安装步骤
安装MariaDB:
sudo apt-get install -y mariadb-server mariadb-client
配置:
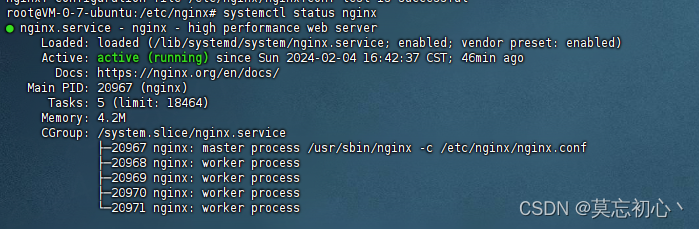
sudo service mysql status
sudo service mysql start
sudo mysql_secure_installation
Enter current password for root (enter for none):
如果你是第一次安装 MySQL,那么根本没有设置过密码,直接按回车即可。
Set root password?
输入 Y,然后输入你想要设置的密码。请注意,这里应该采用强密码,由数字、字母、符号组成,并且不应该与你的其他账户密码相同。
Remove anonymous users?
输入 Y。这样,没有密码的用户将无法访问 MySQL 服务器。
Disallow root login remotely?
这个问题涉及到 MySQL 服务器的安全设置。如果你只是在本地使用 MySQL,而不是在一台远程服务器上,那么直接输入 Y 即可。如果你需要在远程计算机上使用 MySQL,那么需要考虑更复杂的安全设置。
Remove test database and access to it?
输入 Y。这个问题涉及到 MySQL 服务器的安全设置。如果你不需要测试数据库,那么最好将其删除以防止安全漏洞的出现。
Reload privilege tables now?
输入 Y。这样你的设置才会生效。
查看配置:
mysql -u root -p
mysql(打开mysql客户端)-u(用户名,默认为root)-p(输入密码)
show variables like '%char%';
数据库的基本操作
库的操作:
- 有具体格式与语法规则,每一条sql都要以一个英文分号结尾(SQL语句可以跨行,因此要以分号结尾)
- 库表字段名称不能使用关键字-如果非要使用则使用反引号··(tab键上面的按键)括起来
- 不区分大小写 DB_91和db_91以及dB_91相同
show databases;
create database dbname;
//如果创建名称dbname是一个关键字,则用反引号括起来
create database `dbname`;
//典型用法:无论是否存在该数据库都会返回成功
create database if not exits `dbname`;
drop database `dbname`;
use `dbname`;
select database();
- 其他
show creat database `dbname`;
数据类型
- 整形:
bit(16),tinyint, int, bigint - 浮点型:
float(m, d), double(数字个数, 数字中小数的个数)
例如:double(5, 2) -> 888.88,五个数,小数个数为2
decimal(m, d), numeric(m, d):精度损失小,使用较多 - 字符串型:
varchar(32):变长字符类型,该例表示最多存储32个字符,text,mediumtext,blob - 日期型:
datatime
数据库表的操作:
create table if not exits 表名(表内信息);
//注意:变量在前,类型在后
create table if not exits stu(
sn int comment '学号',
name varchar(32) comment '姓名',
age int comment '年龄',
sex varchar(1) comment '性别',
height int comment '身高',
weight decimal(4,1) comment '体重');
comment ‘’:为注释,可以在使用show creat table stu时查看该注释。
2. 查看:查看库中所有表
show tables;
describe 表名;
alter table 表明 add 变量 类型;
//举例:
alter table stu add birth datetime;
- 删除:删除表
drop table 表名;
- 其他
show creat table 表名;
表中数据的增删改查:
insert into 表名 values(参数);
//指定列插入
insert into 表明(变量名) values(指定列参数);
//举例
insert into stu values(1001,'张三',18,'男',165,55.55,'2023-11-27 14:14:12');
insert into stu(name,sn,sex) value('李四',1002,'女');
多行插入:
insert into 表名 values(参数1),(参数2),...(参数n);
//举例
insert into stu values(1001,'张三',18,'男',165,55.55,'2023-11-27 14:14:12'),
(1003,'王五',17,'男',168,54.65,'2023-11-27 14:16:13'),
(1004,'阿衰',19,'男',167,57.85,'2023-11-27 14:17:14');
- 删除:delete
delete from stu where sn=1003;
//前面的=是赋值,后面where的=是判断条件
update 表名 set 内部参数1=赋值,内部参数2=赋值 where 内部参数=表内值;
//举例
update stu set weight=60.4,name='赵四' where sn=1003;
默认全列:
select * from 表名;
select 变量 from 表名;
//举例
select height,weight name from stu;
select 变量1+变量2 as hw from 表名;
//举例
select height+weight as hw name from stu;
去重:distinct
select distinct 变量 from 表名;
//举例
select distinct height from stu;
//升序(默认)
select * from 表名 order by 变量;
select * from 表名 order by 变量 asc;
//降序
select * from 表名 order by 变量 desc;
//举例
//先以第一列指定排序,若在相同的情况下以第二列指定排序
//即先以体重从高到底排序,若体重相同的情况下,按年龄从小到大排序
select * from stu order by height desc, age asc;
from 表名 order by 变量 指定排序 limit 查询数 offset 页数*查询数;
//举例:身高从高到低排序,查询前三名1,2,3
from stu order by height desc limit 3 offset 0;
//第二页:也就是第4,5,6名
from stu order by height desc limit 3 offset 3;
select * from 表名 where 变量名=值;
//举例
select * from stu where name='张三';
//比较:>,>=,<,<=,=,!=,<=>(相等),<>(不相等)
select * from stu where name='张三';
select * from stu where birth<=>null;
//空值:is null, is not null
select * from stu where sn is null;
//范围:between...and..
select * from stu where height between 165 and 170;
//子集匹配:in(集合)
select * from stu where name in ('王四','赵四','李四');
//模糊匹配:like
select * from stu where name like '%四%';
//与:双目,and-连接两个比较条件,两者同为真,则结果为真
select * from stu where height>=165 and height<=170;
//或:双目,or-连接两个比较条件,两者任意一个为真,则结果为真
select * from stu where weight>=55 or height<=170;
//非:单目,not-针对单个比较条件,条件为真,则结果为假
select * from stu where not height>=165;
表中数据的增删改查(进阶):
键值约束:约束表中指定字段的数据必须符合某种规则
种类:
非空约束:NOT NULL – 约束指定字段的数据不能为NULL
唯一约束:UNIQUE – 约束指定字段的数据不能出现重复
主键约束:primary key – 数据非空且唯一,一张表只有一个主键
外键约束:foreign key – 表中指定字段的数据受父表数据约束
默认值:DEFAULT – 为指定字段设置默认值
自增属性:AUTO_INCREMENT – 整形字段数据自动+1
create table if not exits student(
id int primary key auto_increment,
sn int not null unique,
name varchar(32),
class_id int,
sex varchar(1) default '男',
foreign key (class_id) reference class(id)
);
ER关系图:根据实体与实体之间的关系决定数据库表如何设计
一对一:每个实体设计表的时候都应该具有一个唯一主键
一对多:每个学生信息中都会包含一个班级id
多对多:创建一个中间表关联两个实体(学生–课程)
三大范式:数据库表设计的三大规范
1nf:表中每个字段都必须具有不可分割原子特性
第一范式是其他范式的前提
并且如果不遵循第一范式会导致按照某个非原子字段进行查询时降低效率
2nf:表中每个字段有应该与主键完全关联,而不是部分关联
若不遵循第二范式:则表中有可能存在大量冗余数据
3nf:表中每个字段都应该与主键直接关联,而不是间接关联
select 变量1,变量2,... from 表名 grop by 变量1;
select role,sum(salary),max(salary),min(salary) from emp grop by role;
select role,sum(salary),max(salary),min(salary),avg(salary) from emp grop by role having avg(salary)>1500;
聚合函数:
count(*):统计数据条数
sun(fields):统计指定字段的和
max(fields):统计指定字段中的最大值
min(fields):统计指定字段中的最小值
avg(fields):统计指定字段中的平均值
将多张表合在一起:笛卡尔积
左连接:以左表作为基表在右表中查询符合条件的数据
右连接:以右表作为基表在左表中查询符号条件的数据进行连接
//[inner]可省略
select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他条件;
select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他条件;
selsect stu.name,class.name from stu inner join class on stu.class_id=class.id;
//左连接
selsect stu.name,class.name from stu left join class on stu.class_id=class.id;
//右连接
selsect stu.name,class.name from stu right join class on stu.class_id=class.id;
子集
//查询小明同学的同班同学
select * from student where classes_id=(select classes_id from student where name="小明");
select * from score where course_id in (select id from course where name='语文' or name='英文');
EXISTS关键字:后面判断为真则查询
取出一条成绩信息,然后去表中再次查询是否具有符合条件的结果
select * from score where exists(select score.id from course where (name='语文' or name='英文') and course.id=score.course.id);
合并查询:union – 将多条sql语句的执行结果合并到一起
select * from course where id<=3
union
select * from course where name="java";
select * from course where id<=3
union all
select * from course where name="java";
索引
B树与B+树:
B树:是一个多叉树 – 降低树的高度来提高查询效率
B+树:也是一个多叉树
相较于B树的差别:
B树的数据与索引存储在一起,B+树数据与索引分离
一次性可以从磁盘中读取出更多索引信息,更利于索引检索
B+树数据顺序存储,在连续查询或范围查询时可以连续IO去除数据,效率较高
聚簇索引/非聚簇索引:
聚簇索引:以主键作为主索引,数据节点在磁盘中顺序进行存储,其他的索引作为辅助索引,其中辅助索引保存的是主键索引的字段值
使用场景:索引与数据都是顺序存储的,因此中间插入/删除需要调整索引的存储结构。
聚簇索引的数据都是顺序存储的,因此在连续/范围查询的时候效率较高
聚簇索引通常针对主键创建,一张表只有一个
非聚簇索引:主键索引与普通索引区别不大,都是最终索引项中存储数据在磁盘中的存放位置,数据节点在磁盘中并非顺序存储
使用场景:中间插入数据,只需要将数据存储到磁盘新的位置,中间调整索引信息即可
因为索引与数据存储顺序不一致,导致在范围查询是,与单个查询效率没有差别都需要一个个去找出来
innodb索引类型默认是聚簇索引,中间数据的插入与删除会涉及索引与数据的位置调整,因此大多数情况都是使用自增主键作为聚簇索引,这样的话数据与索引总是在最后添加,而不涉及中间插入的调整。
在数据库操作中的索引类型:
- 主键索引:一个字段被设置为主键,则默认就会为主键字段创建主键索引
- 唯一键索引:一个字段被设置了唯一约束,也会默认创建唯一键索引
- 外键索引:一个字段被设置外键约束,也会默认创建外键索引 普通索引:并非默认创建的索引
查看索引:
show index from tbnameG;
创建索引:
create index idx_name on tbname(fields_name);
删除索引:
drop index idx_name on tbname;
数据库事务:
概念:一个或多个sql的组合
示例:
银行转账:给同学转账1000,你的账户少了1000,对方账户多了1000
特性:
原子性:一个事务要么一次完成要么一个都不做。
一致性:在事务前与事务后,数据完整性都要符合预设规则,以来原子性
持久性:事务之后,数据的修改是永久的(持久化存储)
隔离性:允许多个事务并发执行,不会因为交叉执行导致数据不一致
脏写:事务A对数据的修改,在事务提交之前被其他事务覆盖
脏读:一个事务中读取到的数据是其他事务中未提交的数据
不可重复读(针对update):在一个事务的不同阶段所读取的数据不一致
幻读(insert/delete):在一个事务内的不同时间段读取到的数据条数不一致
mvcc:多版本并发控制
就是给每个事务分配一个事务id
事务中对数据进行操作时,都临时拷贝出一份数据进行操作
在本次事务对数据再次进行访问时访问的都是这个临时拷贝
事务提交时将事务操作持久化存储
原文地址:https://blog.csdn.net/m0_49619206/article/details/134637794
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_22556.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!