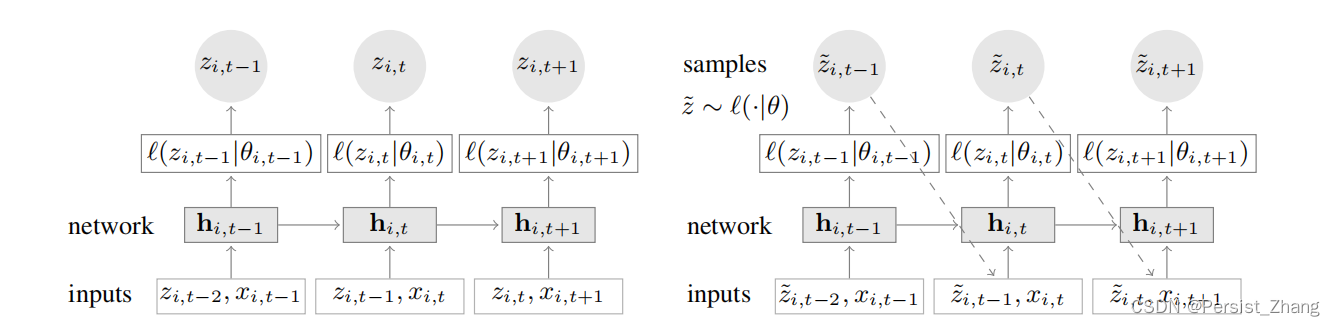
给神经网络增加记忆能力

对卷积层而言,因为卷积核的参数是共享的,所以卷积操作与序列的长度无关。但是因为卷积层的后面往往会跟着一些全连接层,从而导致卷积层的输出不能任意改变
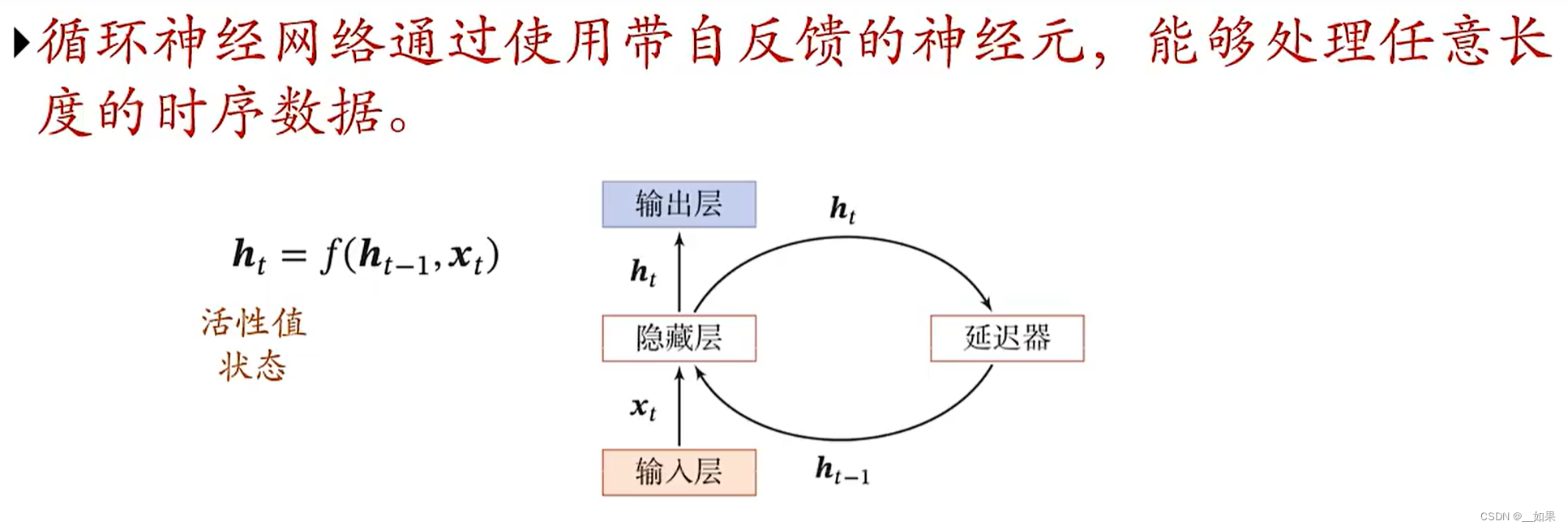
从这不难看出,当前结果的输出不仅依赖于当前时刻的输入,还依赖于上一时刻所处的状态

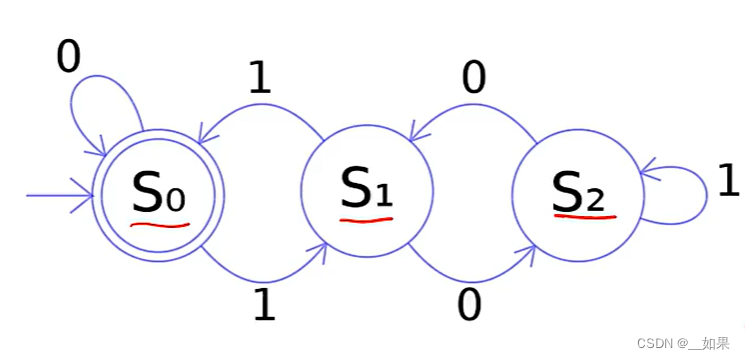
这是一个图灵机:一种抽象的数学模型,可以用来模拟任何可计算问题
输出不单单依靠输入,同时也与控制器的行为、纸带上存下来的信息等有关,比起有限状态自动机更加复杂
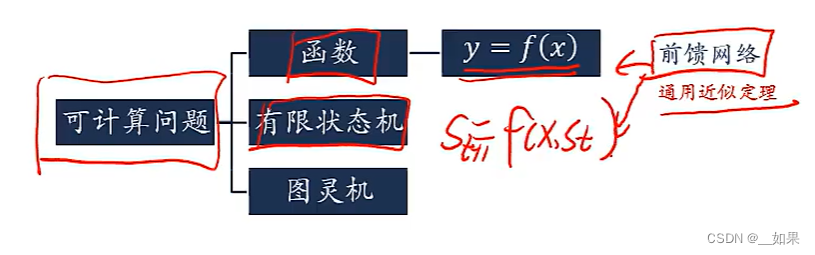
对于有限状态机,我们可以改造前馈网络实现。但是对于更加复杂的图灵机就不能仅依靠改造前馈网络实现,而是需要引入记忆能力
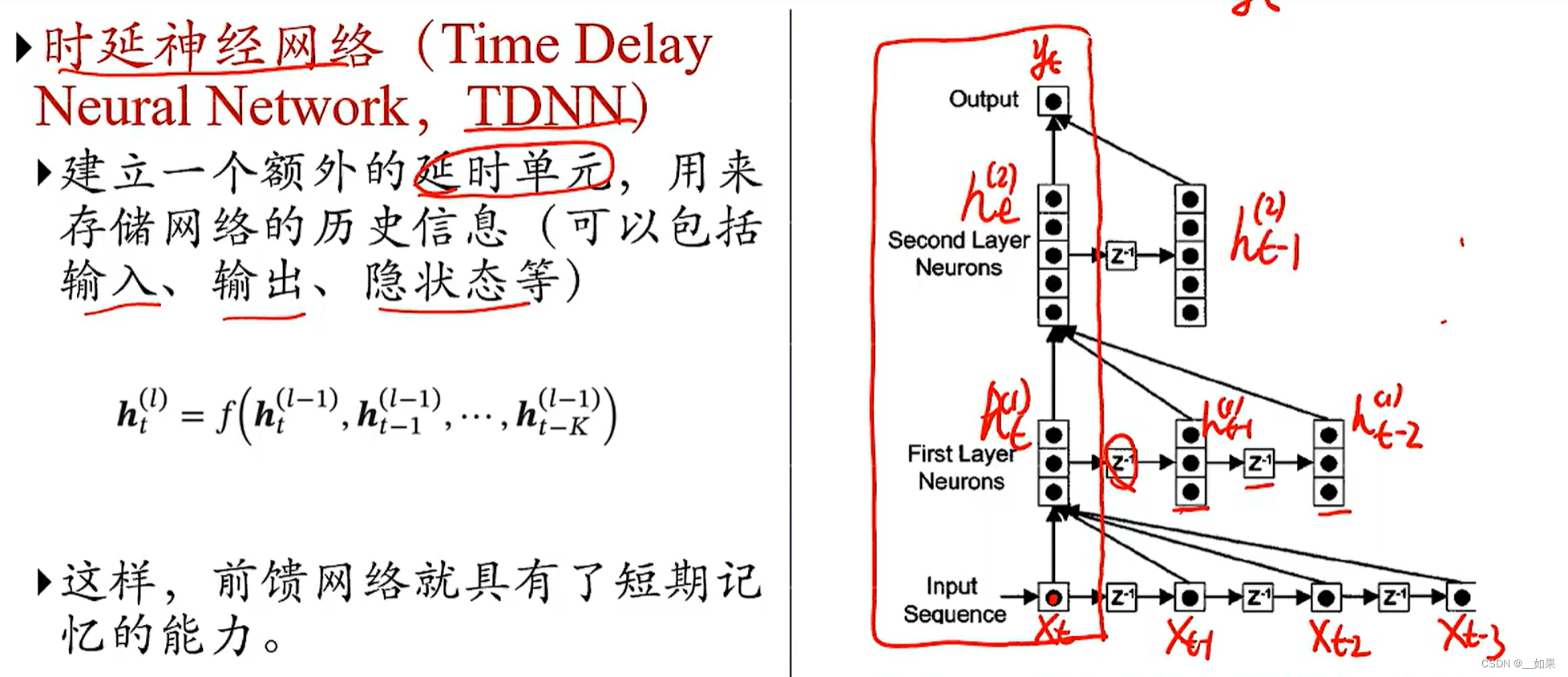
第一个隐藏层中的t-2是由输入层中的t-2与t-3得到的,t-1是由t-1、t-2、t-3得到的,t同理

自回归模型:w0是偏置,wk是权重,当前时刻的yt由前k个时刻的yt-k加权得到
非线性自回归模型:自回归模型没有外部输入,只是y自己预测自己。因此非线性自回归模型引入了非线性函数,x是输入,y是输出,做到了通过时间序列的输入与时间序列的输出一起预测
循环神经网络
Q:循环神经网络与时延神经网络和自回归模型在记忆方式上的差异?
A:循环神经网络(RNN)具有短期记忆能力,可以通过递归的方式对序列数据中的依赖关系进行建模。RNN 的记忆能力来源于网络中的递归结构,它能够记住最近几个时间点的输入信息。然而,随着时间的推移,RNN 的记忆能力会逐渐减弱。
时延神经网络(DTNN)具有长期记忆能力,它通过在时间轴上增加延迟连接来实现对长期依赖关系的建模。DTNN 可以在一定程度上克服 RNN 记忆能力有限的问题,但由于其结构复杂,训练和计算成本较高。
自回归模型(AR)是一种基于 AR 过程的线性模型,它通过自回归系数矩阵来描述过去时刻观测值之间的依赖关系。AR 模型可以看作是一种特殊的 DTNN,其记忆能力取决于自回归系数矩阵的规模。
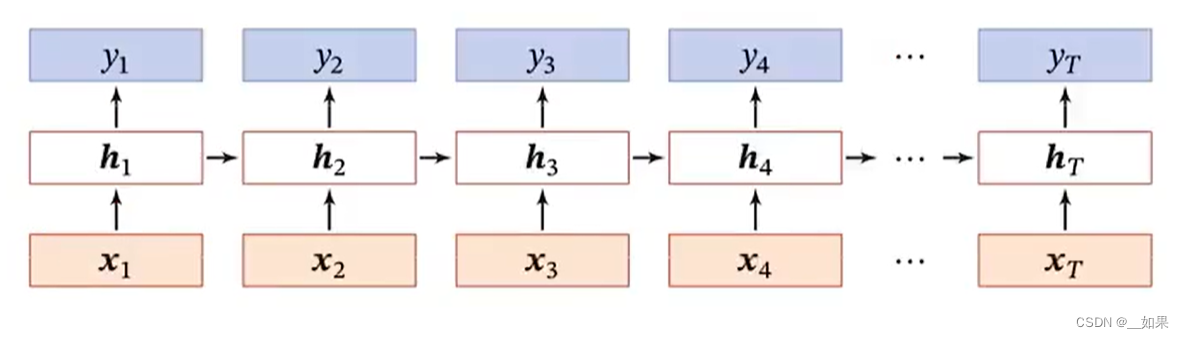
RNN在时间维度上是很深的网络,但是在非时间维度上却是很浅的网络。因为在时间维度上过深,所以需要考虑梯度消失的问题;因为在非时间维度上过浅,所以需要考虑增加模型的复杂度


如果我们认为前馈神经网络可以模拟任何函数的话,那么循环神经网络就可以模拟任何程序
应用到机器学习
序列到类别

情感分类
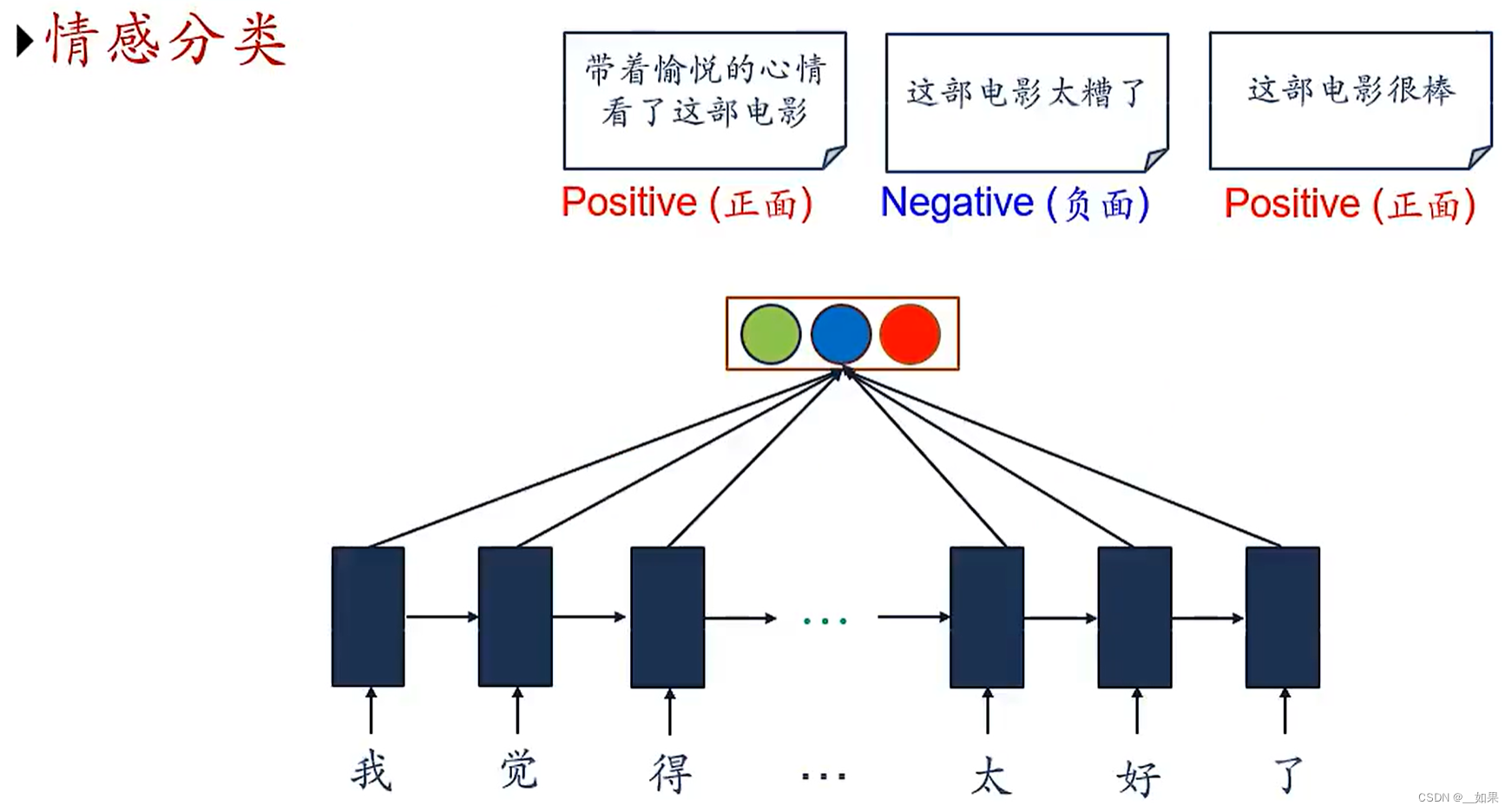
因为文本是一个变长的序列,把每个字看成不同时刻的输入(一个词向量),所以可以使用RNN
同步的序列到序列模式

中文分词
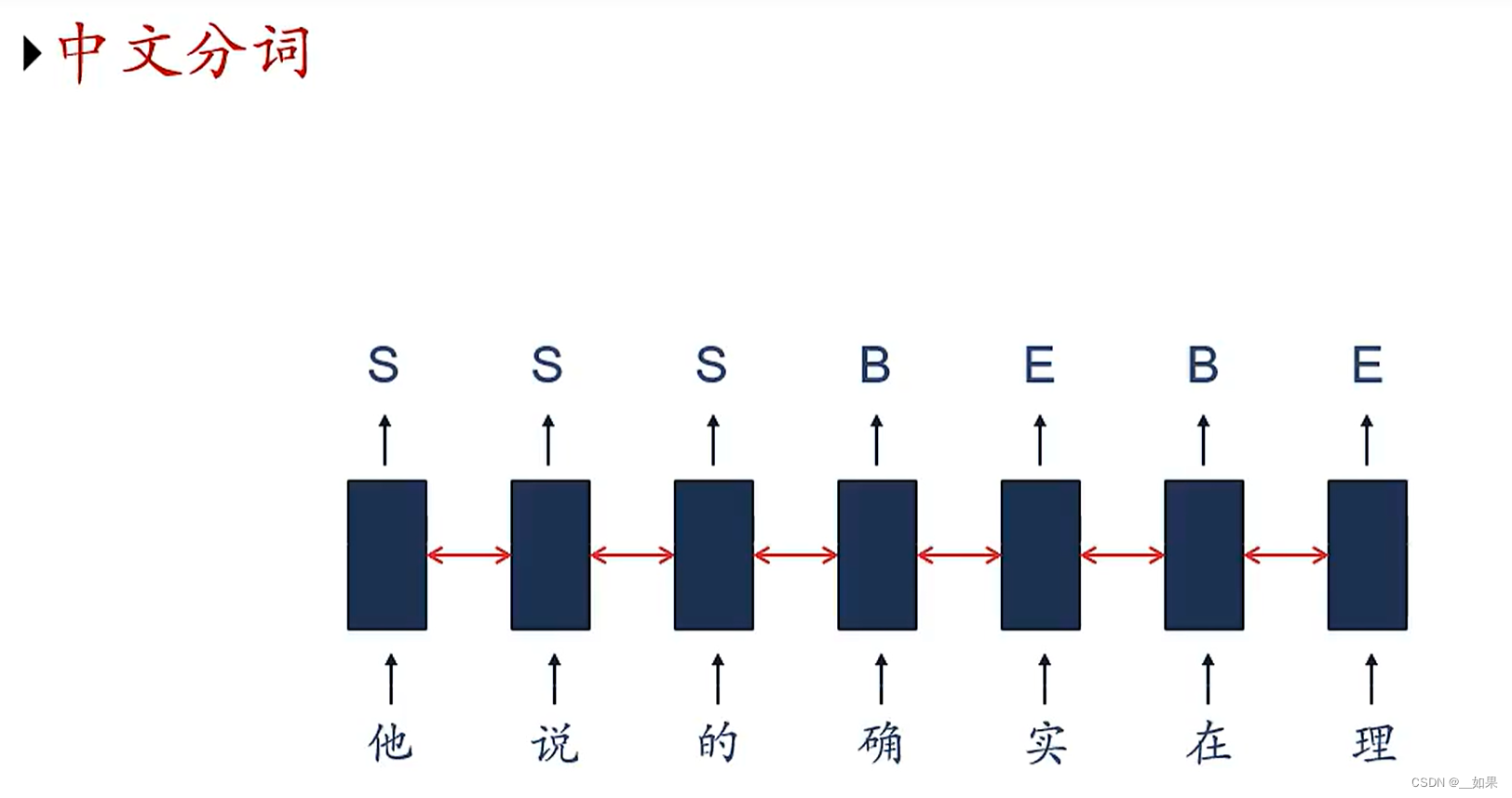
但是在中文中,的确是一个词,实在是一个词,词语分隔存在歧义性
在机器学习中我们把这个任务变成一个序列标注的任务,S表示单个词语,B表示一个词语的开始,E表示一个词语的结束
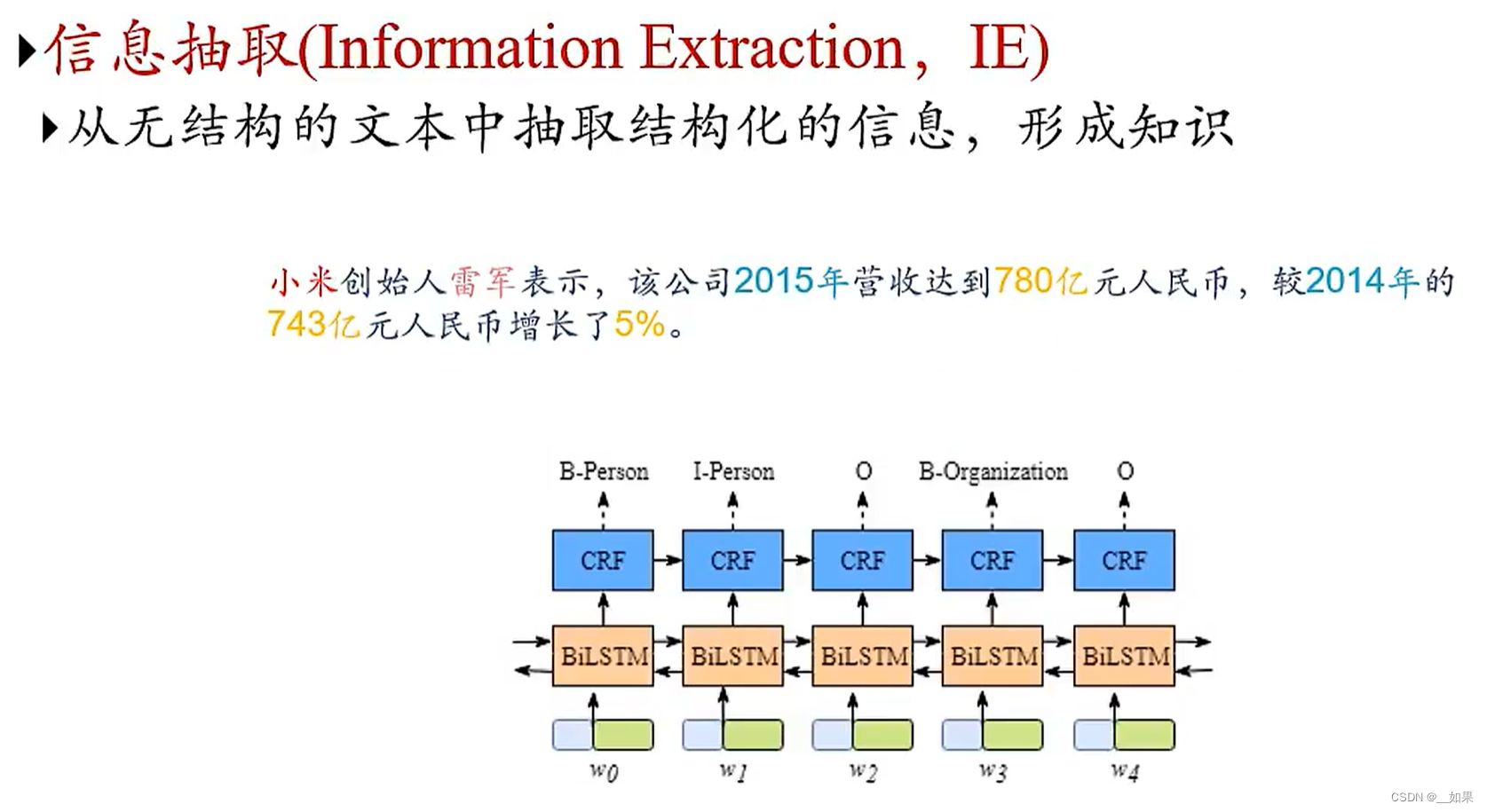
信息抽取
语音识别

异步的序列到序列模式

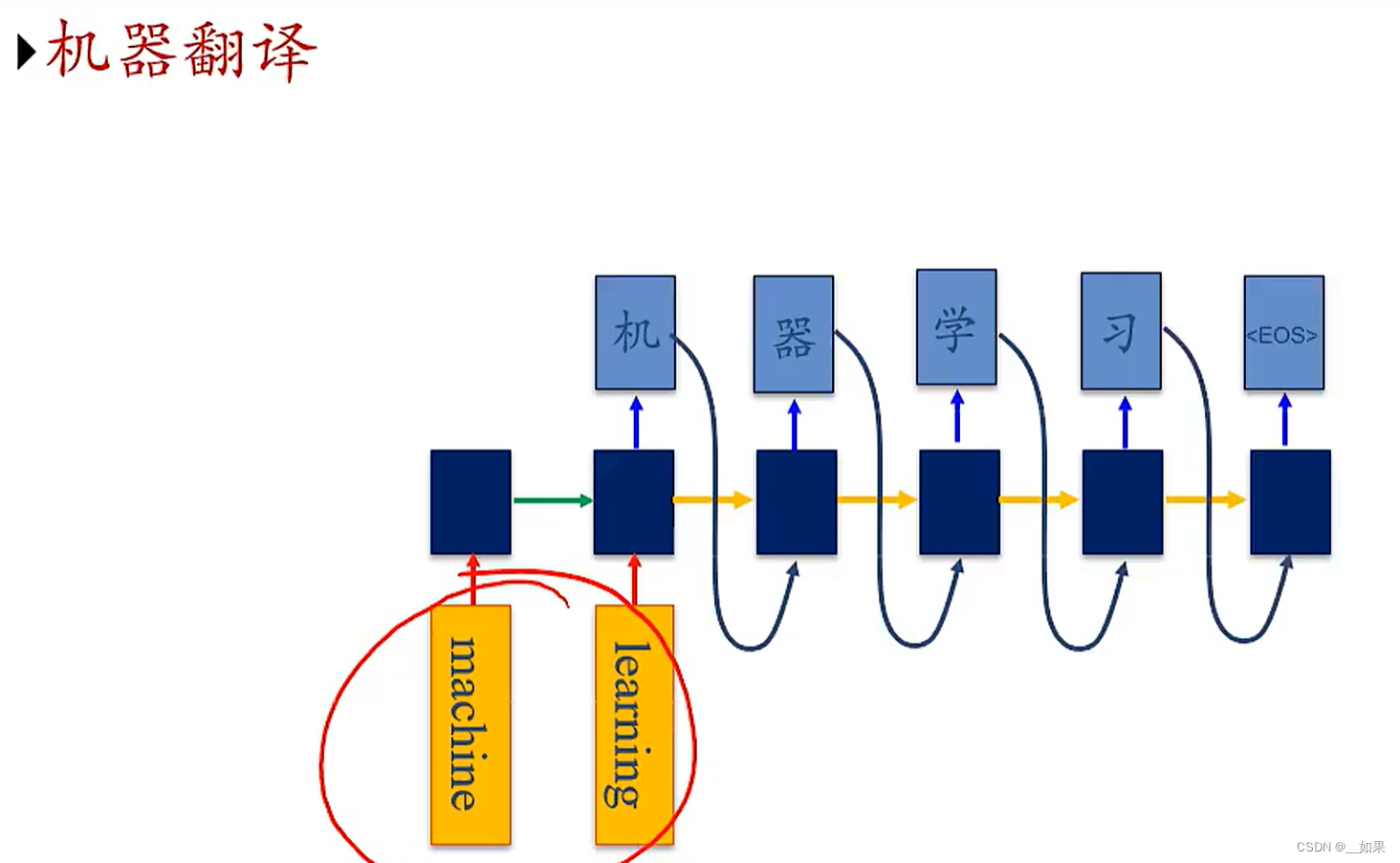
右边的状态是通过上一时刻的状态与上一时刻的输出得到的,没有输入x,可以看作是解码器decoder
机器翻译
参数学习与长程依赖问题
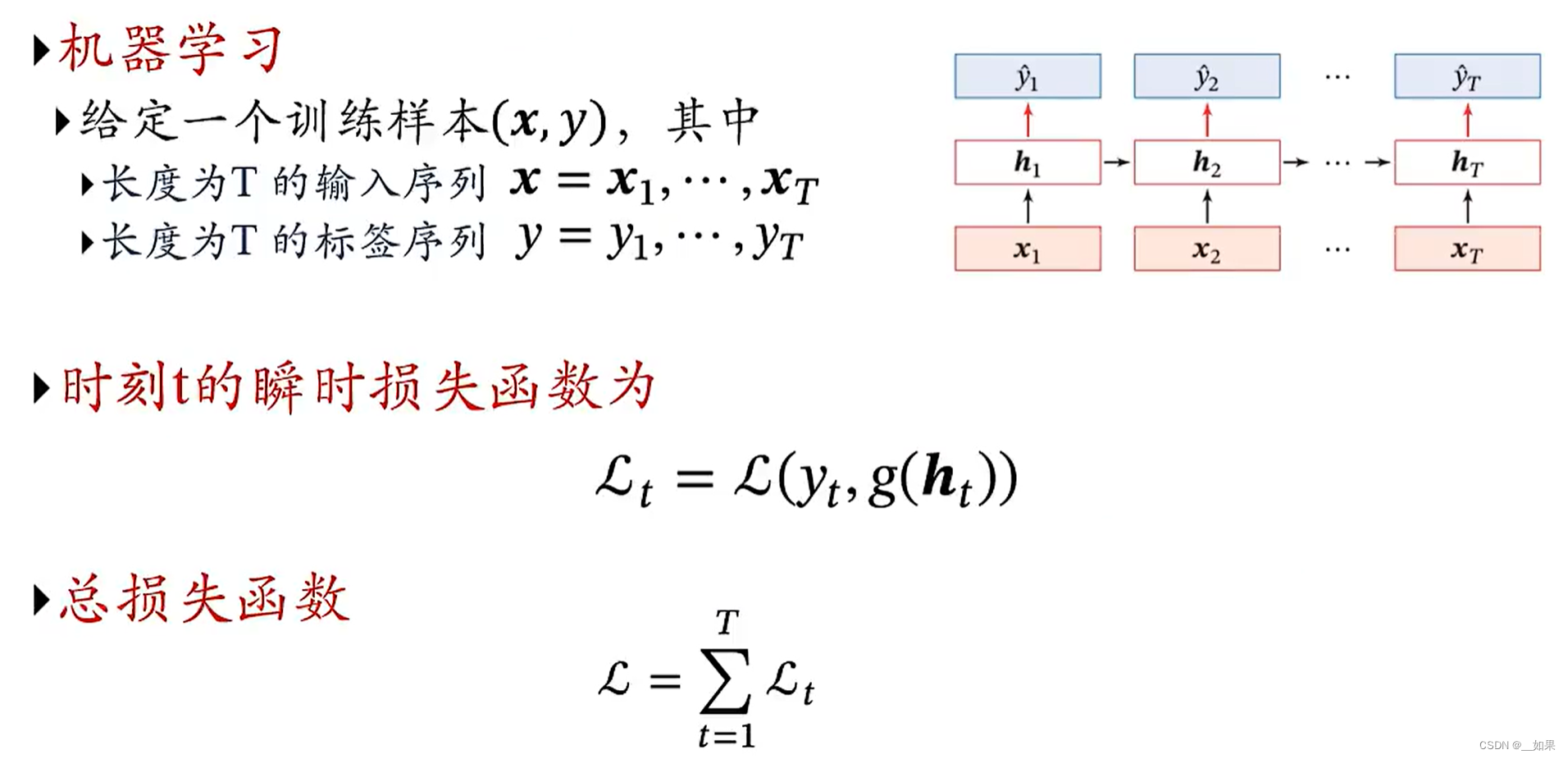
随时间反向传播
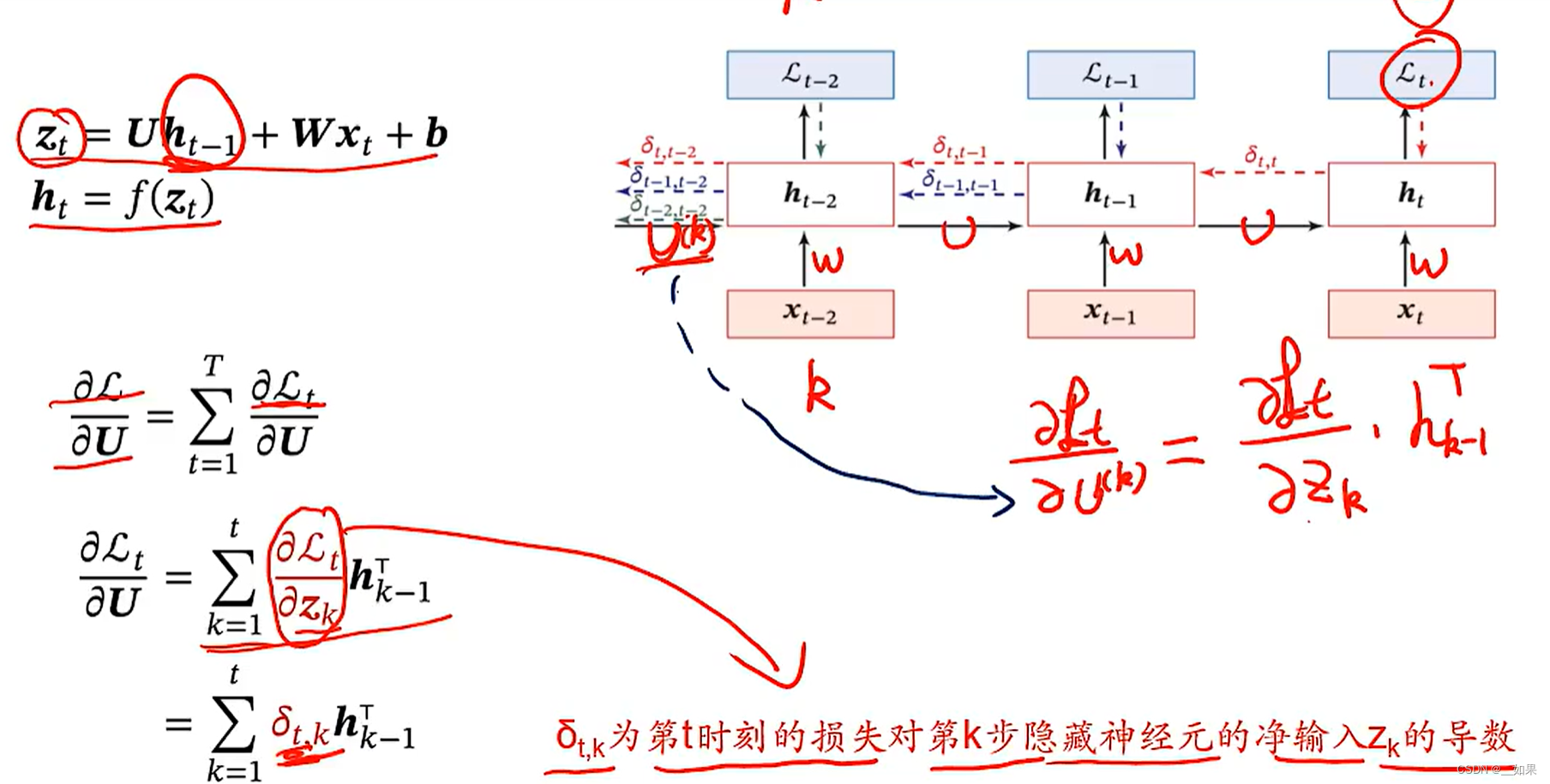
对误差在时间维度上求和就得到了总误差,因此反向传播时也可分为不同时刻的反向传播结果U的结果求和
Lt对U求偏导,就是第t时刻的loss对(第k时刻的zk的导数)*(上一时刻隐藏状态的转置)求和
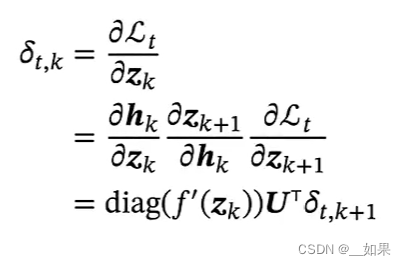
长程依赖问题
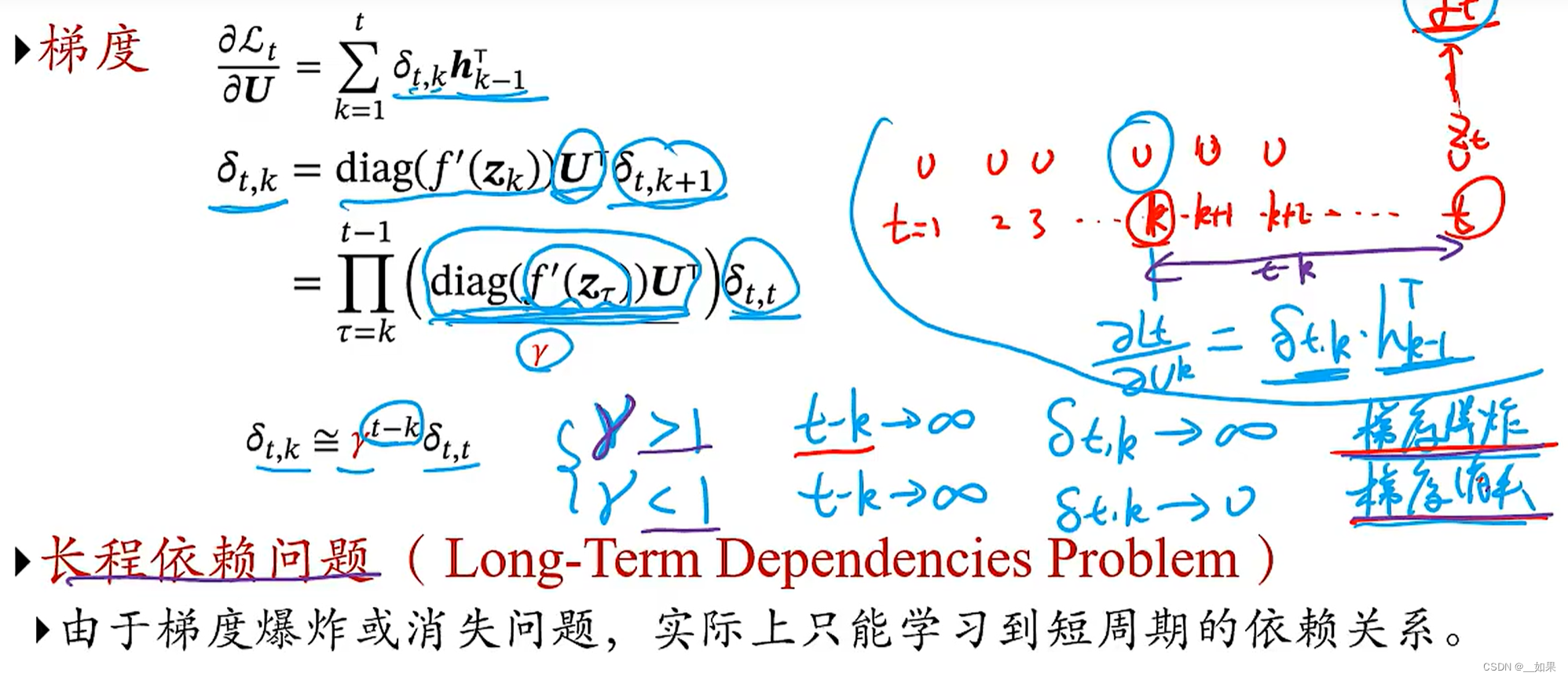
将链式法则求出的式子继续展开得到(t-k个激活函数的导数的对角矩阵乘U的转置)再乘Lt对zt的偏导
由于f'(zτ)是一个有界函数,U是共享的参数,所以把他们近似看作γ
因此δt,k近似等于γ^t-kδt,t,当γ>1时,若t时刻距离k时刻很长,则会梯度爆炸,反之则会梯度消失,所以实际上只能学到短周期的时间依赖关系
如何解决长程依赖问题

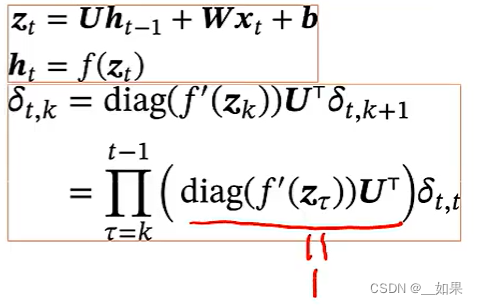
我们希望γ=1,首先把f的非线性f去掉,也就是让ht=Uht-1+Wxt+b,这样使得f’为1。接下来把U变成1也就是单位矩阵,因此ht=ht-1+Wxt+b,此时的γ=1

如图所示,激活函数g是对Wxt+b引入非线性,但是由于ht-1与ht之间变成了线性关系,导致模型能力变差

进一步改进,后面的g(xt,ht-1;θ)其实就是原来的f(Uht-1+Wxt+b),这样改进既保留了非线性,又解决了梯度的问题
当激活函数g选取sigmoid、relu等一直为正的激活函数,加上ht-1是一个累计的状态(不断增大)
例如当激活函数为sigmoid时,由于h不断累计,导致g(xt,ht-1;θ)趋近0或1而出现梯度消失,从而导致难以向网络增加新的信息。因此我们可以在ht-1中选择性地丢弃一些信息,接下来会给大家介绍两种基于门控的方法
残差:如果把g(xt,ht-1;θ)中的xt去掉,得到ht = g(ht-1;θ),这个式子与残差网络是十分相似的,都解决了梯度消失的问题
GRU与LSTM

GRU
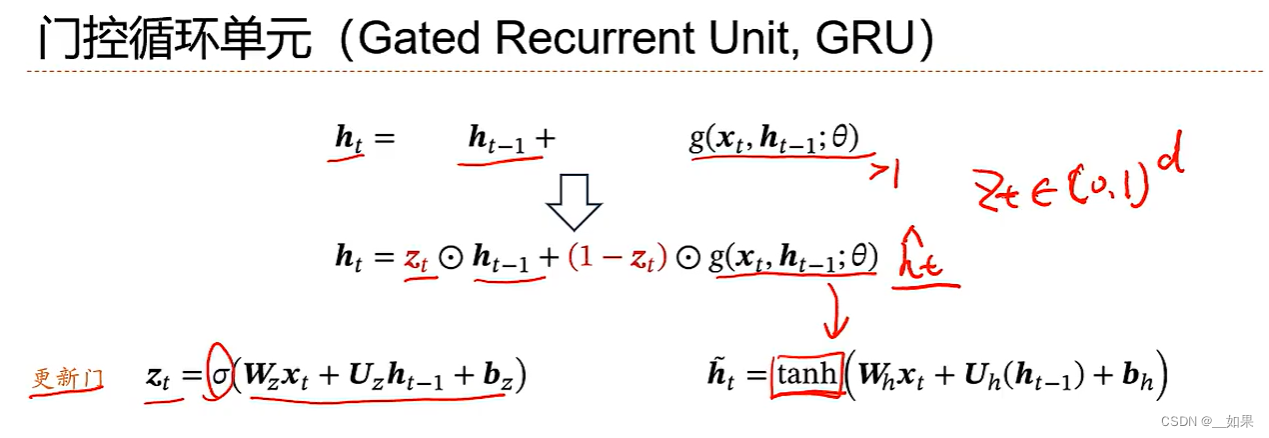
zt是一个与h维度相同的向量,每一维都在0~1之间,用sigmoid激活函数
g用得到是tanh激活函数,将0~1变成-1~1,且梯度更大一些
当zt接近1时,ht的信息更多来自于ht-1;当zt接近0,ht的信息更多来自于xt

若想要ht的信息只来源于xt,则可以加一个rt在ht-1之前
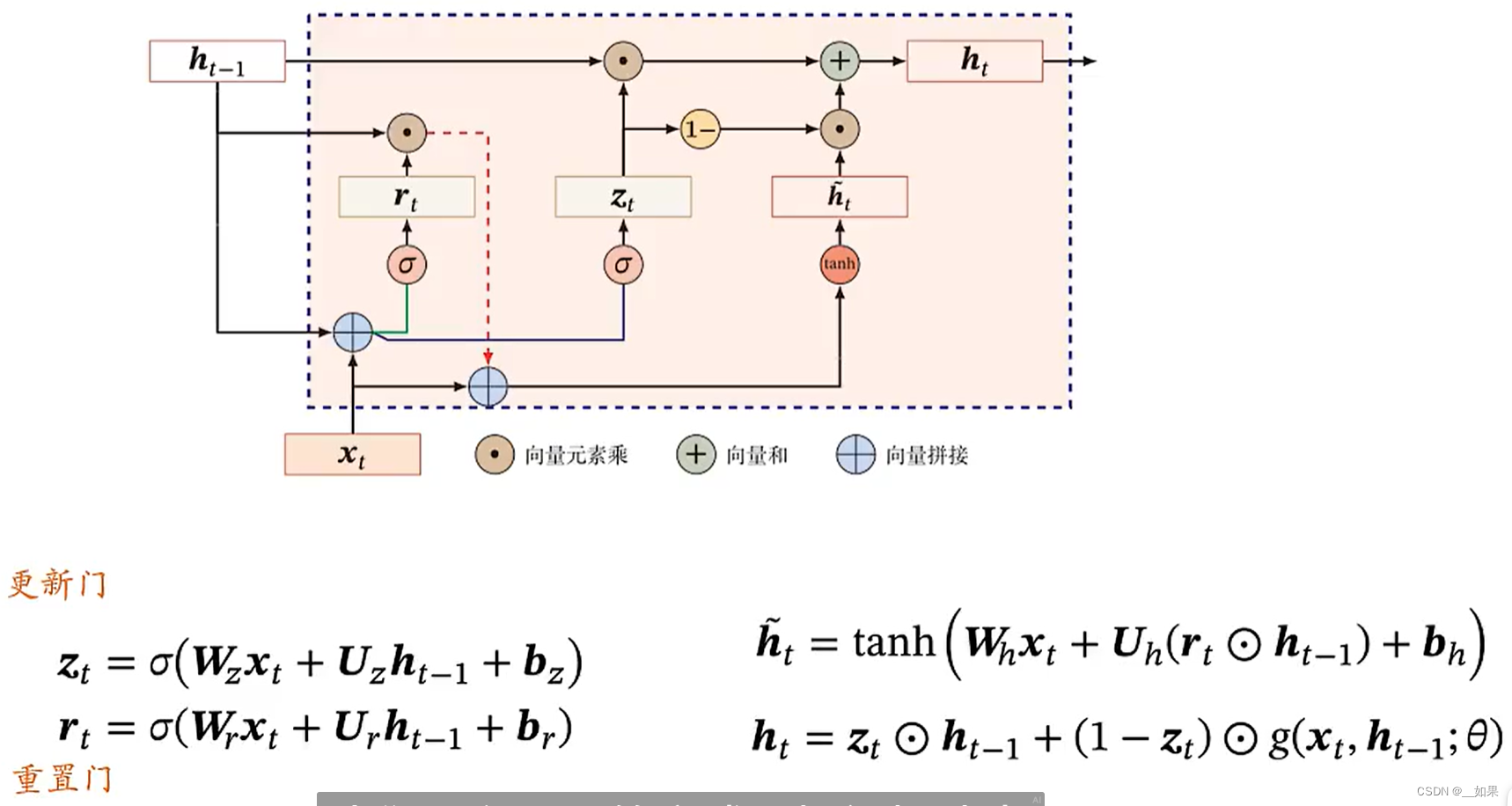
LSTM

引入了内部记忆单元c,通过c进行记忆线性的传递,把h释放出来更好地去做非线性


深层循环神经网络
虽然循环神经网络在时间维度上可以认为是一个非常深的网络,但在非线性维度上是非常浅的,我们希望把它加深,看看模型能力有没有提升
堆叠循环神经网络

变式
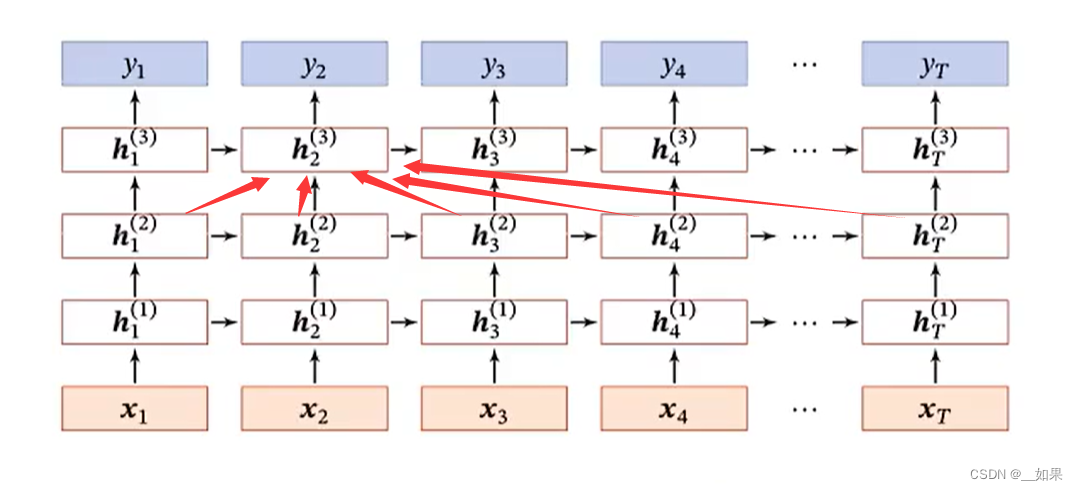
可以使某个状态来自于下一层所有时刻的状态

也可以使某个状态来自于上一时刻的所有层
双向循环神经网络
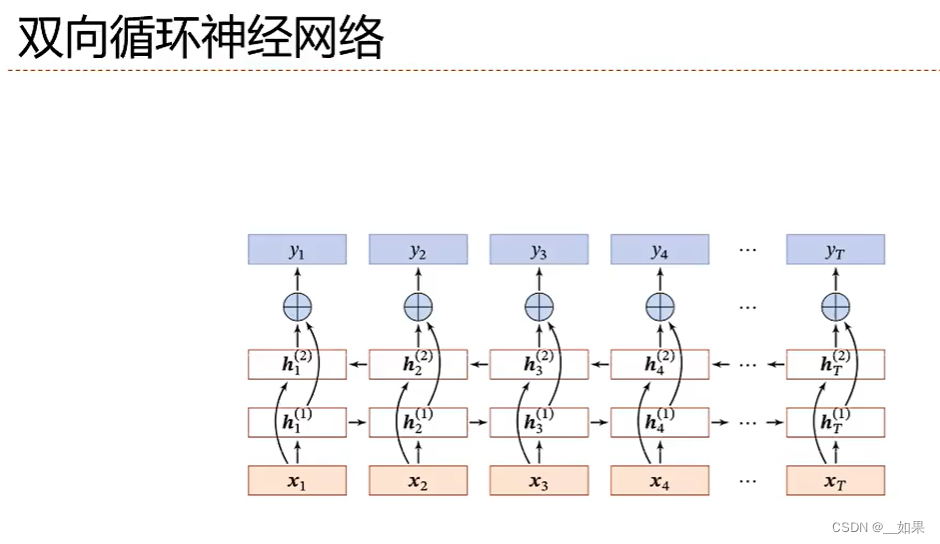
对输入的时序数据,既可以从左往右建模,也可以从右往左建模,好处是得到了双向的信息与趋势,模型效果更好
Q:如何增加循环神经网络的并行能力?
A:
双向循环神经网络(BRNN):BRNN 通过在输入层引入未来信息,使得网络可以同时利用过去和未来的数据。这种结构在处理自然语言处理、语音识别等任务时具有较好的性能。BRNN 可以在一定程度上提高并行计算能力,但仍然受到循环连接的限制。
增加网络层数:通过增加网络层数,可以降低梯度消失和梯度爆炸的问题,提高模型性能。同时,深度循环神经网络具有较强的并行计算能力,因为大部分计算可以在各层之间并行进行。
跳步连接(skip connection):在循环神经网络中引入跳步连接,可以使得网络在训练过程中更快地收敛,并提高模型的并行计算能力。跳步连接使得网络可以在不同层之间直接传递信息,减少了梯度消失问题,同时提高了并行处理能力。
分离式循环神经网络(Separable Recurrent Neural Network,SRNN):SRNN 将循环神经网络的内部循环结构分离成两个独立的子网络,一个负责处理过去信息,另一个负责处理未来信息。这种结构在训练和预测过程中可以实现部分并行计算,提高网络的性能。
准并行循环神经网络(Quasi-Parallel Recurrent Neural Network,QPRNN):QPRNN 采用一种准并行的结构,将循环神经网络中的递归关系用多个并行子网络表示。这种结构可以在一定程度上提高并行计算能力,但仍然受到梯度消失和梯度爆炸问题的限制。
内存增强神经网络(Memory-Augmented Neural Network,MANN):MANN 在循环神经网络中引入了一种新型内存模块,用于存储和检索相关信息。这种结构可以提高网络的并行计算能力,同时增强了对长序列数据的处理能力。
转换器架构(Transformer):转换器架构是一种基于自注意力机制的深度神经网络,其在自然语言处理等领域取得了显著的成果。虽然转换器并非典型的循环神经网络,但其在并行计算方面具有很强的能力。通过将循环神经网络与转换器相结合,可以进一步提高网络的并行能力。
循环神经网络应用




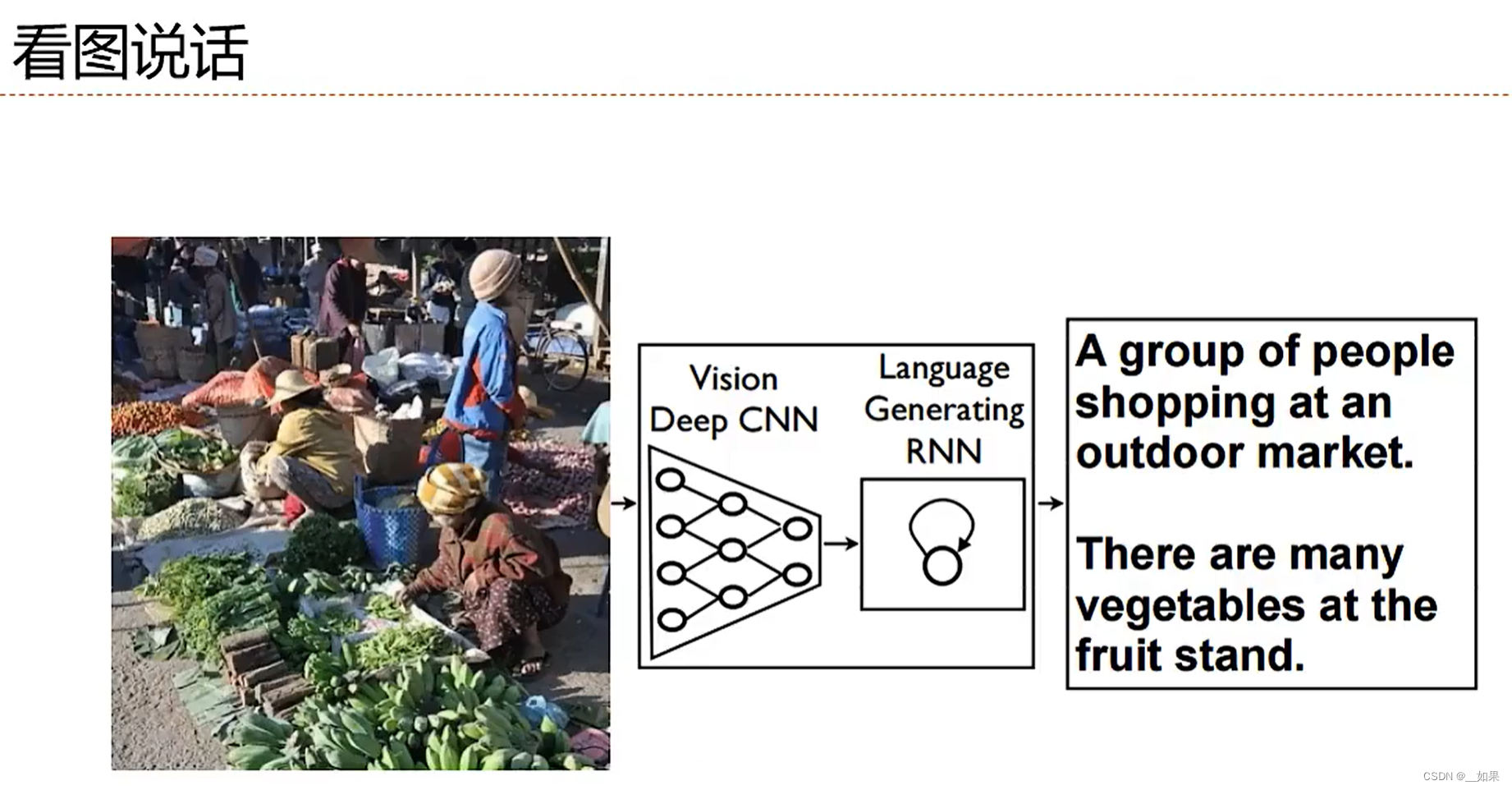



扩展到图结构
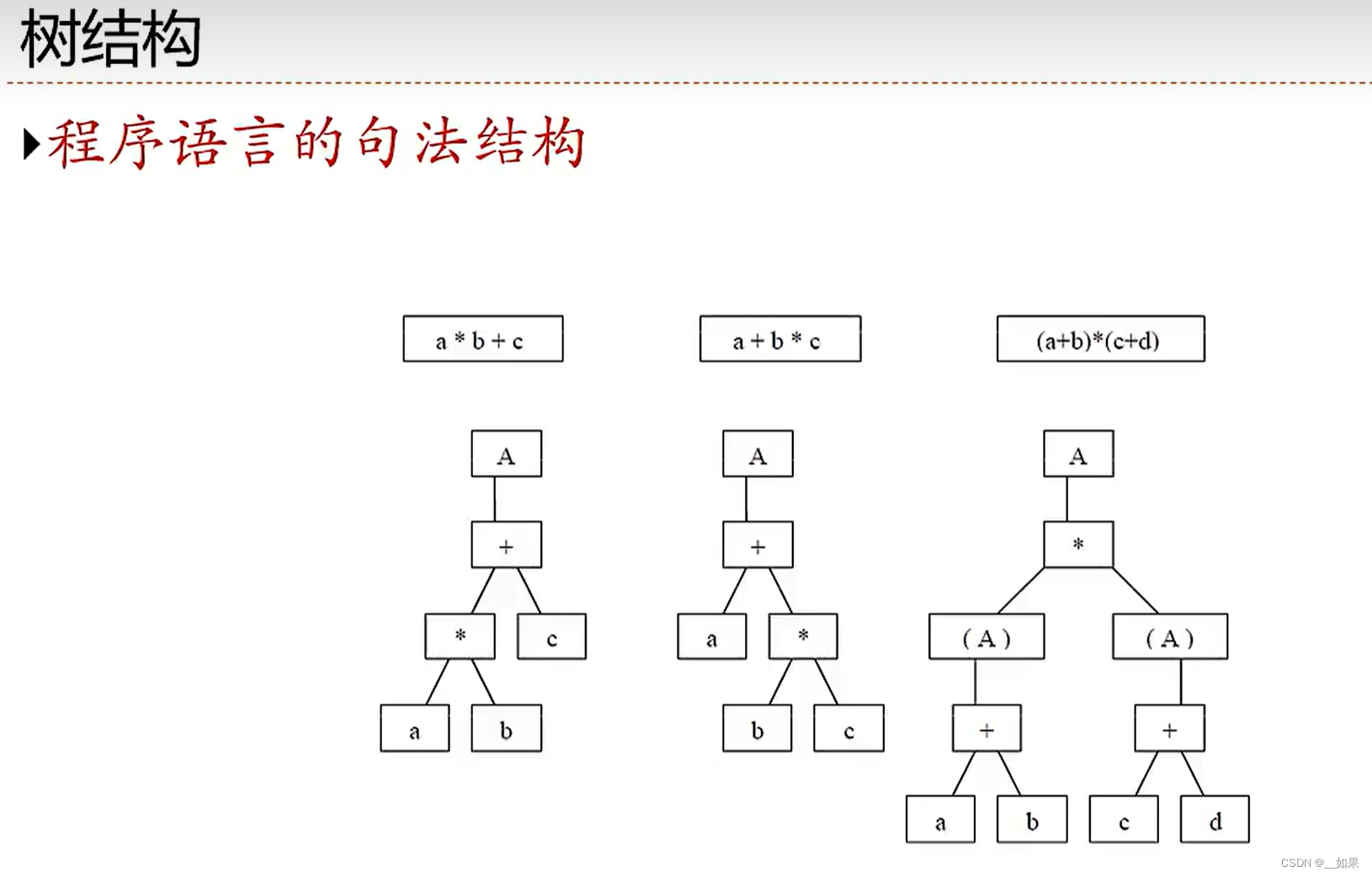
树结构

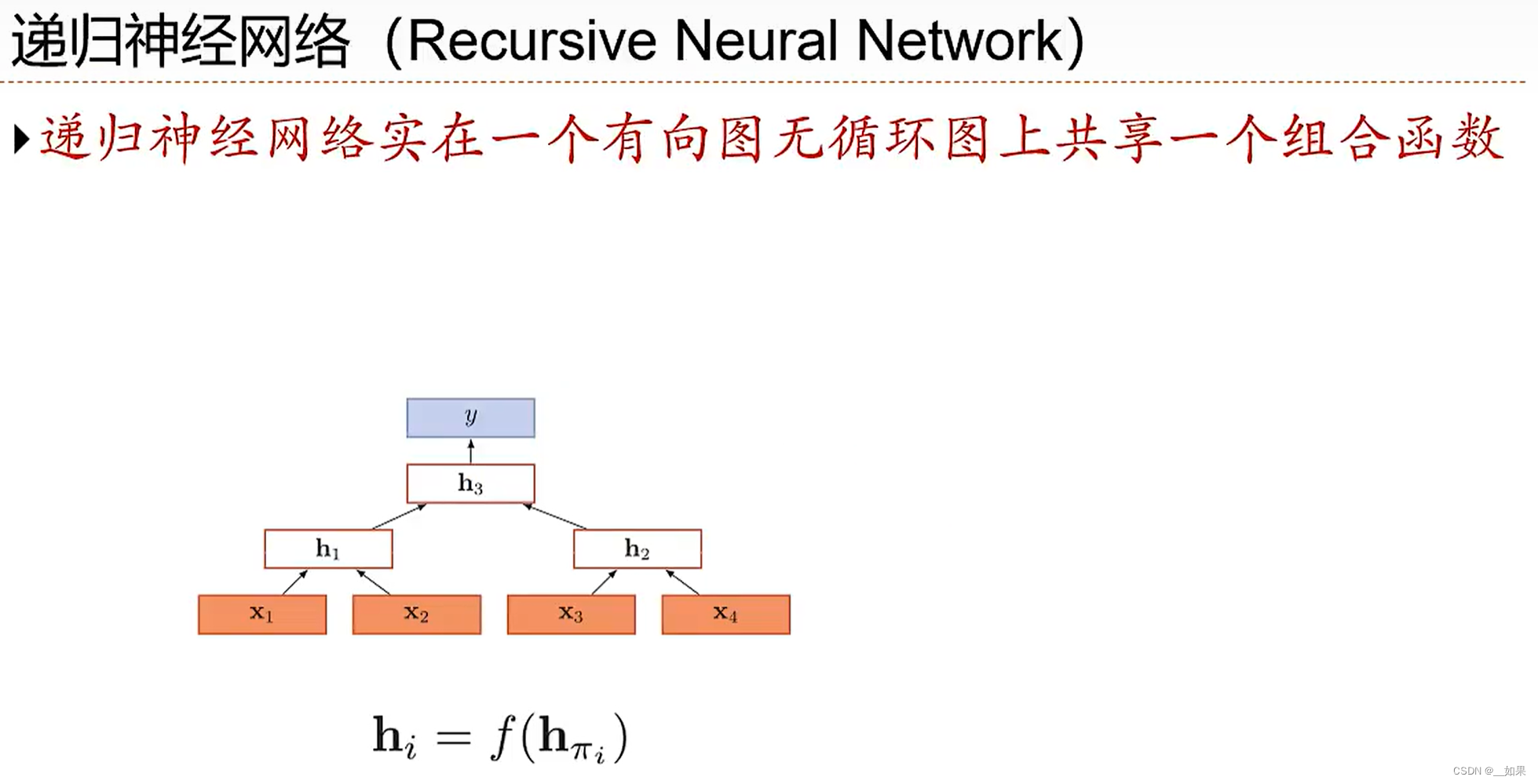
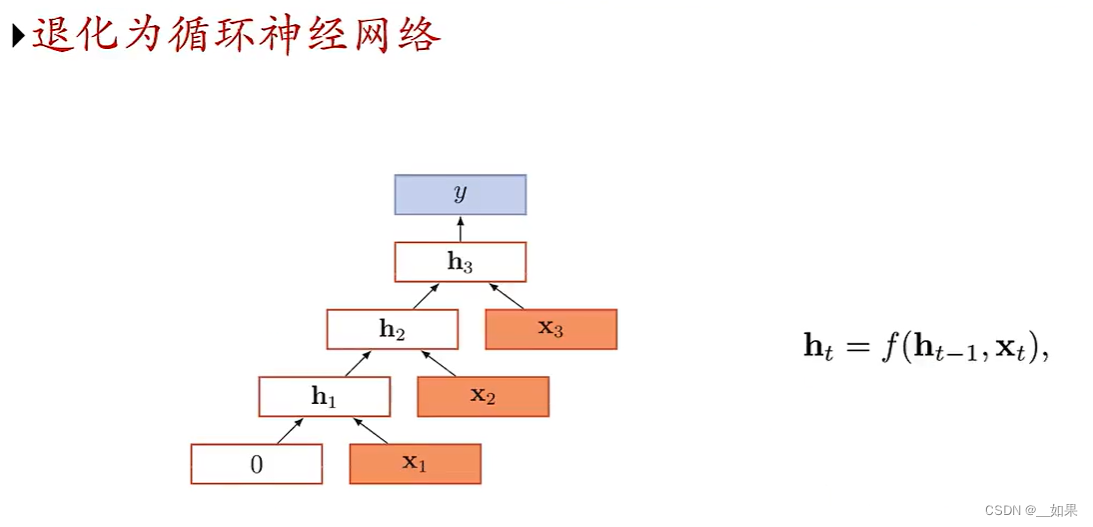
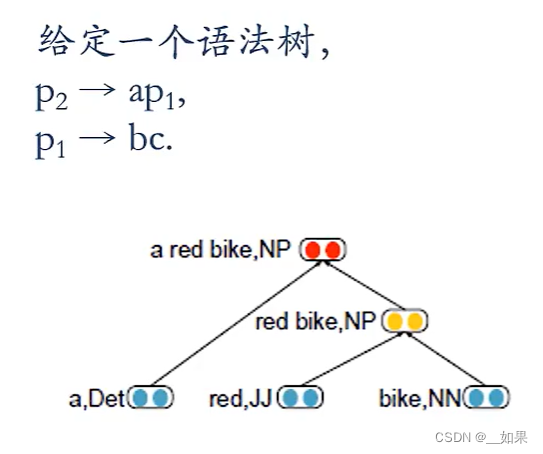
图结构
在实际应用中,很多数据是图结构的,比如知识图谱、社交网络、分子网络等。而前馈网络和循环网络很难处理图结构的数据
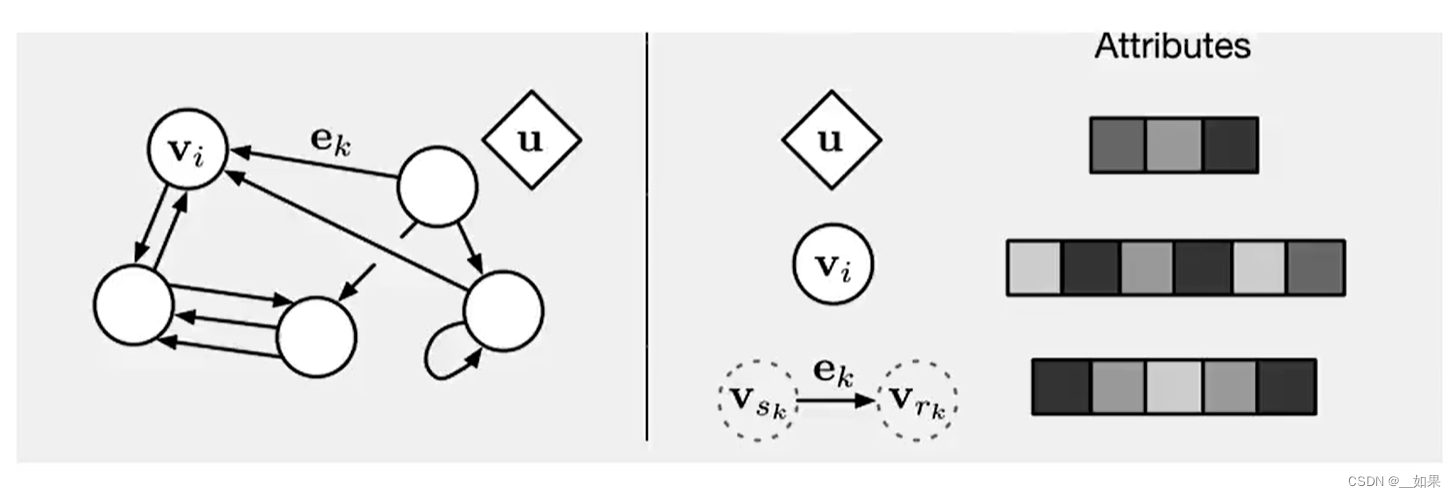
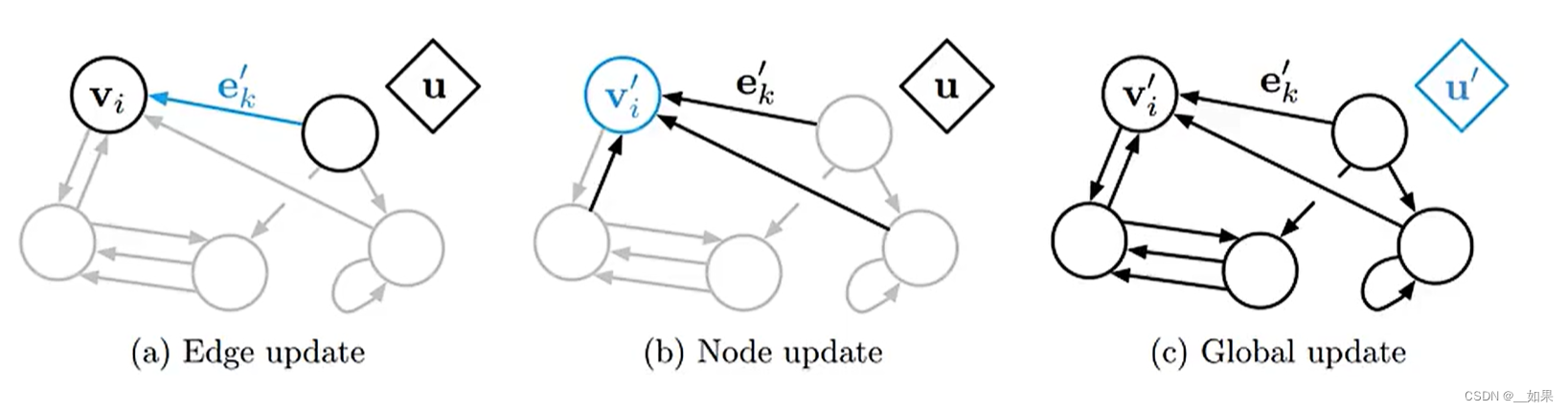
(3)更新u

mt(v)是指v收到的信息,ht-1是上一时刻的状态,u是v的所有邻居结点
原文地址:https://blog.csdn.net/m0_73202283/article/details/134608208
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_22602.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!