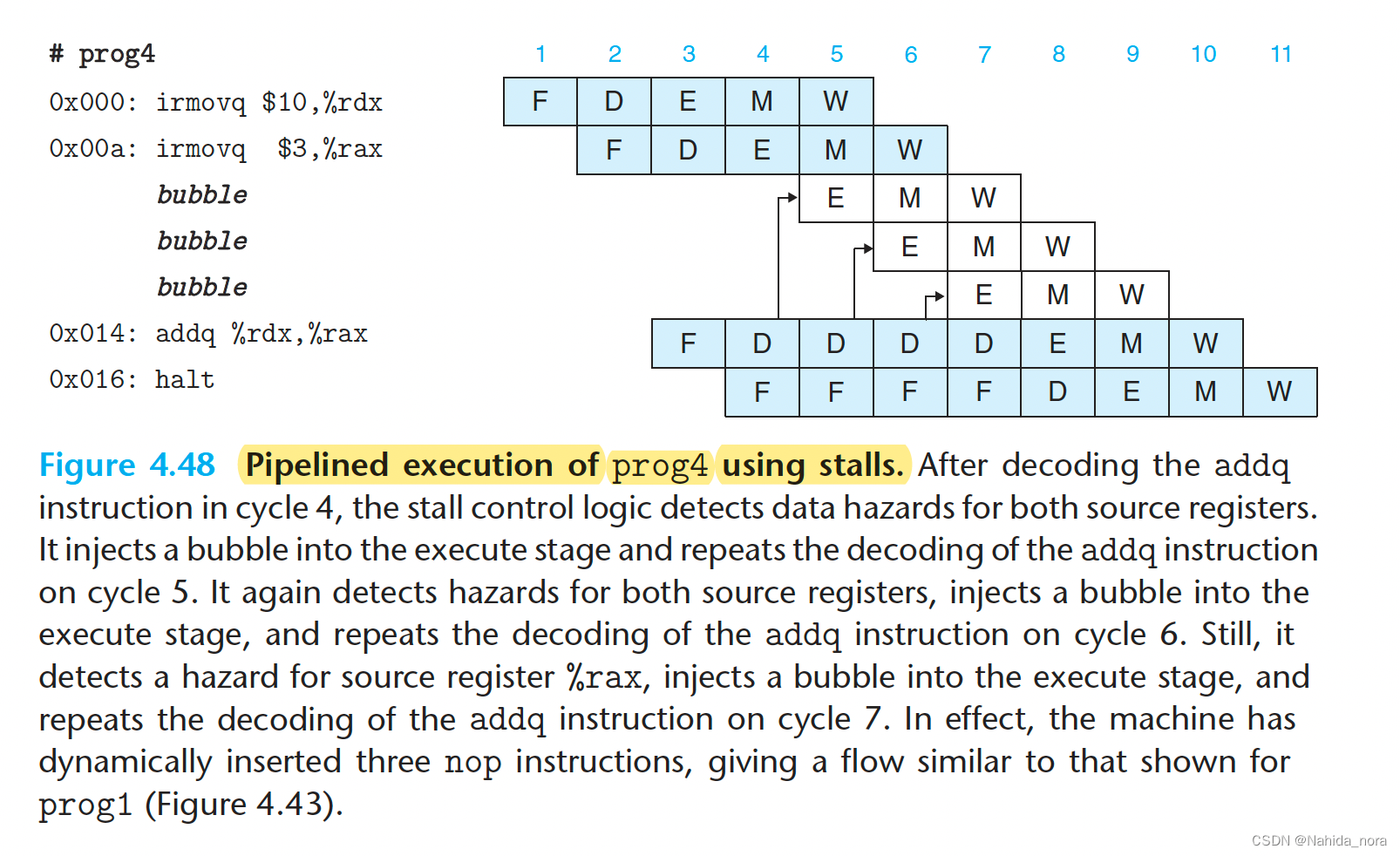
Avoiding Data Hazards by Stalling

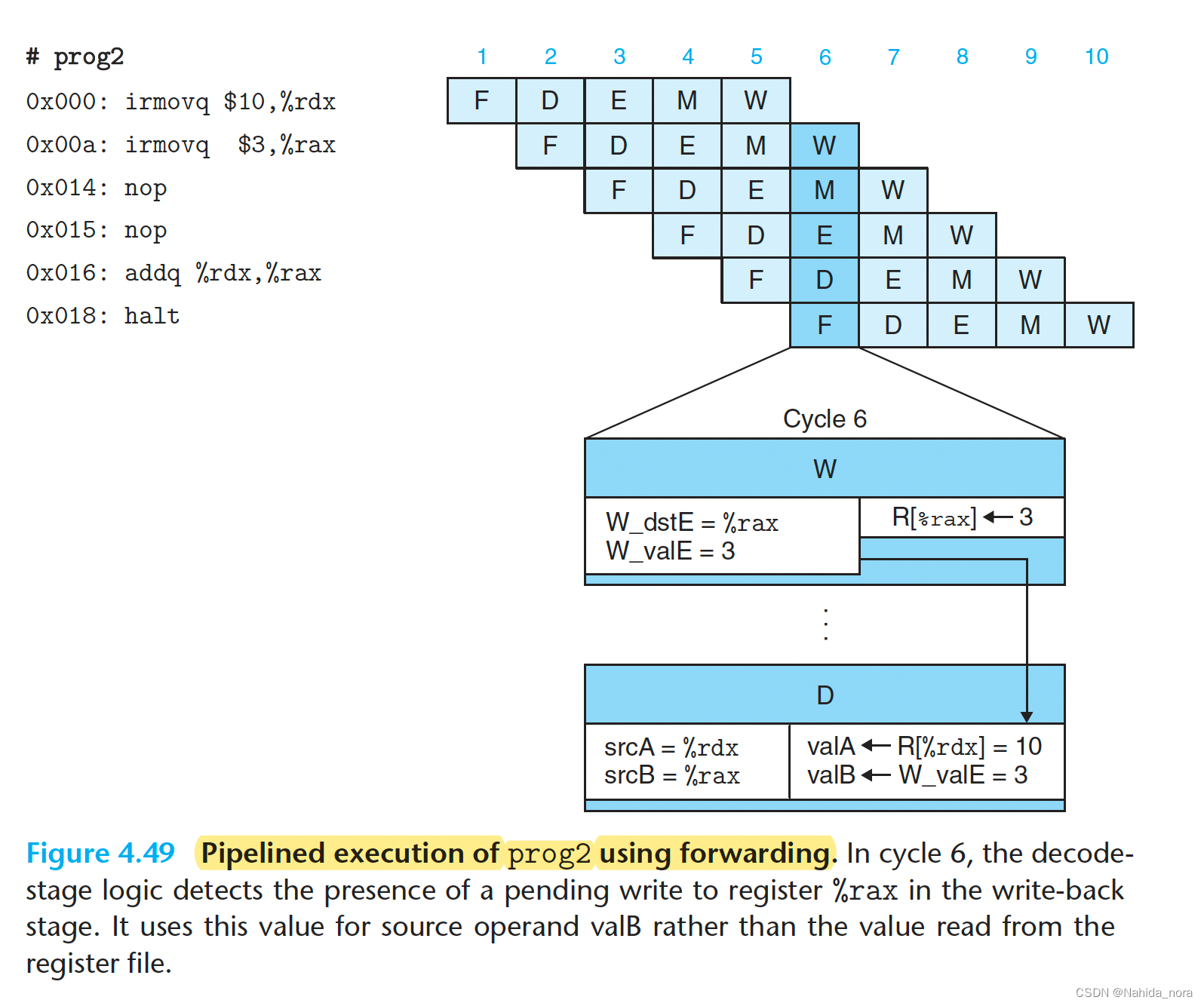
Avoiding Data Hazards by Forwarding
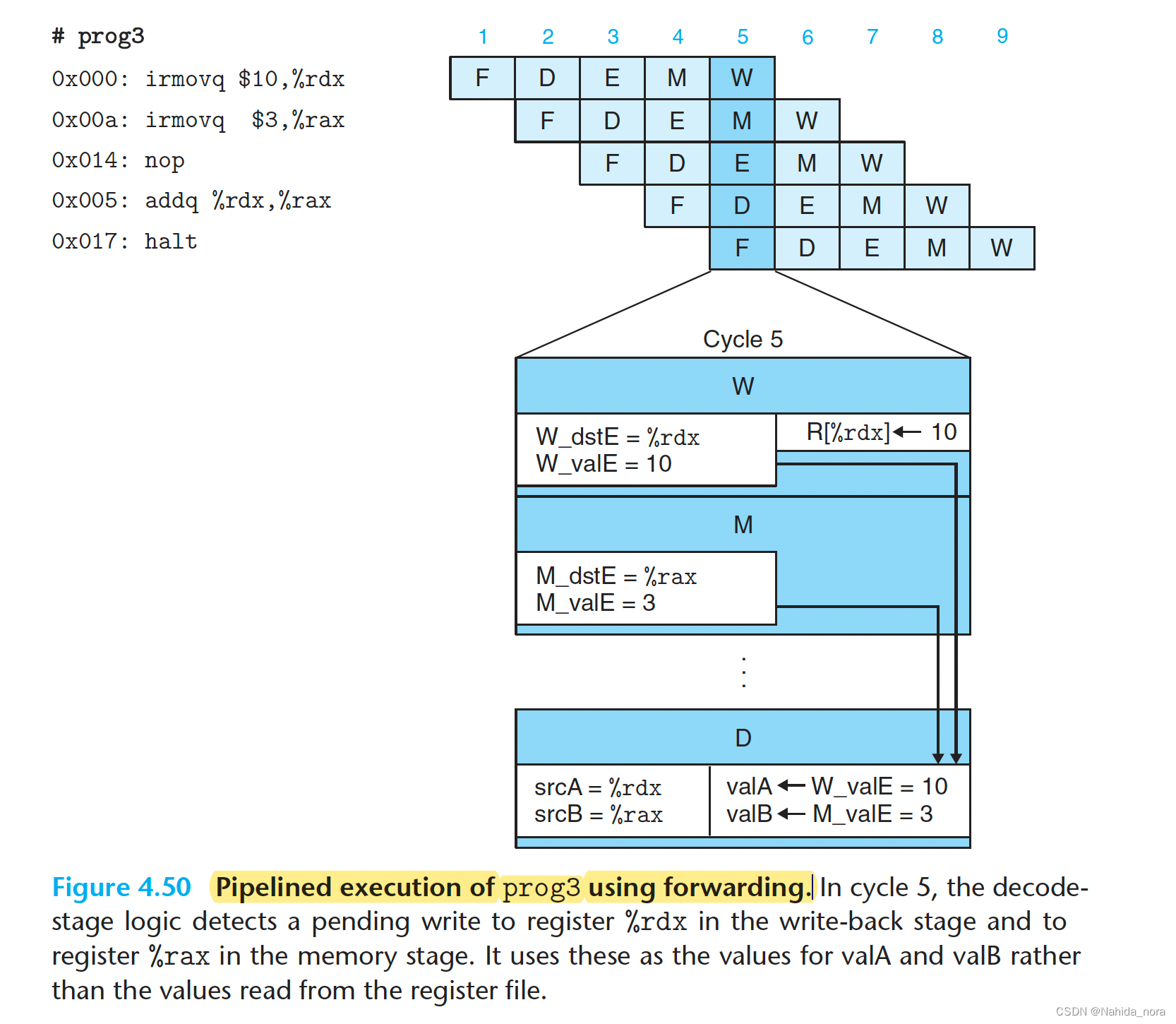
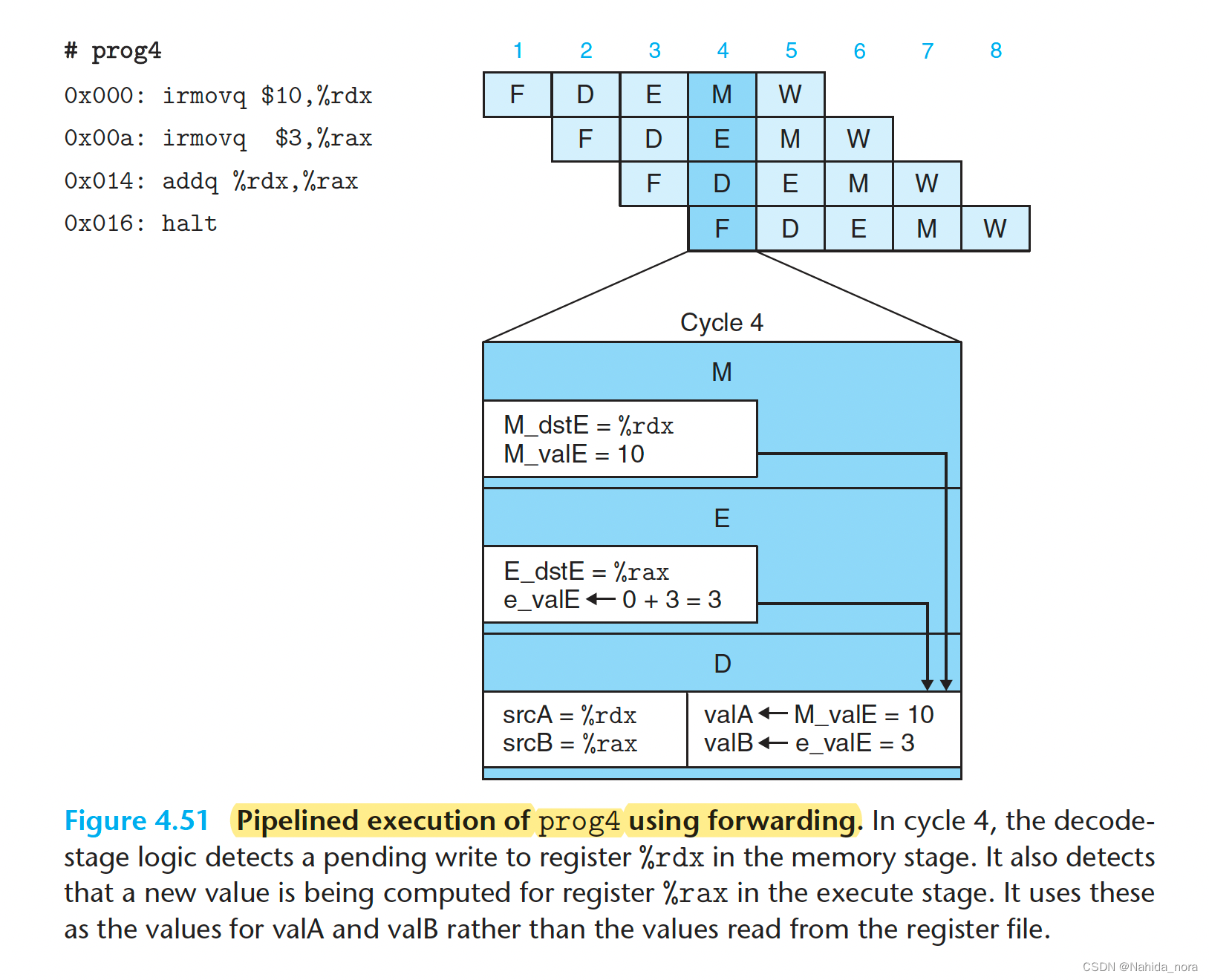
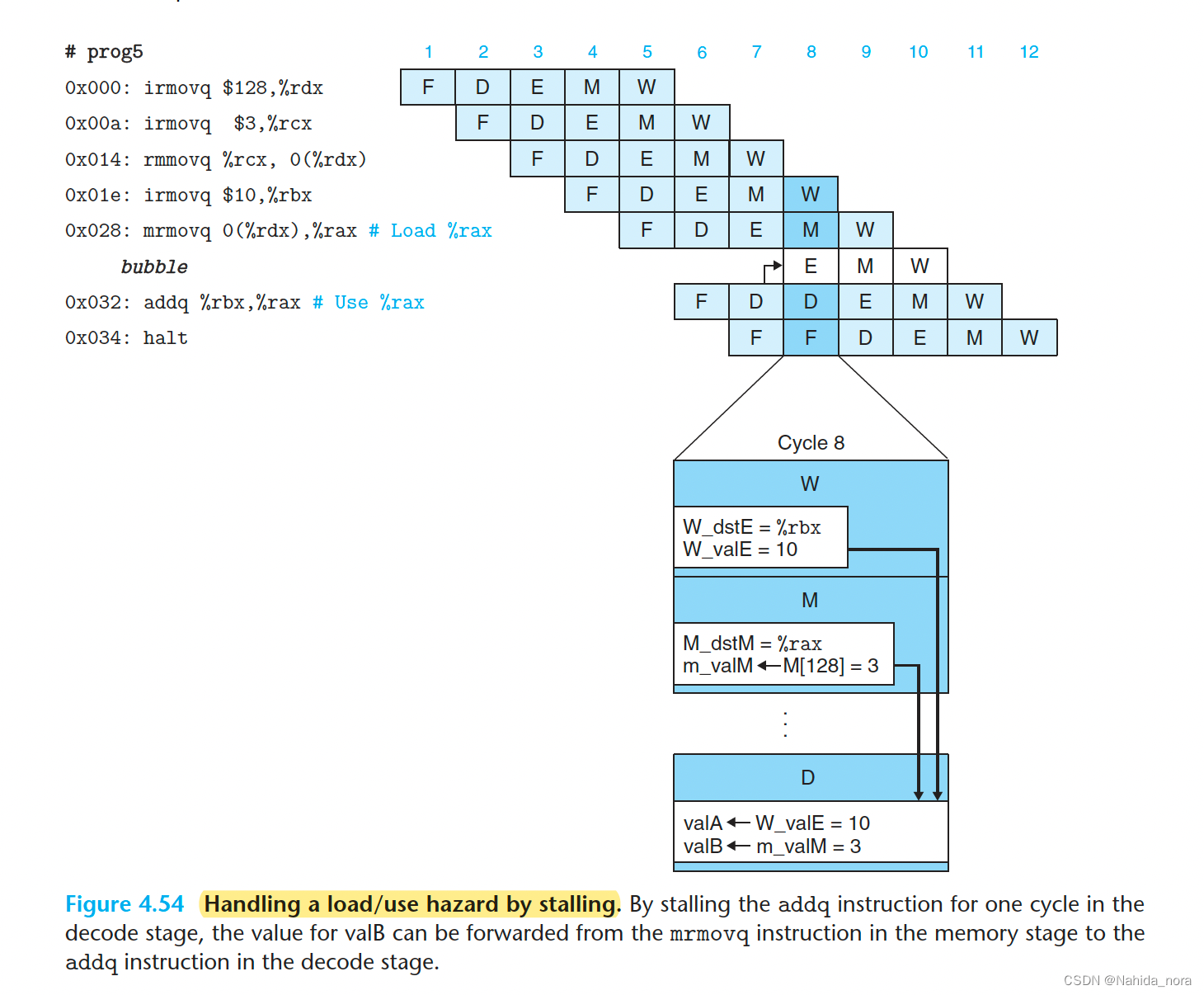
Load/Use Data Hazards


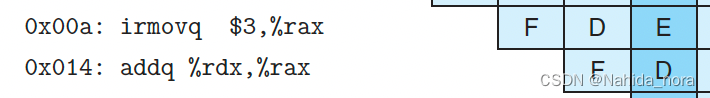
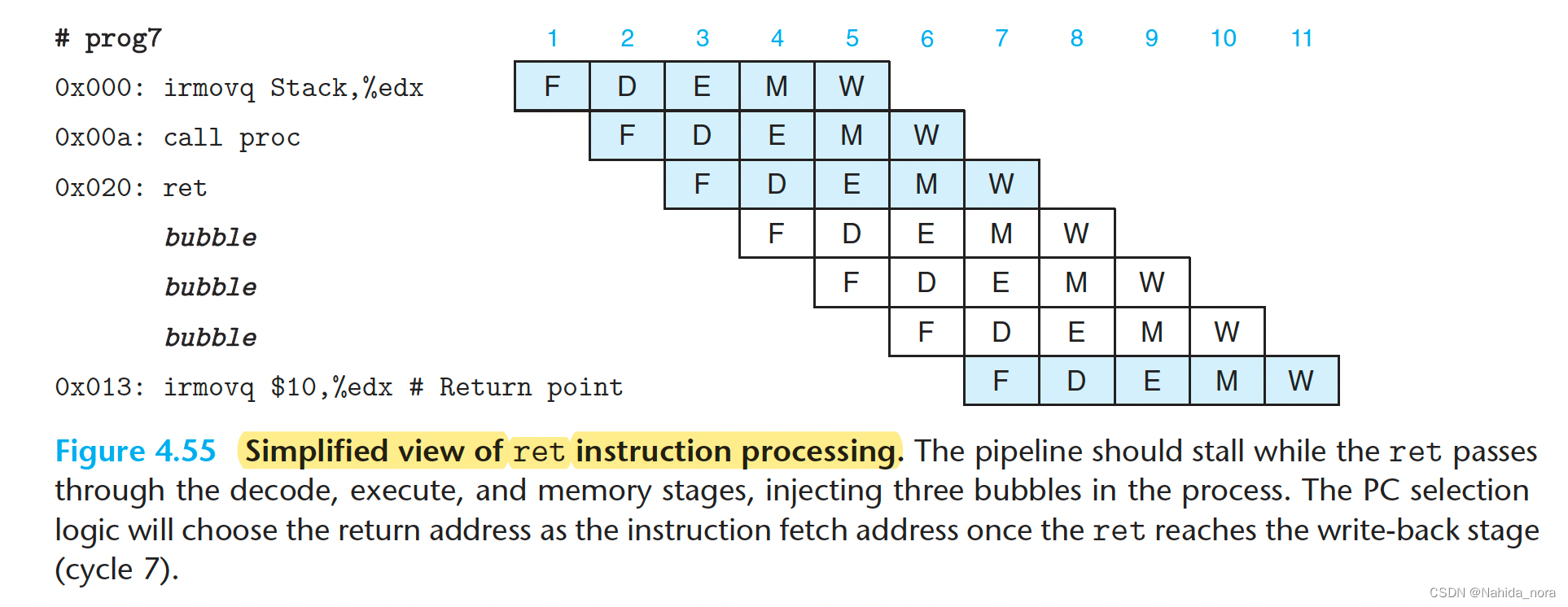
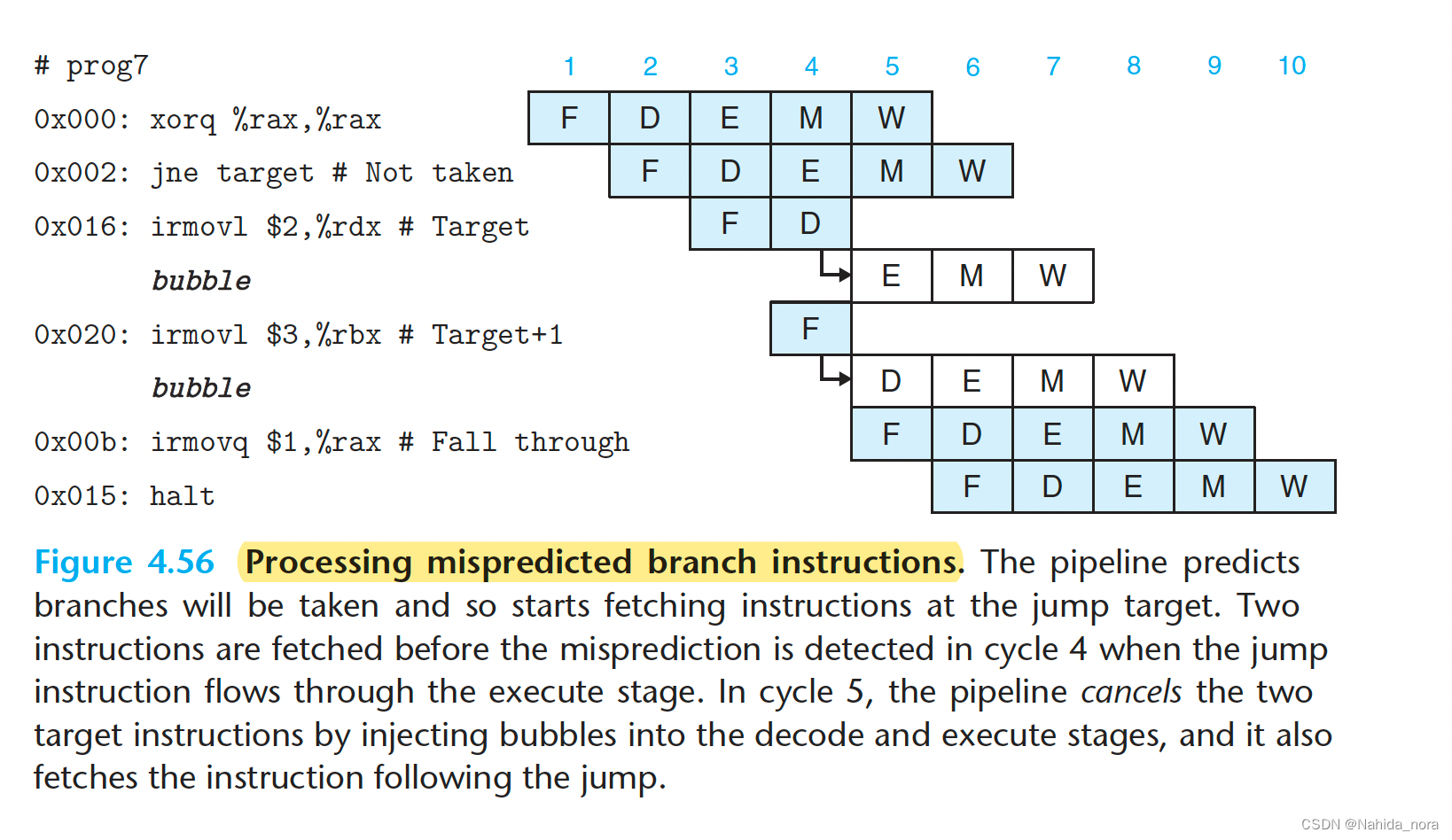
Avoiding Control Hazards


Exception Handling
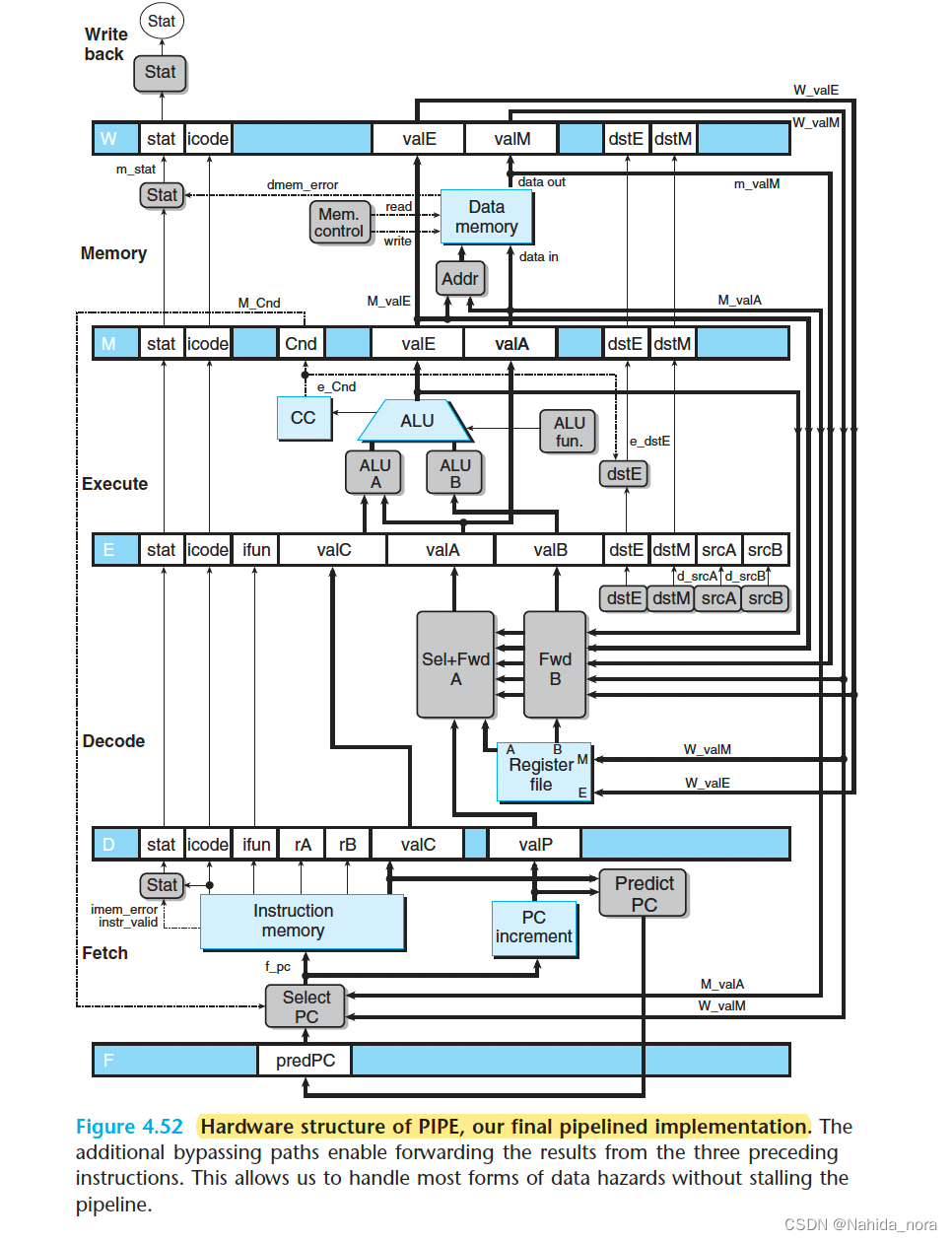
PIPE Stage Implementations

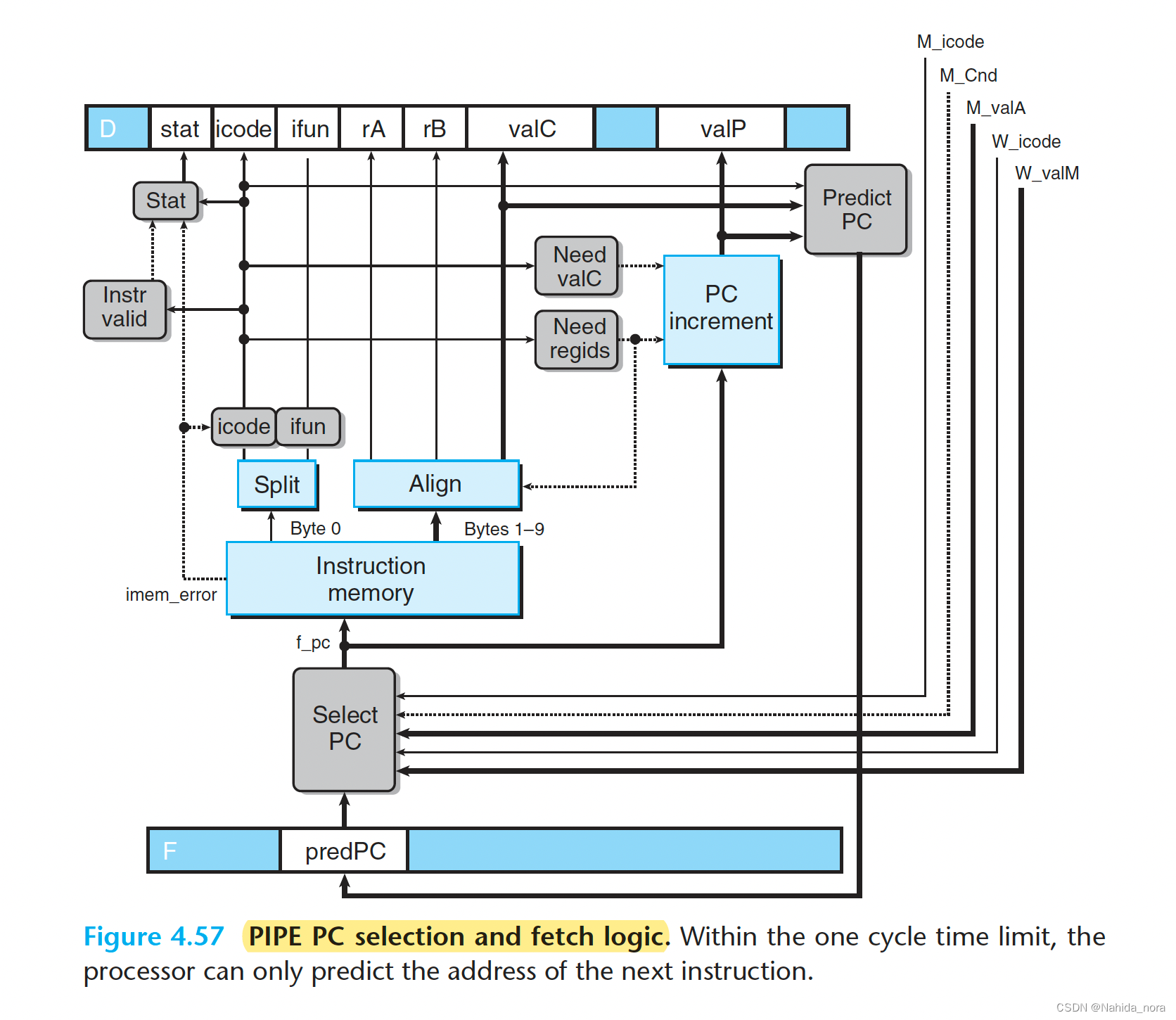
PC Selection and Fetch Stage


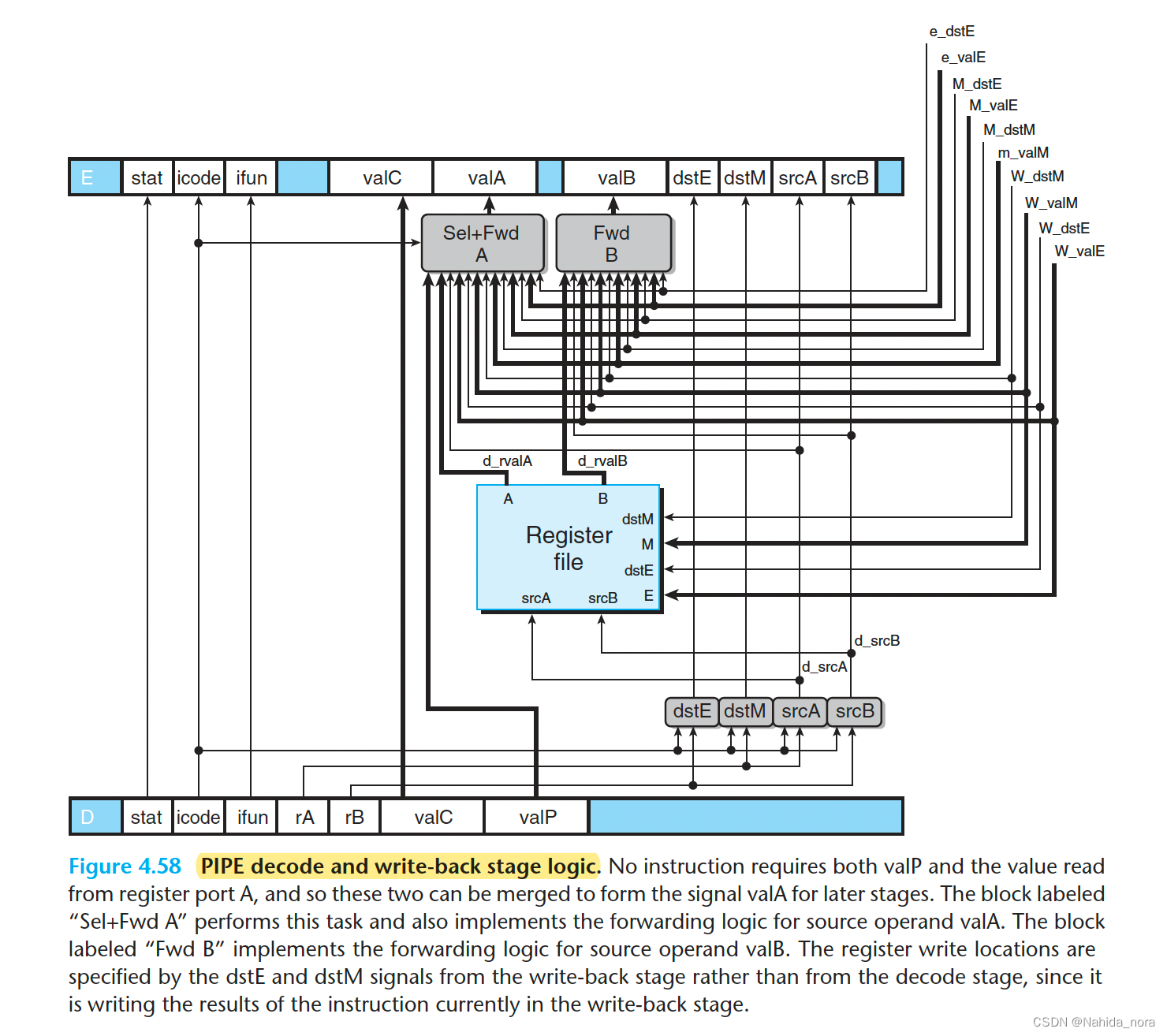
Decode and Write-Back Stages



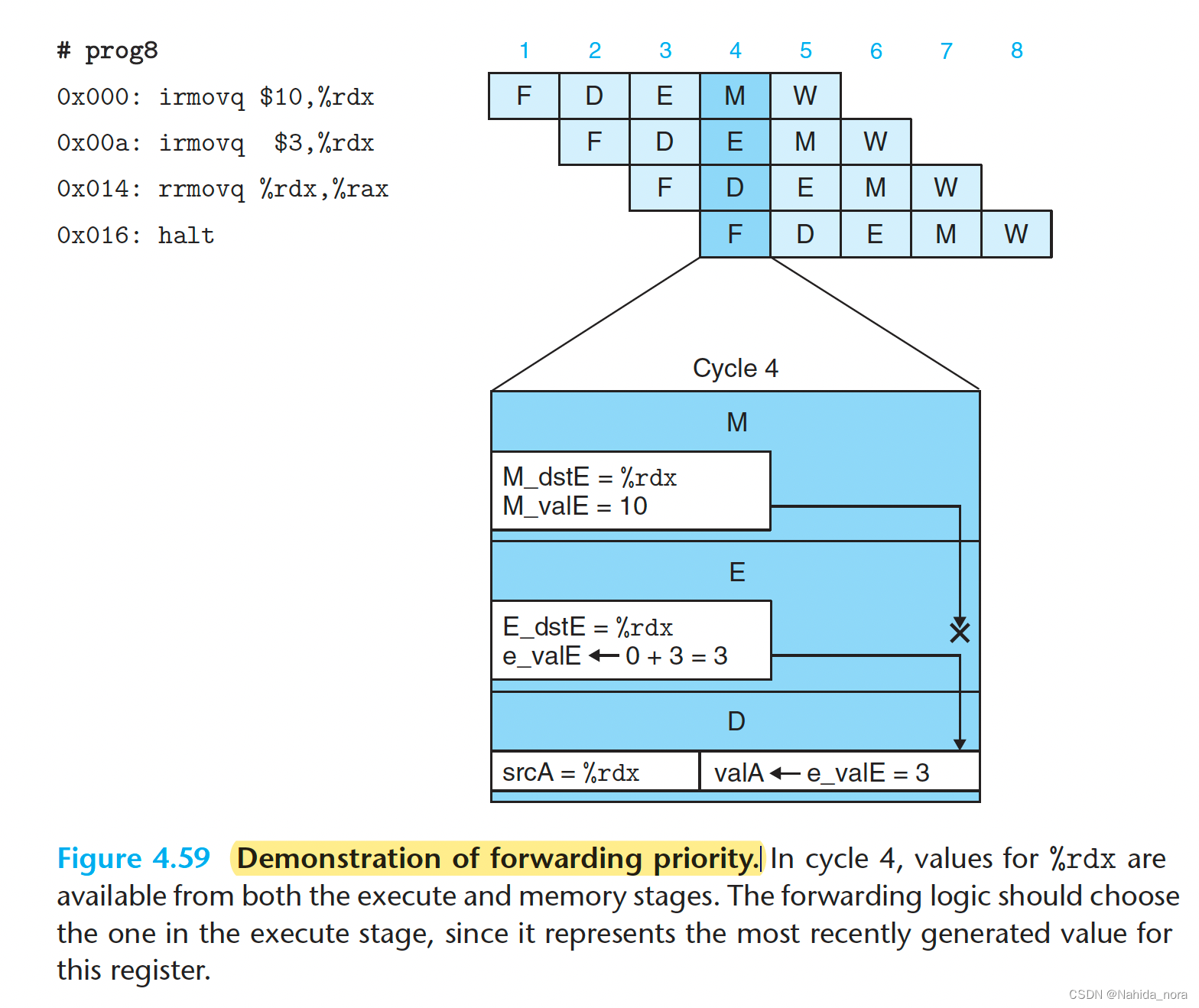

Execute Stage


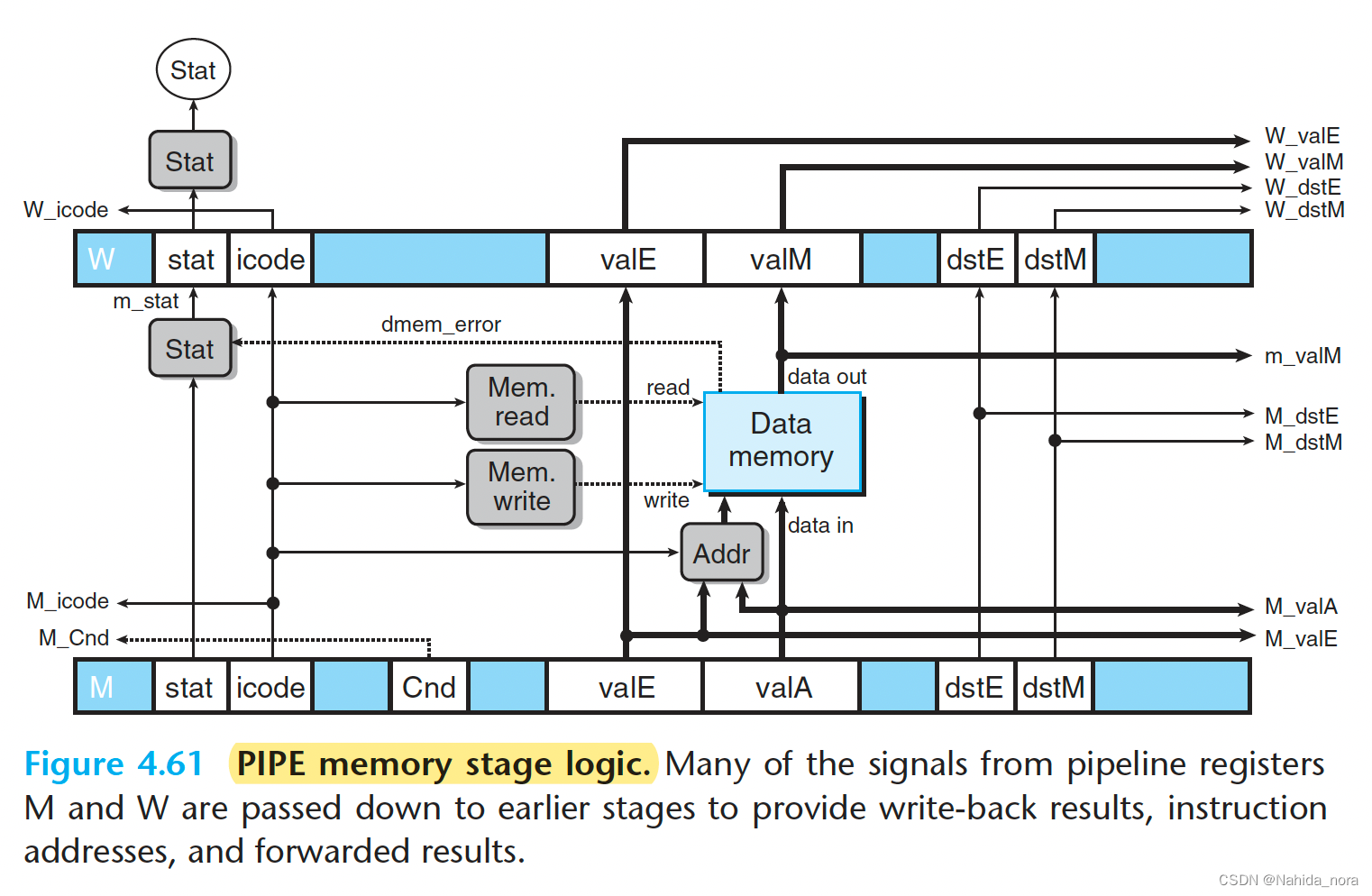
memory stage
相关知识
描的时间转换
links
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。